


La version Microsoft de Sora est née !
Sora est populaire mais de source fermée, ce qui a posé des défis considérables à la communauté universitaire. Les chercheurs ne peuvent qu’essayer d’utiliser l’ingénierie inverse pour reproduire ou étendre Sora.
Bien que des stratégies de transformateur de diffusion et de correctifs spatiaux aient été proposées, il est encore difficile d'atteindre les performances de Sora, sans parler du manque de puissance de calcul et d'ensembles de données.
Cependant, une nouvelle vague de charges lancées par les chercheurs pour reproduire Sora arrive !
Tout à l'heure, l'Université Lehigh s'est associée à l'équipe Microsoft pour développer un nouveau framework d'agents multi-IA : Mora.

Adresse papier : https://arxiv.org/abs/2403.13248
Oui, l'idée deLehigh University et Microsoft repose sur des agents d'IA.
Mora ressemble plus à la génération vidéo généraliste de Sora. En intégrant plusieurs agents d'IA visuelle SOTA, les capacités universelles de génération vidéo démontrées par Sora peuvent être reproduites.

Plus précisément, Mora est capable d'exploiter plusieurs agents visuels pour simuler avec succès les capacités de génération vidéo de Sora dans une variété de tâches, notamment :
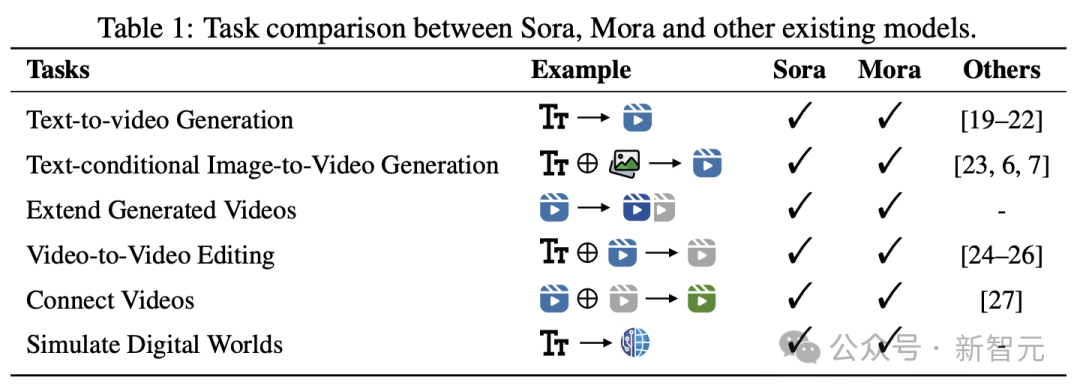
-Génération de texte en vidéo
Basé sur du texte conditionné génération d'image en vidéo
- Extension de la vidéo générée
- Montage vidéo en vidéo
- Vidéo d'assemblage
- Monde numérique analogique
Les résultats montrent, Mora a réalisé une performance proche de Sora dans ces tâches.
Il convient de mentionner que ses performances dans les tâches de génération de texte en vidéo surpassent les modèles open source existants et se classent au deuxième rang parmi tous les modèles, juste derrière Sora.
Cependant, il existe encore un net écart avec Sora en termes de performances globales.

Mora peut générer des vidéos haute résolution et cohérentes dans le temps basées sur des invites textuelles, avec une résolution de 1024 × 576, une durée de 12 secondes et un total de 75 images.
Mora a essentiellement restauré toutes les capacités de Sora. Comment l'incarner ?
Génération de texte en vidéo

Conseils : Un récif de corail vibrant regorgeant de vie sous l'océan bleu cristallin, avec des poissons colorés nageant parmi les coraux, des rayons de soleil filtrant à travers l'eau, et un doux courant faisant bouger les plantes marines.

Conseils : Une chaîne de montagnes majestueuse recouverte de neige, avec les sommets touchant les nuages et un lac aux eaux cristallines à sa base, reflétant les montagnes et le ciel, créant un miroir naturel à couper le souffle.

Conseils : Au milieu d'un vaste désert, une ville dorée du désert apparaît à l'horizon, son architecture est un mélange d'éléments égyptiens anciens et futuristes. La ville est entourée d'une énergie rayonnante barrière, en l'air, sept
Génération d'une image conditionnelle basée sur du texte en vidéo
Entrez dans cette "image de nuage réaliste classique avec le mot SORA".

Astuce : Une image d'un nuage réaliste qui épelle "SORA".
L'effet généré par le modèle Sora est comme ceci.

La vidéo générée par Mora n'est pas mauvaise du tout.

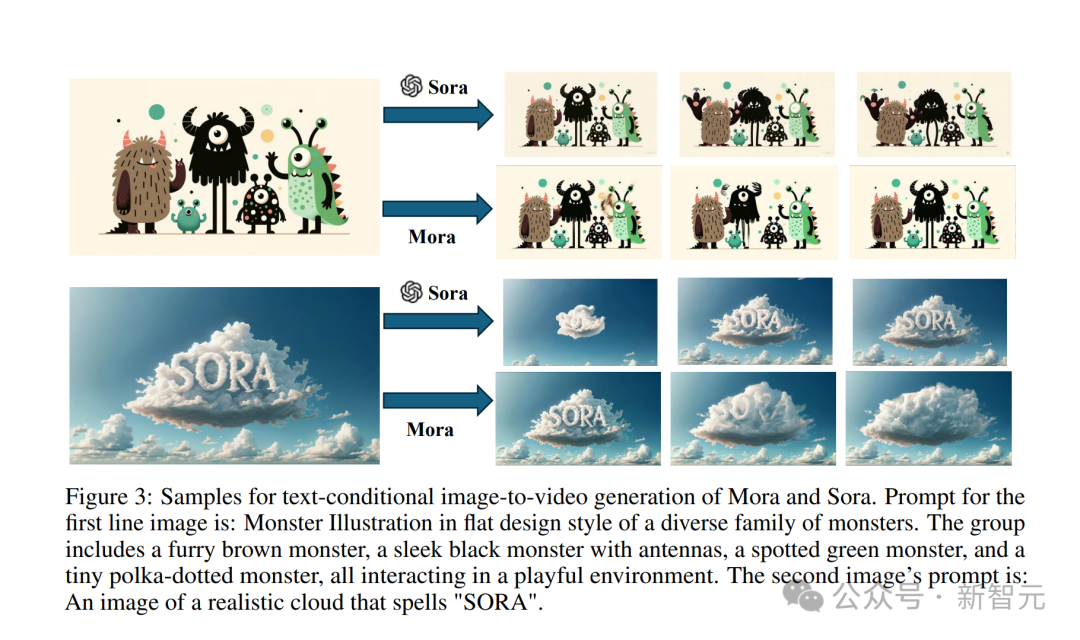
Entrez également une photo d'un petit monstre.

Astuce : Illustration de monstre dans un style design plat d'une famille diversifiée de monstres. Le groupe comprend un monstre brun à fourrure, un monstre noir élégant avec des antennes, un monstre vert tacheté et un petit monstre à pois. tous interagissent dans un environnement ludique.
Sora le convertit en effet vidéo, donnant vie à ces petits monstres.
Mora fait aussi bouger les petits monstres, mais elle est évidemment un peu instable, et les personnages de dessins animés sur la photo n'ont pas l'air cohérents.

Développez la vidéo générée
Donnez-moi d'abord une vidéo

Sora peut générer des vidéos IA stables avec un style cohérent.

Mais dans la vidéo générée par Mora, le cycliste devant s'est retrouvé avec son vélo parti et la personne déformée, donc l'effet n'était pas très bon.

Video to Video Editor
donne une invite "Changez la scène en une voiture ancienne des années 1920" et saisissez une vidéo. 
Sora a l'air très soyeuse après le changement de style.

La création par Mora d'une voiture à l'ancienne est un peu irréaliste en raison de son délabrement.

Splice Videos
Entrez deux vidéos, puis terminez de les assembler.


Vidéo épissée de Mora

Analogique du monde numérique

Après nombre de manifestations, tout le monde est satisfait de la vidéo de Mora. La capacité de générer Vous devez comprendre.
Par rapport à OpenAI Sora, les performances de Mora dans six tâches sont très proches, mais il y a aussi de grosses lacunes.
Génération de texte en vidéo
Plus précisément, le score de qualité vidéo de Mora de 0,792 est juste derrière celui de Sora (0,797) et dépasse les meilleurs modèles open source actuels (tels que VideoCrafter1).
En termes de cohérence des objets, Mora a obtenu un score de 0,95, ce qui est le même que Sora, montrant une excellente cohérence tout au long de la vidéo.
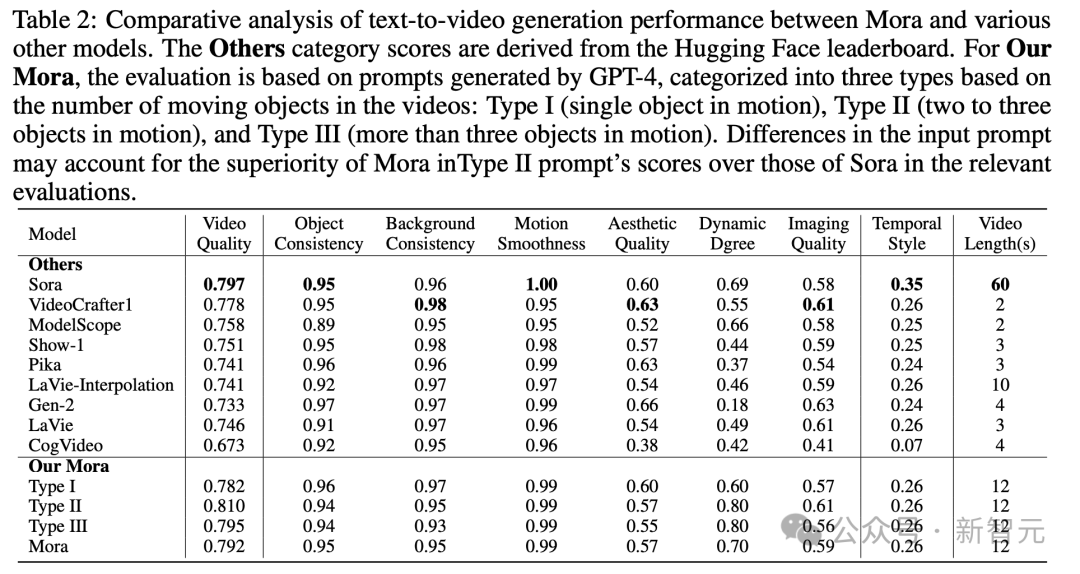
Dans l'image ci-dessous, la fidélité visuelle de la génération texte-vidéo Mora est très frappante, reflétant des images haute résolution, une grande attention aux détails et une représentation vivante de la scène.

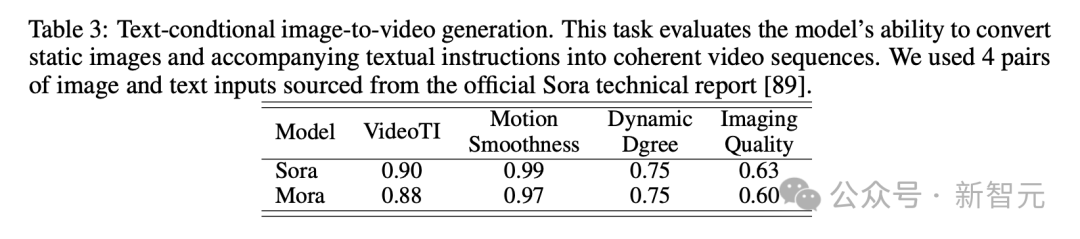
Dans la tâche de génération d'images basée sur des conditions de texte, Sora est certainement le modèle le plus parfait dans sa capacité à convertir des images et des instructions textuelles en vidéos cohérentes.
Cependant, les résultats de Mora sont très différents de ceux de Sora.
Vidéo générée par l'extension
En regardant le test vidéo généré par l'extension, les résultats en termes de continuité et de qualité sont également que Mora est relativement proche de Sora.
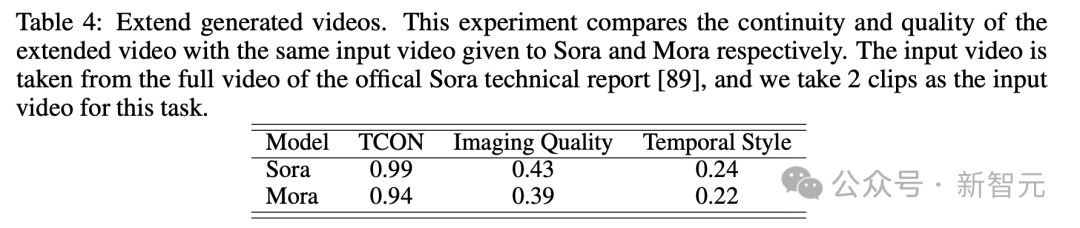
Bien que Sora soit en tête, la capacité de Mora, notamment à suivre les styles temporels et à étendre les vidéos existantes sans perte significative de qualité, prouve son efficacité dans le domaine de l'extension vidéo.

Montage vidéo à vidéo + assemblage vidéo
Pour le montage vidéo à vidéo, Mora est proche de Sora dans sa capacité à maintenir une cohérence visuelle et stylistique. Dans la tâche de raccordement vidéo, Mora peut également raccorder de manière transparente différentes vidéos.
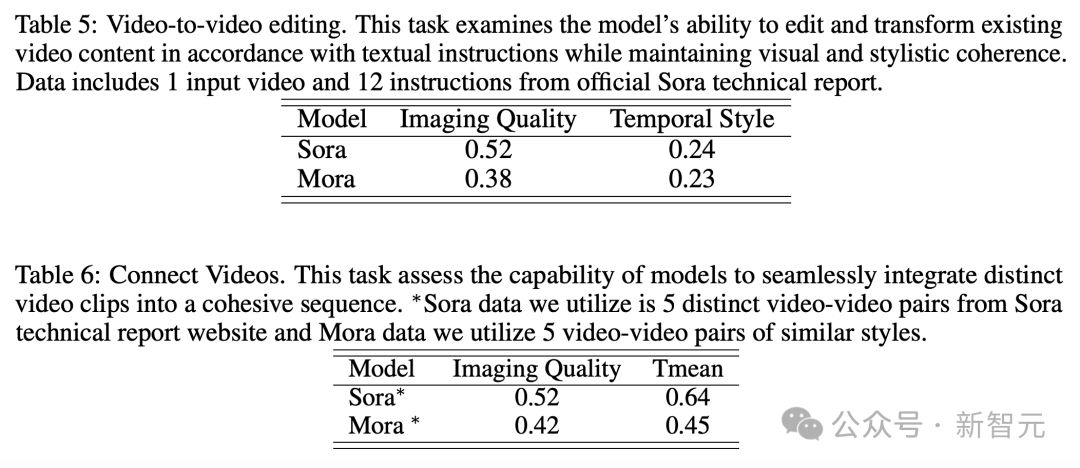
Dans cet exemple, Sora et Mora ont été chargés de modifier le décor dans un style des années 1920 tout en conservant la couleur rouge de la voiture.


Simuler le monde numérique
Il y a aussi la tâche finale de simuler le monde numérique. Mora peut également avoir la capacité de créer un environnement virtuel comme Sora. Cependant, en termes de qualité, c'est pire que Sora.


Comment Mora, un framework multi-agent, résout-il les limites des modèles de génération vidéo actuels ?
La clé est d'effectuer de manière flexible une série de tâches de génération vidéo pour répondre aux divers besoins des utilisateurs en décomposant le processus de génération vidéo en plusieurs sous-tâches et en affectant des agents dédiés à chaque tâche.
Pendant le processus d'inférence, Mora génère une image ou une vidéo intermédiaire, conservant ainsi la variété visuelle, le style et la qualité trouvés dans les modèles texte-image et améliorant les capacités d'édition.

En coordonnant efficacement les agents qui gèrent les tâches de conversion de texte en image, d'image en image, d'image en vidéo et de vidéo en vidéo, Mora est capable de gérer une gamme de tâches de génération vidéo complexes, offrant une flexibilité d'édition exceptionnelle. et le réalisme visuel.
En résumé, les principales contributions de l'équipe sont les suivantes :
- Un framework multi-agent innovant et une interface intuitive pour permettre aux utilisateurs de configurer différents composants et d'organiser les processus de tâches.
- L'auteur a découvert que grâce au travail collaboratif de plusieurs agents (y compris la conversion de texte en images, d'images en vidéos, etc.), la qualité de la génération vidéo peut être considérablement améliorée. Le processus commence par le texte, qui est converti en images, puis les images et le texte sont convertis en vidéos, et enfin les vidéos sont optimisées et éditées.
- Mora démontre des performances supérieures dans 6 tâches liées à la vidéo, surpassant les modèles open source existants. Cela prouve non seulement l'efficacité de Mora, mais démontre également son potentiel en tant que cadre polyvalent.
Dans différentes tâches de génération vidéo, plusieurs agents ayant des expertises différentes sont généralement nécessaires pour travailler ensemble, chaque agent fournissant un résultat dans son domaine d'expertise.
À cette fin, l'auteur définit 5 types d'agents de base : la sélection et la génération d'invites, la génération de texte à image, la génération d'image à image, la génération d'image à vidéo et la génération de vidéo à vidéo. .
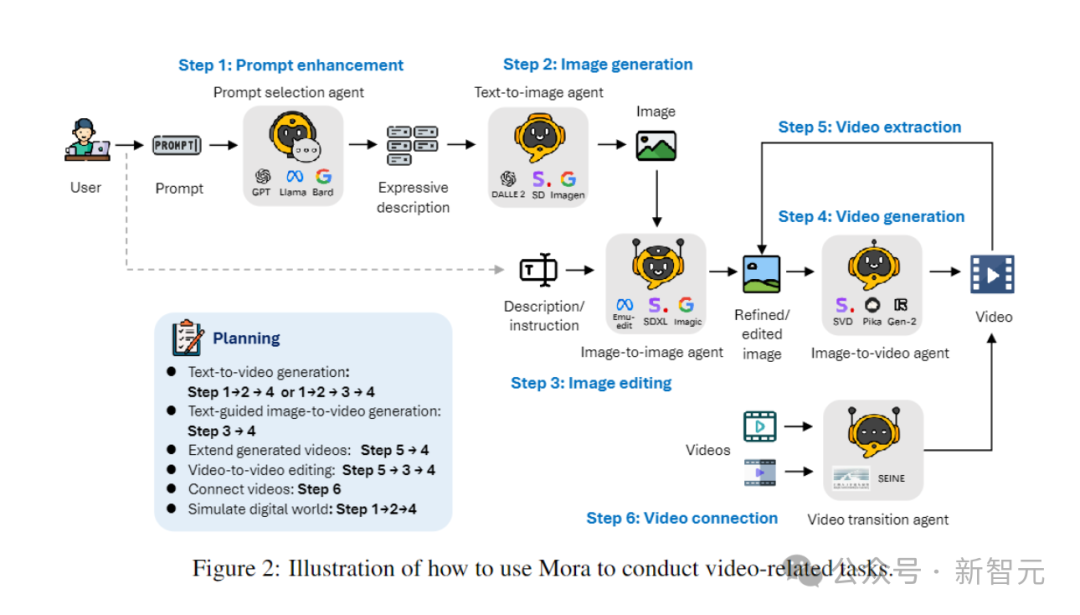
- Agent de sélection et de génération d'invite :
Avant de commencer à générer l'image initiale, l'invite de texte passe par une série d'étapes rigoureuses de traitement et d'optimisation. Cet agent peut exploiter de grands modèles de langage (tels que GPT-4) pour analyser avec précision le texte, extraire des informations et des actions clés et améliorer considérablement la pertinence et la qualité des images générées.
- Agent de génération de texte en image :
Cet agent est chargé de convertir les descriptions de texte enrichi en images de haute qualité. Sa fonctionnalité principale est de comprendre et de visualiser en profondeur la saisie de texte complexe, permettant la création d'images visuelles détaillées et précises basées sur les descriptions textuelles fournies.
- Agent de génération d'image à image :
Modifiez les images source existantes selon des instructions textuelles spécifiques. Il interprète avec précision les signaux textuels et ajuste les images sources en conséquence, depuis des modifications subtiles jusqu'à des transformations complètes. En utilisant des modèles pré-entraînés, il peut fusionner efficacement les descriptions textuelles et les représentations visuelles, permettant l'intégration de nouveaux éléments, des ajustements aux styles visuels ou des modifications dans la composition des images.
- Agent de génération d'image vers vidéo :
Après la génération initiale d'images, cet agent est chargé de convertir les images statiques en vidéos dynamiques. Il analyse le contenu et le style de l'image initiale pour générer des images ultérieures afin d'assurer la cohérence et la consistance visuelle de la vidéo, démontrant la capacité du modèle à comprendre, reproduire l'image initiale, ainsi qu'à prévoir et mettre en œuvre le développement logique de la scène.
- Agent de collage vidéo :
Cet agent assure une transition fluide et visuellement cohérente entre deux vidéos en utilisant sélectivement leurs images clés. Il identifie avec précision les éléments et styles communs dans deux vidéos, produisant une vidéo à la fois cohérente et visuellement attrayante.
Génération de texte en image
Les chercheurs utilisent des modèles texte en image à grande échelle pré-entraînés pour générer des premières images représentatives et de haute qualité.
La première implémentation utilise Stable Diffusion XL.
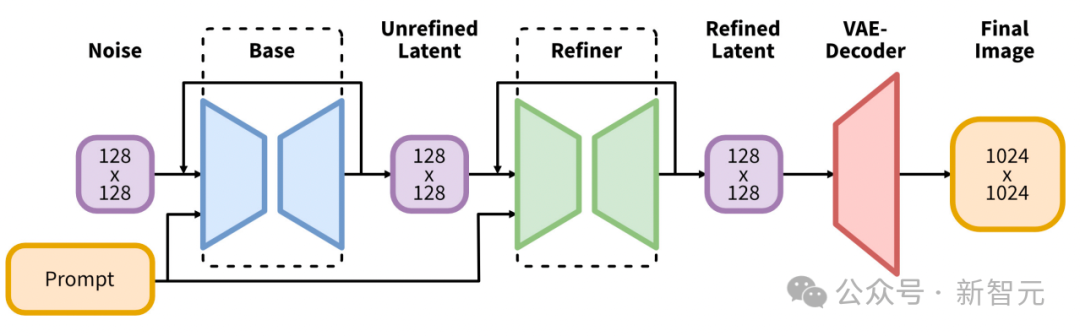
Il introduit une évolution significative dans l'architecture et les méthodes des modèles de diffusion latente pour la synthèse texte-image, établissant une nouvelle référence dans le domaine.
Le cœur de son architecture est un réseau fédérateur UNet étendu, trois fois plus grand que le fédérateur utilisé dans les versions précédentes de Stable Diffusion 2.
Cette expansion est principalement réalisée en augmentant le nombre de blocs d'attention et un plus large éventail de contextes d'attention croisée, et est facilitée par l'intégration d'un système d'encodage de texte double.
Le premier encodeur est basé sur OpenCLIP ViT-bigG, tandis que le deuxième encodeur exploite CLIP ViT-L, permettant une interprétation plus riche et plus nuancée du texte saisi en épissant les sorties de ces encodeurs.

Cette innovation architecturale est complétée par l'introduction de plusieurs nouveaux schémas de conditionnement qui ne nécessitent aucune supervision externe, améliorant ainsi la flexibilité du modèle et sa capacité à générer des images dans plusieurs rapports d'aspect.
De plus, SDXL propose un modèle de raffinement qui utilise une transformation post-hoc d'image en image pour améliorer la qualité visuelle des images générées.
Ce processus de raffinement utilise une technologie de débruitage pour affiner davantage l'image de sortie sans affecter l'efficacité ou la vitesse du processus de génération.
Génération d'image à image
Dans ce processus, le chercheur a utilisé le cadre initial pour implémenter InstructPix2Pix comme agent de génération d'image à image.

InstructPix2Pix est soigneusement conçu pour une édition d'image efficace basée sur des instructions en langage naturel.
Le cœur du système intègre les connaissances approfondies de deux modèles pré-entraînés : GPT-3 pour générer des instructions d'édition et des titres édités basés sur des descriptions de texte ; Stable Diffusion pour convertir ces entrées textuelles en sorties visuelles.
Cette approche ingénieuse affine d'abord GPT-3 sur un ensemble de données organisé de légendes d'images et d'instructions d'édition correspondantes, ce qui donne lieu à un modèle capable de suggérer de manière créative des modifications judicieuses et de générer des légendes modifiées.
Après cela, le modèle de diffusion stable amélioré par la technologie Prompt-to-Prompt génère des paires d'images (avant et après édition) basées sur les sous-titres générés par GPT-3.
Entraînez ensuite le modèle de diffusion conditionnelle du noyau InstructPix2Pix sur l'ensemble de données généré.
InstructPix2Pix exploite directement les instructions de texte et les images d'entrée pour effectuer l'édition en un seul passage.
Cette efficacité est encore améliorée en utilisant des conseils sans classificateur pour les conditions d'image et d'instruction, permettant au modèle d'équilibrer la fidélité de l'image brute et le respect des instructions d'édition.
Génération d'image en vidéo
Dans les agents de génération de texte en vidéo, l'agent de génération vidéo joue un rôle important pour assurer la qualité et la cohérence de la vidéo.
La première implémentation du chercheur consiste à utiliser le modèle actuel de génération de vidéo SOTA, Stable Video Diffusion, pour générer des vidéos.

L'architecture SVD exploite les atouts de Stable Diffusion v2.1, un LDM développé à l'origine pour la synthèse d'images, étendant ses capacités pour gérer la complexité temporelle inhérente au contenu vidéo, introduisant ainsi un moyen de générer des images haute résolution. vidéos méthodes avancées.
Le cœur du modèle SVD suit un système de formation en trois étapes, commençant par la corrélation texte-image, et le modèle apprend une représentation visuelle robuste à partir d'un ensemble d'images différentes. Cette base permet au modèle de comprendre et de générer des motifs visuels et des textures complexes.
Dans la deuxième étape, le pré-entraînement vidéo, le modèle est exposé à de grandes quantités de données vidéo, lui permettant d'apprendre la dynamique temporelle et les modèles de mouvement en combinant les couches de convolution temporelle et d'attention avec leurs homologues spatiales.
La formation est effectuée sur des ensembles de données gérés par le système, garantissant que le modèle apprend à partir d'un contenu vidéo pertinent et de haute qualité.
La dernière étape est le réglage fin de la vidéo de haute qualité, qui se concentre sur l'amélioration de la capacité du modèle à générer des vidéos avec une résolution et une fidélité plus élevées en utilisant des ensembles de données plus petits mais de meilleure qualité.
Cette stratégie de formation en couches, complétée par un nouveau processus de gestion des données, permet à SVD de produire avec brio une synthèse texte-vidéo et image-vidéo de pointe avec des détails, un réalisme et des performances extraordinaires. le temps et la cohérence.
Épissage de vidéos
Pour cette tâche, les chercheurs ont utilisé SEINE pour assembler les vidéos.
SEINE est construit sur la base de l'agent LaVie modèle T2V pré-entraîné.
SEINE se concentre sur un modèle de diffusion vidéo masquée stochastique qui génère des transitions basées sur des descriptions textuelles.
En intégrant des images de différentes scènes avec des commandes basées sur du texte, SEINE peut générer des vidéos de transition qui maintiennent la cohérence et la qualité visuelle.
De plus, le modèle peut être étendu à des tâches telles que l'animation image-vidéo et la prédiction vidéo de régression blanche.
- Cadre innovant et flexibilité :
Mora introduit un cadre de génération vidéo multi-agent révolutionnaire qui élargit considérablement les possibilités dans ce domaine, permettant d'effectuer diverses tâches devenues possibles .
Il simplifie non seulement le processus de conversion de texte en vidéo, mais simule également le monde numérique, faisant preuve d'une flexibilité et d'une efficacité sans précédent.
- Contribution Open Source :
La nature open source de Mora est une contribution importante à la communauté de l'IA, jetant les bases de la recherche future en fournissant une base solide qui encourage le développement et l'amélioration ultérieurs.
Cela rendra non seulement la technologie avancée de génération vidéo plus populaire, mais favorisera également la coopération et l'innovation dans ce domaine.
- Les données vidéo sont cruciales :
Capturer les nuances des mouvements humains nécessite des séquences vidéo fluides et haute résolution. Cela permet de montrer en détail tous les aspects de la dynamique, y compris l'équilibre, la posture et l'interaction avec l'environnement.
Mais les ensembles de données vidéo de haute qualité proviennent principalement de sources professionnelles telles que des films, des émissions de télévision et des séquences de jeux propriétaires. Ils contiennent souvent du matériel protégé par le droit d’auteur qui est difficile à collecter ou à utiliser légalement.
L'absence de ces ensembles de données rend difficile pour les modèles génératifs vidéo comme Mora de simuler des actions humaines dans des environnements réels, comme marcher ou faire du vélo.
- La différence entre masse et longueur :
Bien que Mora puisse effectuer des tâches similaires à Sora, la qualité de la vidéo générée n'est évidemment pas élevée dans les scènes impliquant un grand nombre d'objets en mouvement, et la qualité diminue à mesure que la durée de la vidéo augmente, surtout après qu'elle dépasse 12 secondes.
- Capacité de suivi d'instructions :
Bien que Mora puisse inclure tous les objets spécifiés par l'invite dans la vidéo, il est difficile d'interpréter et d'afficher avec précision la dynamique de mouvement décrite dans l'invite, telle que la vitesse de déplacement.
De plus, Mora ne peut pas contrôler la direction du mouvement de l'objet, comme faire bouger l'objet vers la gauche ou la droite.
Ces limitations sont principalement dues au fait que la génération vidéo de Mora est basée sur la méthode image-vidéo, plutôt que d'obtenir directement des instructions à partir d'invites textuelles.
- Alignement des préférences humaines :
En raison du manque d'informations d'annotation humaine dans le domaine vidéo, les résultats expérimentaux peuvent ne pas toujours être conformes aux préférences visuelles humaines.
Par exemple, l'une des tâches de montage vidéo ci-dessus nécessite de générer une vidéo de transition d'un homme se transformant progressivement en femme, ce qui semble très illogique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



