


Il y a deux jours, Yann LeCun, lauréat du prix Turing, a republié la longue bande dessinée "Allez sur la Lune et explorez-vous", qui a suscité de vives discussions parmi les internautes.

Dans l'article "Story Diffusion: Consistent Self-Attention for long-range image and video Generation", l'équipe de recherche a proposé une nouvelle méthode appelée Story Diffusion pour générer des images et des vidéos cohérentes pour décrire des situations complexes. Les recherches sur ces bandes dessinées proviennent d'institutions telles que l'Université de Nankai et ByteDance.

Des projets associés sont déjà en cours GitHub A obtenu un montant de 1 000 étoiles.
Adresse GitHub : https://github.com/HVision-NKU/StoryDiffusion
Selon la démonstration du projet, StoryDiffusion peut générer des bandes dessinées de styles variés, racontant une histoire cohérente tout en conservant la cohérence des personnages. style et vêtements.

StoryDiffusion peut conserver l'identité de plusieurs personnages simultanément et générer des personnages cohérents à travers une série d'images.

De plus, StoryDiffusion est capable de générer des vidéos de haute qualité conditionnées par des images cohérentes générées ou des images saisies par l'utilisateur.


Nous savons que maintenir la cohérence du contenu à travers une série d'images générées, en particulier celles contenant des sujets et des détails complexes, est un défi important pour les modèles génératifs basés sur la diffusion.
Par conséquent, l'équipe de recherche a proposé une nouvelle méthode de calcul de l'auto-attention, appelée Consistent Self-Attention, en établissant des connexions entre les images au sein d'un lot lors de la génération d'images et en générant des images thématiquement cohérentes sans formation.
Afin d'étendre cette méthode à la génération de vidéos longues, l'équipe de recherche a introduit un prédicteur de mouvement sémantique (Semantic Motion Predictor), qui encode les images dans l'espace sémantique et prédit le mouvement dans l'espace sémantique pour générer des vidéos. C’est plus stable que la prédiction de mouvement basée uniquement sur l’espace latent.
Effectuez ensuite l'intégration du framework, combinant une attention personnelle cohérente et des prédicteurs de mouvement sémantique pour générer des vidéos cohérentes et raconter des histoires complexes. StoryDiffusion peut générer des vidéos plus fluides et plus cohérentes que les méthodes existantes.

Figure 1 : Images et vidéos générées par le StroyDiffusion de l'équipe
La méthode de l'équipe de recherche peut être divisée en deux étapes, comme le montrent les figures 2 et 3.
Dans la première étape, StoryDiffusion utilise l'auto-attention cohérente pour générer des images cohérentes avec un sujet sans formation. Ces images cohérentes peuvent être utilisées directement dans la narration ou comme contribution à une deuxième étape. Dans un deuxième temps, StoryDiffusion crée des vidéos de transition cohérentes basées sur ces images cohérentes.
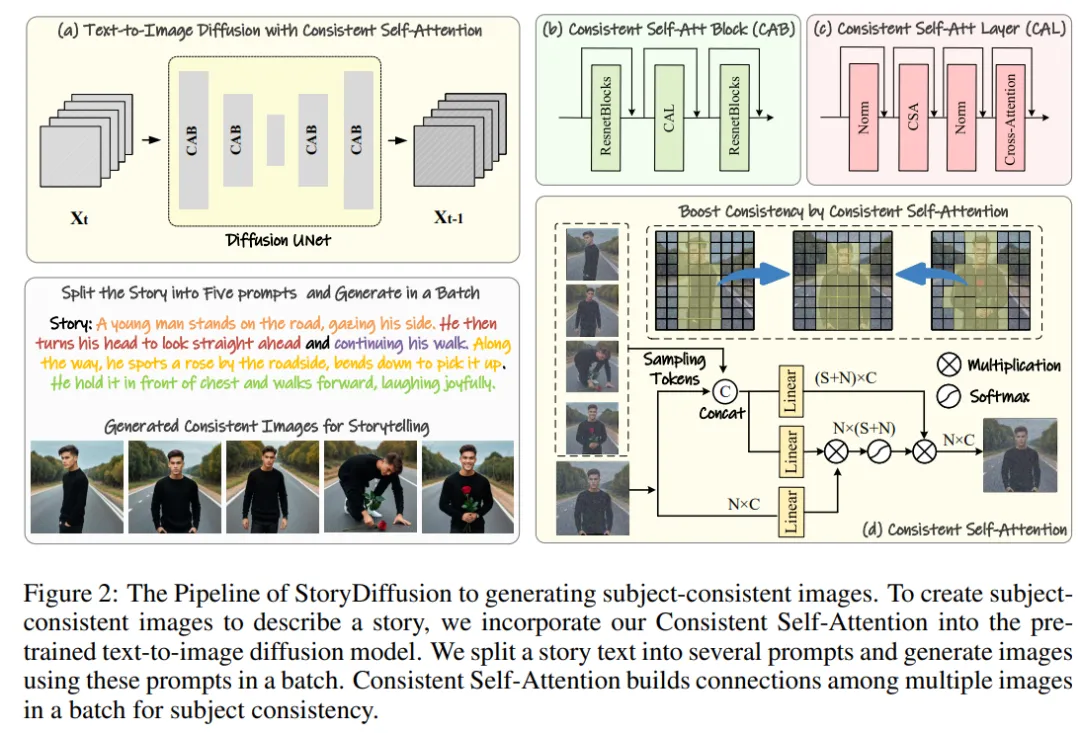
Figure 2 : Présentation du processus StoryDiffusion pour générer des images cohérentes avec un thème
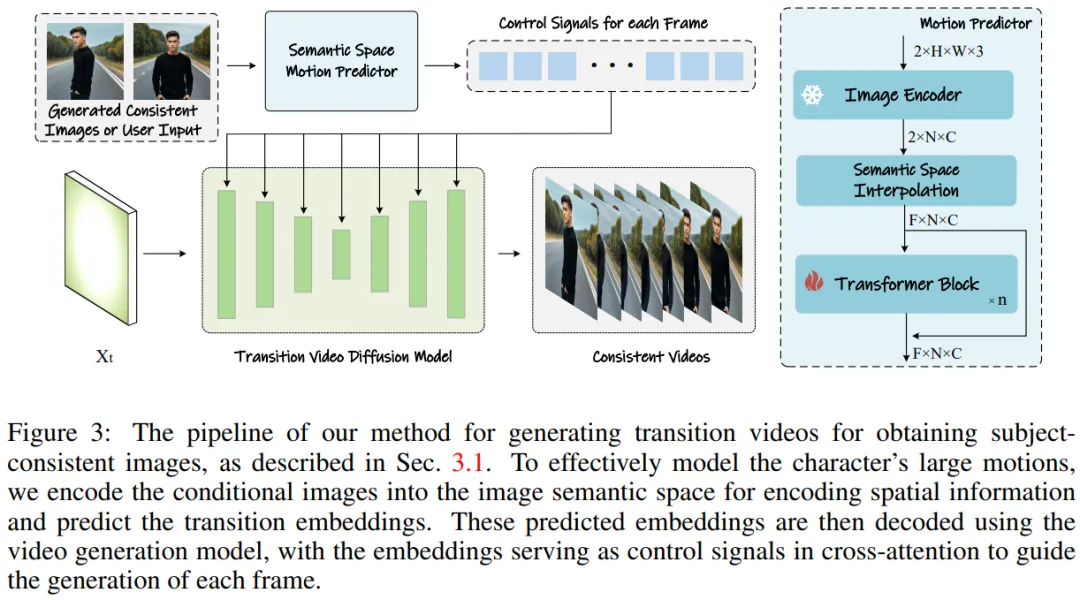 Figure 3 : Méthode de génération de vidéos de transition pour obtenir des images cohérentes avec un thème.
Figure 3 : Méthode de génération de vidéos de transition pour obtenir des images cohérentes avec un thème.
L'équipe de recherche a introduit la méthode "comment générer des images cohérentes avec un thème sans formation". La clé pour résoudre le problème ci-dessus est de savoir comment maintenir la cohérence des caractères dans un lot d'images. Cela signifie que lors du processus de génération, ils doivent établir des connexions entre un lot d'images.
Après avoir réexaminé le rôle des différents mécanismes d'attention dans le modèle de diffusion, ils ont été inspirés pour explorer l'utilisation de l'auto-attention pour maintenir la cohérence des images au sein d'un lot d'images, et ont proposé une auto-attention cohérente - Attention ).
L'équipe de recherche insère une auto-attention cohérente dans la position d'auto-attention d'origine dans l'architecture U-Net du modèle de génération d'images existant, et réutilise les poids d'auto-attention d'origine pour ne maintenir aucune formation et plug-and-play Fonctionnalités utilisées.
À partir de jetons appariés, la méthode de l’équipe de recherche effectue une auto-attention sur un lot d’images, favorisant les interactions entre les différentes caractéristiques de l’image. Ce type d'interaction entraîne la convergence du modèle sur les personnages, les visages et les vêtements au cours de la génération. Bien que la méthode d’auto-attention cohérente soit simple et ne nécessite aucune formation, elle peut générer efficacement des images thématiquement cohérentes.
Pour illustrer plus clairement, l'équipe de recherche montre le pseudocode dans l'algorithme 1.

Semantic Motion Predictor pour la génération vidéo
L'équipe de recherche a proposé le Semantic Motion Predictor (Semantic Motion Predictor), qui encode les images dans l'espace sémantique de l'image pour capturer des informations spatiales. Cela permet un mouvement plus précis prédiction à partir d’une image de début et d’une image de fin données.
Plus précisément, dans le prédicteur de mouvement sémantique proposé par l'équipe, ils utilisent d'abord une fonction E pour établir un mappage à partir d'images RVB vers des vecteurs d'espace sémantique d'image pour coder des informations spatiales.
L'équipe n'a pas utilisé directement la couche linéaire comme fonction E. Au lieu de cela, elle a utilisé un encodeur d'image CLIP pré-entraîné comme fonction E pour profiter de sa capacité de tir zéro pour améliorer les performances.
À l'aide de la fonction E, la trame de début F_s et la trame de fin données F_e sont compressées en vecteurs d'espace sémantique d'image K_s et K_e.

En termes de génération d'images cohérentes avec un sujet, puisque la méthode de l'équipe ne nécessite aucune formation et est plug-and-play, ils ont utilisé deux versions de Stable Diffusion XL et Stable Diffusion 1.5 All mis en œuvre cette méthode. Pour être cohérents avec les modèles comparés, ils ont utilisé les mêmes poids pré-entraînés sur le modèle Stable-XL à des fins de comparaison.
Pour générer des vidéos cohérentes, les chercheurs ont mis en œuvre leur méthode de recherche basée sur le modèle spécialisé Stable Diffusion 1.5 et ont intégré un module temporel pré-entraîné pour prendre en charge la génération de vidéos. Tous les modèles comparés utilisent un score de guidage sans classificateur de 7,5 et un échantillonnage DDIM en 50 étapes.
Comparaison de génération d'images cohérentes
L'équipe a évalué son approche pour générer des images cohérentes par sujet en la comparant à deux méthodes de préservation d'identité de pointe : IP-Adapter et Photo Maker.
Pour tester les performances, ils ont utilisé GPT-4 pour générer vingt instructions de rôle et cent instructions d'activité pour décrire des activités spécifiques.
Les résultats qualitatifs sont présentés dans la figure 4 : "StoryDiffusion est capable de générer des images très cohérentes. Alors que d'autres méthodes, telles que IP-Adapter et PhotoMaker, peuvent produire des images avec des vêtements incohérents ou une contrôlabilité réduite du texte." Figure 4 : Comparaison de la génération d'images cohérentes avec les méthodes actuelles Les chercheurs présentent les résultats de la comparaison quantitative dans le tableau 1. Les résultats montrent : "StoryDiffusion de l'équipe a obtenu les meilleures performances sur les deux mesures quantitatives, indiquant que la méthode peut bien s'adapter à la description de l'invite tout en conservant les caractéristiques des personnages, et montre sa robustesse." génération d'images cohérentes En termes de génération de vidéos de transition, l'équipe de recherche a comparé deux méthodes de pointe - SparseCtrl et SEINE - Des comparaisons ont été faites pour évaluer les performances. Ils ont mené une comparaison qualitative de la génération de vidéos de transition et ont montré les résultats dans la figure 5. Les résultats montrent : "La StoryDiffusion de l'équipe est nettement meilleure que SEINE et SparseCtrl, et la vidéo de transition générée est à la fois fluide et cohérente avec les principes physiques." -méthodes art Comparaison de génération vidéo Ils ont également comparé cette méthode avec SEINE et SparseCtrl et ont utilisé quatre indicateurs quantitatifs, notamment LPIPSfirst, LPIPS-frames, CLIPSIM-first et CLIPSIM-frames, comme indiqué dans le tableau 2. Veuillez vous référer à l'article original pour plus de détails techniques et expérimentaux. 
 Comparaison de la génération de vidéos de transition
Comparaison de la génération de vidéos de transition Tableau 2 : Comparaison quantitative avec le modèle actuel de génération de vidéo de transition de pointe
Tableau 2 : Comparaison quantitative avec le modèle actuel de génération de vidéo de transition de pointe
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Construisez votre propre serveur git
Construisez votre propre serveur git
 La différence entre git et svn
La différence entre git et svn
 git annuler le commit soumis
git annuler le commit soumis
 Comment annuler l'erreur de commit git
Comment annuler l'erreur de commit git
 Comment comparer le contenu des fichiers de deux versions dans git
Comment comparer le contenu des fichiers de deux versions dans git
 Comment changer la couleur d'arrière-plan d'un mot en blanc
Comment changer la couleur d'arrière-plan d'un mot en blanc
 Solution d'erreur 3004 inconnue
Solution d'erreur 3004 inconnue
 Migrer les données d'un téléphone Android vers un téléphone Apple
Migrer les données d'un téléphone Android vers un téléphone Apple








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



