


Un simple croquis peut être transformé en une peinture multi-styles en un seul clic, et des descriptions supplémentaires peuvent être ajoutées dans le cadre d'une étude lancée conjointement par la CMU et Adobe.
Le professeur adjoint de la CMU, Junyan Zhu, est l'auteur de l'étude et son équipe a publié une étude connexe lors de la conférence ICCV 2021. Cette étude montre comment un modèle GAN existant peut être personnalisé avec un seul ou quelques croquis dessinés à la main pour générer des images qui correspondent au croquis.

Comment est l'effet ? Nous l'avons essayé et sommes arrivés à la conclusion qu'il est très jouable. Les styles d'images de sortie sont divers, notamment le style cinématographique, les modèles 3D, l'animation, l'art numérique, le style photographique, le pixel art, l'école fantastique, le néon punk et les bandes dessinées.
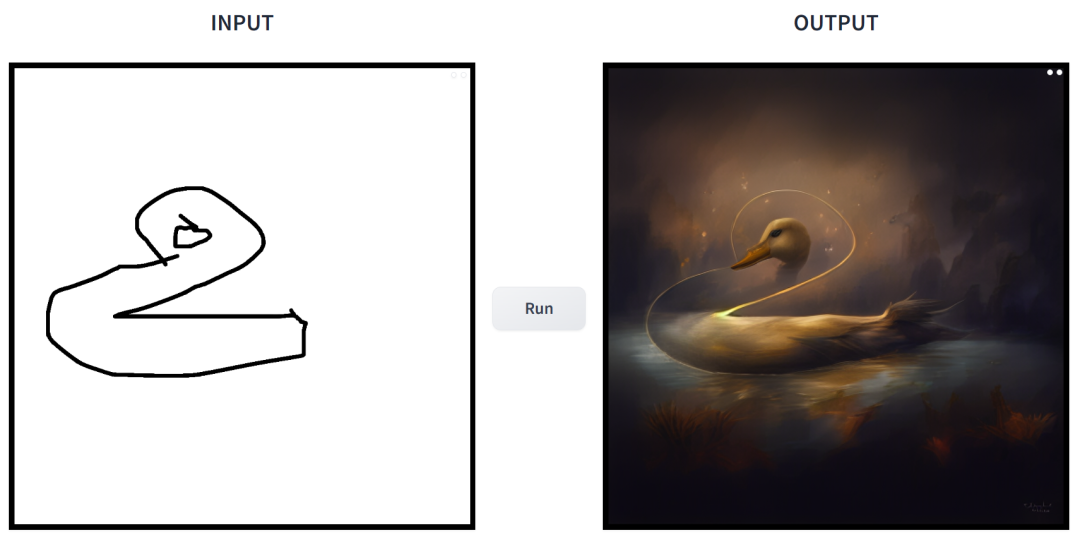
l'invite est "canard".
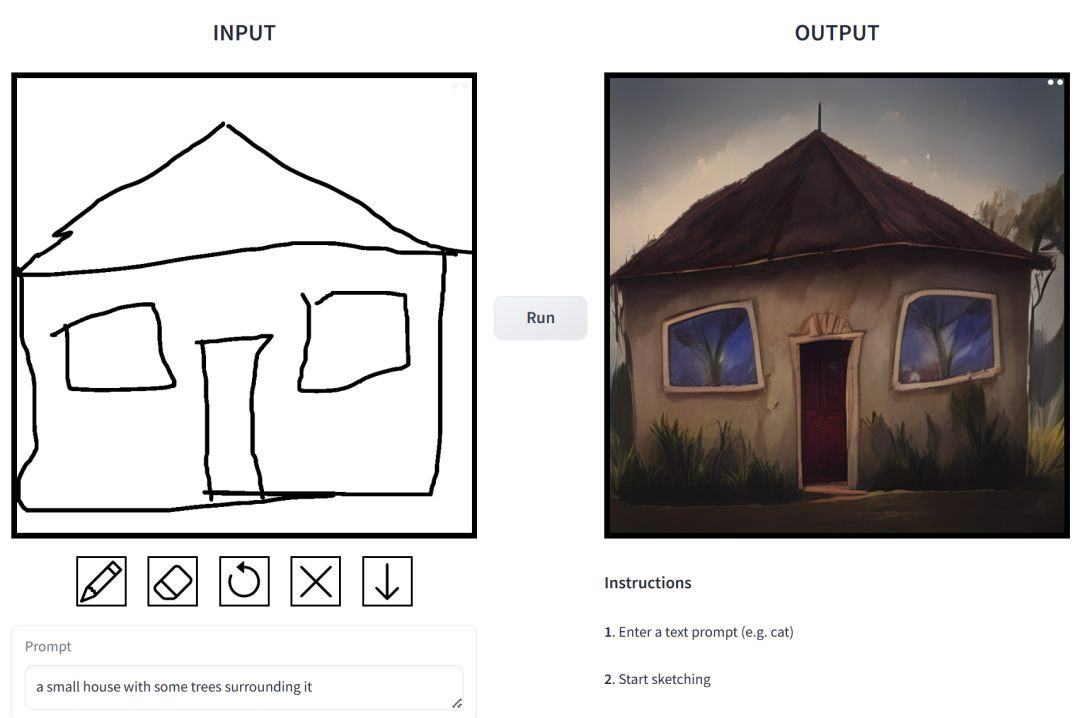
prompt est "une petite maison entourée de végétation".
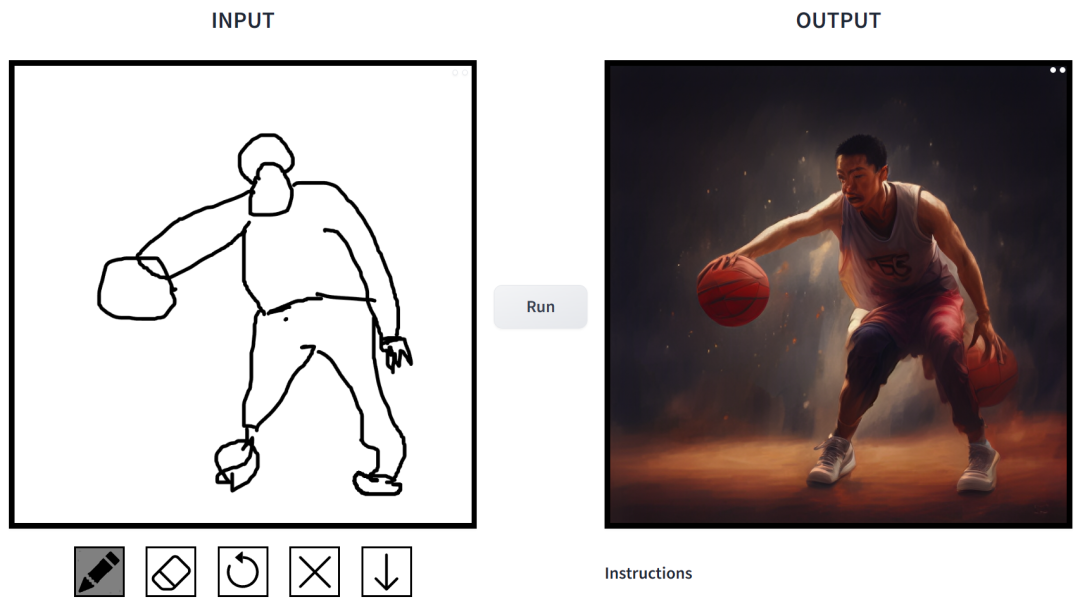
l'invite est "Des garçons chinois jouent au basket".
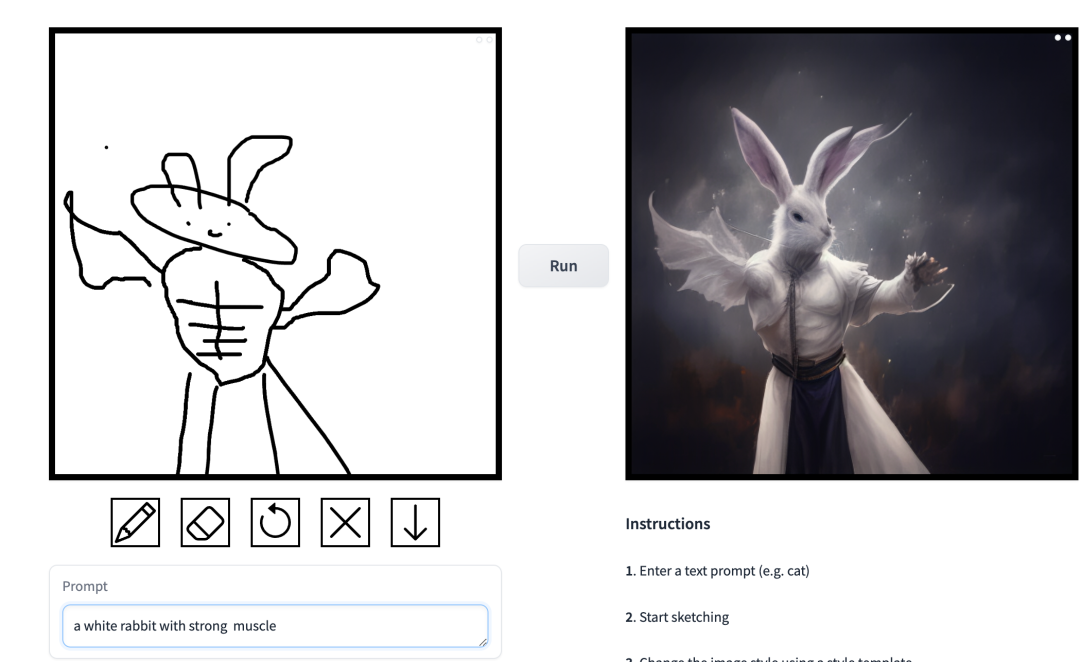
l'invite est "Muscle Man Rabbit". Dans ce travail, les chercheurs ont apporté des améliorations ciblées aux problèmes existants dans le modèle de diffusion conditionnelle dans les applications de synthèse d’images. De tels modèles permettent aux utilisateurs de générer des images basées sur des conditions spatiales et des invites textuelles, et d'avoir un contrôle précis sur la disposition de la scène, les croquis des utilisateurs et les poses humaines.
Mais le problème est que l'itération du modèle de diffusion entraîne un ralentissement de la vitesse d'inférence, limitant les applications en temps réel, telles que Sketch2Photo interactive. De plus, la formation de modèles nécessite généralement des ensembles de données appariés à grande échelle, ce qui entraîne des coûts énormes pour de nombreuses applications et n'est pas réalisable pour certaines autres applications. 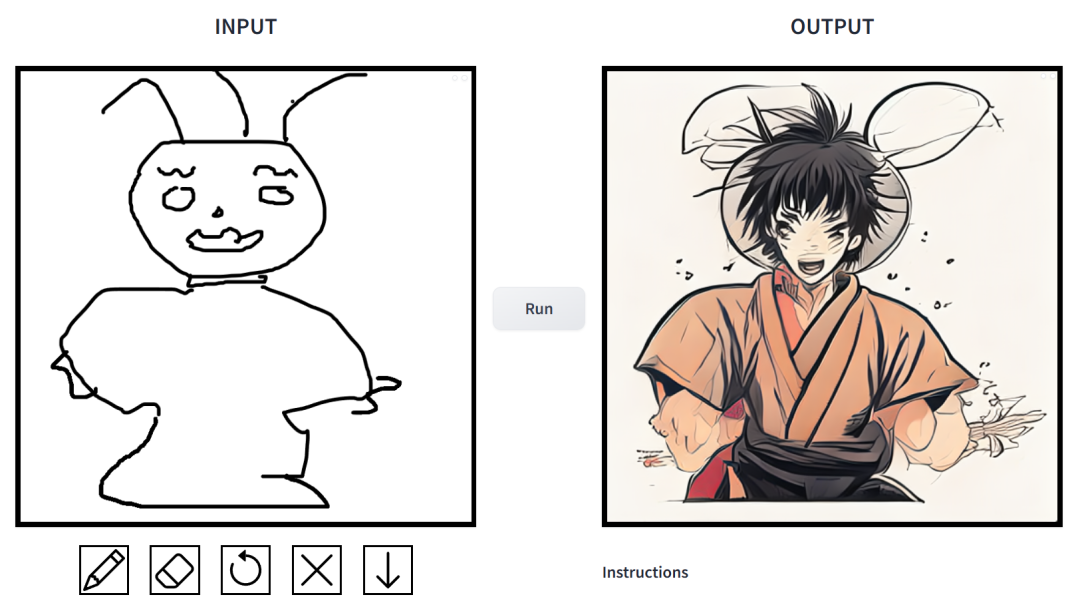
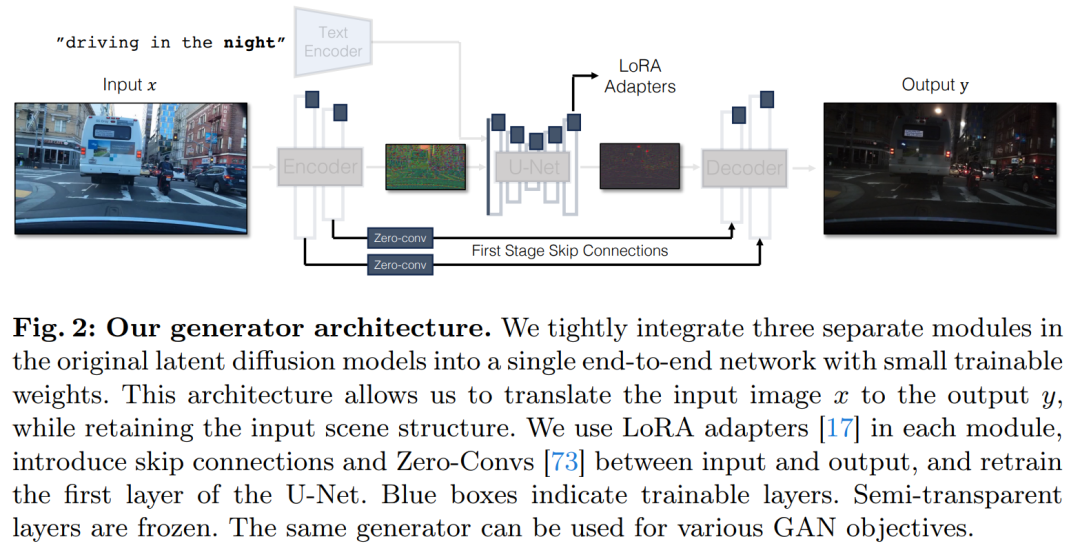
Afin de résoudre les problèmes du modèle de diffusion conditionnelle, les chercheurs ont introduit une méthode générale qui utilise des objectifs d'apprentissage contradictoires pour adapter le modèle de diffusion en une seule étape à de nouvelles tâches et de nouveaux domaines. Plus précisément, ils intègrent des modules individuels d'un modèle de diffusion latente vanille dans un réseau générateur de bout en bout unique avec de petits poids pouvant être entraînés, améliorant ainsi la capacité du modèle à préserver la structure de l'image d'entrée tout en réduisant le surajustement.
Les chercheurs ont lancé le modèle CycleGAN-Turbo, qui, dans un environnement non apparié, peut surpasser les méthodes GAN et basées sur la diffusion existantes dans diverses tâches de conversion de scène, telles que la conversion de jour et de nuit, l'ajout ou la suppression de brouillard et de neige. Pluie et autres conditions météorologiques. effets. 
Parallèlement, afin de vérifier la polyvalence de leur propre architecture, les chercheurs ont mené des expérimentations sur des réglages appariés. Les résultats montrent que leur modèle pix2pix-Turbo obtient des effets visuels comparables à Edge2Image et Sketch2Photo et réduit l'étape d'inférence à 1 étape.
En résumé, ce travail démontre que les modèles texte-image pré-entraînés en une étape peuvent servir de base puissante et polyvalente pour de nombreuses tâches de génération d'images en aval.
Cette étude propose une méthode générale pour adapter les modèles de diffusion en une étape (tels que SD-Turbo) à de nouvelles tâches et domaines grâce à l'apprentissage contradictoire. Cela exploite les connaissances internes du modèle de diffusion pré-entraîné tout en permettant une inférence efficace (par exemple, 0,29 seconde sur A6000 et 0,11 seconde sur A100 pour une image 512 x 512).
De plus, les modèles conditionnels en une seule étape CycleGAN-Turbo et pix2pix-Turbo peuvent effectuer une variété de tâches de traduction d'image à image, adaptées aux paramètres par paires et non par paires. CycleGAN-Turbo surpasse les méthodes existantes basées sur le GAN et la diffusion, tandis que pix2pix-Turbo est à égalité avec des travaux récents tels que ControlNet pour Sketch2Photo et Edge2Image, mais avec l'avantage de l'inférence en une seule étape.
Ajouter une entrée conditionnelle
Afin de convertir un modèle texte-image en modèle image-image, la première chose à faire est de trouver un moyen efficace d'incorporer l'image d'entrée x dans le modèle.
Une stratégie courante pour incorporer des entrées conditionnelles dans les modèles de diffusion consiste à introduire des branches d'adaptateur supplémentaires, comme le montre la figure 3.
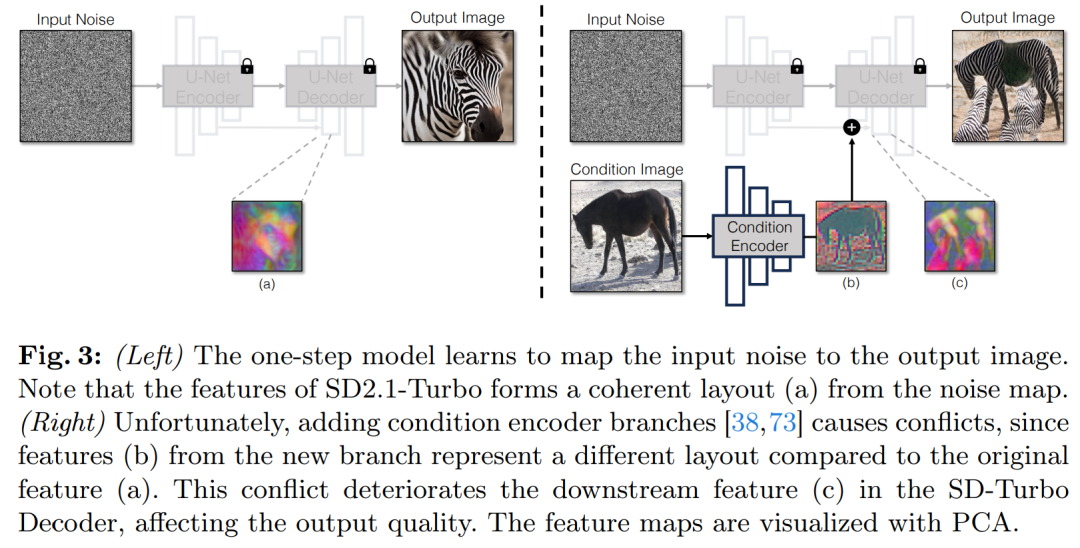
Plus précisément, cette étude initialise le deuxième encodeur et le qualifie de Condition Encoder. L'encodeur de contrôle accepte l'image d'entrée x et génère des cartes de caractéristiques de plusieurs résolutions vers le modèle de diffusion stable pré-entraîné via des connexions résiduelles. Cette méthode permet d'obtenir des résultats remarquables dans le contrôle des modèles de diffusion.
Comme le montre la figure 3, cette étude utilise deux encodeurs (encodeur U-Net et encodeur conditionnel) dans un modèle en une seule étape pour gérer les défis rencontrés par les images bruitées et les images d'entrée. Contrairement aux modèles de diffusion en plusieurs étapes, la carte de bruit dans les modèles en une seule étape contrôle directement la disposition et la pose de l'image générée, ce qui contredit souvent la structure de l'image d'entrée. Par conséquent, le décodeur reçoit deux ensembles de caractéristiques résiduelles représentant différentes structures, ce qui rend le processus de formation plus difficile.
Saisie conditionnelle directe. La figure 3 montre également que la structure de l'image générée par le modèle pré-entraîné est significativement affectée par la carte de bruit z. Sur la base de ces informations, l’étude recommande d’alimenter les entrées conditionnelles directement au réseau. Pour adapter le modèle de base aux nouvelles conditions, l'étude a ajouté plusieurs poids LoRA à différentes couches d'U-Net (voir Figure 2).
Préserver les détails d'entrée
L'encodeur d'image pour les modèles de diffusion latente (MLD) accélère la formation des modèles de diffusion en compressant la résolution spatiale de l'image d'entrée d'un facteur 8 tout en augmentant le nombre de canaux de 3 à 4. processus de raisonnement. Bien que cette conception puisse accélérer la formation et l'inférence, elle n'est peut-être pas idéale pour les tâches de transformation d'image qui nécessitent de préserver les détails de l'image d'entrée. La figure 4 illustre ce problème, où nous prenons une image d'entrée de la conduite de jour (à gauche) et la convertissons en une image correspondante de la conduite de nuit, en utilisant une architecture qui n'utilise pas de connexions sautées (au milieu). On peut observer que les détails fins tels que le texte, les panneaux de signalisation et les voitures éloignées ne sont pas préservés. En revanche, l’image transformée résultante utilisant une architecture qui inclut des connexions sautées (à droite) parvient mieux à préserver ces détails complexes.

Pour capturer les détails visuels fins de l'image d'entrée, l'étude a ajouté des connexions sautées entre les réseaux d'encodeur et de décodeur (voir Figure 2). Plus précisément, l'étude extrait quatre activations intermédiaires après chaque bloc de sous-échantillonnage dans le codeur et les traite via une couche convolutionnelle nulle 1 × 1 avant de les introduire dans le bloc de suréchantillonnage correspondant dans le décodeur. Cette approche garantit que les détails complexes sont préservés lors de la conversion de l'image.
Cette étude a comparé CycleGAN-Turbo avec les précédentes méthodes de transformation d'image non par paire basées sur le GAN. À partir d'une analyse qualitative, les figures 5 et 6 montrent que ni la méthode basée sur le GAN ni la méthode basée sur la diffusion ne peuvent atteindre un équilibre entre le réalisme de l'image de sortie et le maintien de la structure.


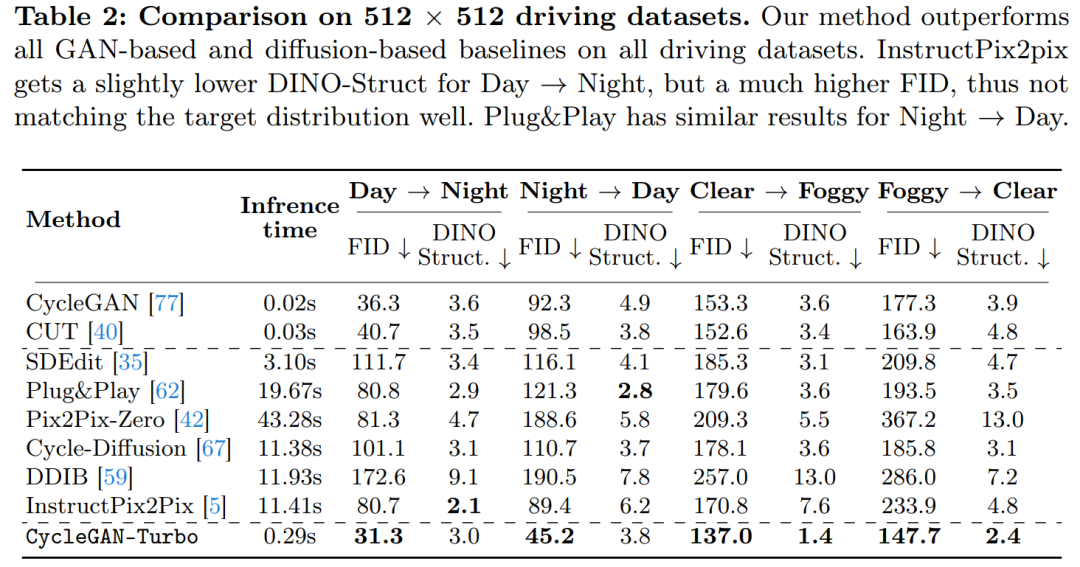
L'étude a également comparé CycleGAN-Turbo avec CycleGAN et CUT. Les tableaux 1 et 2 présentent les résultats de comparaisons quantitatives sur huit tâches de commutation non appariées.
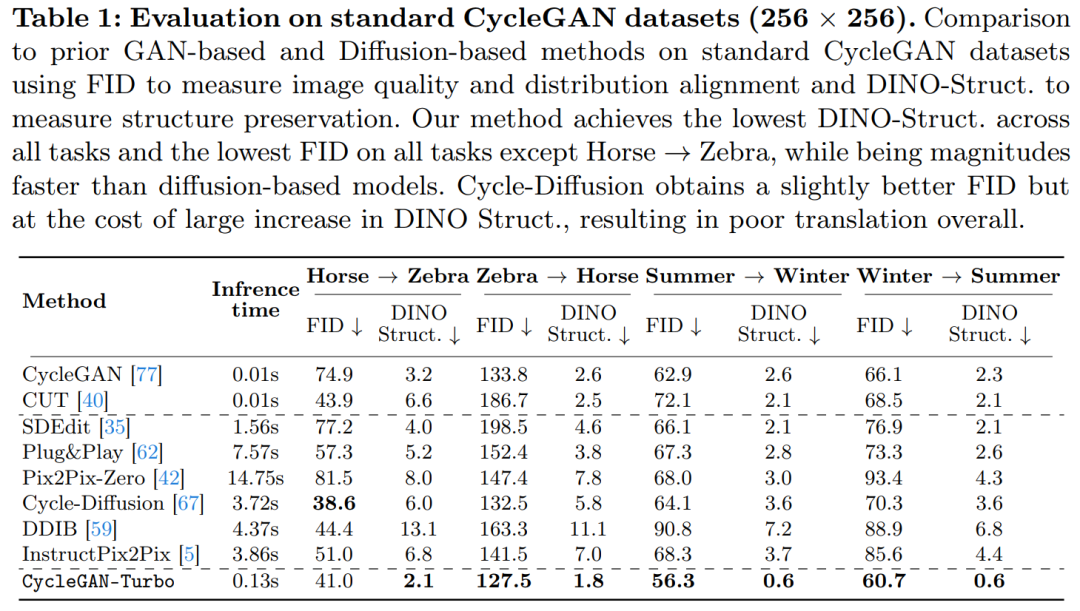
CycleGAN et CUT démontrent des performances efficaces sur des ensembles de données plus simples et centrés sur les objets, tels que cheval → zèbre (Figure 13), obtenant un faible score FID et DINO -Structure. Notre méthode surpasse légèrement ces méthodes dans les métriques de distance FID et DINO-Structure.

Comme le montrent le tableau 1 et la figure 14, sur des ensembles de données centrés sur les objets (tels que cheval → zèbre), ces méthodes peuvent générer des zèbres réalistes, mais souffrent de difficultés de correspondance exacte des objets.
Sur l'ensemble de données de conduite, ces méthodes d'édition fonctionnent bien moins bien pour trois raisons : (1) le modèle a du mal à générer des scènes complexes contenant plusieurs objets, (2) ces méthodes (sauf Instruct-pix2pix) doivent d'abord L'image est inversé en une carte de bruit, introduisant une erreur humaine potentielle, et (3) le modèle pré-entraîné ne peut pas synthétiser des images de vue de rue similaires à celles capturées par l'ensemble de données de conduite. Le tableau 2 et la figure 16 montrent que sur les quatre tâches de transition de conduite, ces méthodes génèrent des images de mauvaise qualité et ne suivent pas la structure de l'image d'entrée.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Classe principale introuvable ou impossible à charger
Classe principale introuvable ou impossible à charger
 Comment configurer la passerelle par défaut
Comment configurer la passerelle par défaut
 Que signifie ajouter en Java ?
Que signifie ajouter en Java ?
 Quels sont les composants d'un système Linux ?
Quels sont les composants d'un système Linux ?
 Qu'est-ce que la rigidité de l'utilisateur
Qu'est-ce que la rigidité de l'utilisateur
 js actualiser la page actuelle
js actualiser la page actuelle
 JavaScript : vide 0
JavaScript : vide 0
 Construire un serveur Internet
Construire un serveur Internet








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



