


Récemment, sous la direction du professeur Yan Shuicheng, le Kunlun Wanwei 2050 Global Research Institute, l'Université nationale de Singapour et l'équipe de l'Université technologique Nanyang de Singapour ont publié conjointement et open source le visuel universel au niveau des pixels Vitron grand modèle de langage multimodal .
Il s'agit d'un grand modèle multimodal visuel général robuste qui prend en charge une série de tâches visuelles allant de la compréhension visuelle à la génération visuelle, du niveau bas au niveau élevé, et résout le problème d'image qui a tourmenté le grand modèle de langage. industrie depuis longtemps. /Problème de fractionnement du modèle vidéo, fournit un grand modèle visuel multimodal général au niveau des pixels qui unifie complètement la compréhension, la génération, la segmentation, l'édition et d'autres tâches des images statiques et du contenu vidéo dynamique, jeter les bases de la prochaine génération de grands modèles visuels généraux. La forme ultime pose les bases et marque un autre grand pas vers l'intelligence artificielle (AGI) générale pour les grands modèles.
Vitron, en tant que grand modèle de langage visuel multimodal unifié au niveau des pixels, offre une prise en charge complète des tâches visuelles de bas niveau à haut niveau, est capable de gérer des tâches visuelles complexes, et Comprenez et générez du contenu image et vidéo, offrant de puissantes capacités de compréhension visuelle et d'exécution de tâches. Dans le même temps, Vitron prend en charge les opérations continues avec les utilisateurs, permettant une interaction homme-machine flexible, démontrant le grand potentiel vers un modèle universel multimodal visuel plus unifié.
Les articles, codes et démos liés à Vitronont tous été rendus publics Il a démontré des avantages et un potentiel uniques en termes d'exhaustivité, d'innovation technologique, d'interaction homme-machine et de potentiel d'application non. ne fait que promouvoir Il favorise non seulement le développement de grands modèles multimodaux, mais fournit également une nouvelle orientation pour la future recherche sur les grands modèles visuels.
Kunlun Wanwei2050Le Global Research Institute s'est engagé à construire une institution de recherche scientifique exceptionnelle pour le monde futur et à travailler avec la communauté scientifique pour traverser "la singularité ", explorez le monde inconnu, créez un avenir meilleur. Auparavant, Kunlun Wanwei 2050Global Research Institute a publié et open source la boîte à outils de recherche et développement d'agents numériquesAgentStudio À l'avenir, l'institut de recherche continuera à promouvoir l'intelligence artificielletechnique. percées, contribuant à la construction écologique de l’intelligence artificielle de la Chine. Le développement actuel des grands modèles de langage visuels (LLM) a fait des progrès gratifiants. La communauté croit de plus en plus que la construction de grands modèles multimodaux (MLLM) plus généraux et plus puissants sera le seul moyen de parvenir à une intelligence artificielle générale (AGI). Cependant, il reste encore quelques défis majeurs dans le processus d'évolution vers un modèle général multimodal (Généraliste). Par exemple, une grande partie du travail ne parvient pas à une compréhension visuelle fine au niveau des pixels, ou manque de prise en charge unifiée pour les images et les vidéos. Ou bien la prise en charge de diverses tâches visuelles est insuffisante, et c'est loin d'être un grand modèle universel. Afin de combler cette lacune, récemment, le Kunlun Worldwide 2050 Global Research Institute, l'Université nationale de Singapour et l'équipe de l'Université technologique de Nanyang de Singapour ont publié conjointement le modèle de grand langage visuel multimodal universel open source Vitron au niveau des pixels. . Vitron prend en charge une série de tâches visuelles allant de la compréhension visuelle à la génération visuelle, du niveau bas au niveau élevé, y compris la compréhension, la génération, la segmentation et l'édition complètes d'images statiques et de contenu vidéo dynamique.
Vitron a décrit de manière exhaustive le support fonctionnel de quatre tâches majeures liées à la vision. et ses principaux avantages. Vitron prend également en charge un fonctionnement continu avec les utilisateurs pour obtenir une interaction homme-machine flexible. Ce projet démontre le grand potentiel d’un modèle général multimodal de vision plus unifiée, jetant les bases de la forme ultime de la prochaine génération de grands modèles de vision générale. Les articles, codes et démos liés à Vitron sont désormais tous publics.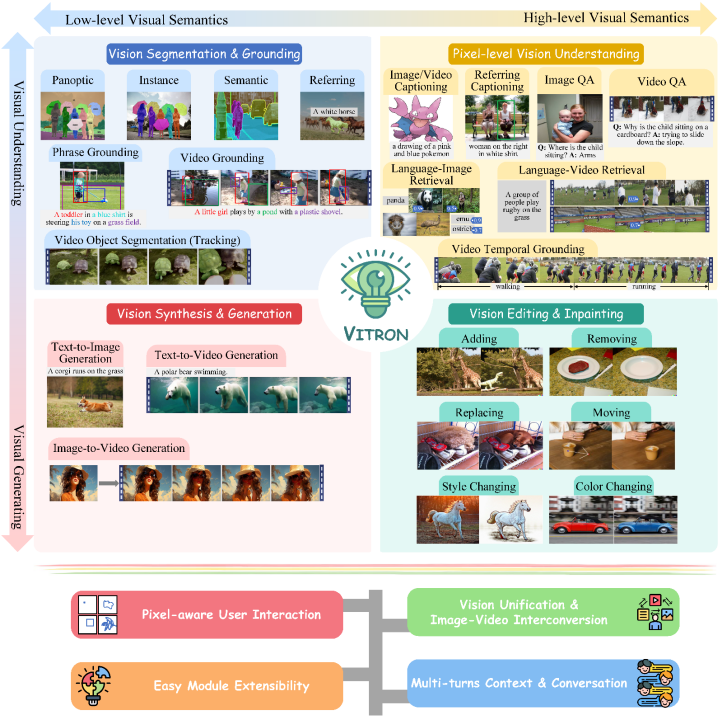
1
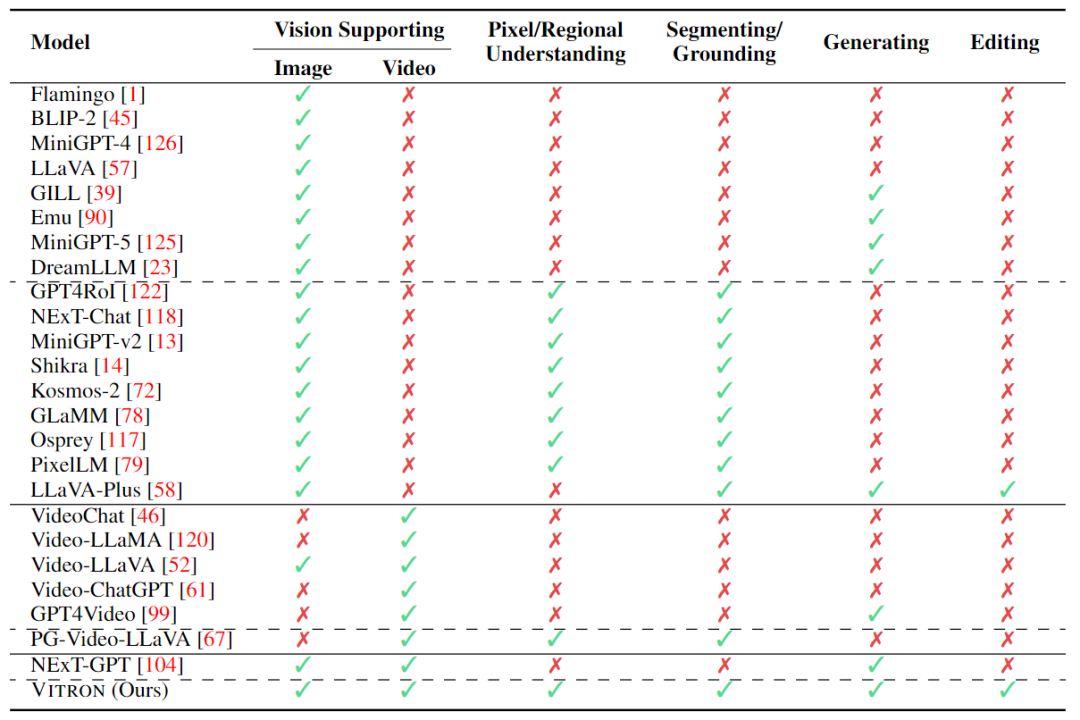
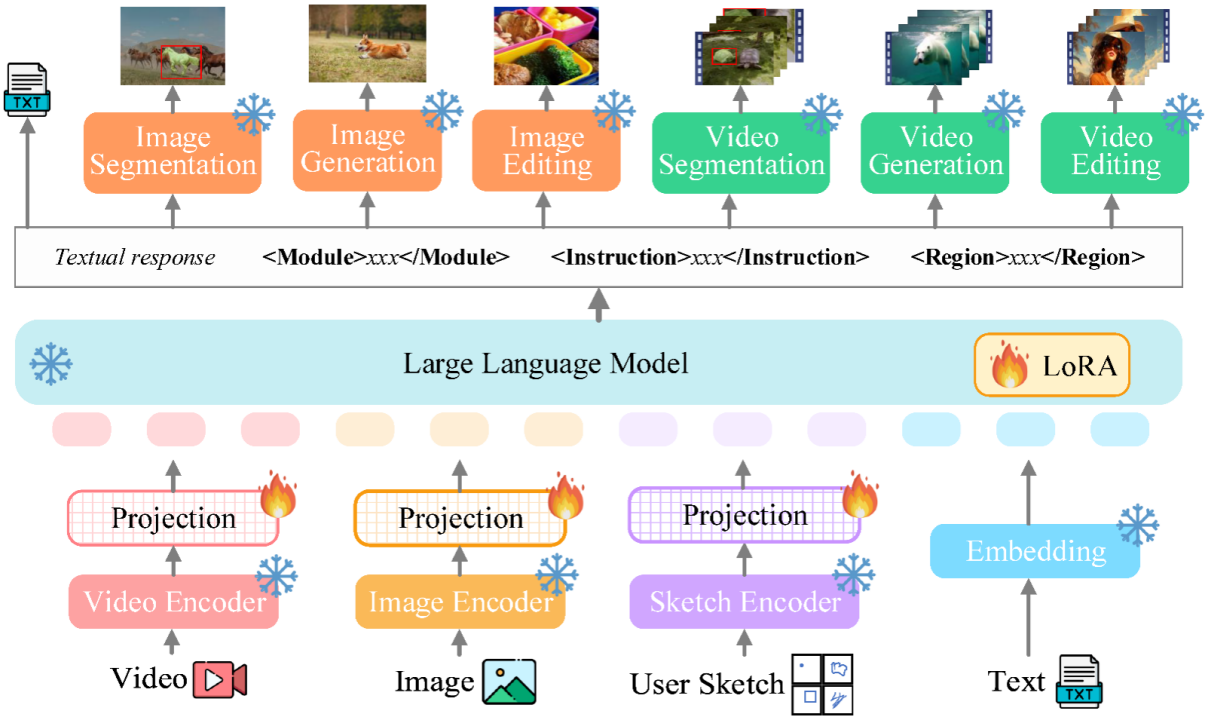
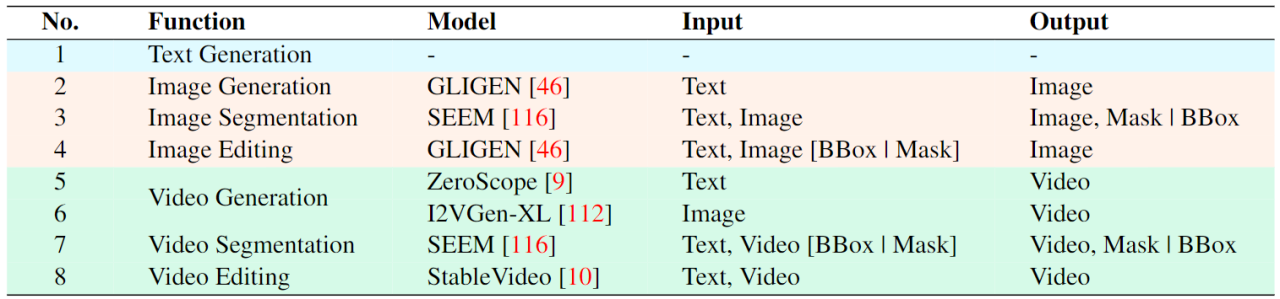
Le modèle de grand langage multimodal unifié ultime. Ces dernières années, les grands modèles de langage (LLM) ont démontré une puissance sans précédent et se sont progressivement révélés être la voie technique vers l'AGI. Les grands modèles multimodaux de langage (MLLM) se développent rapidement dans de nombreuses communautés et émergent rapidement. En introduisant des modules capables d'effectuer une perception visuelle, les LLM purement basés sur le langage sont étendus aux MLLM. De nombreux MLLM puissants et excellents dans la compréhension des images ont été développés. , tels que BLIP-2, LLaVA, MiniGPT-4, etc. Parallèlement, des MLLM axés sur la compréhension de la vidéo ont également été lancés, tels que VideoChat, Video-LLaMA, Video-LLaVA, etc. Par la suite, les chercheurs ont principalement tenté d'étendre davantage les capacités des MLLM à partir de deux dimensions. D'une part, les chercheurs tentent d'approfondir la compréhension de la vision par les MLLM, en passant d'une compréhension approximative au niveau de l'instance à une compréhension fine des images au niveau des pixels, obtenant ainsi des capacités de positionnement de région visuelle (Regional Grounding), telles que GLaMM, PixelLM. , NExT-Chat et MiniGPT-v2 etc. D’un autre côté, les chercheurs tentent d’étendre les fonctions visuelles que les MLLM peuvent prendre en charge. Certaines recherches ont commencé à étudier comment les MLLM non seulement comprennent les signaux visuels d'entrée, mais prennent également en charge la génération de contenu visuel de sortie. Par exemple, les MLLM tels que GILL et Emu peuvent générer du contenu d'image de manière flexible, et GPT4Video et NExT-GPT réalisent la génération de vidéo. À l'heure actuelle, la communauté de l'intelligence artificielle est progressivement parvenue à un consensus selon lequel la tendance future des MLLM visuels évoluera inévitablement dans le sens de capacités hautement unifiées et plus fortes. Cependant, malgré les nombreux MLLM développés par la communauté, une lacune évidente existe encore. Le tableau ci-dessus résume simplement les capacités du MLLM visuel existant (seuls certains modèles sont inclus de manière représentative et la couverture est incomplète). Pour combler ces lacunes, l'équipe propose Vitron, un MLLM visuel général au niveau des pixels. 02. Architecture du système Vitron : trois modules clés Le cadre global de Vitron est présenté dans la figure ci-dessous. Vitron adopte une architecture similaire aux MLLM associés existants, comprenant trois parties clés : 1) module d'encodage visuel et linguistique frontal, 2) module central de compréhension et de génération de texte du LLM, et 3) réponse de l'utilisateur back-end et appels de module pour le contrôle visuel. module. 03.VitronTrois étapes majeures de la formation du modèle Basé sur l'architecture ci-dessus, Vitron est formé et affiné pour lui donner de puissantes capacités de compréhension visuelle et d'exécution de tâches. La formation du modèle comprend principalement trois étapes différentes. 1) Sortie de réponse de l'utilisateur, répondant directement à la réponse de l'utilisateur. saisir . 2) Nom du module, indiquant la fonction ou la tâche à effectuer. 3) Appelez la commande pour déclencher la méta-instruction du module de tâches. 4) Région (sortie facultative) qui spécifie les fonctionnalités visuelles fines requises pour certaines tâches, comme le suivi vidéo ou l'édition visuelle, où les modules backend nécessitent ces informations. Pour les régions, sur la base de la compréhension au niveau des pixels de LLM, des cadres de délimitation décrits par des coordonnées seront générés. 04 Expériences d'évaluation Les chercheurs ont mené des évaluations expérimentales approfondies sur 22 ensembles de données de référence communs et 12 tâches de vision image/vidéo basées sur Vitron. Vitron démontre de solides capacités dans quatre grands groupes de tâches visuelles (segmentation, compréhension, génération et édition de contenu), tout en disposant de capacités flexibles d’interaction homme-machine. Ce qui suit montre de manière représentative quelques résultats de comparaison qualitative : Résultats de la segmentation de l'image référençant l'image Résultats de l'image compréhension d’expressions référentes . Résultats sur les résultats de l'édition vidéo Le système Vitron utilise toujours une approche semi-jointe et semi-agent pour appeler des outils externes. Bien que cette méthode basée sur les appels facilite l'expansion et le remplacement de modules potentiels, cela signifie également que les modules back-end de cette structure de pipeline ne participent pas à l'apprentissage conjoint des modules front-end et de base LLM. Cette limitation n'est pas propice à l'apprentissage global du système, ce qui signifie que la limite supérieure de performance des différentes tâches de vision sera limitée par les modules back-end. Les travaux futurs devraient intégrer divers modules de tâches de vision dans une unité unifiée. Parvenir à une compréhension et une production unifiées d’images et de vidéos tout en prenant en charge les capacités de génération et d’édition via un paradigme génératif unique reste un défi. Actuellement, une approche prometteuse consiste à combiner la tokenisation persistante en termes de modularité pour améliorer l'unification du système sur différentes entrées et sorties et diverses tâches. Contrairement aux modèles précédents qui se concentraient sur une tâche de vision unique (par exemple, Stable Diffusion et SEEM), Vitron vise à faciliter une interaction profonde entre LLM et les utilisateurs, similaire à OpenAI dans la série DALL-E de l'industrie. , Mi-parcours, etc. Atteindre une interactivité utilisateur optimale est l’un des objectifs principaux de ce travail. Vitron exploite les LLM basés sur le langage existants, combinés à des ajustements pédagogiques appropriés, pour atteindre un certain niveau d'interactivité. Par exemple, le système peut répondre de manière flexible à tout message attendu saisi par l'utilisateur et produire des résultats d'opération visuels correspondants sans exiger que l'entrée de l'utilisateur corresponde exactement aux conditions du module principal. Cependant, ce travail présente encore de nombreuses marges d'amélioration en termes de renforcement de l'interactivité. Par exemple, en s'inspirant du système Midjourney à source fermée, quelle que soit la décision prise par LLM à chaque étape, le système doit fournir activement des commentaires aux utilisateurs pour garantir que ses actions et décisions sont cohérentes avec les intentions des utilisateurs. Capacités modales Actuellement, Vitron intègre un modèle 7B Vicuna, qui peut avoir certaines limitations sur sa capacité à comprendre le langage, les images et les vidéos. Les orientations futures de l'exploration pourraient consister à développer un système complet de bout en bout, par exemple en élargissant l'échelle du modèle pour parvenir à une compréhension plus approfondie et plus complète de la vision. En outre, des efforts devraient être faits pour permettre au LLM d’unifier pleinement la compréhension des modalités de l’image et de la vidéo.

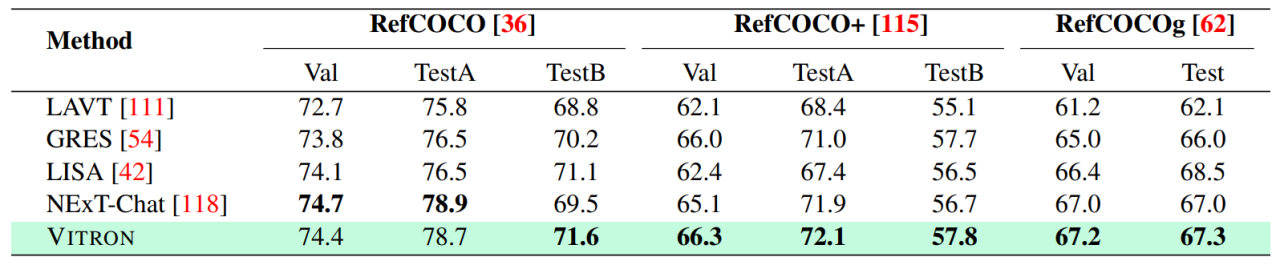

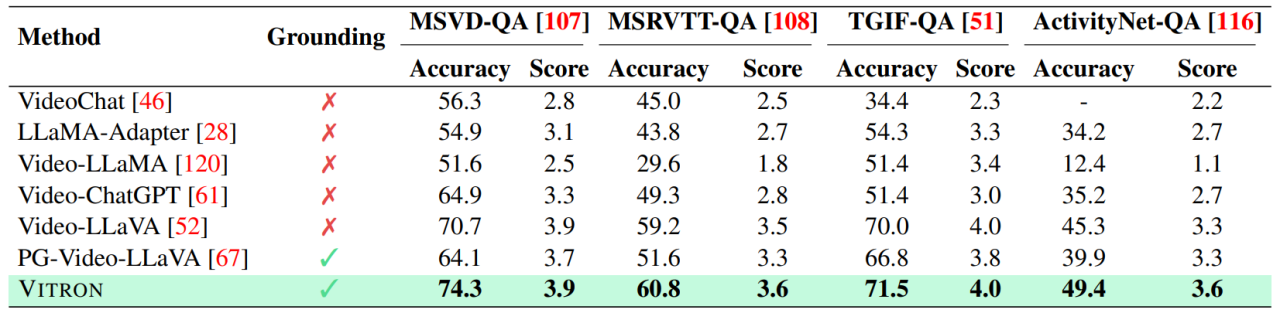
Contenu expérimental et détails plus détaillés Veuillez passer au document.
5
Future Direction Outlook
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



