


L'illusion des grands modèles touche enfin à sa fin ?
Aujourd'hui, une publication sur la plateforme de médias sociaux Reddit a suscité de vives discussions parmi les internautes. L'article traite d'un article « Factualité longue dans les grands modèles de langage » soumis hier par Google DeepMind. Les méthodes et les résultats proposés dans l'article font conclure que l'illusion des grands modèles de langage n'est plus un problème.

Nous savons que les grands modèles linguistiques génèrent souvent du contenu contenant des erreurs factuelles lorsqu'ils répondent à des questions de recherche de faits sur des sujets ouverts. DeepMind a mené des recherches exploratoires sur ce phénomène.
Pour évaluer la factualité longue d'un modèle dans le domaine ouvert, les chercheurs ont utilisé GPT-4 pour générer LongFact, un ensemble d'invites contenant 38 sujets et des milliers de questions. Ils ont ensuite proposé d'utiliser le Search Augmented Fact Evaluator (SAFE) pour utiliser l'agent LLM comme évaluateur automatique de la factualité détaillée. L’objectif de SAFE est d’améliorer l’exactitude des évaluateurs de crédibilité factuelle.
Concernant SAFE, l'utilisation de LLM peut expliquer plus précisément l'exactitude de chaque instance. Ce processus de raisonnement en plusieurs étapes consiste à envoyer une requête de recherche à la recherche Google et à déterminer si les résultats de la recherche prennent en charge une instance spécifique.

Adresse papier : https://arxiv.org/pdf/2403.18802.pdf
Adresse GitHub : https://github.com/google-deepmind/long-form-factuality
De plus, les chercheurs ont proposé d'étendre le score F1 (F1@K) en un indicateur global pratique de forme longue. Ils équilibrent le pourcentage de faits pris en charge dans la réponse (précision) avec le pourcentage de faits fournis par rapport à un hyperparamètre qui représente la longueur de réponse préférée de l'utilisateur (rappel).
Les résultats empiriques montrent que les agents LLM peuvent atteindre des performances de notation supérieures à celles des humains. Sur un ensemble d'environ 16 000 faits individuels, SAFE était d'accord avec les annotateurs humains dans 72 % des cas, et sur un sous-ensemble aléatoire de 100 cas de désaccord, SAFE a atteint un taux de victoire de 76 %. Dans le même temps, SAFE est plus de 20 fois moins cher que les annotateurs humains.
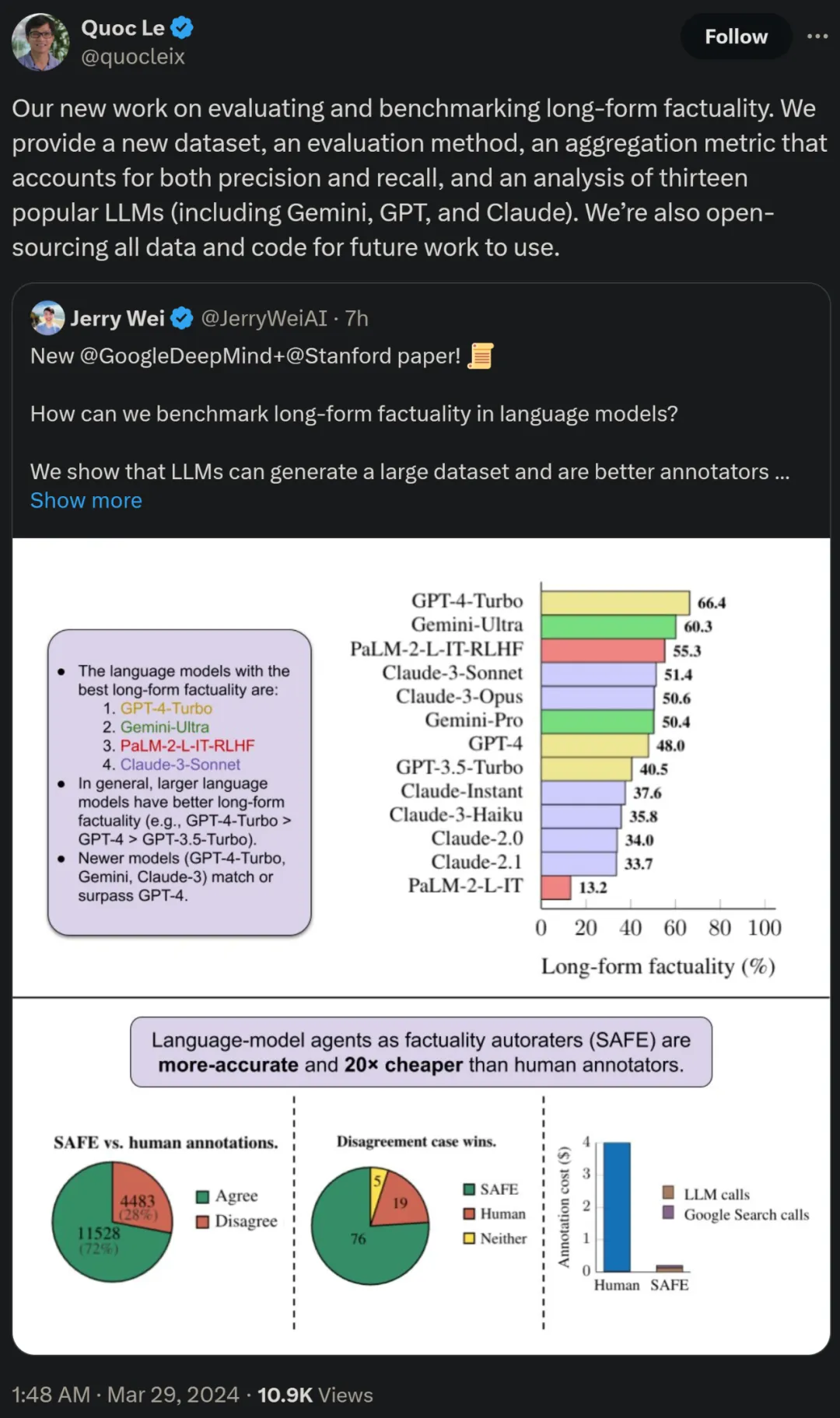
Les chercheurs ont également utilisé LongFact pour comparer 13 modèles de langage populaires dans quatre grandes séries de modèles (Gemini, GPT, Claude et PaLM-2), et ont constaté que des modèles de langage plus grands peuvent généralement obtenir de meilleurs résultats.
Quoc V. Le, l'un des auteurs de l'article et chercheur scientifique chez Google, a déclaré que ce nouveau travail sur l'évaluation et l'analyse comparative de la factualité longue durée propose un nouvel ensemble de données, une nouvelle méthode d'évaluation et une méthode qui équilibre la précision et la métrique agrégée de rappel. Dans le même temps, toutes les données et tous les codes seront open source pour les travaux futurs.
LONGFACT : Utiliser LLM pour générer de longs benchmarks factuels multi-sujets
Premier aperçu de l'ensemble d'invites LongFact généré à l'aide de GPT-4, qui contient 2 280 invites de recherche de faits qui nécessitait des réponses détaillées sur 38 sujets sélectionnés manuellement. Les chercheurs affirment que LongFact est le premier ensemble d’invites permettant d’évaluer la factualité détaillée dans divers domaines.
LongFact contient deux tâches : LongFact-Concepts et LongFact-Objects, distinguées selon que la question porte sur des concepts ou des objets. Les chercheurs ont généré 30 indices uniques pour chaque sujet, ce qui a donné 1 140 indices pour chaque tâche.

SAFE : agent LLM comme évaluateur automatique factuel
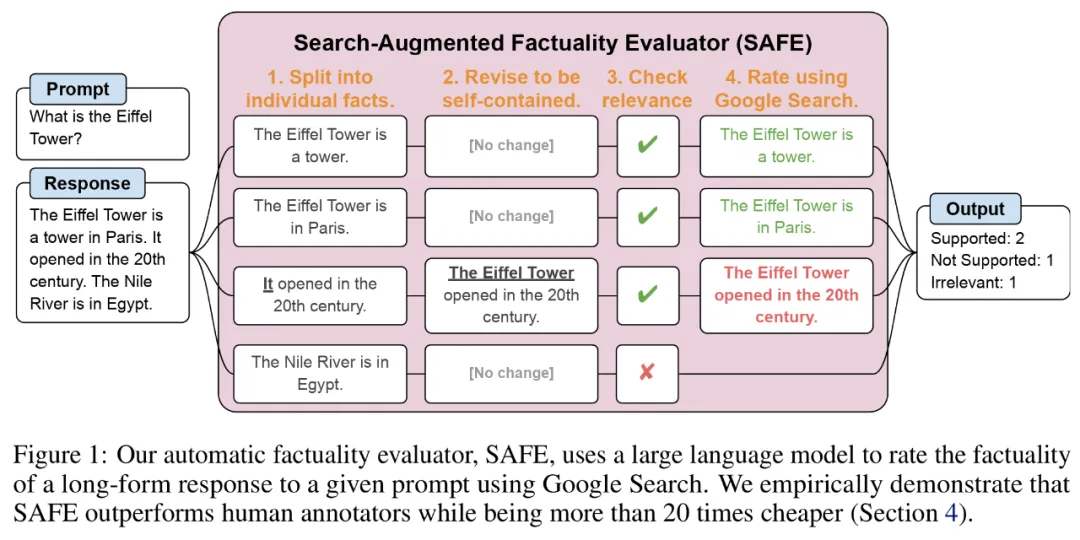
Les chercheurs ont proposé le Search Augmented Fact Evaluator (SAFE), et son principe de fonctionnement est le suivant :
a) Split réponses longues en faits indépendants distincts
b) Déterminer si chaque fait individuel est pertinent pour répondre à l'invite dans son contexte
;c) Pour chaque fait pertinent, lancez de manière itérative une requête de recherche Google dans un processus en plusieurs étapes et déterminez si les résultats de la recherche soutiennent ce fait.
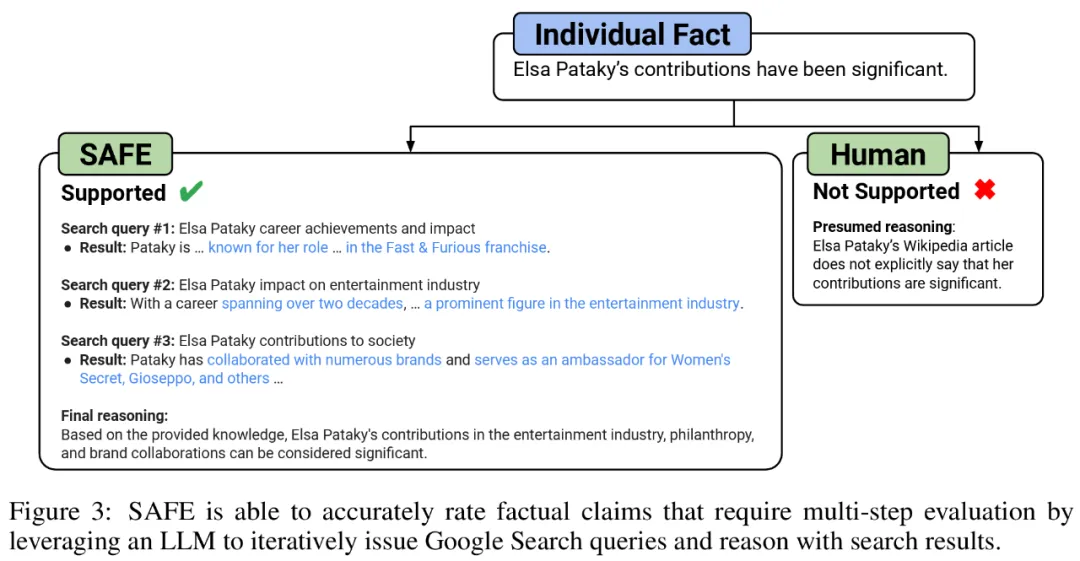
Ils pensent que l'innovation clé de SAFE est d'utiliser des modèles linguistiques comme agents pour générer des requêtes de recherche Google en plusieurs étapes et de réfléchir soigneusement pour savoir si les résultats de la recherche soutiennent les faits. La figure 3 ci-dessous montre un exemple de chaîne de raisonnement.
Pour diviser la réponse longue en faits indépendants distincts, les chercheurs ont d'abord incité le modèle linguistique à diviser chaque phrase de la réponse longue en faits distincts, puis ont ordonné au modèle de séparer les références ambiguës telles que les pronoms) avec les entités correctes auxquelles elles font référence dans le contexte de réponse, modifiant chaque fait individuel pour qu'il soit indépendant.
Pour noter chaque fait indépendant, ils utilisent un modèle de langage pour déterminer si ce fait est pertinent par rapport à l'invite répondue dans le contexte de réponse, puis utilisent une méthode en plusieurs étapes pour évaluer chaque fait pertinent restant comme « pris en charge ». ou "non pris en charge". Les détails sont présentés dans la figure 1 ci-dessous.
A chaque étape, le modèle génère une requête de recherche basée sur les faits à noter et les résultats de recherche précédemment obtenus. Après un certain nombre d'étapes, le modèle effectue une inférence pour déterminer si les résultats de la recherche confirment ce fait, comme le montre la figure 3 ci-dessus. Une fois que tous les faits ont été évalués, les mesures de sortie de SAFE pour une paire invite-réponse donnée sont le nombre de faits « à l'appui », le nombre de faits « non pertinents » et le nombre de faits « non pris en charge ».
Les agents LLM deviennent de meilleurs annotateurs de faits que les humains
Pour évaluer quantitativement la qualité des annotations obtenues à l'aide de SAFE, les chercheurs ont utilisé des annotations humaines participatives. Les données contiennent 496 paires de réponses rapides, où les réponses ont été divisées manuellement en faits individuels (16 011 faits individuels au total), et chaque fait individuel a été manuellement étiqueté comme étant pris en charge, non pertinent ou non pris en charge.
Ils ont comparé directement les annotations SAFE et les annotations humaines pour chaque fait et ont constaté que SAFE était d'accord avec les humains sur 72,0 % des faits individuels, comme le montre la figure 4 ci-dessous. Cela montre que SAFE atteint des performances de niveau humain sur la plupart des faits individuels. Un sous-ensemble de 100 faits individuels issus d'entretiens aléatoires a ensuite été examiné pour lesquels les annotations de SAFE n'étaient pas cohérentes avec celles des évaluateurs humains.
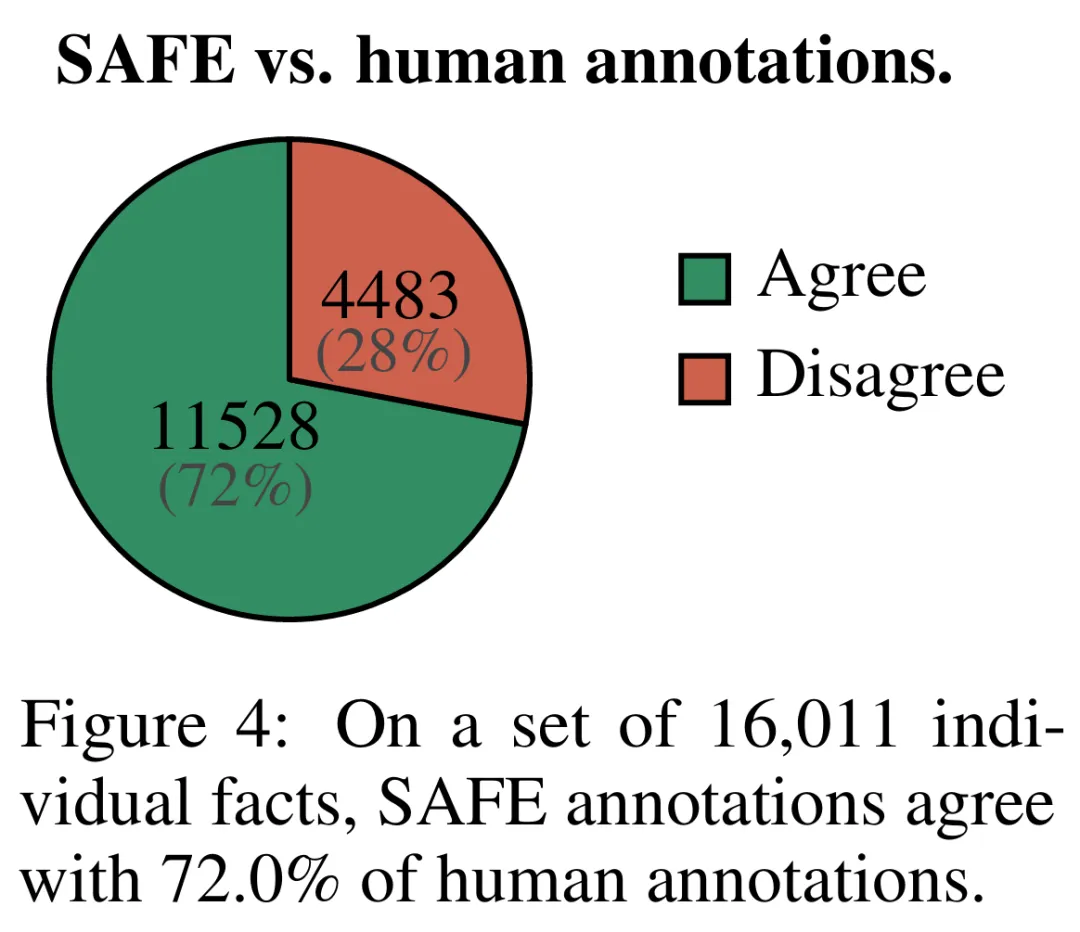
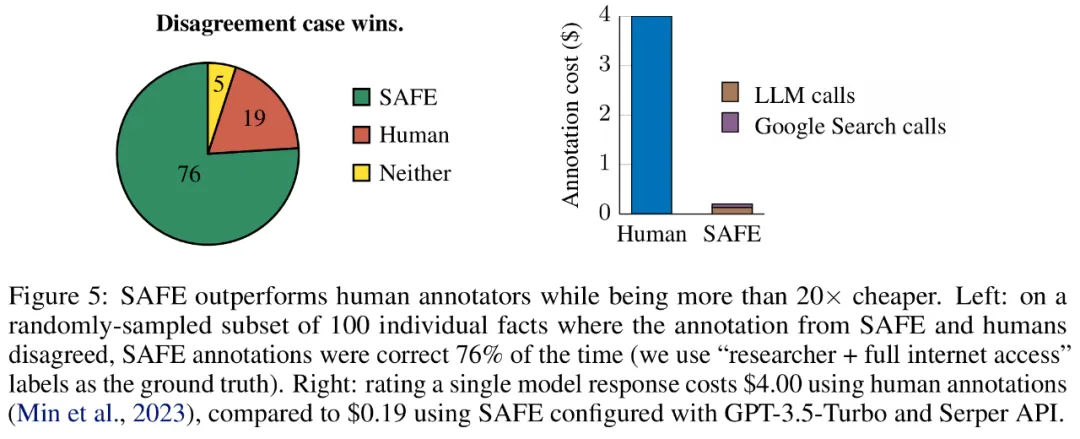
Les chercheurs ont réannoté manuellement chaque fait (permettant d'accéder à la recherche Google, et pas seulement à Wikipédia, pour une annotation plus complète) et ont utilisé ces étiquettes comme vérité terrain. Ils ont constaté que dans ces cas de désaccord, les annotations SAFE étaient correctes dans 76 % des cas, tandis que les annotations humaines n'étaient correctes que dans 19 % des cas, ce qui représente un taux de victoire de 4 contre 1 pour SAFE. Les détails sont présentés dans la figure 5 ci-dessous.
Ici, les prix des deux plans d'annotation méritent qu'on s'y attarde. Le coût de l'évaluation d'une réponse de modèle unique à l'aide d'annotations humaines est de 4 $, tandis que le SAFE utilisant GPT-3.5-Turbo et l'API Serper n'est que de 0,19 $.
Tests de référence des séries Gemini, GPT, Claude et PaLM-2
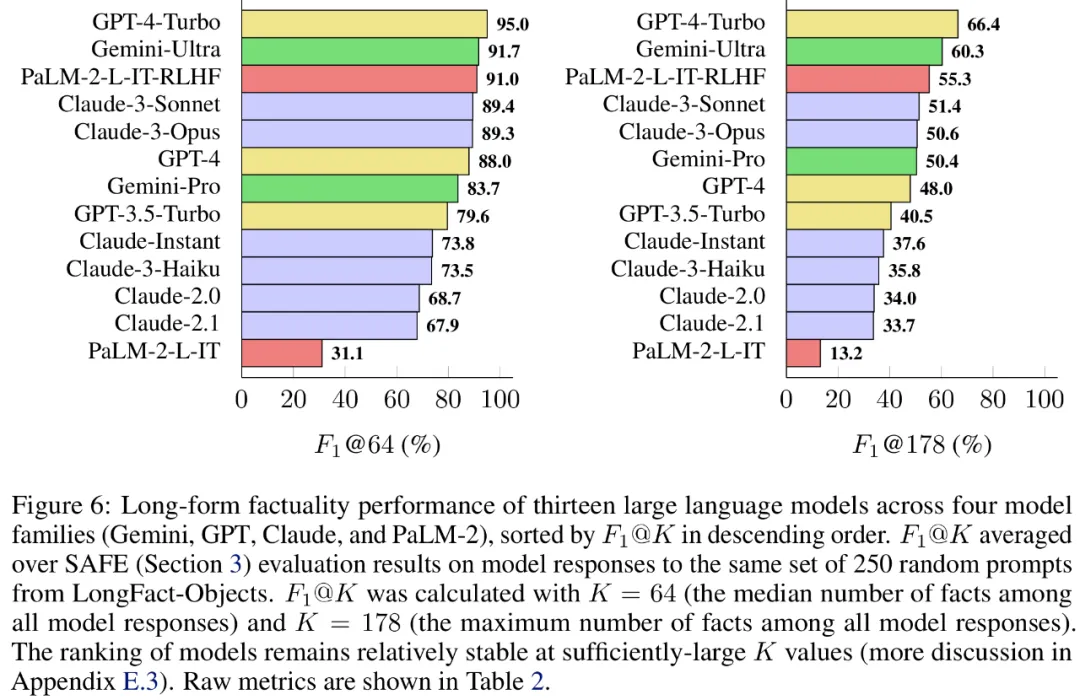
Enfin, les chercheurs ont mené LongFact sur les quatre séries de modèles (Gemini, GPT, Claude et PaLM-2) dans le tableau 1. ci-dessous. 2) Réalisation de tests de référence approfondis sur 13 grands modèles de langage.
Plus précisément, ils ont évalué chaque modèle en utilisant le même sous-ensemble aléatoire de 250 indices dans LongFact-Objects, puis ont utilisé SAFE pour obtenir les métriques d'évaluation brutes de la réponse de chaque modèle et ont utilisé la polymérisation métrique F1@K.

Il a été constaté qu'en général, les modèles linguistiques plus grands permettent d'obtenir une meilleure factualité longue durée. Comme le montrent la figure 6 et le tableau 2 ci-dessous, GPT-4-Turbo est meilleur que GPT-4, GPT-4 est meilleur que GPT-3.5-Turbo, Gemini-Ultra est meilleur que Gemini-Pro et PaLM-2-L. -IT-RLHF Mieux que PaLM-2-L-IT.
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle est la différence entre l'écran d'origine et l'écran assemblé ?
Quelle est la différence entre l'écran d'origine et l'écran assemblé ?
 Solution de rapport d'erreur de fichier SQL d'importation Mysql
Solution de rapport d'erreur de fichier SQL d'importation Mysql
 Comment télécharger le panneau de configuration nvidia
Comment télécharger le panneau de configuration nvidia
 Java conserve deux décimales
Java conserve deux décimales
 Comment résoudre le problème du démarrage lent de l'ordinateur
Comment résoudre le problème du démarrage lent de l'ordinateur
 Que faire si notepad.exe ne répond pas
Que faire si notepad.exe ne répond pas
 Causes et solutions du délai d'expiration de la passerelle 504
Causes et solutions du délai d'expiration de la passerelle 504
 Mise à niveau du Samsung s5830
Mise à niveau du Samsung s5830








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



