


Titre original : NeRF-XL : Scaling NeRFs with Multiple GPUs
Lien papier : https://research.nvidia.com/labs/toronto-ai/nerfxl/assets/nerfxl.pdf
Lien du projet : https:// / /research.nvidia.com/labs/toronto-ai/nerfxl/
Affiliation de l'auteur : NVIDIA University of California, Berkeley

Cet article propose NeRF-XL, qui est un principe procédé de distribution de champs de rayons neuronaux (NeRF) sur plusieurs unités de traitement graphique (GPU), permettant ainsi la formation et le rendu de NeRF avec des capacités arbitrairement grandes. Cet article passe d'abord en revue plusieurs méthodes GPU existantes qui décomposent de grandes scènes en plusieurs NeRF formés indépendamment [9, 15, 17] et identifie plusieurs problèmes fondamentaux avec ces méthodes qui posent problème lorsque l'utilisation de ressources informatiques (GPU) supplémentaires pour la formation empêche l'amélioration de la reconstruction. qualité. NeRF-XL résout ces problèmes et permet aux NeRF avec un nombre illimité de paramètres d'être entraînés et rendus en utilisant simplement plus de matériel. Le cœur de notre approche est une nouvelle formulation de formation et de rendu distribuée, qui est mathématiquement équivalente au cas classique d'un seul GPU et minimise la communication entre les GPU. En déverrouillant les NeRF avec un nombre arbitrairement grand de paramètres, notre méthode est la première à révéler les lois de mise à l'échelle GPU des NeRF, montrant une qualité de reconstruction améliorée à mesure que le nombre de paramètres augmente et que plus de GPU sont utilisés. La vitesse augmente avec l'augmentation. Cet article démontre l'efficacité de NeRF-XL sur une variété d'ensembles de données, y compris MatrixCity [5], qui contient environ 258 000 images et couvre une zone urbaine de 25 kilomètres carrés.
Les progrès récents dans la nouvelle synthèse de perspective ont considérablement amélioré notre capacité à capturer les champs de rayonnement neuronal (NeRF), rendant le processus plus accessible. Ces progrès nous permettent de reconstruire des scènes plus grandes et des détails plus fins. Que ce soit en augmentant l'échelle spatiale (par exemple, capturer des kilomètres d'un paysage urbain) ou en augmentant le niveau de détail (par exemple, scanner des brins d'herbe dans un champ), élargir la portée d'une scène capturée implique d'incorporer une plus grande quantité d'informations dans NeRF pour Réalisez une reconstruction précise. Par conséquent, pour les scènes riches en informations, le nombre de paramètres pouvant être entraînés requis pour la reconstruction peut dépasser la capacité de mémoire d'un seul GPU.
Cet article propose NeRF-XL, un algorithme de principe pour une distribution efficace des scènes radiales neuronales (NeRF) sur plusieurs GPU. La méthode décrite dans cet article permet de capturer des scènes à contenu informatif élevé (y compris des scènes avec des fonctionnalités à grande échelle et très détaillées) en augmentant simplement les ressources matérielles. Le cœur de NeRF-XL est d’attribuer les paramètres NeRF parmi un ensemble de régions spatiales disjointes et de les entraîner conjointement sur les GPU. Contrairement aux processus de formation distribués traditionnels qui synchronisent les gradients lors de la propagation vers l'arrière, notre méthode n'a besoin que de synchroniser les informations lors de la propagation vers l'avant. De plus, en restituant soigneusement les équations et les termes de perte associés dans un environnement distribué, nous réduisons considérablement le transfert de données requis entre les GPU. Cette nouvelle réécriture améliore la formation et l’efficacité du rendu. La flexibilité et l'évolutivité de cette méthode permettent à cet article d'optimiser efficacement plusieurs GPU et d'utiliser plusieurs GPU pour une optimisation efficace des performances.
Nos travaux contrastent avec les approches récentes qui ont adopté des algorithmes GPU pour modéliser des scènes à grande échelle en entraînant un ensemble de NeRF stéréoscopiques indépendants [9, 15, 17]. Bien que ces méthodes ne nécessitent pas de communication entre les GPU, chaque NeRF doit modéliser l'intégralité de l'espace, y compris les zones d'arrière-plan. Cela entraîne une redondance accrue de la capacité du modèle à mesure que le nombre de GPU augmente. De plus, ces méthodes nécessitent un mélange de NeRF lors du rendu, ce qui dégrade la qualité visuelle et introduit des artefacts dans les régions qui se chevauchent. Par conséquent, contrairement à NeRF-XL, ces méthodes utilisent davantage de paramètres de modèle dans l’entraînement (ce qui équivaut à davantage de GPU) et ne parviennent pas à améliorer la qualité visuelle.
Cet article démontre l'efficacité de notre approche à travers un ensemble diversifié de cas de capture, notamment des analyses de rues, des survols de drones et des vidéos centrées sur les objets. Les cas vont de petites scènes (10 mètres carrés) à des villes entières (25 kilomètres carrés). Nos expériences montrent qu'à mesure que nous allouons davantage de ressources informatiques au processus d'optimisation, NeRF-XL commence à améliorer la qualité visuelle (mesurée par le PSNR) et la vitesse de rendu. Par conséquent, NeRF-XL permet d’entraîner NeRF avec une capacité arbitraire sur des scènes de n’importe quelle échelle spatiale et de n’importe quel détail.

Figure 1 : L'algorithme de formation distribué multi-GPU basé sur le principe de cet article peut faire évoluer les NeRF à n'importe quelle grande échelle.

Figure 2 : Formation indépendante et formation conjointe multi-GPU. La formation de plusieurs NeRF [9, 15, 18] nécessite indépendamment que chaque NeRF modélise à la fois la région focale et son environnement, ce qui conduit à une redondance dans la capacité du modèle. En revanche, notre méthode de formation conjointe utilise des NeRF qui ne se chevauchent pas et ne présente donc aucune redondance.
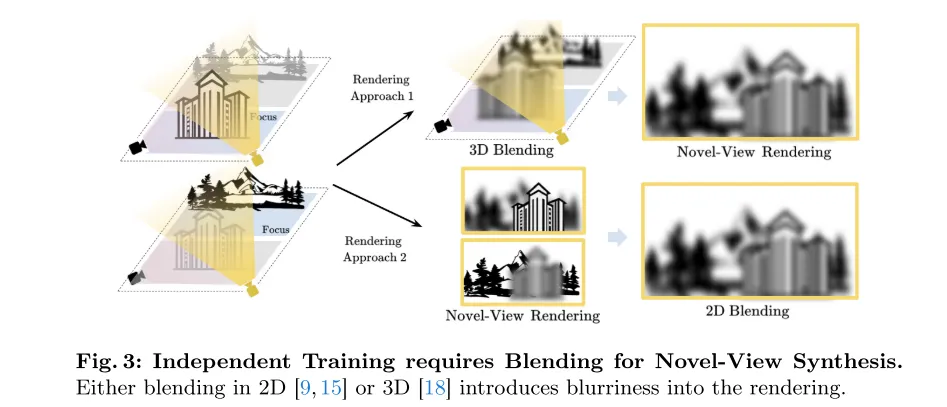
Figure 3 : La formation indépendante nécessite un mélange lorsque de nouvelles perspectives sont synthétisées. Que le mélange soit effectué en 2D [9, 15] ou en 3D [18], du flou sera introduit dans le rendu.
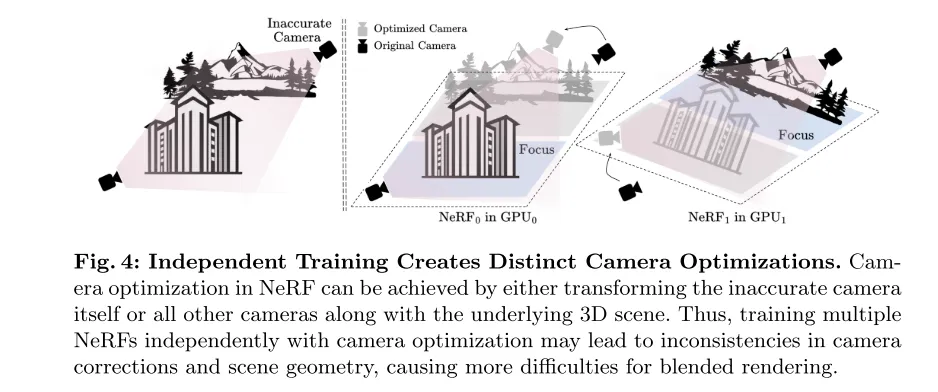
Figure 4 : Une formation indépendante conduit à différentes optimisations de caméra. Dans NeRF, l'optimisation de la caméra peut être obtenue en transformant la caméra imprécise elle-même ou toutes les autres caméras ainsi que la scène 3D sous-jacente. Par conséquent, la formation indépendante de plusieurs NeRF ainsi que l’optimisation de la caméra peuvent entraîner des incohérences dans les corrections de la caméra et la géométrie de la scène, ce qui entraîne davantage de difficultés pour le rendu hybride.
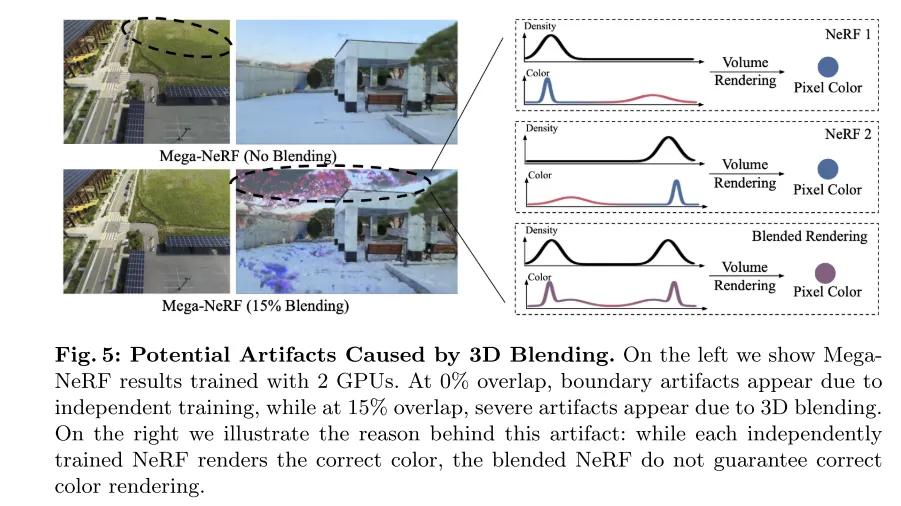
Figure 5 : Artefacts visuels pouvant être causés par le mélange 3D. L'image de gauche montre les résultats de MegaNeRF entraîné à l'aide de 2 GPU. À un chevauchement de 0 %, des artefacts apparaissent aux limites en raison d'un entraînement indépendant, tandis qu'à un chevauchement de 15 %, des artefacts importants apparaissent en raison du mélange 3D. L'image de droite illustre la cause de cet artefact : alors que chaque NeRF formé indépendamment restitue la couleur correcte, le NeRF mélangé ne garantit pas un rendu correct des couleurs.
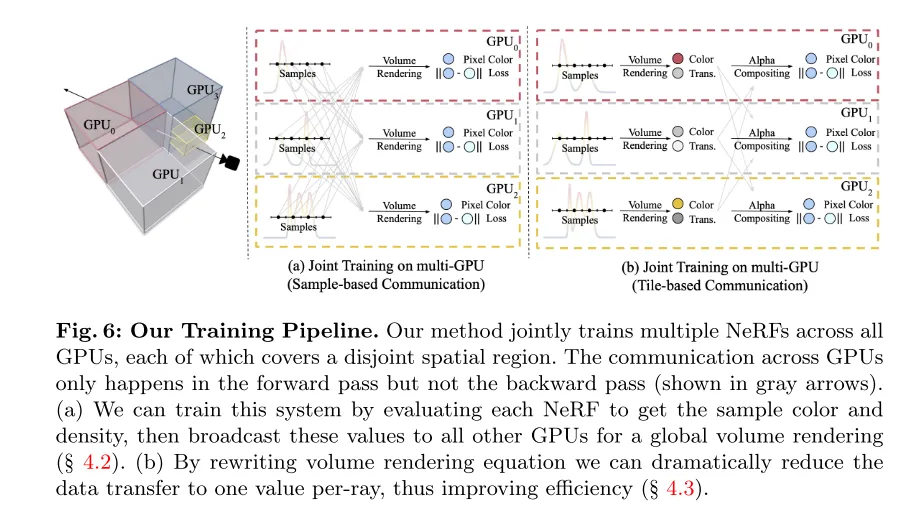
Figure 6 : Le processus de formation de cet article. Notre méthode entraîne conjointement plusieurs NeRF sur tous les GPU, chaque NeRF couvrant une région spatiale disjointe. La communication entre les GPU se produit uniquement en passe avant et non en passe arrière (comme indiqué par la flèche grise). (a) Cet article peut être mis en œuvre en évaluant chaque NeRF pour obtenir la couleur et la densité d'un échantillon, puis en diffusant ces valeurs à tous les autres GPU pour un rendu de volume global (voir section 4.2). (b) En réécrivant l'équation de rendu du volume, cet article peut réduire considérablement la quantité de transmission de données à une valeur par rayon, améliorant ainsi l'efficacité (voir section 4.3).

Figure 7 : Comparaison qualitative. Par rapport aux travaux précédents, notre méthode exploite efficacement les configurations multi-GPU et améliore les performances sur tous les types de données.
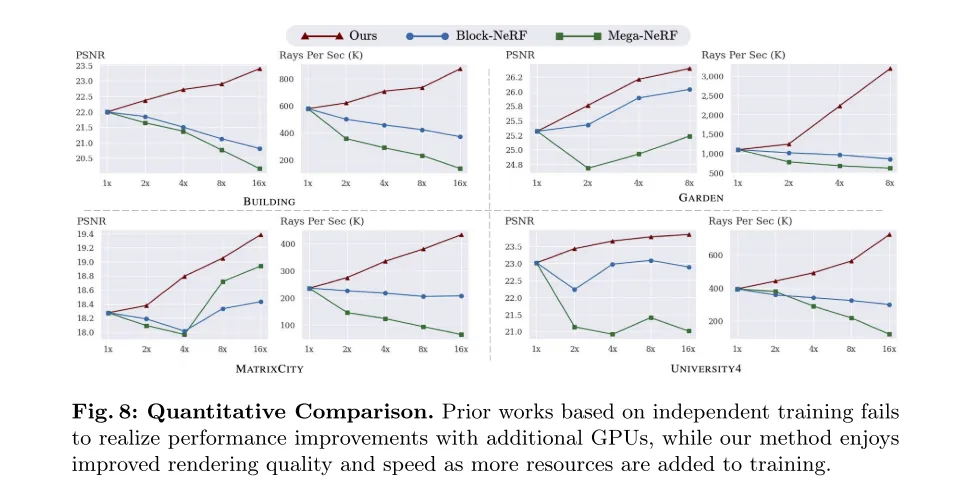
Figure 8 : Comparaison quantitative. Les travaux antérieurs basés sur une formation indépendante n'ont pas réussi à améliorer les performances avec l'ajout de GPU supplémentaires, tandis que notre méthode bénéficie d'améliorations en termes de qualité et de vitesse de rendu à mesure que les ressources de formation augmentent.

Figure 9 : Scalabilité de la méthode dans cet article. Un plus grand nombre de GPU permettent des paramètres plus apprenables, ce qui se traduit par une plus grande capacité de modèle et une meilleure qualité.

Figure 10 : Plus de résultats de rendu sur une capture à grande échelle. Cet article teste la robustesse de notre méthode sur un ensemble de données capturées plus vaste utilisant davantage de GPU. Veuillez consulter la page Web de cet article pour une visite vidéo de ces données.
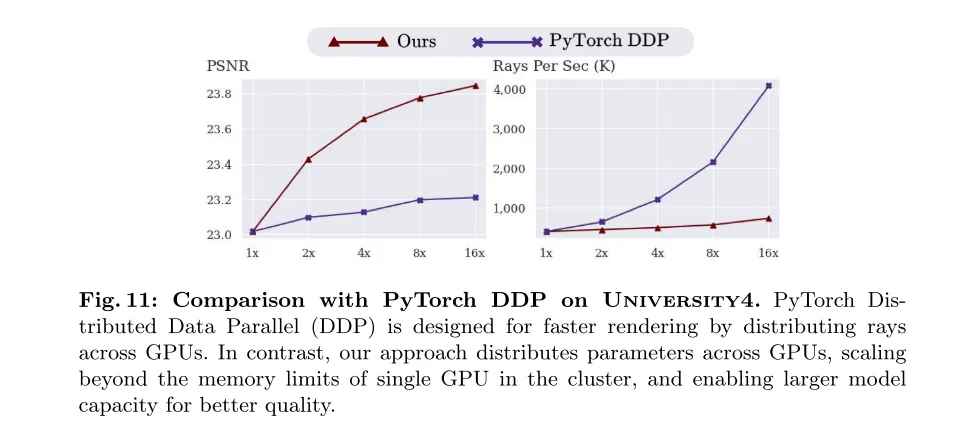
Figure 11 : Comparaison avec PyTorch DDP sur l'ensemble de données University4. PyTorch Distributed Data Parallel (DDP) est conçu pour accélérer le rendu en répartissant la lumière sur le GPU. En revanche, notre méthode distribue les paramètres entre les GPU, dépassant ainsi les limitations de mémoire d'un seul GPU dans le cluster et étant capable d'étendre la capacité du modèle pour une meilleure qualité.
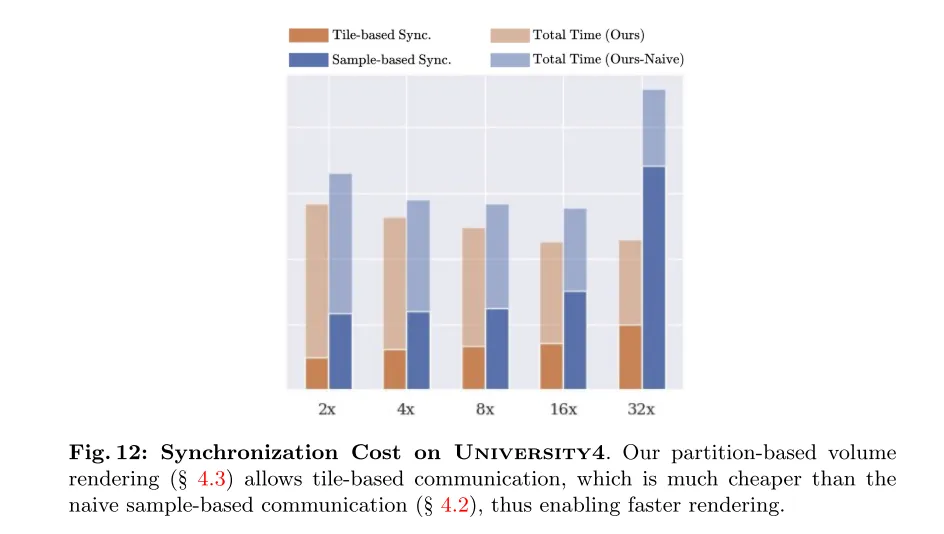
Figure 12 : Coût de synchronisation sur University4. Notre rendu de volume basé sur les partitions (voir Section 4.3) permet une communication basée sur les tuiles, qui est beaucoup moins coûteuse que la communication originale basée sur des échantillons (voir Section 4.2) et permet donc un rendu plus rapide.
En résumé, cet article revisite les méthodes existantes de décomposition de scènes à grande échelle en NeRF (Neural Radiation Fields) formés indépendamment et découvre des obstacles importants qui entravent l'utilisation efficace des ressources informatiques supplémentaires (GPU). ce qui contredit l’objectif principal consistant à exploiter les configurations multi-GPU pour améliorer les performances NeRF à grande échelle. Par conséquent, cet article présente NeRF-XL, un algorithme de principe capable d'exploiter efficacement les configurations multi-GPU et d'améliorer les performances NeRF à n'importe quelle échelle en entraînant conjointement plusieurs NeRF qui ne se chevauchent pas. Il est important de noter que notre méthode ne repose sur aucune règle heuristique et suit les lois de mise à l'échelle de NeRF dans un environnement multi-GPU et est applicable à différents types de données.
@misc{li2024nerfxl,title={NeRF-XL: Scaling NeRFs with Multiple GPUs}, author={Ruilong Li and Sanja Fidler and Angjoo Kanazawa and Francis Williams},year={2024},eprint={2404.16221},archivePrefix={arXiv},primaryClass={cs.CV}}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment gérer le ralentissement de l'ordinateur et la lenteur des réponses
Comment gérer le ralentissement de l'ordinateur et la lenteur des réponses
 mi-téléchargement
mi-téléchargement
 collection de codes HTML
collection de codes HTML
 Quels sont les hébergeurs virtuels php gratuits à l'étranger ?
Quels sont les hébergeurs virtuels php gratuits à l'étranger ?
 Comment récupérer des fichiers complètement supprimés sur un ordinateur
Comment récupérer des fichiers complètement supprimés sur un ordinateur
 Les mots disparaissent après avoir tapé
Les mots disparaissent après avoir tapé
 Quelles sont les applications de l'Internet des objets ?
Quelles sont les applications de l'Internet des objets ?
 Comment déclencher un événement de pression de touche
Comment déclencher un événement de pression de touche








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



