


La simulation réaliste à la lumière joue un rôle clé dans des applications telles que la conduite autonome, où les progrès des champs de rayonnement des réseaux neuronaux (NeRF) peuvent permettre une meilleure évolutivité en créant automatiquement des actifs numériques 3D. Cependant, la qualité de la reconstruction des scènes de rue souffre de la forte colinéarité des mouvements de caméra dans les rues et du faible échantillonnage à grande vitesse. D'un autre côté, l'application nécessite souvent un rendu depuis une perspective de caméra qui s'écarte de la perspective d'entrée pour simuler avec précision des comportements tels que les changements de voie. LidaRF présente plusieurs informations qui permettent une meilleure utilisation des données lidar pour améliorer la qualité du NeRF dans les vues de rue. Premièrement, le cadre apprend les représentations géométriques de scènes à partir des données LiDAR, qui sont combinées avec un décodeur implicite basé sur un maillage pour fournir des informations géométriques plus solides fournies par le nuage de points affiché. Deuxièmement, une stratégie de formation supervisée en profondeur robuste et sensible à l'occlusion est proposée, permettant d'améliorer la qualité de la reconstruction NeRF dans les scènes de rue en accumulant des informations solides à l'aide de nuages de points LiDAR denses. Troisièmement, des vues d'entraînement améliorées sont générées sur la base de l'intensité des points lidar pour améliorer encore les améliorations significatives obtenues dans la synthèse de nouvelles vues dans des scénarios de conduite réels. De cette manière, avec une représentation géométrique plus précise de la scène apprise par le framework à partir des données lidar, la méthode peut être améliorée en une seule étape et obtenir des améliorations significatives dans les scénarios de conduite réels.
La contribution de LidaRF se reflète principalement dans trois aspects :
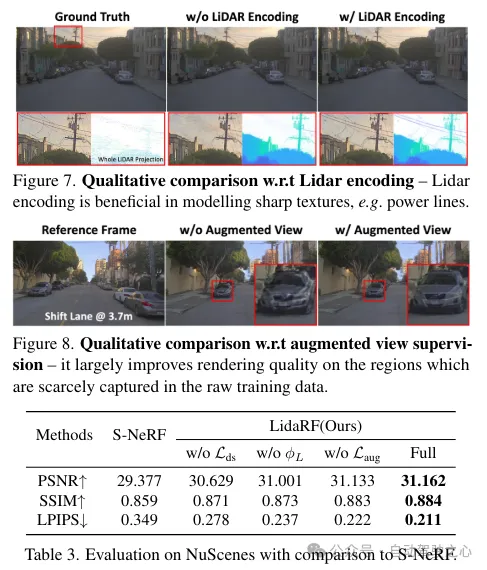
(i) Mélanger l'encodage lidar et les fonctionnalités de grille pour améliorer la représentation de la scène. Bien que le lidar ait été utilisé comme source naturelle de surveillance de la profondeur, son intégration dans les entrées NeRF offre un grand potentiel d’induction géométrique, mais n’est pas simple à mettre en œuvre. À cette fin, une représentation basée sur une grille est empruntée, mais les caractéristiques apprises à partir des nuages de points sont fusionnées dans la grille pour hériter des avantages des représentations explicites des nuages de points. Grâce au lancement réussi du cadre de perception 3D, les réseaux convolutionnels clairsemés 3D sont utilisés comme structure efficace et efficiente pour extraire des caractéristiques géométriques du contexte local et global des nuages de points lidar.
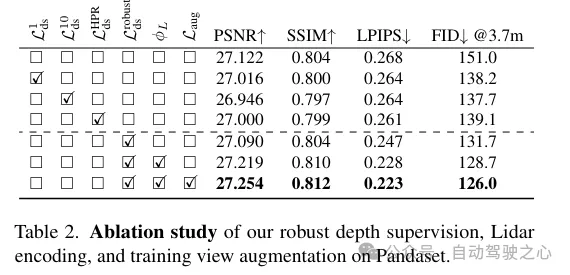
(ii) Supervision de profondeur robuste tenant compte de l'occlusion. À l’instar des travaux existants, le lidar est également utilisé ici comme source de supervision approfondie, mais de manière plus approfondie. Étant donné que la rareté des points lidar limite son efficacité, en particulier dans les zones à faible texture, des cartes de profondeur plus denses sont générées en agrégeant les points lidar sur des images voisines. Cependant, la carte de profondeur ainsi obtenue ne prend pas en compte les occlusions, ce qui entraîne une surveillance erronée de la profondeur. Par conséquent, un système robuste de supervision de la profondeur est proposé, empruntant la méthode d'apprentissage en classe - supervisant progressivement la profondeur du champ proche au champ lointain et filtrant progressivement la mauvaise profondeur pendant le processus de formation NeRF, de manière à extraire plus efficacement la profondeur. profondeur à partir du lidar.
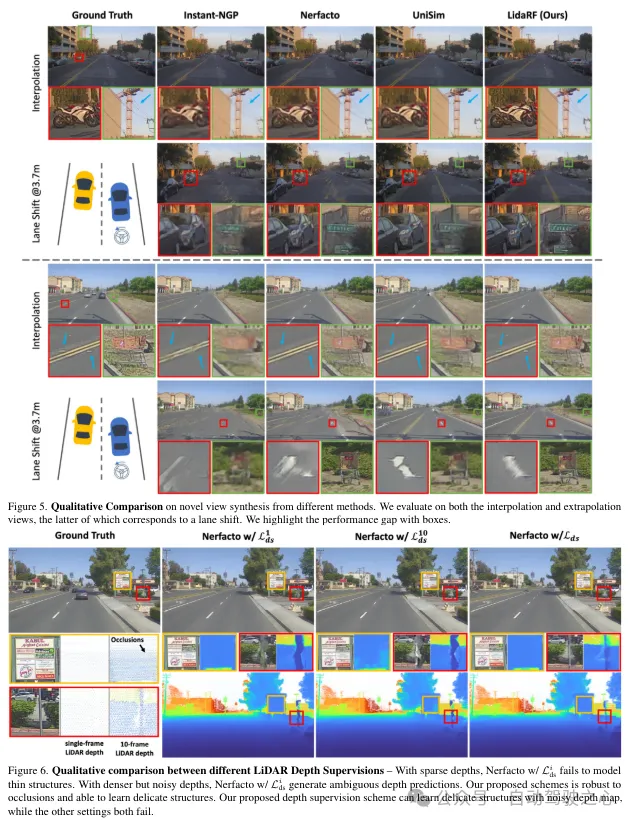
(iii) Amélioration de la vue basée sur LiDAR. De plus, étant donné la rareté des vues et la couverture limitée dans les scénarios de conduite, le lidar est utilisé pour densifier les vues d'entraînement. Autrement dit, les points lidar accumulés sont projetés dans de nouvelles vues d'entraînement ; notez que ces vues peuvent s'écarter quelque peu de la trajectoire de conduite. Ces vues projetées à partir du lidar sont ajoutées à l'ensemble de données d'entraînement et ne tiennent pas compte des problèmes d'occlusion. Cependant, nous appliquons le schéma de supervision mentionné précédemment pour résoudre le problème d’occlusion, améliorant ainsi les performances. Bien que notre méthode soit également applicable aux scènes générales, dans ce travail nous nous concentrons davantage sur l'évaluation des scènes de rue et obtenons des améliorations significatives par rapport aux techniques existantes, tant quantitativement que qualitativement.
LidaRF a également montré des avantages dans des applications intéressantes qui nécessitent un plus grand écart par rapport à la vue d'entrée, améliorant considérablement la qualité de NeRF dans les applications de scènes de rue difficiles.
LidaRF est une méthode de saisie et de sortie des densités et des couleurs correspondantes. Elle utilise UNet pour combiner le codage Huff et le codage lidar. De plus, des données de formation améliorées sont générées via des projections lidar pour former des prédictions géométriques à l'aide du schéma de supervision approfondie robuste proposé.
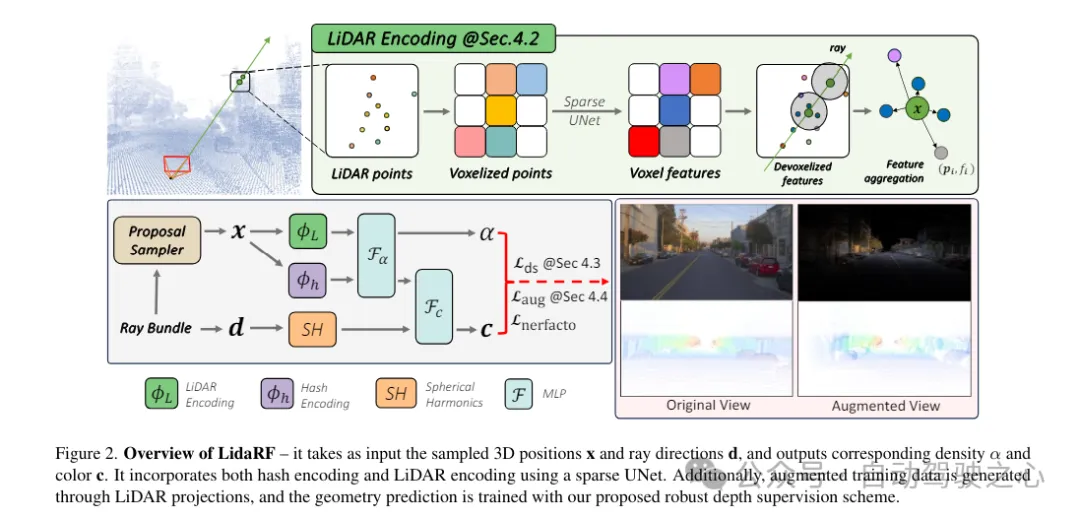
Les nuages de points Lidar ont un fort potentiel de guidage géométrique, ce qui est extrêmement précieux pour le NeRF (Neural Rendering Field). Cependant, s'appuyer uniquement sur les fonctionnalités lidar pour la représentation de la scène entraîne un rendu à faible résolution en raison de la nature clairsemée des points lidar (malgré l'accumulation temporelle). De plus, comme le lidar a un champ de vision limité, par exemple il ne peut pas capturer les surfaces des bâtiments au-dessus d'une certaine hauteur, des rendus vierges se produisent dans ces zones. En revanche, notre framework fusionne les fonctionnalités lidar et les fonctionnalités de grille spatiale haute résolution pour exploiter les avantages des deux et apprendre ensemble pour obtenir un rendu de scène complet et de haute qualité.
Extraction des fonctionnalités Lidar. Le processus d'extraction de caractéristiques géométriques pour chaque point lidar est décrit en détail ici. En référence à la figure 2, les nuages de points lidar de toutes les images de la séquence entière sont d'abord agrégés pour créer une collection de nuages de points plus dense. Le nuage de points est ensuite voxélisé en une grille de voxels, où les positions spatiales des points au sein de chaque unité de voxel sont moyennées pour générer une caractéristique 3D pour chaque unité de voxel. Inspirées par le succès généralisé des cadres de perception 3D, les caractéristiques de la géométrie de la scène sont codées à l'aide d'UNet 3D clairsemé sur une grille de voxels, ce qui permet d'apprendre à partir du contexte global de la géométrie de la scène. UNet 3D clairsemé prend une grille de voxels et ses caractéristiques tridimensionnelles comme caractéristiques volumétriques neuronales d'entrée et de sortie. Chaque voxel occupé est composé de caractéristiques à n dimensions.
Requête de fonctionnalité Lidar. Pour chaque point échantillon x le long du rayon à restituer, s'il y a au moins K points lidar à proximité dans le rayon de recherche R, ses caractéristiques lidar sont interrogées, sinon, ses caractéristiques lidar sont définies sur nulles (c'est-à-dire toutes des zéros). Plus précisément, la méthode FRNN (Fixed Radius Nearest Neighbour) est utilisée pour rechercher l'ensemble d'indices de points lidar le plus proche lié à x, noté . Différente de la méthode de [9] qui prédétermine les points d'échantillonnage des rayons avant de commencer le processus de formation, notre méthode est en temps réel lors de l'exécution de la recherche FRNN, car à mesure que la formation NeRF converge, la distribution des points d'échantillonnage du réseau de régions tendra dynamiquement se concentrer sur la surface. Suivant l'approche Point-NeRF, notre méthode utilise un perceptron multicouche (MLP) F pour cartographier les caractéristiques lidar de chaque point dans une description de scène neuronale. Pour le i-ème point voisin de la méthode de pondération de distance inverse pour agréger la description de la scène neuronale de ses K points voisins
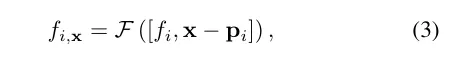
Fusion de fonctionnalités pour le décodage radiatif. Le code lidar ϕL est concaténé avec le code de hachage ϕh, et un perceptron multicouche Fα est appliqué pour prédire la densité α et l'incorporation de densité h de chaque échantillon. Enfin, grâce à un autre perceptron multicouche Fc, la couleur correspondante c est prédite sur la base du codage harmonique sphérique SH et de la densité intégrant h dans la direction de visualisation d.
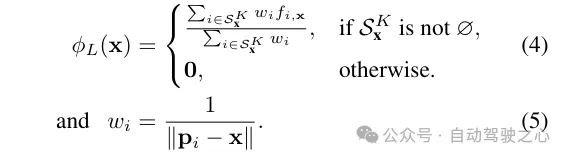
En plus de l'encodage des fonctionnalités, la supervision de profondeur est obtenue à partir de points lidar en les projetant sur le plan image. Cependant, en raison de la rareté des points lidar, les avantages qui en résultent sont limités et insuffisants pour reconstruire des zones à faible texture telles que les chaussées. Ici, nous proposons d'accumuler des images lidar adjacentes pour augmenter la densité. Bien que les points 3D soient capables de capturer avec précision la structure de la scène, l'occlusion entre les points doit être prise en compte lors de leur projection sur le plan image pour la surveillance de la profondeur. Les occlusions résultent d'un déplacement accru entre la caméra et le lidar et ses images adjacentes, entraînant une fausse surveillance de la profondeur, comme le montre la figure 3. En raison de la nature clairsemée du lidar, même après accumulation, il est très difficile de résoudre ce problème, ce qui rend les techniques graphiques fondamentales telles que le z-buffering inapplicables. Dans ce travail, un schéma de supervision robuste est proposé pour filtrer automatiquement les supervisions profondes parasites lors de la formation NeRF. 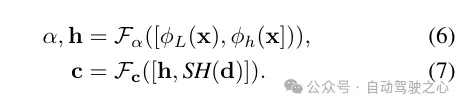
Rappelons qu'en raison du mouvement vers l'avant de la caméra embarquée, les images d'entraînement qu'elle produit sont clairsemées et ont une couverture de champ de vision limitée, ce qui pose des défis à la reconstruction NeRF, en particulier lorsque la nouvelle vue s'écarte de la trajectoire du véhicule. Ici, nous proposons d'exploiter LiDAR pour augmenter les données de formation. Tout d’abord, nous colorons le nuage de points de chaque image lidar en le projetant sur sa caméra synchronisée et en interpolant les valeurs RVB. Le nuage de points colorés est accumulé et projeté sur un ensemble de vues synthétiquement améliorées, produisant l’image synthétique et la carte de profondeur illustrées à la figure 2.
 Analyse comparative expérimentale
Analyse comparative expérimentale

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 utilisation du nœud clone
utilisation du nœud clone
 Tutoriel du portefeuille Eou web3
Tutoriel du portefeuille Eou web3
 Recommandation du logiciel de programmation PHP
Recommandation du logiciel de programmation PHP
 Prix de la pièce U aujourd'hui
Prix de la pièce U aujourd'hui
 Que dois-je faire si II ne peut pas démarrer ?
Que dois-je faire si II ne peut pas démarrer ?
 Quelle carte est la carte TF ?
Quelle carte est la carte TF ?
 Comment générer des nombres aléatoires en js
Comment générer des nombres aléatoires en js








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



