

Comment Ethereum Reth atteint-il 1 Go de gaz par seconde ? Nous avons commencé à construire Reth en 2022 pour fournir de l'élasticité à Ethereum L1 tout en résolvant le problème de mise à l'échelle de la couche d'exécution sur L2. Aujourd’hui, nous sommes ravis de partager comment Reth prévoit d’atteindre un débit L2 de 1 Go de gaz par seconde en 2024, ainsi que notre feuille de route à long terme sur la manière de dépasser cet objectif. Nous invitons l’ensemble de l’écosystème à se joindre à nous pour repousser les limites de la performance et une analyse comparative rigoureuse en matière de cryptographie. Aujourd'hui, l'éditeur de ce site Web vous donnera une introduction détaillée sur la façon dont Reth atteint 1 Go de gaz par seconde. Les amis qui aiment Ethereum Reth ne devraient pas le manquer !
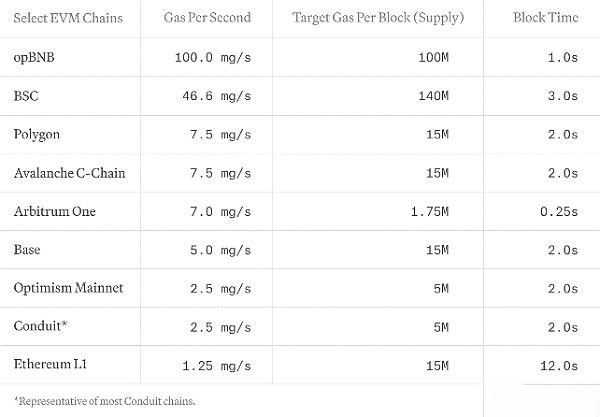
Nous mettons l'accent sur le gaz par seconde et l'utilisons pour évaluer de manière exhaustive les performances du réseau EVM tout en capturant les coûts de calcul et de stockage. Des réseaux comme Solana, Sui ou Aptos ne sont pas inclus en raison de leurs modèles de coûts uniques. Nous encourageons les efforts visant à harmoniser les modèles de coûts sur tous les réseaux blockchain afin de permettre des comparaisons complètes et équitables.
Nous développons une suite d'outils d'analyse comparative non-stop pour Reth afin de reproduire les charges de travail réelles. Notre exigence en matière de nœuds est de se conformer au benchmark TPC.
Une partie de notre motivation pour créer Reth en 2022 était que nous avions désespérément besoin d'un client spécialement conçu pour les rollups Web. Nous pensons que notre voie à suivre est prometteuse.
Reth atteint déjà 100 à 200 Mo de gaz par seconde lors de la synchronisation en direct (y compris la récupération de l'expéditeur, l'exécution des transactions et le calcul des essais pour chaque bloc, donc pour atteindre notre objectif à court terme de 1 Go de gaz par seconde), nous devons évoluer ; encore 10 fois.
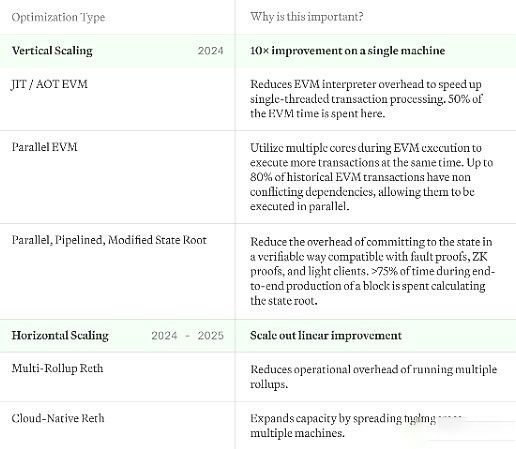
À mesure que Reth grandit, nos plans d'expansion doivent trouver un équilibre entre évolutivité et efficacité :
Expansion verticale : Notre objectif est de maximiser l'utilisation de chaque "box" à son plein potentiel. En optimisant la façon dont chaque système traite les transactions et les données, nous pouvons considérablement améliorer les performances globales tout en rendant les opérateurs de nœuds individuels plus efficaces.
Mise à l'échelle horizontale : malgré les optimisations, le volume des transactions à l'échelle du Web dépasse la capacité de traitement de n'importe quel serveur unique. Pour faire face à cette situation, nous avons envisagé de déployer une architecture de mise à l’échelle horizontale similaire au modèle Kubernetes de nœuds blockchain. Cela signifie répartir la charge de travail sur plusieurs systèmes pour garantir qu'aucun nœud ne puisse devenir un goulot d'étranglement.
L'optimisation dont nous discutons ici n'impliquera pas de solutions de croissance de l'État, cette partie est quelque chose que nous discuterons séparément dans d'autres articles. Voici un aperçu de nos plans pour y parvenir :
Tout au long de la pile technologique, nous avons également optimisé les E/S et le processeur à l'aide du modèle d'acteur, permettant à chaque partie de la pile d'être déployée en tant que service, et à granularité fine. contrôle de son utilisation. Enfin, nous évaluons activement des bases de données alternatives, mais n'en avons pas encore finalisé.
Notre objectif en matière de mise à l'échelle verticale est de maximiser les performances et l'efficacité du serveur ou de l'ordinateur portable exécutant Reth.
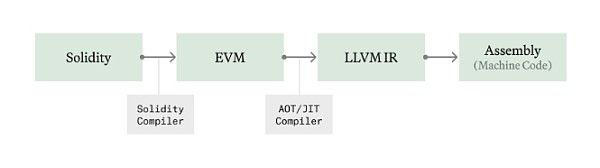
(1) EVM même (juste à temps) et EVM en avance (en avance sur le temps)
Dans un environnement blockchain comme la machine virtuelle Ethereum (EVM), l'exécution du bytecode se fait par interprétation Interprète (interprète), l'interprète traite les instructions en séquence. Cette méthode entraînera une certaine surcharge, car les instructions d'assemblage natives ne sont pas exécutées directement, mais l'opération est effectuée via la couche VM.
La compilation juste à temps (JIT) résout ce problème en convertissant le bytecode en code machine natif avant l'exécution, améliorant ainsi les performances en contournant le processus d'interprétation de la VM. Cette technologie peut compiler à l'avance les contrats dans un code machine optimisé et a été bien utilisée dans d'autres machines virtuelles telles que Java et WebAssembly.
Cependant, le JIT peut être vulnérable à un code malveillant conçu pour exploiter les vulnérabilités du processus JIT ou être trop lent pour s'exécuter en temps réel pendant l'exécution. Reth compilera à l'avance les contrats les plus exigeants (AOT) et les stockera sur le disque, empêchant ainsi le bytecode non fiable de tenter d'abuser de notre processus de compilation de code natif lors de l'exécution en direct.
Nous avons développé un compilateur JIT/AOT pour Revm et l'intégrons actuellement à Reth. Nous l'ouvrirons dès que nous aurons terminé les tests de référence dans les semaines à venir. En moyenne, environ 50 % du temps d'exécution est passé dans l'interpréteur EVM, donc une amélioration d'environ 2 fois de l'exécution EVM devrait être nécessaire, mais dans certains cas avec des exigences de calcul plus importantes, l'impact peut être plus important. Au cours des prochaines semaines, nous partagerons nos benchmarks et intégrerons notre propre JIT EVM à Reth.
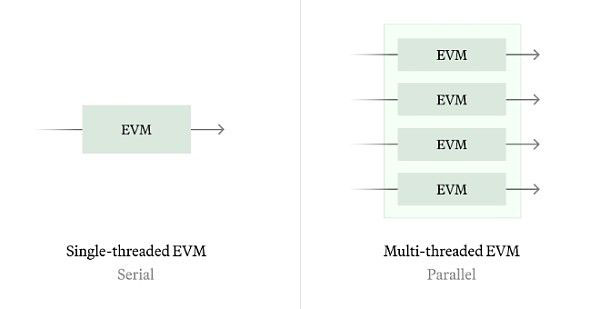
(2) Parallel EVM
Le concept de machine virtuelle Parallel Ethereum (Parallel EVM) prend en charge le traitement de plusieurs transactions en même temps, ce qui est différent du modèle d'exécution série EVM traditionnel. Nous avons les deux chemins suivants :
Synchronisation historique : La synchronisation historique nous permet de calculer le meilleur calendrier parallèle possible en analysant les transactions historiques et en identifiant tous les conflits d'état historiques.
Synchronisation en temps réel : pour la synchronisation en temps réel, nous pouvons utiliser une technologie telle que Block STM pour effectuer une exécution spéculative sans aucune information supplémentaire (telle que des listes d'accès). L'algorithme fonctionne mal pendant les périodes de conflits d'état graves, nous aimerions donc explorer la commutation entre l'exécution série et parallèle en fonction des conditions de charge de travail, ainsi que prédire statiquement à quels emplacements de stockage seront accédés pour améliorer la qualité du parallélisme.
Selon notre analyse historique, environ 80 % des emplacements de stockage Ethereum sont accessibles indépendamment, ce qui signifie que le parallélisme peut augmenter l'efficacité d'exécution de l'EVM de 5 fois.
(3) Optimisation de l'engagement de l'état
Dans le modèle Reth, le calcul de la racine de l'état est un processus indépendant de l'exécution des transactions, permettant l'utilisation du stockage KV standard sans obtenir d'informations trie. Cela prend actuellement plus de 75 % du temps de bout en bout pour sceller un bloc, ce qui constitue un domaine d'optimisation très intéressant.
Nous avons identifié les deux « gains faciles » suivants pour améliorer les performances de la racine d'état de 2 à 3 fois sans aucun changement de protocole :
Paralléliser entièrement la racine d'état : maintenant, nous la re-parallélisons simplement Calculer l'arborescence de stockage pour les comptes modifiés, mais nous pouvons aller plus loin et calculer l'arborescence des comptes en parallèle pendant que le travail racine de stockage se termine en arrière-plan.
Racine d'état pipeline : pendant l'exécution, les nœuds de tri intermédiaires sont préextraits du disque en informant le service racine d'état des emplacements de stockage et des comptes impliqués.
En plus de cela, nous pouvons également explorer certaines voies à suivre en s'écartant de l'activité racine d'état Ethereum L1 :
Calcul de racine d'état plus fréquent : ne calcule pas la racine d'état sur chaque bloc, mais tous les blocs T sont calculé une fois. Cela réduit le temps total passé à investir dans la racine d’état de l’ensemble du système, ce qui constitue probablement la solution la plus simple et la plus efficace.
Suivez la racine de l'état : au lieu de calculer la racine de l'état sur le même bloc, laissez-la être quelques blocs derrière. Cela permet à l'exécution d'avancer sans bloquer le calcul de la racine de l'état.
Remplacer l'encodeur RLP et Keccak256 : il peut être moins coûteux de fusionner les octets directement et d'utiliser une fonction de hachage plus rapide comme Blake3 que d'utiliser l'encodage RLP.
Trie plus large : augmentez la N-arité des nœuds enfants de l'arbre pour réduire l'augmentation des IO en raison de la profondeur logN du trie.
Quelques questions ici :
Quels sont les impacts secondaires des changements ci-dessus sur les clients légers, L2, les ponts, les coprocesseurs et autres protocoles qui s'appuient sur des comptes fréquents et une preuve de stockage ?
Pouvons-nous optimiser simultanément les engagements de l'État pour les preuves SNARK et la vitesse d'exécution native ?
Quel est l’engagement de l’État le plus large que nous puissions obtenir avec nos outils existants ? Quels sont les effets secondaires sur la taille des témoins ?
Nous exécuterons bon nombre des mesures ci-dessus tout au long de 2024 pour atteindre l'objectif de 1 Go de gaz par seconde.
Cependant, la mise à l’échelle verticale finit par se heurter à des limites physiques et pratiques. Aucune machine ne peut à elle seule répondre aux besoins informatiques mondiaux. Nous pensons qu'il existe ici deux voies qui peuvent nous aider à nous développer en introduisant plus de boîtes après l'augmentation de la charge :
(1) Multiple Rollup Reth
La pile L2 d'aujourd'hui doit exécuter plusieurs services pour suivre la chaîne : L1 CL, L1 Fonctions dérivées EL, L1 -> L2 (éventuellement regroupées avec L2 EL) et L2 EL. Bien que cela soit idéal pour la modularité, les choses deviennent plus compliquées lors de l'exécution de plusieurs piles de nœuds. Imaginez devoir exécuter 100 rollups !
Nous voulons permettre aux rollups d'être publiés simultanément à mesure que Reth évolue et réduire les coûts opérationnels liés à l'exécution de milliers de rollups à presque zéro.
Nous travaillons déjà là-dessus dans notre projet Execution Scaling, et d'autres seront à venir dans les semaines à venir.
(2) Reth natif du cloud
Les trieurs hautes performances peuvent avoir de nombreuses exigences sur une seule chaîne, ils doivent être mis à l'échelle et une seule machine ne peut pas répondre à leurs besoins. Cela n'est pas possible avec les déploiements actuels à nœud unique.
Nous espérons prendre en charge l'exécution de nœuds Reth natifs dans le cloud, les déployer en tant que pile de services qui peut automatiquement évoluer en fonction des besoins informatiques et utiliser un stockage d'objets cloud apparemment illimité pour le stockage persistant. Il s'agit d'une architecture courante dans les projets de bases de données sans serveur tels que NeonDB, CockroachDB ou Amazon Aurora.

Nous espérons déployer progressivement cette feuille de route auprès de tous les utilisateurs de Reth. Notre mission est de rendre 1 Go d'essence par seconde et plus accessible à tous. Nous testerons l'optimisation sur Reth AlphaNet et nous espérons que les gens utiliseront Reth comme SDK pour créer des nœuds hautes performances optimisés.
Il y a certaines questions auxquelles nous n’avons pas encore trouvé de réponses.
Comment Reth contribue-t-il à améliorer les performances de l'ensemble de l'écosystème L2 ?
Comment mesurer correctement les pires scénarios pouvant survenir avec certaines de nos optimisations en général ?
Comment gérer les éventuels désaccords entre L1 et L2 ?
Nous n’avons pas encore de réponses à beaucoup de ces questions, mais nous avons beaucoup de premières idées prometteuses qui nous occuperont pendant un moment, et nous espérons voir ces efforts se concrétiser dans les mois à venir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Qu'est-ce que la blockchain web3.0
Qu'est-ce que la blockchain web3.0
 Jusqu'où ira Ethereum ?
Jusqu'où ira Ethereum ?
 Cotations de prix Ethereum
Cotations de prix Ethereum
 Prix du marché d'Ethereum aujourd'hui
Prix du marché d'Ethereum aujourd'hui
 Que signifie STO dans la blockchain ?
Que signifie STO dans la blockchain ?
 Comment gagner de l'argent avec la blockchain
Comment gagner de l'argent avec la blockchain
 Découvrez les dix principales crypto-monnaies dans lesquelles il vaut la peine d'investir
Découvrez les dix principales crypto-monnaies dans lesquelles il vaut la peine d'investir
 Pourquoi ne puis-je pas accéder au navigateur Ethereum ?
Pourquoi ne puis-je pas accéder au navigateur Ethereum ?









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



