


Un portrait est une description structurée de l'utilisateur qui est compréhensible par l'homme, lisible par la machine et inscriptible. Elle fournit non seulement des services personnalisés, mais joue également un rôle important dans la prise de décision stratégique et l'analyse commerciale de l'entreprise.
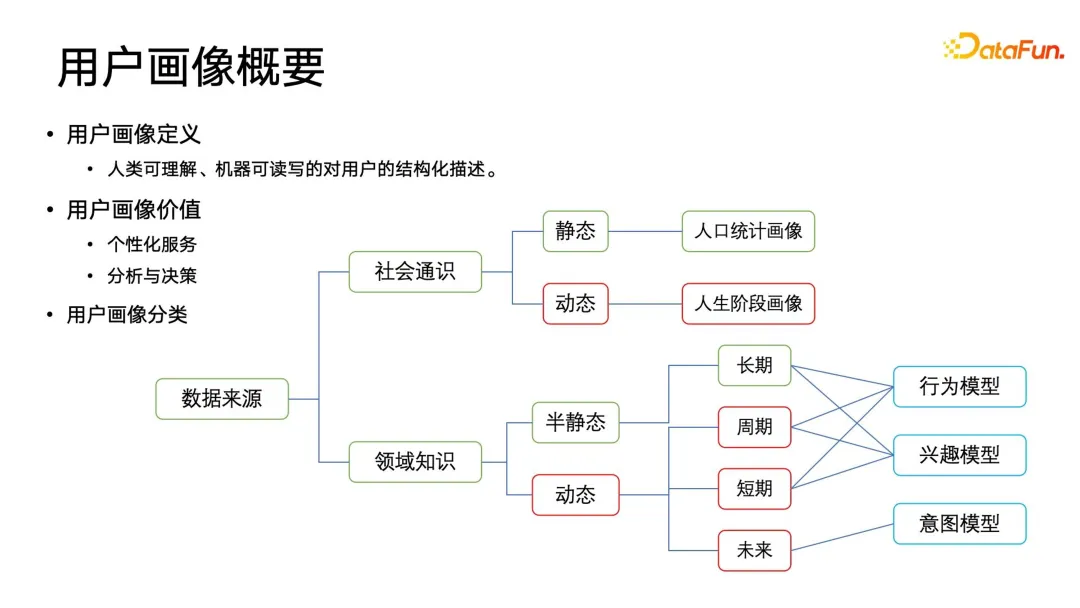
Selon la source de données, il est divisé en catégorie de connaissances sociales générales et en catégorie de connaissances de domaine. Les portraits sociaux généraux peuvent être divisés en catégories statiques et dynamiques selon la dimension temporelle. Les portraits sociaux généraux statiques les plus courants incluent des caractéristiques démographiques, telles que le sexe, l'enregistrement du ménage, l'école d'obtention du diplôme, etc. Ces contenus sont affichés sur une période relativement longue. temps. Les fenêtres sont relativement statiques. En plus de l'utiliser en images, il est aussi souvent utilisé en démographie, en démographie, en sociologie, etc. Les portraits sociaux généraux dynamiques sont plus importants, également connus sous le nom de portraits d'étapes de vie. Par exemple, dans le commerce électronique, les revenus des gens continueront de changer avec l'évolution de leur carrière, et leurs tendances d'achat changeront également, donc ces portraits d'étapes de vie sont d'une grande utilité pratique. valeur.
En plus des portraits généraux ci-dessus, les entreprises peuvent construire davantage de portraits de connaissances de domaine au sein de l'entreprise. Les portraits de connaissances de domaine peuvent être divisés en portraits d'attributs semi-statiques et dynamiques à partir de la dimension temporelle, et peuvent être subdivisés en portraits d'attributs à long terme, cycliques, à court terme et futurs. Ces portraits dimensionnels temporels sont mêlés à des champs conceptuels, qui comprennent des modèles comportementaux, des modèles d'intérêt et des modèles d'intention.
Le modèle comportemental suit principalement les comportements cycliques des utilisateurs, tels que ce qu'ils font pendant leur trajet chaque matin, ce qu'ils font après avoir quitté le travail le soir, ce qu'ils font pendant la semaine, ce qu'ils font le week-end et d'autres comportements cycliques. Le modèle d'intérêt effectue une certaine modélisation conjointe et un tri des balises au sein des connaissances du domaine. Par exemple, les utilisateurs peuvent obtenir des journaux d'opérations après avoir interagi avec des produits de plate-forme tels que les applications. Les journaux peuvent être corrélés et analysés pour extraire certaines données structurées et étiquetées. Ils peuvent être divisés en catégories, en leur attribuant un certain poids, et enfin triés pour former un certain profil d'intérêt. Il convient de noter que le modèle d'intention est davantage un futur et constitue une prédiction de l'intention future de l'utilisateur. Mais comment prédire les intentions possibles des nouveaux utilisateurs avant qu’ils n’interagissent ? Ce problème concerne davantage les portraits en temps réel et futurs, et nécessite également des exigences plus élevées en matière de structure globale de l'infrastructure des données de portrait.
Après avoir compris le concept et la classification générale des images, présentons brièvement le cadre d'application de base des portraits d'utilisateurs. L'ensemble du cadre peut être divisé en quatre niveaux : le premier est la collecte des données, le deuxième est le prétraitement des données, le troisième est la construction et la mise à jour de portraits basés sur ces données traitées, et enfin la couche application est définie dans le cadre. couche d'application pour permettre aux utilisateurs en aval de Diverses applications peuvent utiliser les images de manière plus pratique, plus rapide et plus efficace.
Nous pouvons déduire de ce cadre que les applications de profilage d'utilisateurs et les algorithmes de profilage d'utilisateurs doivent comprendre une connotation très large et complexe, car ce à quoi nous sommes confrontés ne sont pas seulement des données simples, étiquetées et basées sur du texte. Il existe également diverses données multi- les données modales, qui peuvent être audio, vidéo ou graphiques, diverses méthodes de prétraitement sont nécessaires pour obtenir des données de haute qualité, puis construire un portrait plus confiant. Cela impliquera divers aspects tels que l'exploration de données, l'apprentissage automatique, les graphiques de connaissances et l'apprentissage statistique. La différence entre les portraits d'utilisateurs et les algorithmes de recommandation de recherche traditionnels réside dans le fait que nous devons travailler en étroite collaboration avec des experts du domaine pour créer en permanence des portraits de meilleure qualité par itérations et cycles.

Le portrait d'utilisateur est un concept établi grâce à une analyse approfondie des données et des informations sur le comportement des utilisateurs. En comprenant les intérêts, les préférences et les comportements des utilisateurs, nous pouvons mieux leur offrir des services et des expériences personnalisés.
Au début, les portraits d'utilisateurs reposaient principalement sur des graphes de connaissances, issus du concept d'ontologie. L’ontologie, quant à elle, appartient à la catégorie de la philosophie. Tout d’abord, la définition de l’ontologie est très similaire à la définition du portrait. Il s’agit d’un système conceptuel compréhensible par les humains et lisible et inscriptible par les machines. Bien entendu, la complexité de ce système conceptuel lui-même peut être très élevée. Il est composé d’entités, d’attributs, de relations et d’axiomes. L'avantage des portraits d'utilisateurs basés sur l'ontologie est qu'il est facile de classer les utilisateurs et le contenu, et qu'il est pratique de produire des rapports de données qui peuvent être compris intuitivement par les humains, puis de prendre des décisions basées sur les conclusions pertinentes des rapports. pourquoi cette méthode est choisie à l'ère du non-apprentissage profond. Une forme technique.
Ensuite, nous présenterons quelques concepts de base en ontologie. Pour construire une ontologie, vous devez d'abord conceptualiser la connaissance du domaine, c'est-à-dire construire des entités, des attributs, des relations et des axiomes, et les traiter dans des formats lisibles par machine, tels que RDF et OWL. Bien sûr, vous pouvez également utiliser des formats de données plus simples, ou même dégénérer l'ontologie en une base de données relationnelle ou une base de données graphique capable de stocker, lire, écrire et analyser. La manière d’obtenir ce type de portrait est généralement de le construire par l’intermédiaire d’experts du domaine, ou de l’enrichir et de l’affiner en fonction de certains standards industriels existants. Par exemple, le système d’étiquetage des produits adopté par Taobao s’inspire en fait des normes publiques du pays pour diverses industries manufacturières de matières premières, et s’enrichit et se répète sur cette base.

L'image ci-dessous est un exemple d'ontologie très simple, qui contient 3 nœuds. L'entité dans l'image est une balise d'intérêt dans le domaine du divertissement. Par exemple, il existe de nombreux films sur des plateformes telles que Netflix. Les films ont des identifiants uniques et chaque film a ses propres attributs, tels que le titre et le rôle principal. Cette entité appartient également à la série policière, et la série policière appartient à la sous-catégorie des films d'action. Nous écrivons le document texte RDF sur le côté droit de la figure ci-dessous sur la base de ce diagramme visuel, dans ce document, en plus des relations entre les attributs d'entité que nous pouvons comprendre intuitivement, certains axiomes sont également définis, comme la contrainte qui "a". titre" ne peut agir que sur Pour le domaine conceptuel de base des films, s'il existe d'autres domaines conceptuels, comme utiliser le réalisateur du film en tant qu'entité pour l'intégrer dans l'ontologie, le réalisateur du film ne peut pas avoir l'attribut "a un titre". . Ce qui précède est une brève introduction à l’ontologie.

Au début de la réalisation de portraits d'utilisateurs basés sur l'ontologie, une méthode similaire à TF-IDF était utilisée pour calculer le poids des balises structurées construites. Dans le passé, TF-IDF était principalement utilisé dans le champ de recherche ou le champ sujet du texte. Lorsqu'il est appliqué aux portraits d'utilisateurs, il suffit de le restreindre et de le déformer légèrement, par exemple. dans l'exemple précédent, TF consiste à compter le nombre de films ou de courtes vidéos que les utilisateurs regardent sous ce type de balise. IDF doit d'abord compter le nombre de films ou de courtes vidéos que les utilisateurs regardent sous chaque type de balise et le nombre total de balises. toutes les vues historiques, puis calculez-le selon la formule de la figure et TF *IDF. La méthode de calcul de TF-IDF est très simple et stable, et elle est également interprétable et facile à utiliser.
Mais ses défauts sont également évidents : TF-IDF est très sensible à la granularité des balises, mais est insensible à la structure de l'ontologie elle-même. Il peut trop insister sur des intérêts impopulaires et conduire à des solutions triviales, telles que les utilisateurs qui ne regardent qu'occasionnellement. vidéo sous une certaine balise, TF sera très petit et IDF sera extrêmement grand. TF-IDF pourrait devenir une valeur proche de son intérêt populaire. Plus important encore, nous devons mettre à jour et ajuster les portraits des utilisateurs au fil du temps, et la méthode traditionnelle TF-IDF n'est pas adaptée à cette situation. Par conséquent, les chercheurs ont proposé une nouvelle méthode pour construire directement des portraits d’utilisateurs pondérés basés sur l’expression structurée de l’ontologie afin de répondre aux besoins de mises à jour dynamiques.

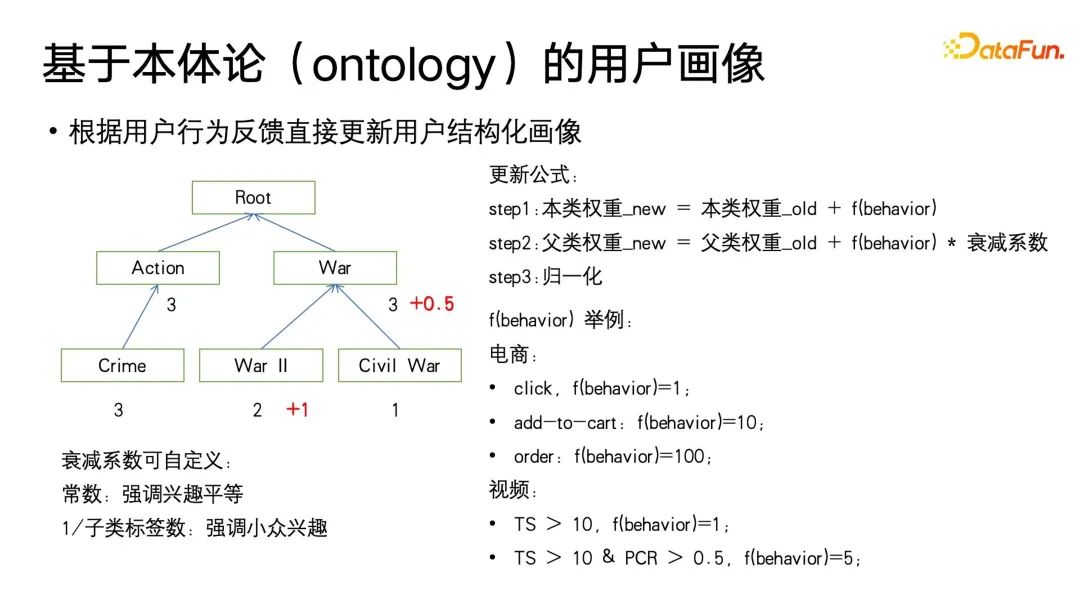
Cet algorithme part de la catégorie feuille d'Ontologie, utilise le comportement de consommation multimédia de l'utilisateur sous la balise correspondante pour mettre à jour le poids. Le poids est initialisé à 0, puis mis à jour selon la fonction fbehavior définie par le comportement de l'utilisateur. . La fonction fbehaviour donnera différents signaux de retour implicites en fonction des différents niveaux de consommation de l'utilisateur, tels que les clics, les achats et commandes supplémentaires dans le domaine du commerce électronique, ou la lecture et la réalisation dans le domaine de la vidéo. Dans le même temps, nous donnerons également des signaux de rétroaction de différentes forces aux différents comportements des utilisateurs, par exemple, dans le comportement de consommation du commerce électronique, commande > achat > clics, dans la consommation vidéo, une lecture plus complète, une durée de lecture plus élevée, etc. Une valeur fbehavior plus forte sera également définie.
Une fois le poids de signature cible de la classe feuille mis à jour, le poids de la classe parent doit être mis à jour. Il convient de noter que lors de la mise à jour de la classe parent, un coefficient de décroissance inférieur à 1 doit être défini. Parce que, comme le montre la figure, les utilisateurs peuvent être intéressés par la sous-catégorie « Seconde Guerre mondiale » dans « Guerre », mais peuvent ne pas être intéressés par d'autres thèmes de guerre. Ce coefficient d'atténuation peut être personnalisé en tant qu'hyperparamètre.Cette définition met l'accent sur l'égalité de la contribution de l'intérêt de chaque sous-catégorie à la catégorie parente. L'inverse du nombre d'étiquettes de sous-catégorie peut également être utilisé comme coefficient d'atténuation, afin de mettre davantage l'accent. sur les intérêts de niche, par exemple, certains grands nœuds de catégories parents contiennent des thèmes de sous-catégories qui sont larges et peu liés. L'audience entre eux dépend du nombre d'œuvres. Habituellement, le nombre de ces œuvres sera très, très important. et la vitesse de décroissance peut être réglée de manière appropriée pour être plus rapide, et les étiquettes de sous-catégories plus petites peuvent présenter des intérêts de niche et il n'y a pas beaucoup de travaux. La relation entre les sujets de sous-catégories sera relativement étroite et la vitesse d'atténuation. peut être réglé de manière appropriée pour être plus petit. En bref, nous pouvons définir le coefficient d'atténuation en fonction de ces attributs de connaissance du domaine définis dans l'ontologie.
La méthode ci-dessus peut obtenir l'effet de mise à jour des balises structurées, et elle peut fondamentalement égaler ou même surpasser l'effet TF-IDF. Cependant, il lui manque un attribut d'échelle de temps, c'est-à-dire comment construire un temps. échelle qui est un portrait plus sensible.
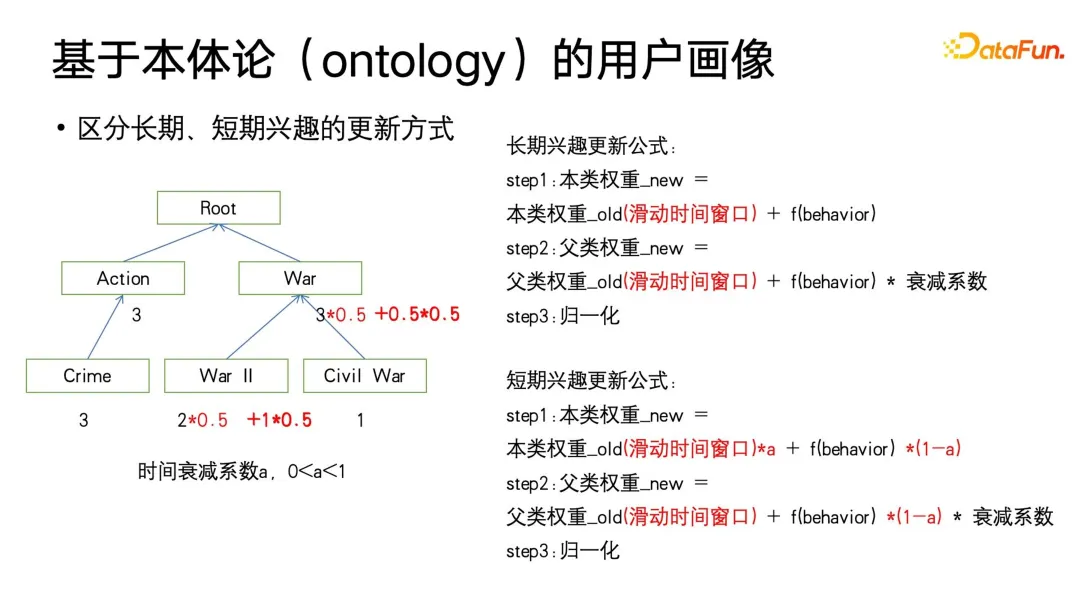
Nous avons d'abord pensé que nous pourrions ajuster davantage la mise à jour du poids lui-même. Lorsque vous devez distinguer les portraits d'utilisateurs à long terme et à court terme, vous pouvez ajouter une fenêtre glissante au poids et définir un coefficient de décroissance temporelle a (entre 0 et 1). La fonction de la fenêtre glissante est de se concentrer uniquement sur l'utilisateur. comportement au cours de la période de fenêtre et ne vous concentrez pas sur le comportement de l'utilisateur avant la fenêtre. La raison en est que les intérêts à long terme de l'utilisateur changeront également lentement avec le changement d'étape de la vie. Par exemple, l'utilisateur peut aimer un certain type de. film pendant un ou deux ans, puis je ne l’aime plus.
De plus, vous remarquerez peut-être également que cette formule est similaire à la méthode de mise à jour du gradient d'Adam avec élan. Nous ajustons la taille de a pour que la mise à jour du poids se concentre davantage sur l'histoire ou le présent dans une certaine mesure. Plus précisément, lorsqu’on lui attribue un a plus petit, il se concentrera davantage sur le présent, et l’accumulation historique aura alors une plus grande atténuation.
Les méthodologies ci-dessus sont limitées aux informations que l'utilisateur a reçues, mais nous rencontrons généralement également un grand nombre de balises manquantes, ainsi que des démarrages à froid de l'utilisateur ou lorsque l'utilisateur n'a peut-être pas été exposé à cela. contenu, mais cela ne veut pas dire que les utilisateurs ne l’aiment pas. Dans ces cas, la réalisation des intérêts et la déduction des intérêts sont requises.
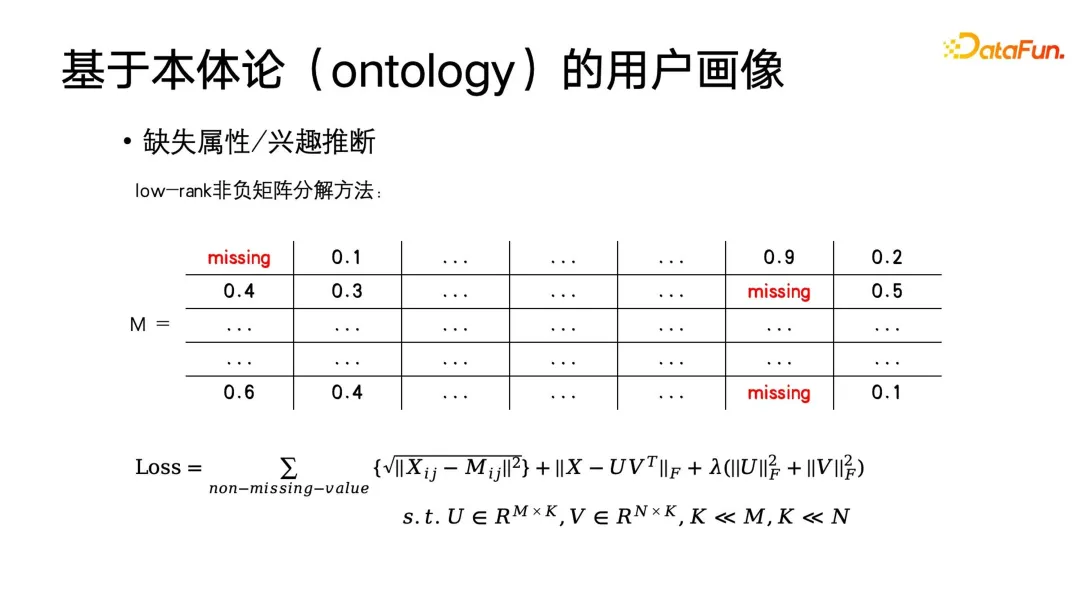
La méthode la plus basique consiste à utiliser le filtrage collaboratif dans le système de recommandation pour compléter le portrait. Supposons qu'il y ait une matrice d'étiquettes, l'axe horizontal est l'utilisateur et l'axe vertical est chaque élément de cette très grande matrice. sont la réponse de l'utilisateur à cette étiquette. Intérêt, ces éléments peuvent être 0 ou 1, ou des poids d'intérêt. Bien entendu, cette matrice peut également être transformée pour s'adapter au profil démographique. Par exemple, le label peut être exprimé comme s'il s'agit d'un étudiant, ou s'il s'agit d'un professionnel, ou quel type de profession, etc. Vous pouvez également utiliser. une méthode de codage pour construire cette matrice.Vous pouvez également appliquer la décomposition matricielle pour obtenir la décomposition matricielle, puis compléter les valeurs propres manquantes. À ce stade, l'objectif d'optimisation est celui indiqué dans la figure ci-dessous.
Comme vous pouvez le voir sur cette formule, la matrice d'origine est M, la matrice d'achèvement est une matrice de bas rang, car nous supposons que les intérêts d'un grand nombre d'utilisateurs sont similaires. Pour des utilisateurs similaires, la matrice d'étiquettes doit être de bas rang. Enfin, une régularisation est effectuée sur cette matrice pour atteindre l'objectif de décomposition matricielle non négative. Cette méthode peut en fait être résolue en utilisant la méthode de descente de gradient stochastique que nous connaissons le mieux.
Bien sûr, en plus de déduire les attributs ou les intérêts manquants via la décomposition matricielle, les méthodes traditionnelles d'apprentissage automatique peuvent également être utilisées. On suppose toujours que des utilisateurs similaires auront des intérêts similaires. À l'heure actuelle, la classification ou la régression KNN peut être utilisée pour déduire les intérêts. La méthode spécifique consiste à établir la carte des relations entre les voisins les plus proches de l'utilisateur, puis à ajouter les balises ou les balises les plus grandes. nombre de voisins parmi les k voisins les plus proches de l'utilisateur. La moyenne pondérée est attribuée aux attributs manquants de l'utilisateur. Le graphique de relation de voisinage peut être construit par vous-même, ou il peut s'agir d'une structure de graphique de voisinage prête à l'emploi, telle que le portrait d'utilisateur d'un réseau social, ou le portrait d'entreprise du côté B - la carte d'entreprise.

Ce qui précède est une introduction à la construction de portraits traditionnels par Ontologie. La valeur de l'algorithme traditionnel de construction de portraits est qu'il est très simple, direct, facile à comprendre et facile à mettre en œuvre. En même temps, son effet est bon, il ne sera donc pas complètement remplacé par des algorithmes d'ordre supérieur, en particulier. lorsque nous aurons besoin de déboguer le portrait, une classe d'algorithmes traditionnels sera plus pratique.
Après être entré dans l'ère de l'apprentissage profond, tout le monde espère l'améliorer encore en combinant des algorithmes d'apprentissage profond L'effet de l'algorithme de profilage. Quelle est la valeur du deep learning pour les algorithmes de profilage ?
Tout d'abord, il doit y avoir des capacités de représentation des utilisateurs plus puissantes. Dans le domaine de l'apprentissage profond et de l'apprentissage automatique, il existe une catégorie spéciale : l'apprentissage par représentation, ou apprentissage métrique. Cette méthode d'apprentissage peut nous aider à construire un outil très puissant. Représentation des utilisateurs. La seconde est un processus de modélisation plus simple. Nous pouvons utiliser l'approche de bout en bout de l'apprentissage profond pour simplifier le processus de modélisation. Dans de nombreux cas, il suffit de construire des fonctionnalités, de procéder à une ingénierie des fonctionnalités, puis de traiter le réseau neuronal comme tel. une boîte noire Les fonctionnalités sont entrées et des étiquettes ou d'autres informations de supervision sont définies en sortie sans prêter attention aux détails.
Une fois de plus, grâce aux puissantes capacités d’expression du deep learning, nous avons également atteint une plus grande précision dans de nombreuses tâches. Ensuite, l’apprentissage profond peut également modéliser uniformément les données multimodales. À l'ère des algorithmes traditionnels, nous devons consacrer beaucoup d'énergie au prétraitement des données. Par exemple, l'extraction des balises de type vidéo mentionnée ci-dessus nécessite un prétraitement très complexe. Il faut d'abord couper la vidéo, puis extraire le sujet, puis identifier. les visages un par un. Ajoutez les balises correspondantes, et enfin construisez le portrait. Avec le deep learning, lorsque vous souhaitez une expression d'utilisateur ou d'élément unifiée, vous pouvez traiter directement les données multimodales de bout en bout.
Enfin, nous espérons réduire au maximum les coûts lors des itérations. Comme mentionné dans l'article précédent, la différence entre l'itération de l'algorithme de profilage et l'itération d'autres types d'algorithmes tels que la promotion de recherche est qu'elle nécessite beaucoup de participation manuelle. Parfois, les données les plus fiables sont les données annotées par des personnes ou collectées via des questionnaires et d'autres méthodes. Le coût d'obtention de ces données est assez élevé, alors comment obtenir des données avec plus de valeur d'annotation à moindre coût ? Ce problème a également plus d'idées et de solutions à l'ère de l'apprentissage profond.

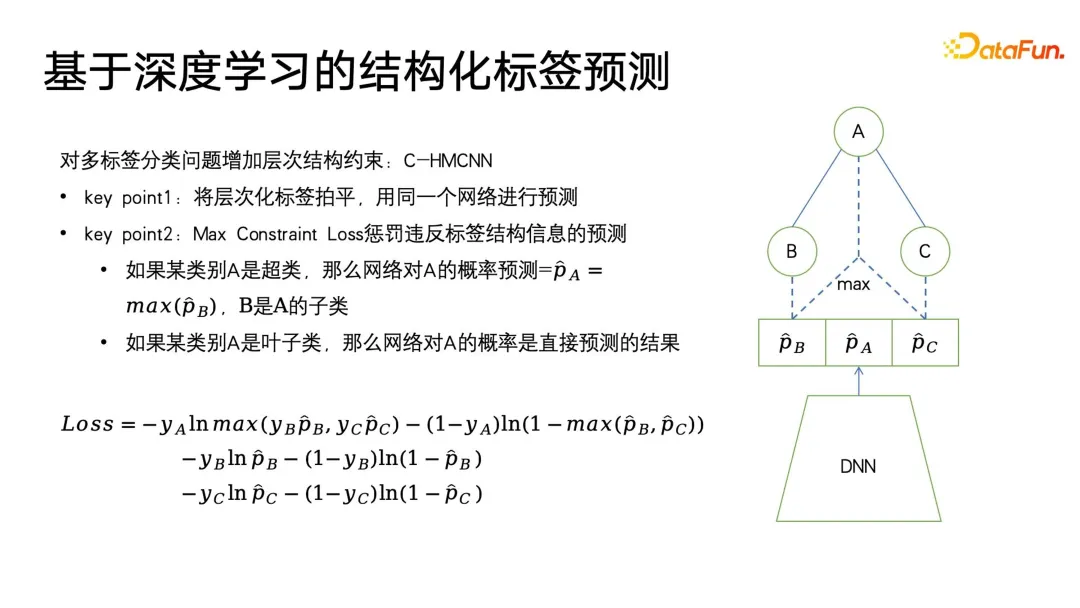
C-HMCNN est une méthode d'apprentissage en profondeur classique pour prédire les étiquettes structurées d'ontologies. Il ne s'agit pas d'une structure de réseau sophistiquée, mais d'une définition d'un cadre d'algorithme approprié. pour les étiquettes, en particulier pour la classification ou la prédiction structurée des étiquettes.
L'essentiel est d'aplatir les balises structurées hiérarchiques puis de les prédire. Comme le montre le côté droit de la figure ci-dessous, le réseau donne directement la probabilité de prédiction des trois balises ABC sans tenir compte du niveau et de la profondeur de la structure. Sa conception de formule de perte peut également punir les résultats qui violent autant que possible les balises structurées. La formule utilise d'abord la perte d'entropie croisée classique pour les catégories feuilles B et C, et max(yBpB pour les catégories parent , y. CpC) pour contraindre les informations structurelles et prédire la catégorie parent A uniquement lorsque la sous-catégorie est censée être vraie, en utilisant 1-max(pB, pC) Pour exprimer, lorsque le L'étiquette cible de la classe parent est fausse, la prédiction de la catégorie de sous-classe est forcée à être aussi proche de 0 que possible, obtenant ainsi des contraintes sur les étiquettes structurées. L'avantage de cette modélisation est que le calcul de la perte est très simple. Elle prédit toutes les étiquettes de manière égale et peut presque ignorer les informations de profondeur de l'arborescence des étiquettes.
La dernière chose à mentionner est que cette méthode nécessite que chaque étiquette soit 0 ou 1. Par exemple, PB représente uniquement ce que l'utilisateur aime ou n'aime pas, et ne peut pas être défini sur une multi-catégorie, car les contraintes de PERTE de multi-catégories sera plus difficile à établir, donc lors de la modélisation de ce modèle, cela équivaut à aplatir toutes les étiquettes, puis à faire des prédictions de 0 et 1. Un problème qui peut être causé par l'aplatissement est que lorsque l'étiquette parent dans la structure arborescente des étiquettes comporte un grand nombre de sous-étiquettes, elle sera confrontée à un problème de classification multi-étiquettes à très grande échelle. Pour utiliser certains moyens de filtrage à l'avance, l'utilisateur peut ne pas en être conscient.
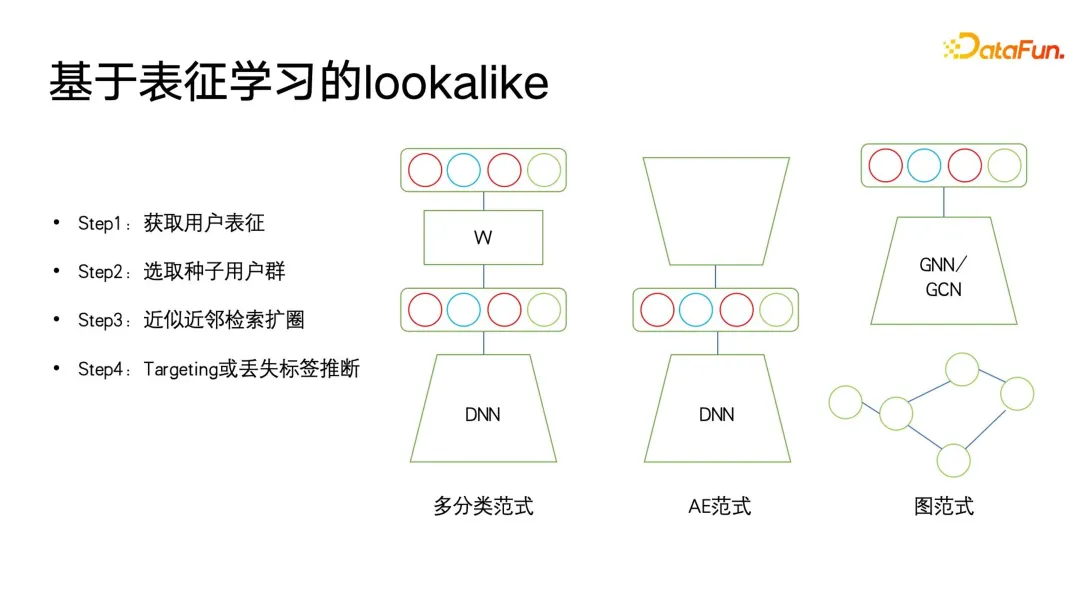
Dans l'application des portraits d'utilisateurs, l'idée de sosie est souvent utilisée. Dans les applications de portrait en aval, le sosie peut être utilisé pour cibler des groupes d'utilisateurs potentiels pour les publicités. Le sosie peut également être utilisé pour trouver certains utilisateurs pour lesquels il manque des attributs cibles en fonction des utilisateurs de départ, puis les attributs manquants correspondants de ces utilisateurs peuvent être remplacés ou exprimés. avec les utilisateurs de semences.
Ce dont l'application Lookalike a le plus besoin, c'est d'un puissant apprenant en représentation. Comme le montre la figure ci-dessous, il existe trois types de méthodes de modélisation de représentation qui sont les plus couramment utilisées.
La première est une méthode multi-classification. Si nous disposons de plusieurs données de portrait d'étiquettes de classification, nous pouvons apprendre des représentations plus ciblées avec des signaux supervisés pour un certain type d'étiquette que nous voulons prédire. Les représentations entraînées pour faire des prédictions sont très nombreuses. utile pour les prédictions ciblées d’étiquettes manquantes.
Le deuxième est le paradigme AE (auto-encoder). La structure du modèle est sous la forme d'un sablier. Il n'est pas nécessaire de prêter attention aux informations de supervision. Au lieu de cela, il vous suffit de trouver un mode d'encodage. utilisateur, puis au milieu de la taille fine. Ce paradigme de compression d'informations et d'obtention de représentation est plus fiable lorsqu'il n'y a pas suffisamment de données de supervision.
Le troisième est le paradigme des graphes. À l'heure actuelle, les réseaux de graphes tels que GNN et GCN sont utilisés dans de plus en plus de domaines, y compris dans les portraits. De plus, GNN peut être formé sans supervision sur la base de la méthode du maximum de vraisemblance, ou il peut le faire. Formation supervisée avec informations sur les étiquettes et surpasse les paradigmes multi-classification. Car en plus d'exprimer les informations d'étiquette, la structure graphique peut également intégrer davantage d'informations sur la structure graphique. Lorsqu'il n'y a pas de structure graphique affichée, il existe de nombreuses façons de construire un graphique. Par exemple, swing i2i, un algorithme de recommandation bien connu dans le domaine du commerce électronique, construit un graphique biparti basé sur les achats conjoints ou les enregistrements de visualisations conjointes des utilisateurs. De telles structures graphiques sont également très riches. Les informations sémantiques peuvent nous aider à apprendre de meilleures représentations utilisateur. Une fois que nous disposons de représentations riches, nous pouvons sélectionner certains utilisateurs de départ pour utiliser la recherche du voisin le plus proche pour élargir le cercle, puis utiliser les utilisateurs étendus pour déduire les balises ou la cible manquantes.
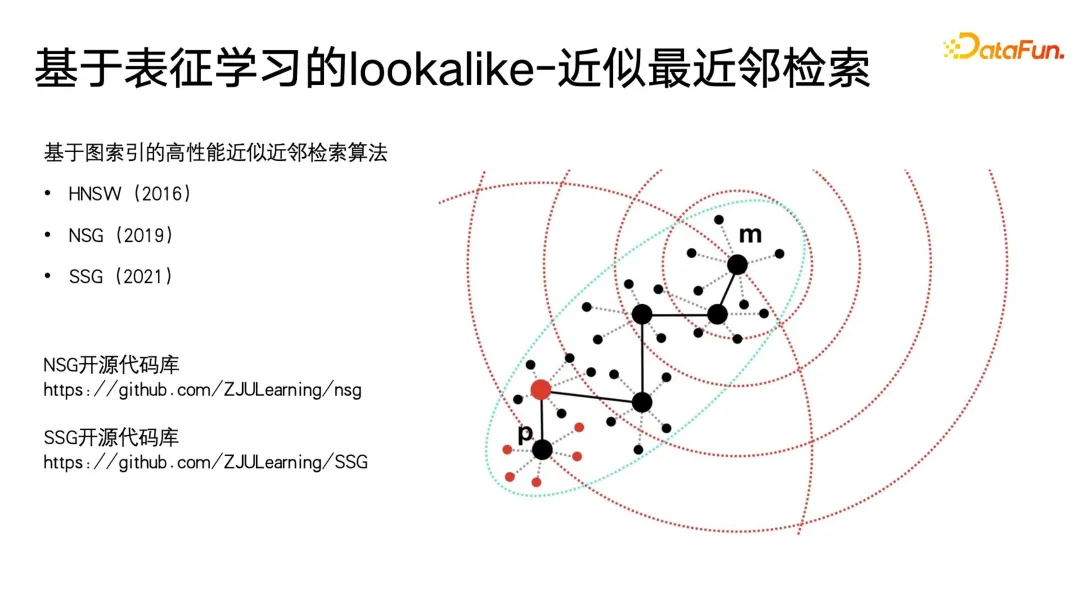
Il est très facile d'effectuer la récupération du voisin le plus proche sur des applications à petite échelle, mais sur des données à très grande échelle, telles que de grandes plates-formes avec des centaines de millions d'utilisateurs actifs mensuels, il est difficile d'effectuer KNN. la récupération sur ces utilisateurs prend beaucoup de temps, c'est pourquoi la méthode la plus couramment utilisée à l'heure actuelle est la récupération approximative du voisin le plus proche, qui se caractérise par l'échange de précision contre efficacité. Elle garantit une précision proche de 99 % tout en compressant le temps de récupération à 1/. 1000, 1/1 de la récupération violente originale 10000, voire 1/100000.
À l'heure actuelle, les méthodes efficaces de récupération approximative du voisin le plus proche sont des algorithmes de récupération vectorielle basés sur des index graphiques. Ces méthodes ont atteint leur apogée dans l'ère actuelle des grands modèles, qui est le concept le plus populaire dans certains grands modèles. -- RAG (Retrieval Enhancement Generation). La méthode de base utilisée par l'amélioration de la récupération pour la récupération de texte est la récupération vectorielle. La méthode la plus couramment utilisée est la récupération vectorielle basée sur des graphiques. Les méthodes les plus largement utilisées sont HNSW, NSG et SSG. Les deux derniers Le code open source original et le lien d'implémentation sont également placés dans la figure ci-dessous.
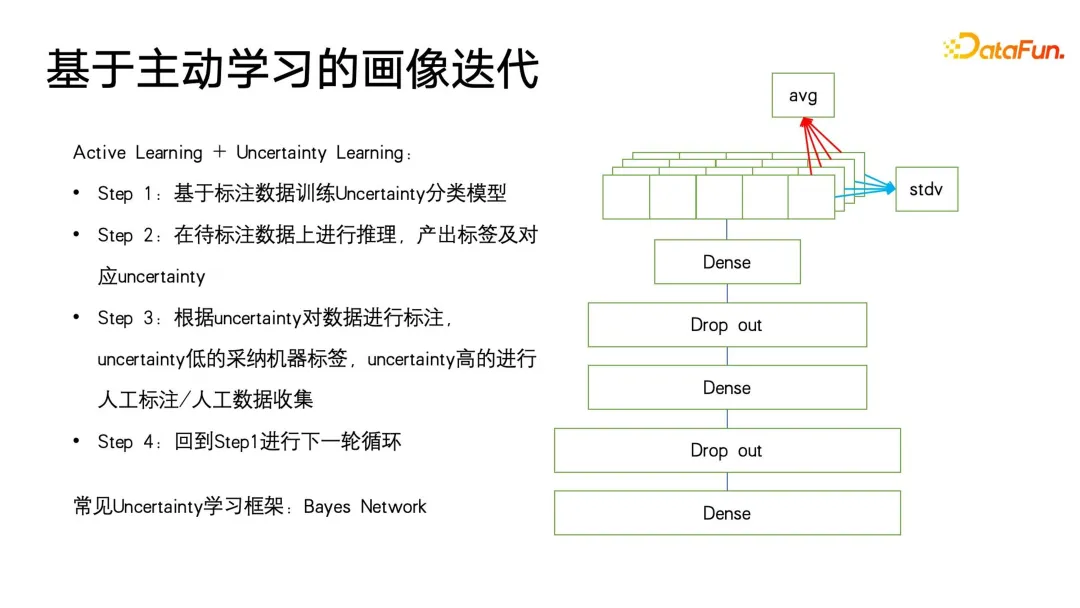
Dans le processus d'itération de portrait, il existe encore des angles morts qui ne peuvent pas être couverts. Par exemple, certains portraits d'utilisateurs ayant un comportement de faible consommation ne le sont toujours pas. très bien. En fin de compte, de nombreuses méthodes reviendront toujours aux méthodes de collecte manuelle. Cependant, nous avons tellement d'utilisateurs peu actifs que si nous ne pouvons sélectionner que des utilisateurs plus précieux et plus représentatifs pour l'étiquetage, nous pouvons collecter des données plus précieuses. Par conséquent, nous avons introduit un cadre d'apprentissage actif à faible coût sur l'apprentissage incertain. .
Tout d'abord, sur la base des données annotées existantes, entraîner un modèle de classification avec prédiction d'incertitude. La méthode utilisée est la méthode classique dans le domaine de l'apprentissage probabiliste - réseau bayésien. La caractéristique du réseau bayésien est que lors de la prédiction, il peut non seulement donner la probabilité, mais également prédire l'incertitude du résultat de la prédiction.
Le réseau bayésien est très facile à mettre en œuvre, comme le montre le côté droit de la figure ci-dessous. Ajoutez simplement quelques couches spéciales à la structure du réseau d'origine. Nous ajoutons des couches de suppression au milieu de ces réseaux pour supprimer aléatoirement les éléments. réseau feedforward. Le réseau bayésien contient plusieurs sous-réseaux, dont chacun a exactement les mêmes paramètres de réseau. Cependant, en raison des caractéristiques de la couche d'abandon, la probabilité que chaque paramètre de réseau soit abandonné de manière aléatoire est différente lorsqu'il est abandonné de manière aléatoire. formés pour l'inférence est également conservé lors de l'utilisation du drop out, ce qui est différent de la façon dont le drop out est utilisé dans d'autres domaines. Dans d'autres domaines, l'abandon n'est effectué que pendant la formation et tous les paramètres sont appliqués lors de l'inférence. Ce n'est que lorsque les valeurs de logit et de probabilité sont finalement calculées que le doublement d'échelle d'une valeur prédite provoqué par l'abandon est restauré.
La différence entre les réseaux bayésiens est que tout abandon aléatoire doit être conservé lors de l'inférence rétroactive, de sorte que chaque réseau donne une probabilité différente de cette étiquette, puis calcule cet ensemble de probabilités. La moyenne est en fait le résultat d'un vote et la valeur de probabilité que nous voulons prédire. En même temps, un calcul de variance est effectué sur cet ensemble de valeurs de probabilité pour exprimer l'incertitude de la prédiction. Lorsqu'un échantillon subit différentes expressions de paramètres d'abandon, la valeur de probabilité finale obtenue est différente. Plus la variance de la valeur de probabilité est grande, plus la certitude de probabilité dans le processus d'apprentissage est faible. Enfin, les échantillons de prédiction d'étiquettes présentant une incertitude élevée peuvent être étiquetés manuellement, et pour les étiquettes avec une certitude élevée, les résultats de l'étiquetage automatique peuvent être directement adoptés. Revenez ensuite à la première étape du cadre d'apprentissage actif pour faire du cycle. Ce qui précède est le cadre de base de l'apprentissage actif.
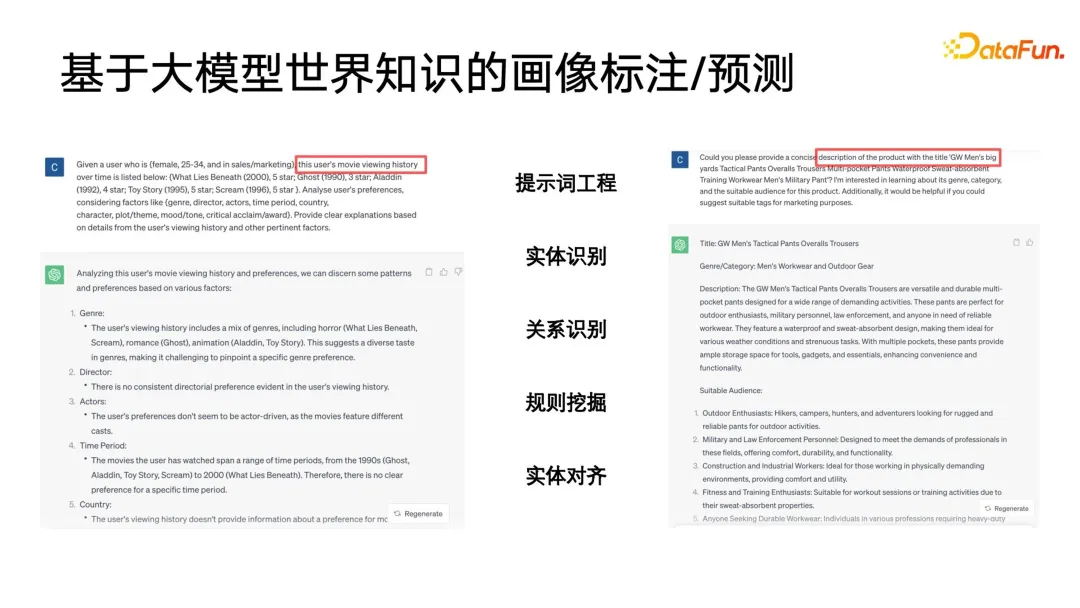
À l'ère des grands modèles, la connaissance du monde des grands modèles peut également être introduite pour l'annotation des portraits. La figure suivante donne deux exemples simples. Sur la gauche, un grand modèle est utilisé pour annoter les portraits des utilisateurs, et l'historique de visualisation de l'utilisateur est organisé dans un certain ordre pour former une invite. Vous verrez que le grand modèle peut fournir un aperçu très détaillé. analyses, telles que les genres, réalisateurs, acteurs, etc. qui pourraient plaire à l'utilisateur. A droite se trouve un grand modèle qui analyse le titre d'un produit, et donne le titre du produit pour que le grand modèle puisse deviner à quelles catégories il appartient.
À ce stade, nous avons découvert qu'un gros problème est que la sortie du grand modèle n'est pas structurée, une expression textuelle relativement primitive et nécessite un certain post-traitement. Par exemple, il est nécessaire d'effectuer la reconnaissance d'entités, la reconnaissance de relations, l'exploration de règles, l'alignement d'entités, etc. sur la sortie d'un grand modèle, et ces post-traitements appartiennent aux règles d'application de base dans la catégorie des graphes de connaissances ou des ontologies.
Pourquoi l'utilisation de la connaissance mondiale des grands modèles pour l'annotation d'images donne-t-elle de meilleurs résultats, et peut même remplacer une partie du travail ? Parce que les grands modèles sont formés sur un large éventail de connaissances sur les réseaux ouverts, tandis que les systèmes de recommandation, les moteurs de recherche, etc. ne disposent que de quelques données historiques d'interaction entre les utilisateurs et les bibliothèques de produits sur leurs propres plates-formes fermées. Ces données sont en réalité basées sur des journaux système. , dont beaucoup sont interdépendants, sont difficiles à interpréter à travers les connaissances fermées de la plate-forme existante, mais la connaissance mondiale du grand modèle peut nous aider à compléter les connaissances qui manquent dans le système fermé, nous aidant ainsi à dessiner une meilleure étiquetage ou prédiction de portrait. Le grand modèle peut même être compris comme une représentation abstraite de haute qualité du système conceptuel du monde lui-même. Ces systèmes conceptuels conviennent parfaitement aux portraits et aux systèmes d'étiquetage.
Enfin, résumons brièvement les limites actuelles des portraits d'utilisateurs et l'orientation future du développement.
La première question est de savoir comment améliorer encore la précision des images existantes. Les facteurs qui entravent l'amélioration de la précision comprennent les aspects suivants. Le premier est l'unification de l'identification virtuelle à la personne physique. En réalité, un utilisateur dispose de plusieurs appareils pour se connecter au même compte, et peut également disposer de plusieurs ports et canaux. pour se connecter. Par exemple, un utilisateur se connecte à différentes applications, mais ces applications appartiennent au même groupe. Pouvons-nous connecter des personnes physiques au sein du groupe, mapper tous les identifiants virtuels à la même personne, puis l'identifier ?
La seconde est la question de l'identification du sujet pour les comptes familiaux partagés. Ce problème est très courant dans le domaine de la vidéo, notamment dans le domaine des vidéos longues. Par exemple, l'utilisateur est évidemment un adulte d'environ 40 ans, mais les recommandations sont toutes des dessins animés. la famille partage un compte et chacun a des intérêts personnels différents. En réponse à cette situation, pouvons-nous utiliser certains moyens pour identifier l'heure actuelle et les comportements, afin de mettre à jour le portrait rapidement et en temps réel, puis de déterminer qui est le sujet actuel, puis de fournir des services personnalisés ciblés.
Le troisième est la prédiction d'intention en temps réel de la liaison multi-scénarios. Nous avons constaté que lorsque la plateforme a atteint un certain stade de développement, ses images de recherche et de promotion sont encore relativement fragmentées. Par exemple, parfois un utilisateur vient d'entrer dans une scène recommandée et est maintenant prêt à en proposer une meilleure. sur l'intention en temps réel de la scène recommandée à l'instant ? Si vous recherchez des mots recommandés ou si vous venez de rechercher quelque chose, pouvez-vous utiliser cette intention pour diffuser et prédire d'autres catégories de choses que l'utilisateur pourrait vouloir voir, et faire une prédiction d’intention.
La transition d'une ontologie fermée à une ontologie ouverte est également une question à résoudre de toute urgence dans le domaine de l'imagerie. Pendant longtemps, des normes industrielles relativement solides ont été utilisées pour définir l'ontologie, mais désormais, l'ontologie de nombreux systèmes est complètement ouverte aux mises à jour incrémentielles, telles que les plates-formes de vidéos courtes, et les différentes balises des vidéos courtes elles-mêmes continuent de le faire. grandir et exploser spontanément sous la création commune. De nombreux mots chauds et tags chauds continuent d'émerger au fil du temps. Comment améliorer l'actualité des images sur une ontologie ouverte, supprimer le bruit, puis explorer davantage et utiliser certaines méthodes pour nous aider à améliorer la précision des images est également une question qui mérite d'être étudiée.
Enfin, à l'ère de l'apprentissage profond, comment améliorer l'interprétabilité des algorithmes de profilage, en particulier les algorithmes de profilage qui appliquent l'apprentissage profond, et comment mieux implémenter de grands modèles dans les algorithmes de profilage, ce seront des orientations pour les recherches futures.

Ce ci-dessus est le contenu partagé cette fois, merci à tous !
A1 : Le lien d'application pour les portraits est en effet relativement long. Si votre portrait sert principalement des algorithmes, il existe alors en effet un écart de perte de précision entre la précision du portrait et celle des modèles en aval. En fait, je ne recommande pas particulièrement de faire le test portrait AB. Je pense qu'une meilleure façon de l'appliquer est de s'adresser aux opérateurs et de l'utiliser dans la sélection des utilisateurs et la publicité des investissements fixes et d'autres scénarios d'application de nature plus opérationnelle, tels que comme coupons pour de grosses ventes. Effectuez des tests AB dans des scénarios tels que la livraison ciblée. Parce que leurs effets sont directement basés sur votre portrait, vous pouvez envisager ce type de test AB collaboratif en ligne côté application avec un lien relativement court. De plus, je pourrais suggérer qu'en plus du test AB, nous envisagions également une autre méthode de test - la validation croisée, pour recommander à un utilisateur les résultats de tri en fonction des images avant et après optimisation, puis laisser l'utilisateur évaluer lequel est mieux. Par exemple, nous pouvons désormais constater que certains grands fabricants de modèles laisseront le modèle produire deux résultats, puis laisseront les utilisateurs décider quel grand modèle produira le meilleur texte. En fait, je pense qu’une telle vérification croisée pourrait être plus efficace, et elle est directement liée au portrait lui-même.
A2 : Cela ne signifie pas qu'il y a un abandon sur l'ensemble de test, mais cela signifie que lors du test de l'inférence, nous conserverons toujours les caractéristiques aléatoires de l'abandon dans le réseau pour l'inférence aléatoire.
A3 : Franchement, il n’existe actuellement pas de très bonne solution dans l’industrie. Mais il peut y avoir deux manières de procéder. La première consiste à faire appel à un tiers de confiance mutuelle pour effectuer le déploiement d'inférence de grands modèles localisés. Un autre concept nouveau, également récent, est appelé réseau fédéré, qui n'est pas un apprentissage fédéré. Vous pouvez jeter un œil à certaines des possibilités contenues dans les réseaux fédérés.
A4 : En plus de l'annotation, il y a aussi des analyses et des raisonnements des utilisateurs. Sur la base des portraits existants, nous pouvons déduire la prochaine intention de l'utilisateur, ou nous pouvons collecter une grande quantité de données utilisateur et utiliser un grand modèle pour analyser certains modèles d'utilisateurs régionaux ou autres sous contraintes. En fait, il existe des démos open source pour cela, vous pouvez explorer cette direction.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



