


En tant que base de la technologie d'apprentissage profond, les réseaux de neurones ont obtenu des résultats efficaces dans de nombreux domaines d'application. En pratique, l'architecture réseau peut affecter considérablement l'efficacité de l'apprentissage. Une bonne architecture de réseau neuronal peut intégrer une connaissance préalable du problème, établir une formation réseau et améliorer l'efficacité informatique. Actuellement, les méthodes classiques de conception d'architecture de réseau incluent la conception manuelle, la recherche d'architecture de réseau neuronal (NAS) [1] et les méthodes de conception de réseau basées sur l'optimisation [2]. Architectures de réseau conçues artificiellement telles que ResNet, etc. ; la recherche d'architecture de réseau neuronal recherche la meilleure structure de réseau dans l'espace de recherche par le biais de la recherche ou de l'apprentissage par renforcement ; un paradigme courant dans les méthodes de conception basées sur l'optimisation est le déroulement d'algorithmes. Cette méthode conçoit généralement le réseau. structure du point de vue d’un algorithme d’optimisation avec une fonction objectif explicite. Ces méthodes conçoivent la structure du réseau du point de vue de l'algorithme d'optimisation tout en concevant la structure du réseau du point de vue de l'algorithme d'optimisation.
De nos jours, la plupart des conceptions classiques d'architecture de réseaux de neurones ignorent l'approximation universelle du réseau - c'est l'un des facteurs clés de la puissante performance des réseaux de neurones. Ces méthodes de conception perdent donc dans une certaine mesure la garantie a priori de performance du réseau. Bien que le réseau neuronal à deux couches ait des propriétés d’approximation universelles lorsque la largeur tend vers l’infini [3], en pratique, nous ne pouvons généralement considérer que des structures de réseau de largeur limitée, et les résultats de l’analyse des performances dans ce domaine sont très limités. En fait, il est difficile de considérer la propriété d’approximation universelle dans la conception de réseaux, qu’il s’agisse d’une conception heuristique artificielle ou d’une recherche d’architecture de réseau neuronal en boîte noire. Bien que la conception de réseaux neuronaux basée sur l’optimisation soit relativement plus interprétable, elle nécessite généralement une fonction objective évidente, ce qui se traduit par une variété limitée de structures de réseau conçues et limite son champ d’application. Comment concevoir systématiquement des architectures de réseaux neuronaux avec des propriétés d’approximation universelles reste un problème important.
L'équipe du professeur Lin Zhouchen de l'Université de Pékin a proposé une architecture de réseau neuronal basée sur des outils de conception d'algorithmes d'optimisation. Cette méthode améliore la vitesse d'entraînement en combinant l'algorithme d'optimisation du premier ordre basé sur le gradient avec l'algorithme d'optimisation du second ordre basé sur le hachage. algorithme d'optimisation et de convergence, et améliore la garantie de robustesse du réseau neuronal. Ce module de réseau neuronal peut également être utilisé avec les méthodes de conception de réseau existantes basées sur la modularité et continue d'améliorer les performances du modèle. Récemment, ils ont analysé les propriétés d'approximation des équations différentielles des réseaux neuronaux (NODE) et ont prouvé que les réseaux de neurones connectés entre couches ont des propriétés d'approximation universelles. Ils ont également utilisé le cadre proposé pour concevoir des réseaux variantes tels que ConvNext et ViT, et ont obtenu des résultats. qui a dépassé la ligne de base. L'article a été accepté par TPAMI, la principale revue sur l'intelligence artificielle.

Les méthodes traditionnelles de conception de réseaux neuronaux basées sur l'optimisation partent souvent d'une fonction objectif avec une expression explicite, utilisent un algorithme d'optimisation spécifique pour la résoudre, puis mappent les résultats de l'optimisation sur une structure de réseau neuronal, telle que la célèbre LISTA. - NN est une expression explicite obtenue en utilisant l'algorithme LISTA pour résoudre le problème LASSO, et transforme les résultats d'optimisation en une structure de réseau neuronal [4]. Cette méthode dépend fortement de l'expression explicite de la fonction objectif, de sorte que la structure de réseau résultante ne peut être optimisée que pour l'expression explicite de la fonction objectif, et il existe un risque de concevoir des hypothèses qui ne sont pas conformes à la situation réelle. Certains chercheurs tentent de concevoir la structure du réseau en personnalisant la fonction objectif, puis en utilisant des méthodes telles que l'expansion d'algorithmes, mais ils nécessitent également des hypothèses telles que la rereliure des poids qui ne correspondent pas nécessairement aux hypothèses des situations réelles. Par conséquent, certains chercheurs ont proposé d'utiliser des algorithmes évolutifs basés sur des réseaux de neurones pour rechercher une architecture de réseau afin d'obtenir une structure de réseau plus raisonnable.
Le format mis à jour du plan de conception de l'architecture du réseau devrait suivre l'idée dede l'algorithme d'optimisation de premier ordre à l'algorithme du point le plus proche et effectuer une optimisation progressive. Par exemple, l'algorithme de l'angle d'Euler peut être remplacé par l'algorithme des quaternions, ou un algorithme itératif plus efficace peut être utilisé pour approximer la solution. Le format mis à jour devrait envisager d’augmenter la précision des calculs et d’améliorer l’efficacité opérationnelle.
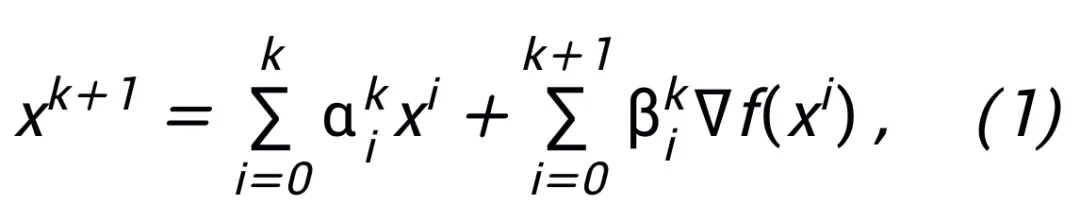
où 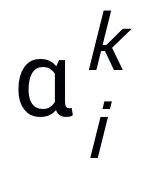 et
et 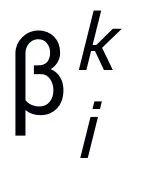 représentent le coefficient (taille du pas) à la kième mise à jour de l'étape, puis remplacez le terme de gradient par le module apprenable T dans le réseau neuronal pour obtenir le squelette du réseau neuronal de la couche L :
représentent le coefficient (taille du pas) à la kième mise à jour de l'étape, puis remplacez le terme de gradient par le module apprenable T dans le réseau neuronal pour obtenir le squelette du réseau neuronal de la couche L :
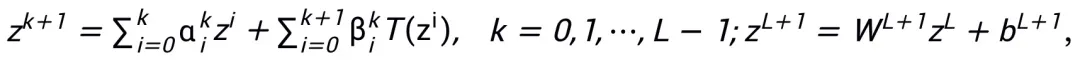
Le cadre global de la méthode est présenté dans la figure 1.
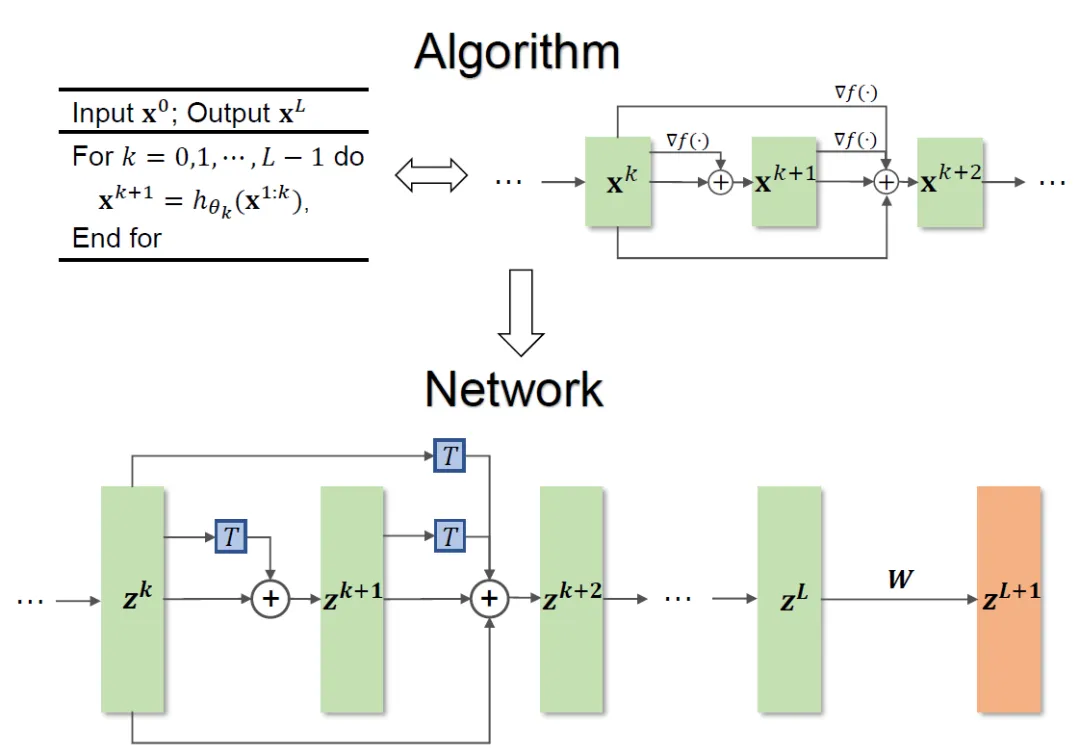
Figure 1 Illustration de la conception de réseau
La méthode proposée dans l'article peut inspirer la conception de réseaux classiques tels que ResNet et DenseNet, et résout le problème que les méthodes traditionnelles basées sur l'optimisation de la conception de l'architecture de réseau sont limités à des fonctions objectives spécifiques.
Sélection du module et détails architecturaux
Le module réseau T conçu par cette méthode ne nécessite qu'une structure de réseau à deux couches, c'est-à-dire 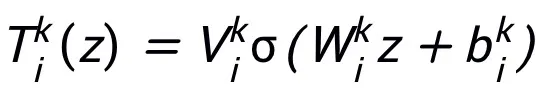 , comme sous-structure, il peut garantir que le réseau conçu a La propriété d'approximation universelle, dans laquelle la largeur de la couche exprimée est limitée (c'est-à-dire qu'elle n'augmente pas avec l'amélioration de la précision de l'approximation), et la propriété d'approximation universelle de l'ensemble du réseau n'est pas obtenue en élargissant la
, comme sous-structure, il peut garantir que le réseau conçu a La propriété d'approximation universelle, dans laquelle la largeur de la couche exprimée est limitée (c'est-à-dire qu'elle n'augmente pas avec l'amélioration de la précision de l'approximation), et la propriété d'approximation universelle de l'ensemble du réseau n'est pas obtenue en élargissant la 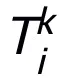 couches. Le module T peut être le bloc de pré-activation largement utilisé dans ResNet, ou il peut s'agir de la structure de couche attention + feedforward dans Transformer. La fonction d'activation dans T peut être des fonctions d'activation courantes telles que ReLU, GeLU, Sigmoid, etc. Des couches de normalisation correspondantes peuvent également être ajoutées en fonction de tâches spécifiques. De plus, lorsque
couches. Le module T peut être le bloc de pré-activation largement utilisé dans ResNet, ou il peut s'agir de la structure de couche attention + feedforward dans Transformer. La fonction d'activation dans T peut être des fonctions d'activation courantes telles que ReLU, GeLU, Sigmoid, etc. Des couches de normalisation correspondantes peuvent également être ajoutées en fonction de tâches spécifiques. De plus, lorsque 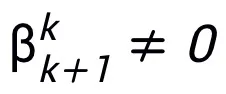 , le réseau conçu est un réseau implicite [5], et la méthode d'itération en virgule fixe peut être utilisée pour approximer le format implicite, ou la méthode de différenciation implicite peut être utilisée pour résoudre le gradient pour la mise à jour.
, le réseau conçu est un réseau implicite [5], et la méthode d'itération en virgule fixe peut être utilisée pour approximer le format implicite, ou la méthode de différenciation implicite peut être utilisée pour résoudre le gradient pour la mise à jour.
Concevoir plus de réseaux grâce à une représentation équivalente
Cette méthode ne nécessite pas que le même algorithme ne puisse correspondre qu'à une seule structure. Au contraire, cette méthode peut utiliser la représentation équivalente de problèmes d'optimisation pour concevoir plus de réseaux. architectures, reflétant sa flexibilité. Par exemple, la méthode du multiplicateur de direction alternée linéarisé est souvent utilisée pour résoudre des problèmes d'optimisation sous contrainte : 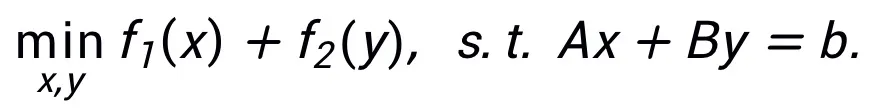 En laissant
En laissant 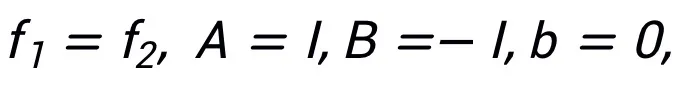 nous pouvons obtenir un format d'itération mis à jour qui peut inspirer le réseau :
nous pouvons obtenir un format d'itération mis à jour qui peut inspirer le réseau :
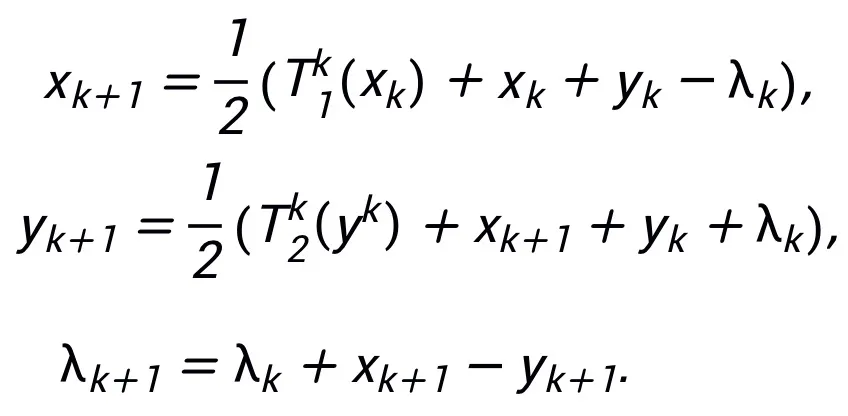
La structure du réseau inspiré Voir la figure 2.

Figure 2 Structure de réseau inspirée de la méthode du multiplicateur de direction alternée linéarisée
Le réseau inspiré a des propriétés d'approximation universelles
Die mit dieser Methode entworfene Netzwerkarchitektur kann beweisen, dass das von einem Optimierungsalgorithmus erster Ordnung inspirierte neuronale Netzwerk unter der Bedingung, dass das Modul die vorherigen Bedingungen erfüllt und der Optimierungsalgorithmus (im Allgemeinen) stabil und konvergent ist, Folgendes aufweist Eigenschaften im hochdimensionalen kontinuierlichen Funktionenraum Alle Approximationseigenschaften sind angegeben und die Approximationsgeschwindigkeit ist angegeben. Zum ersten Mal beweist die Arbeit die universellen Approximationseigenschaften neuronaler Netze mit allgemeinen schichtübergreifenden Verbindungen unter der Einstellung „begrenzte Breite“ (frühere Forschungen konzentrierten sich hauptsächlich auf FCNN und ResNet, siehe Tabelle 1). kurz wie folgt beschrieben werden:
Hauptsatz (Kurzfassung): Sei A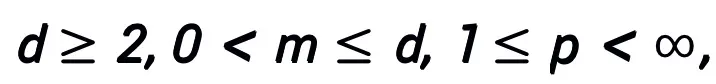 ein Gradientenoptimierungsalgorithmus erster Ordnung. Wenn Algorithmus A das Aktualisierungsformat in Formel (1) hat und die Konvergenzbedingung erfüllt (übliche Schrittgrößenauswahlen für Optimierungsalgorithmen erfüllen alle die Konvergenzbedingung. Wenn sie alle im heuristischen Netzwerk lernbar sind, ist diese Bedingung nicht erforderlich), wird die neuronale Netzwerk inspiriert durch den Algorithmus:
ein Gradientenoptimierungsalgorithmus erster Ordnung. Wenn Algorithmus A das Aktualisierungsformat in Formel (1) hat und die Konvergenzbedingung erfüllt (übliche Schrittgrößenauswahlen für Optimierungsalgorithmen erfüllen alle die Konvergenzbedingung. Wenn sie alle im heuristischen Netzwerk lernbar sind, ist diese Bedingung nicht erforderlich), wird die neuronale Netzwerk inspiriert durch den Algorithmus:
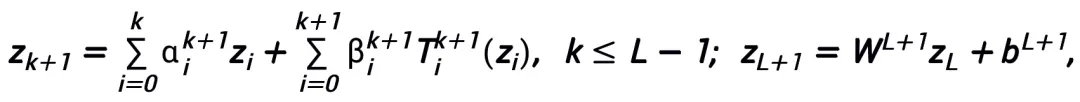
und der Norm 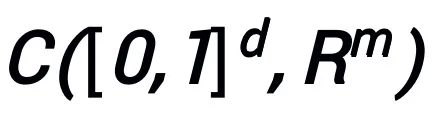 , wobei das lernbare Modul T nur zwei A-Strukturen enthalten muss mit einer Schichtform wie
, wobei das lernbare Modul T nur zwei A-Strukturen enthalten muss mit einer Schichtform wie 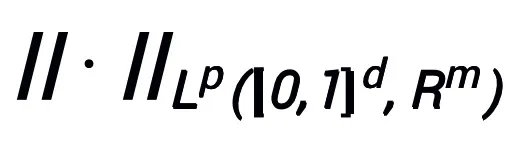 (σ kann eine häufig verwendete Aktivierungsfunktion sein) kann als Unterstruktur verwendet werden.
(σ kann eine häufig verwendete Aktivierungsfunktion sein) kann als Unterstruktur verwendet werden. 
1) Im Faltungsnetzwerk, Voraktivierungsblock: BN-ReLU-Conv-BN-ReLU-Conv (z),
2) Im Transformer: Attn (z) + MLP (z+Attn (z)). Der Beweis des Hauptsatzes nutzt die universelle Näherungseigenschaft von NODE und die Konvergenzeigenschaft der linearen Mehrschrittmethode Das Design des Optimierungsalgorithmus entspricht der Diskretisierung von kontinuierlichem NODE durch ein konvergentes lineares Mehrschrittverfahren, sodass das inspirierte Netzwerk die Approximationsfähigkeit von NODE „erbt“. Im Beweis gibt die Arbeit auch die Approximationsgeschwindigkeit von NODE an, um eine kontinuierliche Funktion im d-dimensionalen Raum zu approximieren, was ein verbleibendes Problem der vorherigen Arbeit löst [6].
Tabelle 1 Frühere Untersuchungen zu universellen Approximationseigenschaften konzentrierten sich im Wesentlichen auf FCNN und ResNet (genannt OptDNN), die Netzwerkinformationen sind in Tabelle 2 aufgeführt, und es wurden Experimente zu Problemen wie der Trennung verschachtelter Ringe, der Funktionsnäherung und der Bildklassifizierung durchgeführt. Der Artikel verwendet außerdem ResNet, DenseNet, ConvNext und ViT als Basislinien, verwendet die vorgeschlagene Methode, um ein verbessertes OptDNN zu entwerfen, und führt Experimente zum Problem der Bildklassifizierung unter Berücksichtigung der beiden Genauigkeitsindikatoren und FLOPs durch.
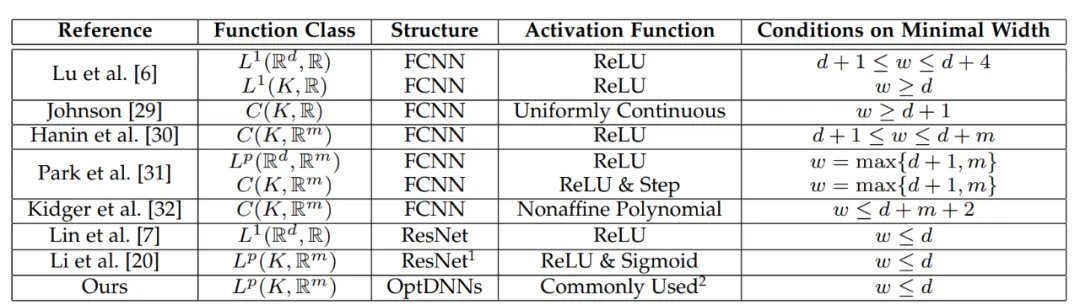
Tabelle 2 Relevante Informationen des entworfenen Netzwerks
Abbildung 3: OptNN nähert sich der Paritätsfunktion an schmal-tiefe Einstellungen bzw Mit dem Datensatz wurde ein Experiment zur Bildklassifizierung durchgeführt. Die Ergebnisse sind in den Tabellen 3 und 4 aufgeführt. Die Experimente wurden alle unter starken Datenerweiterungseinstellungen durchgeführt. Es ist ersichtlich, dass einige OptDNN bei gleichem oder sogar geringerem FLOPs-Overhead geringere Fehlerraten als ResNet erzielten. Der Artikel führte auch Experimente unter ResNet- und DenseNet-Einstellungen durch und erzielte ähnliche experimentelle Ergebnisse. ?? DNN- Das APG2-Netzwerk wurde am ImageNet-Datensatz unter den Einstellungen von ConvNext und ViT weiter getestet. Die Netzwerkstruktur von OptDNN-APG2 ist in Abbildung 5 dargestellt, und die experimentellen Ergebnisse sind in den Tabellen 5 und 6 aufgeführt. OptDNN-APG2 erreichte eine Genauigkeit, die ConvNext und ViT mit gleicher Breite übertraf, was die Zuverlässigkeit dieser Architekturentwurfsmethode weiter bestätigte.
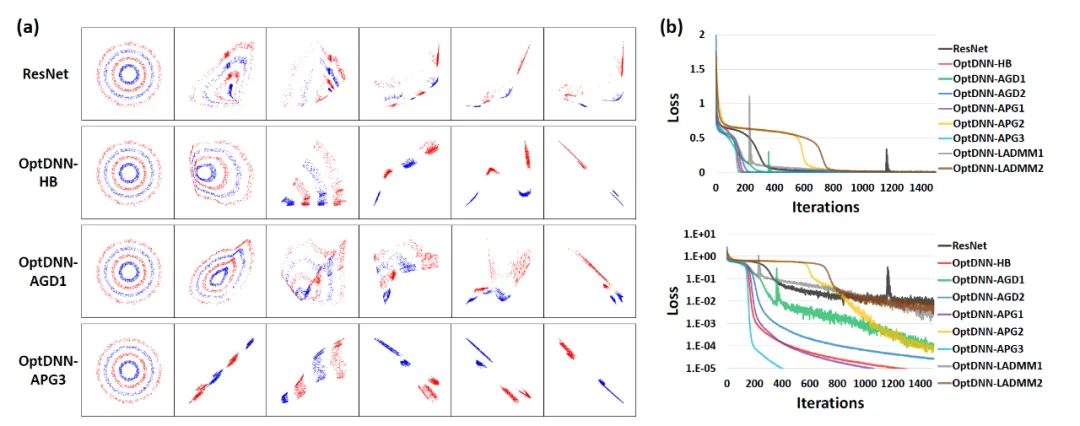
Abbildung 5 Netzwerkstruktur von OptDNN-APG2
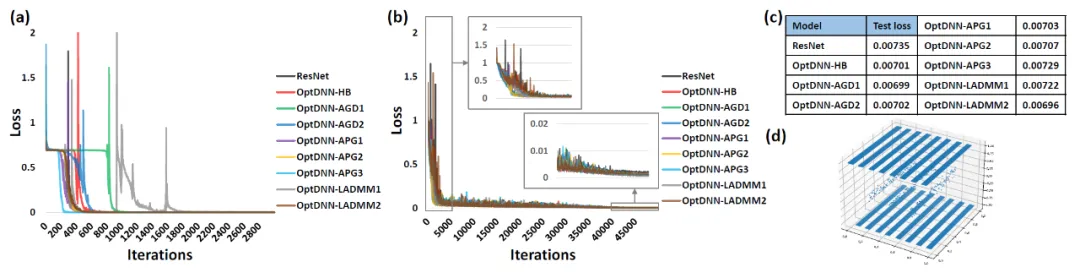
Tabelle 5 Leistungsvergleich von OptDNN-APG2 auf ImageNet
Tabelle. 6 OptDNN-AP G2 und isotrop) Leistungsvergleich von ConvNeXt und ViT
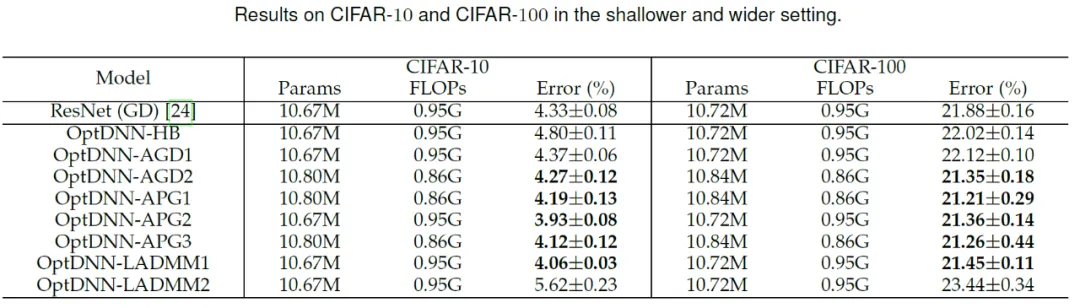
Abschließend entwarf das Papier drei implizite Netzwerke basierend auf Algorithmen wie Proximal Gradient Descent und FISTA und führte Experimente am CIFAR-Datensatz mit explizitem ResNet und einigen häufig verwendeten impliziten Netzwerken durch. Zum Vergleich die experimentellen Ergebnisse sind in Tabelle 7 aufgeführt. Alle drei impliziten Netzwerke erzielten experimentelle Ergebnisse, die mit fortgeschrittenen impliziten Netzwerken vergleichbar sind, was auch die Flexibilität der Methode verdeutlicht.
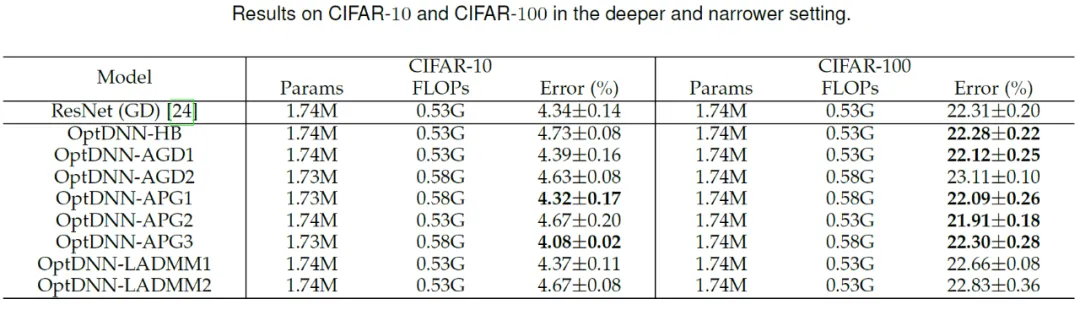
Tabelle 7 Leistungsvergleich impliziter Netzwerke
Zusammenfassung
Das Design neuronaler Netzwerkarchitekturen ist eines der Kernthemen beim Deep Learning. Der Artikel schlägt ein einheitliches Framework für die Verwendung von Optimierungsalgorithmen erster Ordnung zum Entwurf neuronaler Netzwerkarchitekturen mit universellen Approximationseigenschaften vor und erweitert die Methode basierend auf dem Optimierungsdesign-Netzwerkarchitekturparadigma. Diese Methode kann mit den meisten vorhandenen Architekturentwurfsmethoden kombiniert werden, die sich auf Netzwerkmodule konzentrieren, und ein effizientes Modell kann nahezu ohne Erhöhung des Rechenaufwands entworfen werden. Theoretisch beweist das Papier, dass die durch konvergente Optimierungsalgorithmen induzierte Netzwerkarchitektur unter milden Bedingungen universelle Approximationseigenschaften aufweist und die Darstellungsfähigkeiten von NODE und allgemeinen schichtübergreifenden Verbindungsnetzwerken überbrückt. Es wird erwartet, dass diese Methode auch mit NAS, SNN-Architekturdesign und anderen Bereichen kombiniert wird, um eine effizientere Netzwerkarchitektur zu entwerfen. 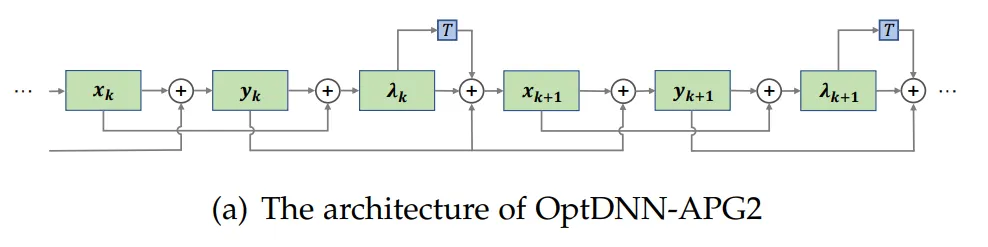
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 L'ordinateur demande une solution nsiserror
L'ordinateur demande une solution nsiserror
 es6 nouvelles caractéristiques
es6 nouvelles caractéristiques
 Solution au rapport Java indiquant que les entrées du chemin de construction sont vides
Solution au rapport Java indiquant que les entrées du chemin de construction sont vides
 Les pièces d'inscription Sols reviendront-elles à zéro ?
Les pièces d'inscription Sols reviendront-elles à zéro ?
 Que sont les frameworks d'intelligence artificielle Python ?
Que sont les frameworks d'intelligence artificielle Python ?
 mise à jour automatique de Windows
mise à jour automatique de Windows
 Quels sont les attributs du javabean ?
Quels sont les attributs du javabean ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



