


Détection d'objets statiques (SOD), y compris les feux de circulation, les panneaux de guidage et les cônes de signalisation, la plupart des algorithmes sont des réseaux neuronaux profonds basés sur des données et nécessitent une grande quantité de données d'entraînement. La pratique actuelle implique généralement l'annotation manuelle d'un grand nombre d'échantillons d'entraînement sur des données de nuages de points analysées par LiDAR pour corriger les cas à longue traîne.

L'annotation manuelle est difficile à capturer la variabilité et la complexité des scènes réelles, et ne parvient souvent pas à prendre en compte les occultations, les différentes conditions d'éclairage et les divers angles de vision (flèches jaunes sur la figure 1). L'ensemble du processus comporte de longs liens, est extrêmement long, sujet aux erreurs et coûteux (Figure 2). Les entreprises recherchent donc actuellement des solutions d'étiquetage automatique, notamment basées sur la vision pure. Après tout, toutes les voitures ne disposent pas d'un lidar.
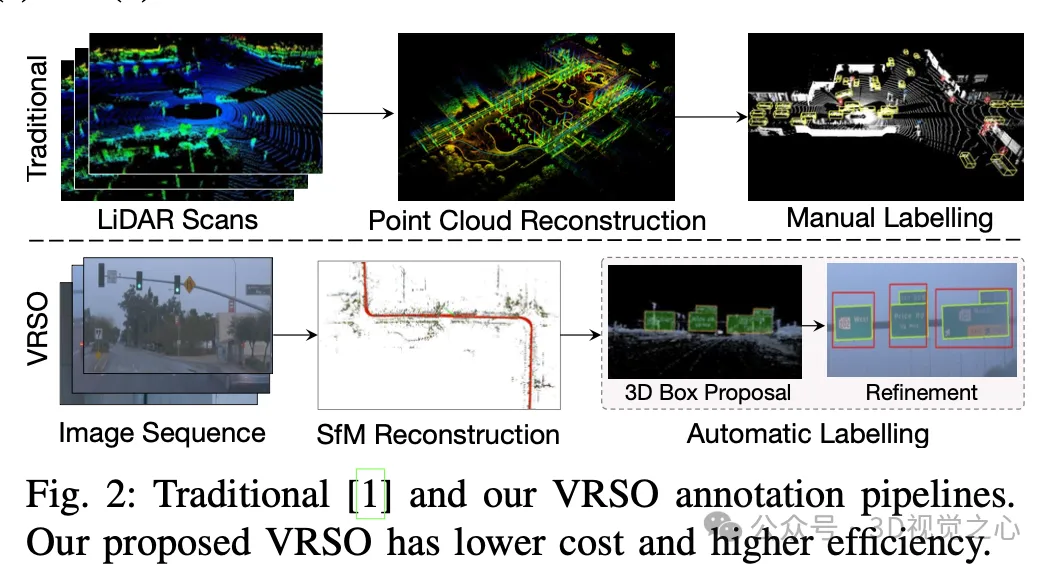
VRSO+ est un système d'annotation basé sur la vision pour l'annotation d'objets statiques. Il utilise principalement les informations des résultats de SFM, de détection d'objets 2D et de segmentation d'instance. L'effet global est le suivant :
Pour les objets statiques, VRSO extrait les points clés grâce à la segmentation des instances et aux contours pour résoudre le défi de l'intégration et la déduplication d'objets statiques de différents points de vue, ainsi que la difficulté de sous-observation due à des problèmes d'occlusion, améliorent la précision des annotations. À partir de la figure 1, par rapport aux résultats d'annotation manuelle de l'ensemble de données Waymo Open, VRSO démontre une robustesse et une précision géométrique supérieures.
(Vous avez tous vu ça, pourquoi ne pas glisser votre pouce vers le haut et cliquer sur la carte en haut pour me suivre, L'opération entière ne vous prendra que 1,328 secondes, puis enlèvera toutes les informations utiles dans l'avenir, au cas où cela serait utile~)
Le système VRSO est principalement divisé en deux parties : Reconstruction de scène et Annotation d'objet statique.
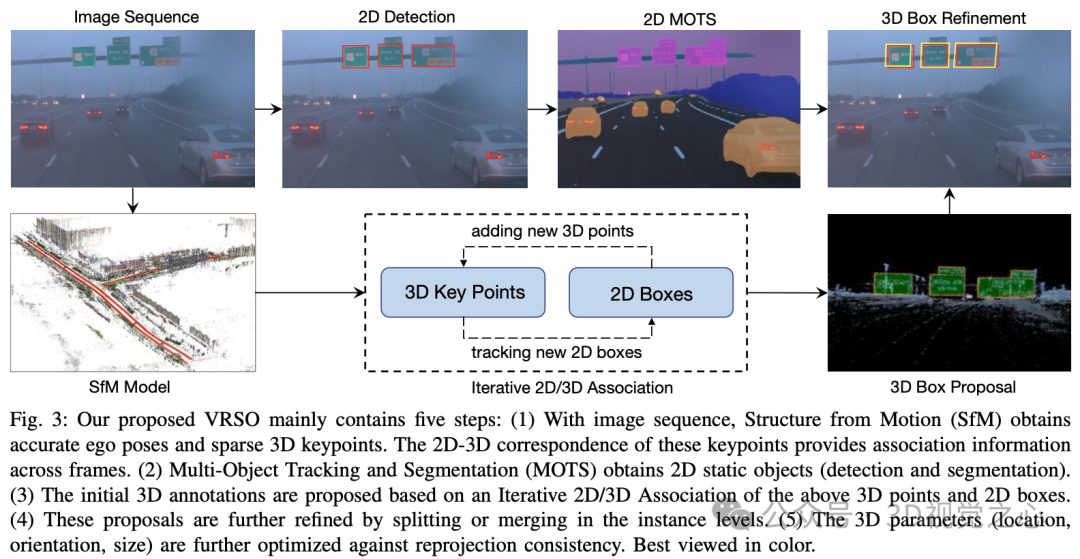
La partie reconstruction n'est pas au centre, elle est basée sur l'algorithme SFM pour restaurer la pose de l'image et les points clés 3D clairsemés.
Algorithme d'annotation d'objets statiques, combiné à un pseudo-code, le processus général est le suivant (ce qui suit sera détaillé étape par étape) :

pour initialiser les paramètres de la boîte 3D (position, direction, taille) de l'objet statique pour l'ensemble du clip vidéo. Chaque point clé de SFM a une position 3D précise et une image 2D correspondante. Pour chaque instance 2D, les points caractéristiques du masque d'instance 2D sont extraits. Ensuite, un ensemble de points clés 3D correspondants peut être considéré comme candidat aux boîtes englobantes 3D.
Un panneau de signalisation est représenté comme un rectangle avec une orientation dans l'espace, qui possède 6 degrés de liberté, dont la translation (,,), l'orientation (θ) et la taille (largeur et hauteur). Compte tenu de sa profondeur, un feu tricolore possède 7 degrés de liberté. Les cônes de signalisation sont représentés de la même manière que les feux de circulation.
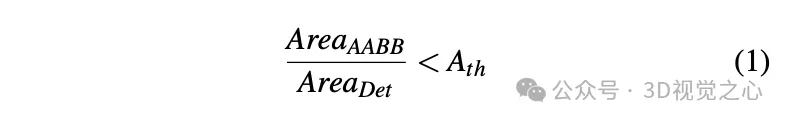
Obtenez la valeur initiale du sommet de l'objet statique dans des conditions 3D grâce à la triangulation.
En vérifiant le nombre de points clés dans les boîtes englobantes 3D obtenues par SFM et la segmentation des instances lors de la reconstruction de la scène, seules les instances dont le nombre de points clés dépasse le seuil sont considérées comme des observations stables et valides. Pour ces instances, la boîte englobante 2D correspondante est considérée comme une observation valide. Grâce à l'observation 2D de plusieurs images, les sommets du cadre de délimitation 2D sont triangulés pour obtenir les coordonnées du cadre de délimitation.
Pour les panneaux circulaires qui ne distinguent pas les sommets « inférieur gauche, supérieur gauche, supérieur droit, supérieur droit et inférieur droit » sur le masque, ces panneaux circulaires doivent être identifiés. En utilisant les résultats de détection 2D comme observations d'objets circulaires, des masques de segmentation d'instance 2D sont utilisés pour l'extraction de contours. Le point central et le rayon sont calculés via un algorithme d'ajustement des moindres carrés. Les paramètres du signe circulaire incluent le point central (,,), la direction (θ) et le rayon ().
Correspondance des points de fonctionnalité de suivi basée sur SFM. Déterminez s'il convient de fusionner ces instances distinctes en fonction de la distance euclidienne des sommets du cadre de délimitation 3D et de la projection IoU du cadre de délimitation 2D. Une fois la fusion terminée, les points caractéristiques 3D au sein d'une instance peuvent être regroupés pour associer davantage de points caractéristiques 2D. L'association itérative 2D-3D est effectuée jusqu'à ce qu'aucun point caractéristique 2D ne puisse être ajouté.
En prenant le signe rectangulaire comme exemple, les paramètres qui peuvent être optimisés incluent la position (,,), la direction (θ) et la taille (,), avec un total de six degrés. de liberté. Les principales étapes comprennent :


Il existe également des cas difficiles à longue traîne, tels qu'une résolution extrêmement basse et un éclairage insuffisant.

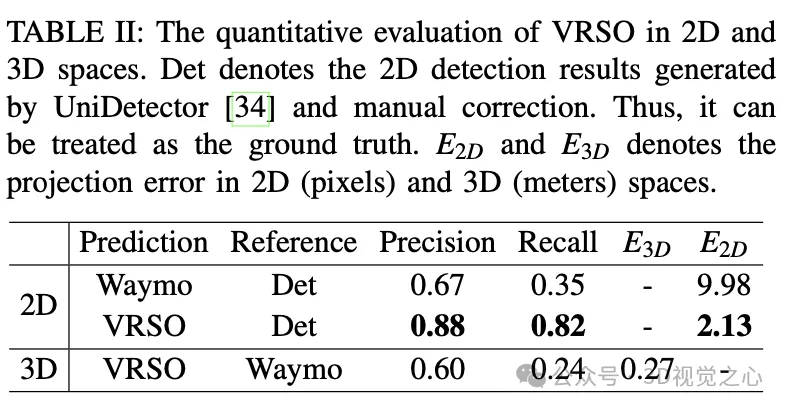
Le cadre VRSO permet d'obtenir une annotation 3D de haute précision et cohérente d'objets statiques, intègre étroitement les algorithmes de détection, de segmentation et SFM, élimine l'intervention manuelle dans l'annotation de conduite intelligente et fournit des résultats comparables basés sur LiDAR. à l'annotation manuelle. Des évaluations qualitatives et quantitatives ont été menées avec l'ensemble de données ouvert Waymo largement reconnu : par rapport à l'annotation manuelle, la vitesse est augmentée d'environ 16 fois, tout en conservant la meilleure cohérence et précision.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction au système d'exploitation Linux
Introduction au système d'exploitation Linux
 Solution d'erreur SQL 5120
Solution d'erreur SQL 5120
 Comment centrer la page Web dans Dreamweaver
Comment centrer la page Web dans Dreamweaver
 puce FAI
puce FAI
 minidump.dmp
minidump.dmp
 Comment clearfix implémente la compensation des flotteurs
Comment clearfix implémente la compensation des flotteurs
 Outil de requête de nom de domaine d'enregistrement
Outil de requête de nom de domaine d'enregistrement
 Comment utiliser l'outil de capture de paquets HttpCanary
Comment utiliser l'outil de capture de paquets HttpCanary








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



