



Titre : DECO : Détection d'objets de bout en bout basée sur des requêtes avec ConvNets
Article : https://arxiv.org/pdf/2312.13735.pdf
Code source : https://github.com / xinghaochen/DECO
Texte original : https://zhuanlan.zhihu.com/p/686011746@王云河
Après l'introduction du transformateur de détection (DETR), il y a eu un essor dans le domaine de la détection de cibles , et de nombreuses études ultérieures se sont concentrées sur la précision. Des améliorations ont été apportées par rapport au DETR original en termes de vitesse et de vitesse. Cependant, la discussion se poursuit quant à savoir si les Transformers peuvent complètement dominer le champ visuel. Certaines études comme ConvNeXt et RepLKNet montrent que les structures CNN ont encore un grand potentiel dans le domaine de la vision.
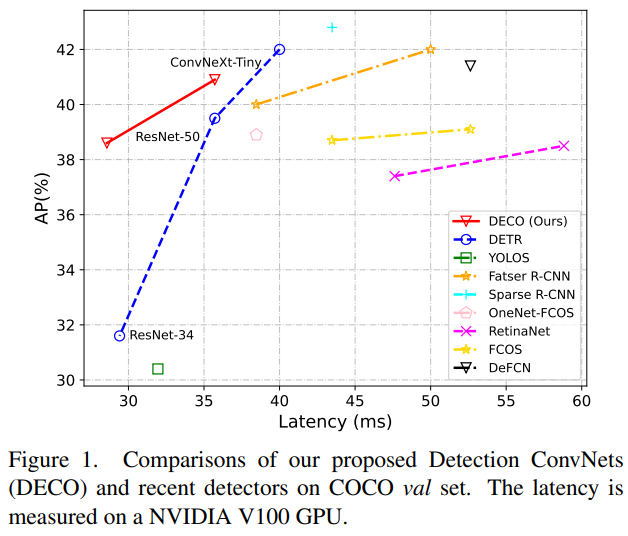
Ce que nous explorons dans ce travail est de savoir comment utiliser l'architecture convolution pure pour obtenir un détecteur de cadre de type DETR avec de hautes performances. En hommage à DETR, nous appelons notre approche DECO (Detection ConvNets). En utilisant un paramètre structurel similaire à DETR et en utilisant différents Backbones, DECO a atteint 38,6 % et 40,8 % d'AP sur COCO et 35 FPS et 28 FPS sur V100, obtenant ainsi de meilleures performances que DETR. Associé à des modules tels que des fonctionnalités multi-échelles similaires à RT-DETR, DECO a atteint une vitesse de 47,8 % AP et 34 FPS. Les performances globales présentent de bons avantages par rapport à de nombreuses méthodes d'amélioration DETR.
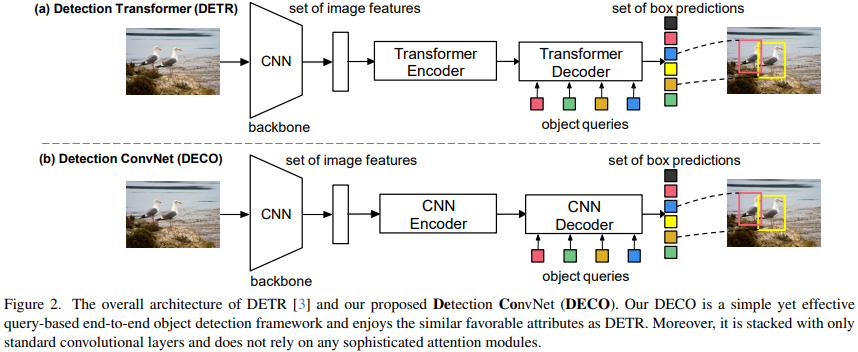
La caractéristique principale de DETR est d'utiliser la structure du transformateur encodeur-décodeur pour interagir avec une image d'entrée à l'aide d'un ensemble de requêtes pour interagir avec les caractéristiques de l'image, et peut directement générer une image spécifiée. nombre de trames de détection. Cela élimine la dépendance aux opérations de post-traitement telles que NMS. L'architecture globale de DECO que nous avons proposée est similaire à DETR. Elle comprend également Backbone pour l'extraction de caractéristiques d'image, une structure Encoder-Decoder pour interagir avec Query et génère enfin un nombre spécifique de résultats de détection. La seule différence est que l'encodeur et le décodeur de DECO sont des structures purement convolutives. DECO est donc un détecteur de bout en bout basé sur des requêtes et composé de convolution pure. Le remplacement de la structure de l'encodeur de
DETR est relativement simple. Nous choisissons d'utiliser 4 blocs ConvNeXt pour former la structure de l'encodeur. Plus précisément, chaque couche de l'encodeur est implémentée en empilant une convolution de profondeur 7x7, une couche LayerNorm, une convolution 1x1, une fonction d'activation GELU et une autre convolution 1x1. De plus, dans DETR, comme l'architecture du Transformer a une invariance de permutation à l'entrée, un codage de position doit être ajouté à l'entrée de chaque couche d'encodeur, mais pour l'encodeur composé de convolutions, il n'est pas nécessaire d'ajouter un encodage de position
En comparaison, le remplacement du Décodeur est bien plus compliqué. La fonction principale du décodeur est d'interagir pleinement avec les caractéristiques de l'image et Query, afin que Query puisse pleinement percevoir les informations sur les caractéristiques de l'image et ainsi prédire les coordonnées et les catégories de cibles dans l'image. Le Décodeur comprend principalement deux entrées : la sortie de fonctionnalités de l'Encodeur et un ensemble de vecteurs de requête apprenables (Query). Nous divisons la structure principale de Decoder en deux modules : le module d'auto-interaction (SIM) et le module d'interaction croisée (CIM).
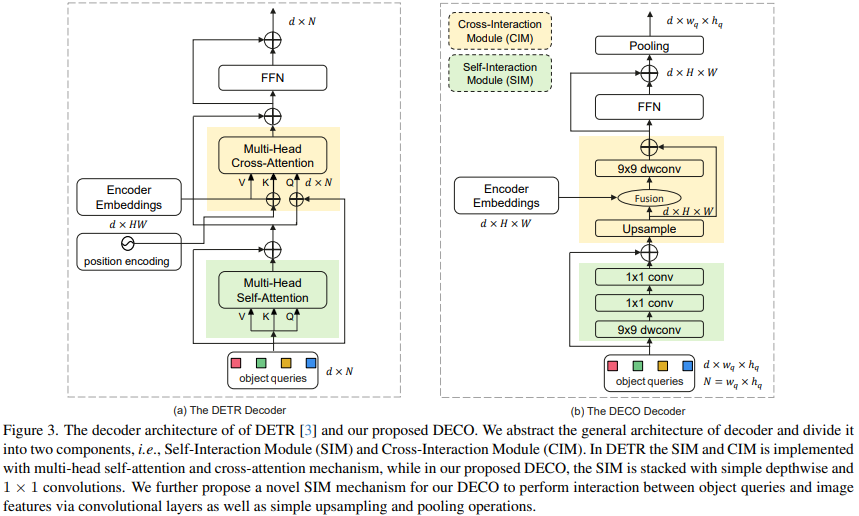
Ici, le module SIM intègre principalement la sortie des couches de requête et de décodeur supérieure. Cette partie de la structure peut être composée de plusieurs couches convolutives, utilisant une convolution en profondeur 9x9 et une convolution 1x1 dans la dimension spatiale et la dimension du canal respectivement. . Effectuez un échange d'informations pour obtenir entièrement les informations sur la cible requises et envoyez-les au module CIM suivant pour une extraction plus approfondie des fonctionnalités de détection de cible. La requête est un ensemble de vecteurs initialisés de manière aléatoire. Ce nombre détermine le nombre de trames de détection finalement émises par le détecteur. Sa valeur spécifique peut être ajustée en fonction des besoins réels. Pour DECO, comme toutes les structures sont composées de convolutions, nous transformons la requête en deux dimensions. Par exemple, 100 requêtes peuvent devenir 10x10 dimensions.
La fonction principale du module CIM est d'interagir pleinement entre les caractéristiques de l'image et Query, afin que Query puisse pleinement percevoir les informations sur les caractéristiques de l'image et ainsi prédire les coordonnées et les catégories de cibles dans l'image. Pour la structure Transformer, il est facile d'atteindre cet objectif en utilisant le mécanisme d'attention croisée, mais pour la structure de convolution, la plus grande difficulté est de savoir comment interagir pleinement avec les deux fonctionnalités.
Pour fusionner les caractéristiques globales de la sortie SIM et de la sortie de l'encodeur avec des tailles différentes, nous devons d'abord aligner spatialement les deux, puis les fusionner. Tout d'abord, nous effectuons un suréchantillonnage du voisin le plus proche sur la sortie SIM :

de sorte qu'après le suréchantillonnage. Les fonctionnalités ont la même taille que les fonctionnalités globales générées par l'encodeur, puis les fonctionnalités suréchantillonnées sont fusionnées avec les fonctionnalités globales générées par l'encodeur, puis entrent dans une convolution profonde pour l'interaction des fonctionnalités, puis ajoutent l'entrée résiduelle :
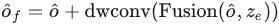
Enfin, les fonctionnalités interagies sont échangées contre des informations de canal via FNN, puis regroupées vers le numéro cible pour obtenir l'intégration de sortie du décodeur :
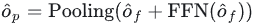
Enfin, nous enverrons l'intégration de sortie obtenue à la tête de détection pour une classification ultérieure. et la régression.
Comme le DETR original, le DECO obtenu par le framework ci-dessus présente un défaut commun, à savoir le manque de fonctionnalités multi-échelles, ce qui a un grand impact sur la détection de cibles de haute précision. Deformable DETR intègre des fonctionnalités de différentes échelles en utilisant un module d'attention déformable multi-échelles, mais cette méthode est fortement couplée à l'opérateur Attention, elle ne peut donc pas être utilisée directement sur notre DECO. Afin de permettre à DECO de gérer des fonctionnalités multi-échelles, nous utilisons un module de fusion de fonctionnalités multi-échelles proposé par RT-DETR après les fonctionnalités sorties par le Decoder. En fait, une série de méthodes d'amélioration ont été élaborées après la naissance de DETR. Nous pensons que de nombreuses stratégies sont également applicables à DECO et nous espérons que les personnes intéressées pourront en discuter ensemble.
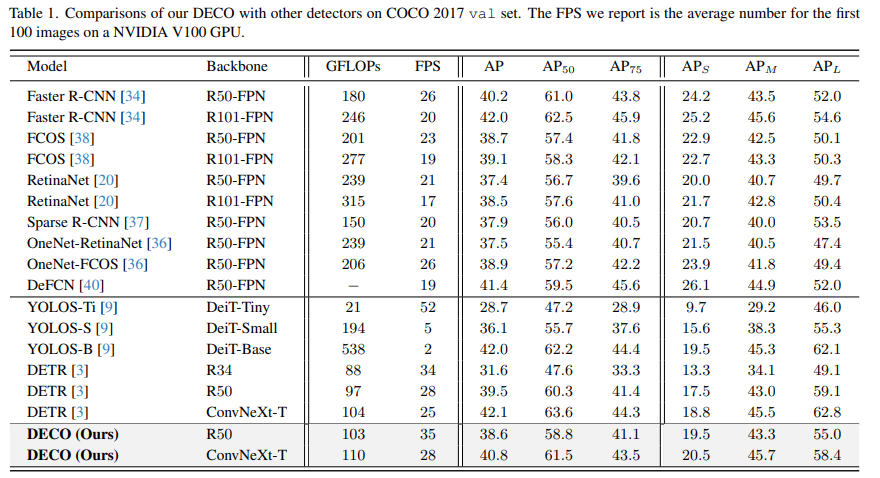
Nous avons mené des expériences sur COCO et comparé DECO et DETR tout en gardant l'architecture principale inchangée, comme en gardant le nombre de requêtes cohérent, en gardant le nombre de couches de décodeur inchangé, etc., et en changeant uniquement le transformateur dans DETR. La structure est remplacée par notre structure convolutive telle que décrite ci-dessus. On peut voir que DECO a obtenu une meilleure précision et un compromis plus rapide que DETR.
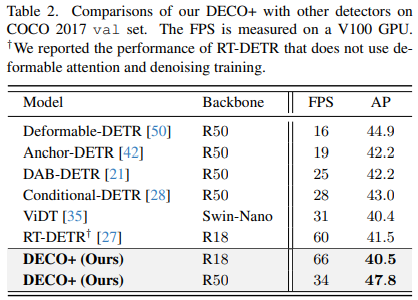
Nous avons également comparé DECO, qui est équipé de fonctionnalités multi-échelles, avec davantage de méthodes de détection de cibles, y compris de nombreuses variantes de DETR. Comme vous pouvez le voir sur la figure ci-dessous, DECO a obtenu de très bons résultats, obtenant de meilleurs résultats. performances que de nombreux détecteurs précédents.
La structure DECO dans l'article a fait l'objet de nombreuses expériences et visualisations d'ablation, y compris les stratégies de fusion spécifiques (addition, multiplication de points, Concat) sélectionnées dans le décodeur et comment définir les dimensions de la requête pour obtenir des résultats optimaux. etc., il existe également des résultats intéressants. Pour des résultats et une discussion plus détaillés, veuillez vous référer à l'article original.
Cet article vise à étudier s'il est possible de créer un cadre de détection d'objets de bout en bout basé sur des requêtes sans utiliser une architecture Transformer complexe. Un nouveau cadre de détection appelé Detection ConvNet (DECO) est proposé, comprenant un réseau fédérateur et une structure codeur-décodeur convolutif. En concevant soigneusement l'encodeur DECO et en introduisant un nouveau mécanisme, le décodeur DECO est capable de réaliser l'interaction entre la requête cible et les caractéristiques de l'image via des couches convolutives. Des comparaisons ont été effectuées avec les détecteurs précédents du benchmark COCO et, malgré sa simplicité, DECO a atteint des performances compétitives en termes de précision de détection et de vitesse d'exécution. Plus précisément, en utilisant les backbones ResNet-50 et ConvNeXt-Tiny, DECO a atteint 38,6 % et 40,8 % d'AP sur la validation COCO définie à 35 et 28 FPS respectivement, surpassant le modèle DET. On espère que DECO offrira une nouvelle perspective sur la conception de cadres de détection d'objets.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées
 Introduction au framework utilisé par vscode
Introduction au framework utilisé par vscode
 propriétés du dégradé CSS3
propriétés du dégradé CSS3
 Comment ouvrir des fichiers torrent
Comment ouvrir des fichiers torrent
 Caractéristiques des systèmes d'information de gestion
Caractéristiques des systèmes d'information de gestion
 La différence et le lien entre le langage C et C++
La différence et le lien entre le langage C et C++
 Introduction aux types de méthodes de soudage
Introduction aux types de méthodes de soudage
 Comment utiliser le post-message
Comment utiliser le post-message







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



