


Actuellement, à mesure que la technologie de conduite autonome devient plus mature et que la demande de tâches de perception de conduite autonome augmente, l'industrie et le monde universitaire espèrent beaucoup un modèle d'algorithme de perception idéal qui puisse simultanément compléter tâches de détection de cibles tridimensionnelles et de segmentation sémantique basées sur l'espace BEV. Pour un véhicule capable de conduire de manière autonome, il est généralement équipé de capteurs de caméra à vision panoramique, de capteurs lidar et de capteurs radar à ondes millimétriques pour collecter des données selon différentes modalités. De cette manière, les avantages complémentaires entre les différentes données modales peuvent être pleinement exploités, de sorte que les avantages complémentaires des données entre les différentes modalités puissent être obtenus. Par exemple, les données de nuages de points 3D peuvent fournir des informations pour les tâches de détection de cibles 3D, tandis que les données d'images couleur. peut fournir plus d'informations pour les tâches de segmentation sémantique. Compte tenu des avantages complémentaires entre différentes données modales, en convertissant les informations efficaces de différentes données modales dans le même système de coordonnées, un traitement et une prise de décision conjoints ultérieurs sont facilités. Par exemple, les données de nuages de points 3D peuvent être converties en données de nuages de points basées sur l'espace BEV, et les données d'image des caméras à vision panoramique peuvent être projetées dans l'espace 3D grâce à l'étalonnage des paramètres internes et externes de la caméra, permettant ainsi un traitement unifié des données modales différentes. En tirant parti de différentes données modales, des résultats de perception plus précis peuvent être obtenus que des données modales uniques. Désormais, nous pouvons déjà déployer le modèle d'algorithme de perception multimodale sur la voiture pour produire des résultats de perception spatiale plus robustes et plus précis. Grâce à des résultats de perception spatiale précis, nous pouvons fournir une garantie plus fiable et plus sûre pour la réalisation des fonctions de conduite autonome.
Bien que de nombreux algorithmes de perception 3D pour la fusion de données multisensorielles et multimodales basés sur le cadre de réseau Transformer aient été récemment proposés dans le monde universitaire et l'industrie, ils utilisent tous le mécanisme d'attention croisée de Transformer pour réaliser l'intégration de données multimodales. fusion entre eux pour obtenir des résultats de détection de cible 3D idéaux. Cependant, ce type de méthode de fusion de fonctionnalités multimodale n’est pas totalement adapté aux tâches de segmentation sémantique basées sur l’espace BEV. De plus, en plus d'utiliser le mécanisme d'attention croisée pour compléter la fusion d'informations entre différentes modalités, de nombreux algorithmes utilisent la conversion vectorielle directe dans LSA pour construire des fonctionnalités fusionnées, mais il existe également certains problèmes comme suit : (Limitation du nombre de mots, une description détaillée suit ).
Compte tenu des nombreux problèmes mentionnés ci-dessus dans le processus de fusion multimodale qui peuvent affecter la capacité de perception du modèle final, et compte tenu des performances puissantes récemment démontrées par le modèle génératif, nous avons exploré le modèle génératif en utilisant Il est utilisé pour réaliser des tâches de fusion multimodale et de débruitage entre plusieurs capteurs. Sur cette base, nous proposons un algorithme de perception de modèle génératif DifFUSER basé sur la diffusion conditionnelle pour implémenter des tâches de perception multimodales. Comme le montre la figure ci-dessous, l'algorithme de fusion de données multimodales DifFUSER que nous avons proposé peut réaliser un processus de fusion multimodale plus efficace.  L'algorithme de fusion de données multimodales DifFUSER peut réaliser un processus de fusion multimodale plus efficace. La méthode comprend principalement deux étapes. Premièrement, nous utilisons des modèles génératifs pour débruiter et améliorer les données d’entrée, générant ainsi des données multimodales propres et riches. Ensuite, les données générées par le modèle génératif sont utilisées pour une fusion multimodale afin d'obtenir de meilleurs effets de perception. Les résultats expérimentaux de l'algorithme DifFUSER montrent que l'algorithme de fusion de données multimodal que nous avons proposé peut réaliser un processus de fusion multimodale plus efficace. Lors de la mise en œuvre de tâches de perception multimodale, cet algorithme peut réaliser un processus de fusion multimodale plus efficace et améliorer les capacités de perception du modèle. De plus, l'algorithme de fusion de données multimodales de l'algorithme peut réaliser un processus de fusion multimodale plus efficace. Dans l'ensemble
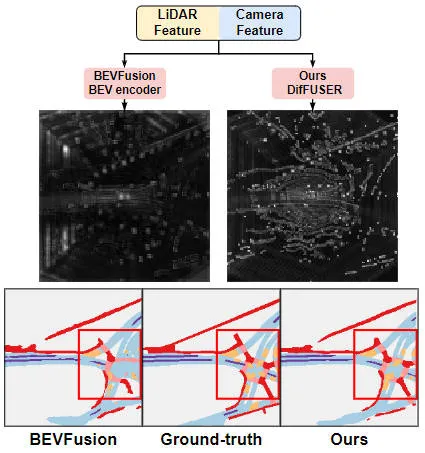
Tableau de comparaison visuel des résultats du modèle d'algorithme proposé et d'autres modèles d'algorithme
Lien papier : https://arxiv.org/pdf/2404.04629.pdf
"Détails du module de l'algorithme DifFUSER, algorithme de perception multitâche basé sur un modèle de diffusion conditionnelle" est un algorithme utilisé pour résoudre les problèmes de perception des tâches. La figure ci-dessous montre la structure globale du réseau de notre algorithme DifFUSER proposé. Dans ce module, nous proposons un algorithme de perception multitâche basé sur le modèle de diffusion conditionnelle pour résoudre le problème de perception des tâches. L'objectif de cet algorithme est d'améliorer les performances de l'apprentissage multitâche en diffusant et en agrégeant des informations spécifiques à une tâche dans le réseau. Intégration de l'algorithme DifFUSER
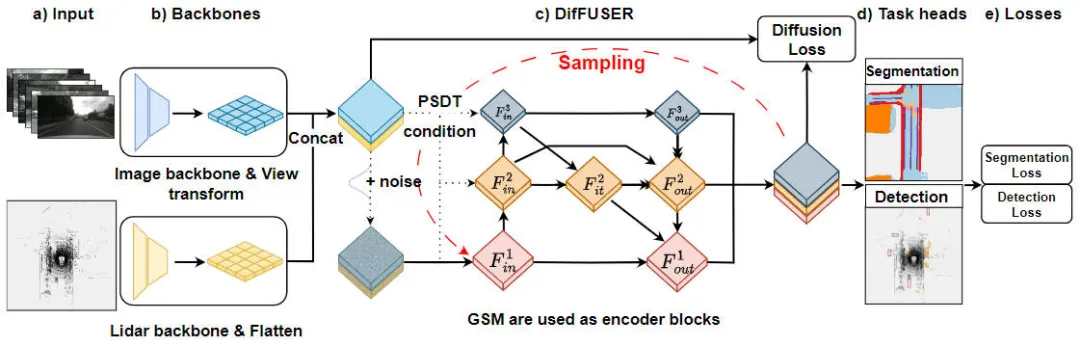 Schéma de structure de réseau du modèle d'algorithme de perception DifFUSER proposé
Schéma de structure de réseau du modèle d'algorithme de perception DifFUSER proposé
Comme le montre la figure ci-dessus, la structure de réseau DifFUSER que nous avons proposée comprend principalement trois sous-réseaux, à savoir la partie réseau fédérateur, la partie fusion de données multimodales de DifFUSER et la dernière partie BEV Head de la tâche de segmentation sémantique. Responsable d'une tâche de perception de détection d'objets 3D. Dans la partie réseau fédérateur, nous utilisons des architectures de réseau d'apprentissage en profondeur existantes, telles que ResNet ou VGG, pour extraire des fonctionnalités de haut niveau des données d'entrée. La partie fusion de données multimodales de DifFUSER utilise plusieurs branches parallèles, chaque branche est utilisée pour traiter différents types de données de capteurs (tels que les images, le lidar et le radar, etc.). Chaque branche possède sa propre partie de réseau fédérateur
Ensuite, nous présenterons soigneusement les détails de mise en œuvre de chaque sous-partie principale du modèle.
Pour les tâches de perception dans le système de conduite autonome, il est crucial que le modèle d'algorithme puisse percevoir l'environnement externe actuel en temps réel, il est donc très important pour garantir les performances et l’efficacité du module de diffusion. Par conséquent, nous nous inspirons du réseau pyramidal de fonctionnalités bidirectionnel et introduisons une architecture de diffusion BiFPN avec des conditions similaires, que nous appelons Conditional-Mini-BiFPN. Sa structure de réseau spécifique est illustrée dans la figure ci-dessus.


Pour un véhicule autonome, les performances du capteur d'acquisition de conduite autonome sont cruciales Lors de la conduite quotidienne du véhicule autonome, il est très probable que le. Le capteur de caméra ou le capteur lidar sera bloqué ou fonctionnera mal, ce qui affectera la sécurité et l'efficacité de fonctionnement du système de conduite autonome final. Sur la base de cette considération, nous avons proposé un paradigme de formation progressive à l'abandon du capteur pour améliorer la robustesse et l'adaptabilité du modèle d'algorithme proposé dans les situations où le capteur peut être bloqué.
Grâce à notre paradigme de formation à l'abandon progressif des capteurs proposé, le modèle d'algorithme peut reconstruire les caractéristiques manquantes en utilisant la distribution de deux données modales collectées par les capteurs de caméra et les capteurs lidar, obtenant ainsi une excellente adaptation dans des conditions difficiles, en termes de performances et de robustesse. Plus précisément, nous exploitons les fonctionnalités des données d'image et des données de nuages de points lidar de trois manières différentes, en tant que cibles d'entraînement, entrée de bruit dans le module de diffusion et pour simuler les conditions dans lesquelles un capteur est perdu ou défectueux. Pour simuler des conditions de perte ou de défaillance du capteur. nous augmentons progressivement le taux de perte d'entrée du capteur de caméra ou du capteur lidar de 0 à une valeur maximale prédéfinie a = 25 pendant l'entraînement. L'ensemble du processus peut être exprimé par la formule suivante :
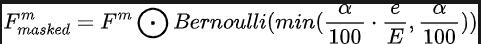
Parmi eux, représente le nombre de cycles de formation dans lesquels se trouve le modèle actuel et définit la probabilité d'abandon pour représenter la probabilité que chaque fonctionnalité soit abandonnée. Grâce à ce processus de formation progressif, le modèle est non seulement entraîné à débruiter efficacement et à générer des caractéristiques plus expressives, mais minimise également sa dépendance à l'égard d'un seul capteur, améliorant ainsi sa gestion des capteurs incomplets avec une plus grande résilience des données.

Plus précisément, la structure du réseau du module de diffusion de modulation à auto-conditionnement à grille est illustrée dans la figure ci-dessous
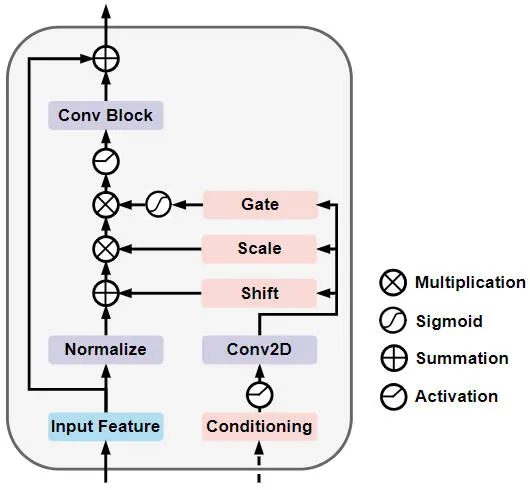
Auto-conditionné à grille Modulation Diffusion Diagramme schématique de la structure du réseau de modules

Afin de vérifier les résultats perceptuels de notre modèle d'algorithme proposé DifFUSER sur des tâches multi-tâches, nous avons principalement effectué sur l'ensemble de données nuScenes, expériences de détection de cibles 3D et de segmentation sémantique basées sur l'espace BEV.
Tout d'abord, nous avons comparé les performances du modèle d'algorithme proposé DifFUSER avec d'autres algorithmes de fusion multimodaux sur des tâches de segmentation sémantique. Les résultats expérimentaux spécifiques sont présentés dans le tableau suivant :
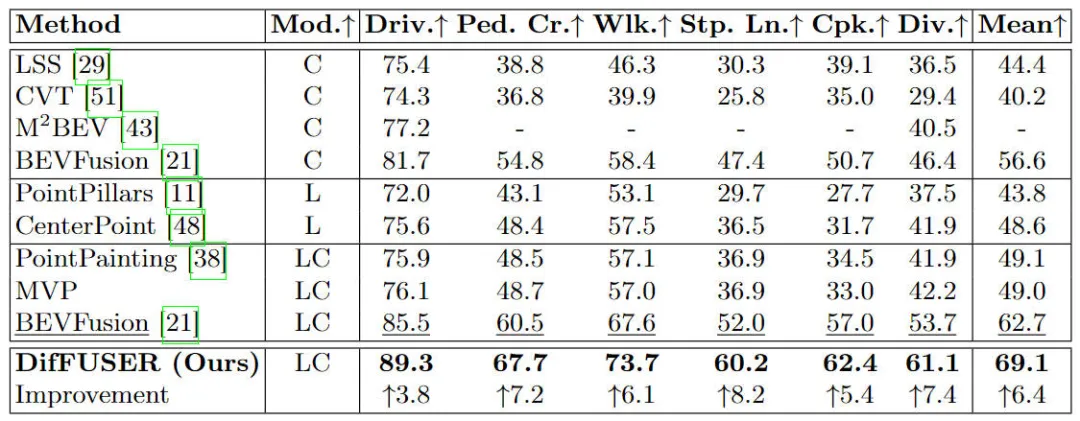 Différents modèles d'algorithmes sur l'ensemble de données nuScenes Comparaison de. résultats expérimentaux des tâches de segmentation sémantique basées sur l'espace BEV
Différents modèles d'algorithmes sur l'ensemble de données nuScenes Comparaison de. résultats expérimentaux des tâches de segmentation sémantique basées sur l'espace BEV
Les résultats expérimentaux montrent que le modèle d'algorithme que nous avons proposé a considérablement amélioré les performances par rapport au modèle de base. Plus précisément, la valeur mIoU du modèle BEVFusion n'est que de 62,7 %, tandis que le modèle d'algorithme que nous avons proposé a atteint 69,1 %, avec une amélioration de 6,4 %, ce qui montre que l'algorithme que nous avons proposé présente plus d'avantages dans différentes catégories. De plus, la figure ci-dessous illustre également de manière plus intuitive les avantages du modèle d'algorithme que nous avons proposé. Plus précisément, l'algorithme BEVFusion produira de mauvais résultats de segmentation, en particulier dans les scénarios longue distance, où le désalignement des capteurs est plus évident. En comparaison, notre modèle d’algorithme donne des résultats de segmentation plus précis, avec des détails plus évidents et moins de bruit.
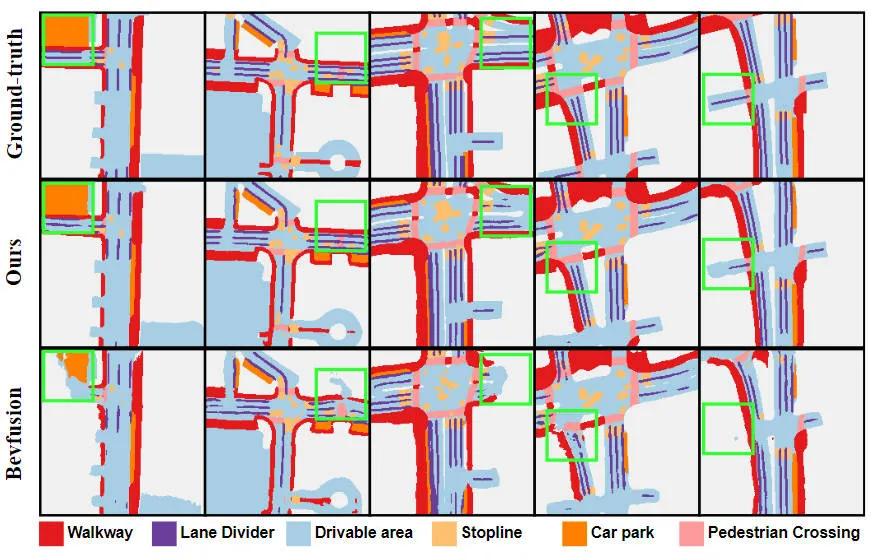
Comparaison des résultats de visualisation de segmentation du modèle d'algorithme proposé et du modèle de base
De plus, nous avons également comparé le modèle d'algorithme proposé avec d'autres modèles d'algorithme de détection de cibles 3D. Les résultats expérimentaux spécifiques sont présentés dans le tableau ci-dessous.
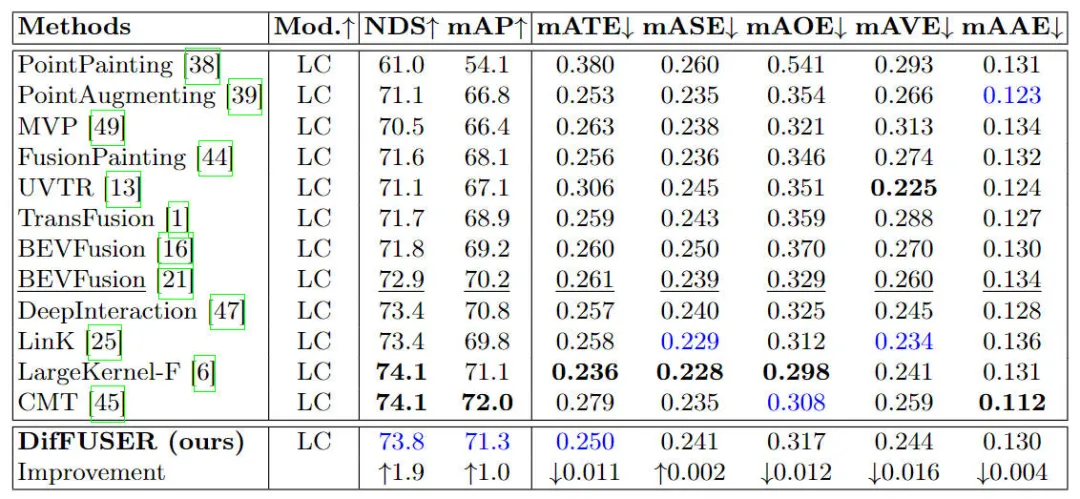
Comparaison des résultats expérimentaux de différents modèles d'algorithme sur la tâche de détection de cible 3D sur l'ensemble de données nuScenes
Comme le montrent les résultats répertoriés dans le tableau, notre modèle d'algorithme proposé DifFUSER a de meilleures performances à la fois en NDS et en mAP indicateurs que le modèle de base. Par rapport aux 72,9 % NDS et 70,2 % mAP du modèle de base BEVFusion, notre modèle d'algorithme est respectivement 1,8 % et 1,0 % plus élevé. L'amélioration des indicateurs pertinents montre que le module de fusion par diffusion multimodale que nous avons proposé est efficace dans le processus de réduction et de raffinement des caractéristiques.
De plus, afin de montrer la robustesse perceptuelle du modèle d'algorithme proposé en cas de défaillance ou d'occlusion du capteur, nous avons comparé les résultats des tâches de segmentation associées, comme le montre la figure ci-dessous.
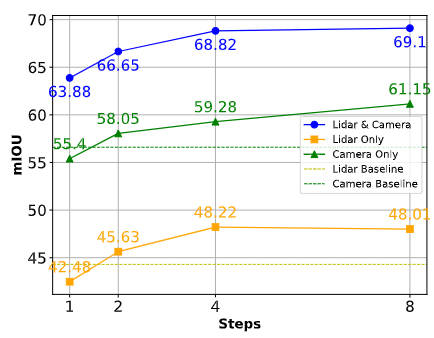
Comparaison des performances de l'algorithme dans différentes situations
Comme le montre la figure ci-dessus, lorsque l'échantillonnage est suffisant, le modèle d'algorithme que nous proposons peut compenser efficacement les fonctionnalités manquantes et être utilisé comme base pour la collecte de capteurs manquants. informations. Contenu alternatif. La capacité de notre modèle d'algorithme DifFUSER proposé à générer et à utiliser des fonctionnalités synthétiques atténue efficacement la dépendance à l'égard d'une modalité de capteur unique et garantit que le modèle peut fonctionner sans problème dans des environnements divers et difficiles.
La figure suivante montre la visualisation des résultats de détection de cible 3D et de segmentation sémantique de l'espace BEV de notre modèle d'algorithme DifFUSER proposé. Il ressort des résultats de visualisation que le modèle d'algorithme que nous avons proposé est bon. Détection et effet Split.

Cet article propose un modèle d'algorithme de perception multimodale DifFUSER basé sur le modèle de diffusion, qui améliore la qualité de fusion du modèle de réseau en améliorant l'architecture de fusion du modèle de réseau et en utilisant les propriétés de débruitage du modèle de diffusion. Les résultats expérimentaux sur l'ensemble de données Nuscenes montrent que le modèle d'algorithme que nous avons proposé atteint des performances de segmentation SOTA dans la tâche de segmentation sémantique de l'espace BEV et peut atteindre des performances de détection similaires au modèle d'algorithme SOTA actuel dans la tâche de détection de cible 3D.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quels sont les opérateurs en langage Go ?
Quels sont les opérateurs en langage Go ?
 Que dois-je faire si le navigateur IE affiche une erreur de script ?
Que dois-je faire si le navigateur IE affiche une erreur de script ?
 que signifie la concentration
que signifie la concentration
 Quatre caractéristiques majeures de la blockchain
Quatre caractéristiques majeures de la blockchain
 Comment récupérer des fichiers qui ont été vidés de la corbeille
Comment récupérer des fichiers qui ont été vidés de la corbeille
 Que faire si l'ordinateur n'a pas de son
Que faire si l'ordinateur n'a pas de son
 Site de trading Bitcoin
Site de trading Bitcoin
 Que sont les éditeurs de texte Java ?
Que sont les éditeurs de texte Java ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



