count(*) ne compte pas la valeur de chaque colonne (qu'elle soit nulle ou non), mais compte directement le nombre de lignes, ce qui est plus efficace ;
Vous pouvez également utiliser la méthode d'élimination. Par exemple, si la plateforme est qq et qu'il y a beaucoup de données, vous pouvez utiliser les données totales pour soustraire les données de platform=other;
D'un point de vue commercial, le coût pour obtenir des valeurs précises est très élevé, mais le coût des valeurs approximatives est inférieur si les exigences ne sont pas strictes, des valeurs approximatives peuvent être utilisées à la place. 🎜#
Vous pouvez également envisager d'utiliser une "base de données mémoire" telle que Redis pour maintenir cette acquisition de données chronophage ;
1. Si je rencontre un tel problème, ma solution est de créer une nouvelle table, telle que playfrom_count pour les statistiques. Il serait préférable d'utiliser des méthodes comme after_insert et after_delete dans le framework. Sinon, écrivez-en une vous-même. . Si le volume d'une telle requête n'est pas très important, ou s'il n'est pas très précis, vous pouvez effectuer une tâche pour l'exécuter de temps en temps 3. ajouté où, il analysera toute la table. Vous pouvez donc augmenter la vitesse de récupération en ajoutant une clé primaire.
Option 1. Créez une table de partition pour la plateforme Option 2. Divisez la table par plateforme Option 3. Créez un index séparé pour la plateforme, mais étant donné que l'ensemble de valeurs de votre plateforme ne doit pas être très grand, ce n'est pas le cas approprié de faire cet index
Ce problème sera rencontré dans les bases de données relationnelles classiques. La solution générale consiste à accéder à la table système, qui contient le nombre de lignes de données dans chaque table, ce qui est infiniment plus rapide que votre COUNT(*).
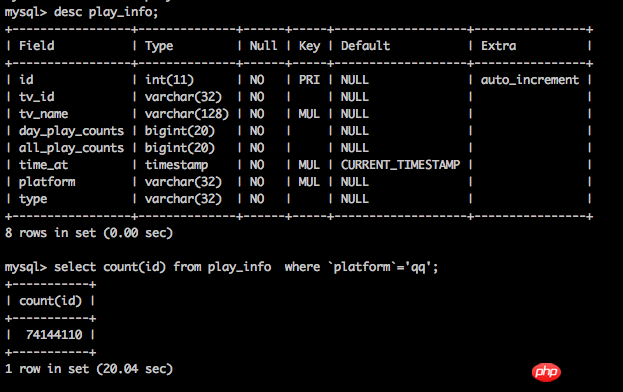
Mettez à niveau votre machine. Même un simple décompte prend 20 secondes. Bien qu'il existe de nombreuses méthodes telles que les tables de partition, je pense que l'investissement n'en vaut pas la peine.
Il est recommandé de considérer d'abord les besoins du scénario commercial. Le coût d'une solution purement technique est trop élevé et, dans de nombreux cas, il est pratiquement impossible de la mettre en œuvre. Les solutions possibles sont : 1. Diviser les tables : diviser en plusieurs tables selon la plate-forme. Le moteur de stockage est MyISAM. L'instruction de requête est modifiée en count(*). dans le tableau, l'efficacité des requêtes est donc grandement améliorée. Il est nécessaire de prendre en compte la charge de travail de transformation du système causée par les sous-tables et de savoir si MyISAM peut répondre aux exigences du système car MyISAM ne prend pas en charge les transactions.
2. Créez des tables ou des champs redondants et recalculez les données qui doivent être résumées lorsqu'elles changent. Vous devez vous demander si un grand nombre d'opérations de mise à jour augmenteront la charge du système.
3. Si les résultats de la requête ne doivent pas être complètement précis, les résultats peuvent être calculés régulièrement et enregistrés lors de l'interrogation, la table d'origine n'est pas directement interrogée.
Dans ce cas, il peut être divisé en plusieurs tableaux statistiques selon les mois ou les trimestres. Par exemple, si vous avez 8 millions de données, créez un nouveau tableau et chaque ligne représente le total des enregistrements d'un mois. De cette façon, les statistiques seront beaucoup plus rapides.
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




count(*) ne compte pas la valeur de chaque colonne (qu'elle soit nulle ou non), mais compte directement le nombre de lignes, ce qui est plus efficace ;
Vous pouvez également utiliser la méthode d'élimination. Par exemple, si la plateforme est qq et qu'il y a beaucoup de données, vous pouvez utiliser les données totales pour soustraire les données de platform=other;
D'un point de vue commercial, le coût pour obtenir des valeurs précises est très élevé, mais le coût des valeurs approximatives est inférieur si les exigences ne sont pas strictes, des valeurs approximatives peuvent être utilisées à la place. 🎜#
Vous pouvez également envisager d'utiliser une "base de données mémoire" telle que Redis pour maintenir cette acquisition de données chronophage ;1. Si je rencontre un tel problème, ma solution est de créer une nouvelle table, telle que playfrom_count pour les statistiques.
Il serait préférable d'utiliser des méthodes comme after_insert et after_delete dans le framework. Sinon, écrivez-en une vous-même.
. Si le volume d'une telle requête n'est pas très important, ou s'il n'est pas très précis, vous pouvez effectuer une tâche pour l'exécuter de temps en temps
3. ajouté où, il analysera toute la table. Vous pouvez donc augmenter la vitesse de récupération en ajoutant une clé primaire.
Option 1. Créez une table de partition pour la plateforme
Option 2. Divisez la table par plateforme
Option 3. Créez un index séparé pour la plateforme, mais étant donné que l'ensemble de valeurs de votre plateforme ne doit pas être très grand, ce n'est pas le cas approprié de faire cet index
Ce problème sera rencontré dans les bases de données relationnelles classiques. La solution générale consiste à accéder à la table système, qui contient le nombre de lignes de données dans chaque table, ce qui est infiniment plus rapide que votre COUNT(*).
Mettez à niveau votre machine. Même un simple décompte prend 20 secondes. Bien qu'il existe de nombreuses méthodes telles que les tables de partition, je pense que l'investissement n'en vaut pas la peine.
Il est recommandé de considérer d'abord les besoins du scénario commercial. Le coût d'une solution purement technique est trop élevé et, dans de nombreux cas, il est pratiquement impossible de la mettre en œuvre.
Les solutions possibles sont :
1. Diviser les tables : diviser en plusieurs tables selon la plate-forme. Le moteur de stockage est MyISAM. L'instruction de requête est modifiée en count(*). dans le tableau, l'efficacité des requêtes est donc grandement améliorée. Il est nécessaire de prendre en compte la charge de travail de transformation du système causée par les sous-tables et de savoir si MyISAM peut répondre aux exigences du système car MyISAM ne prend pas en charge les transactions.
2. Créez des tables ou des champs redondants et recalculez les données qui doivent être résumées lorsqu'elles changent. Vous devez vous demander si un grand nombre d'opérations de mise à jour augmenteront la charge du système.
3. Si les résultats de la requête ne doivent pas être complètement précis, les résultats peuvent être calculés régulièrement et enregistrés lors de l'interrogation, la table d'origine n'est pas directement interrogée.
Dans ce cas, il peut être divisé en plusieurs tableaux statistiques selon les mois ou les trimestres. Par exemple, si vous avez 8 millions de données, créez un nouveau tableau et chaque ligne représente le total des enregistrements d'un mois. De cette façon, les statistiques seront beaucoup plus rapides.