


Il n'y a pas si longtemps, OpenAI Sora est rapidement devenu populaire grâce à ses incroyables effets de génération vidéo. Il s'est démarqué parmi la foule des modèles vidéo Wensheng et est devenu le centre de l'attention mondiale. Suite au lancement du processus de reproduction d'inférence de formation Sora avec une réduction des coûts de 46 % il y a 2 semaines, l'équipe Colossal-AI a entièrement open source le premier modèle de génération vidéo d'architecture de type Sora au monde "Open-Sora 1.0", couvrant l'ensemble du processus de formation. , y compris le traitement des données, tous les détails de formation et les poids des modèles, et joignez-vous à des passionnés mondiaux d'IA pour promouvoir une nouvelle ère de création vidéo.
Pour un aperçu, regardons d'abord une vidéo d'une ville animée générée par le modèle « Open-Sora 1.0 » publié par l'équipe Colossal-AI.

Un instantané de la ville animée généré par Open-Sora 1.0
Ce n'est que la pointe de l'iceberg de la technologie de reproduction de Sora concernant l'architecture du modèle de la vidéo Wensheng ci-dessus, les poids du modèle entraîné et. tous les détails de formation de la reproduction, L'équipe Colossal-AI a rendu le processus de prétraitement des données, l'affichage de la démonstration et les didacticiels de démarrage détaillés gratuits et open source sur GitHub. Dans le même temps, l'auteur a immédiatement contacté l'équipe et a appris qu'ils le feraient. continuez à mettre à jour les solutions liées à Open-Sora et les derniers développements, les amis intéressés peuvent continuer à prêter attention à la communauté open source d'Open-Sora .
Adresse open source Open-Sora : https://github.com/hpcaitech/Open-Sora
Ensuite, nous approfondirons plusieurs aspects de Sora solution de réplication Les aspects clés incluent la conception de l'architecture du modèle, les méthodes de formation, le prétraitement des données, l'affichage des effets du modèle et les stratégies de formation d'optimisation.
Le modèle adopte l'architecture actuellement populaire du transformateur de diffusion (DiT) [1]. L'équipe d'auteurs utilise le modèle graphique Vincent open source de haute qualité PixArt-α [2] qui utilise également l'architecture DiT comme base, introduit une couche d'attention temporelle sur cette base et l'étend aux données vidéo. Plus précisément, l'ensemble de l'architecture comprend un VAE pré-entraîné, un encodeur de texte et un modèle STDiT (Spatial Temporal Diffusion Transformer) qui utilise le mécanisme d'attention spatio-temporelle. Parmi eux, la structure de chaque couche de STDiT est présentée dans la figure ci-dessous. Il utilise une méthode sérielle pour superposer un module d'attention temporelle unidimensionnelle sur un module d'attention spatiale bidimensionnelle afin de modéliser les relations temporelles. Après le module d'attention temporelle, le module d'attention croisée permet d'aligner la sémantique du texte. Par rapport au mécanisme d’attention totale, une telle structure réduit considérablement les frais de formation et d’inférence. Par rapport au modèle Latte [3], qui utilise également un mécanisme d'attention spatio-temporel, STDiT peut mieux utiliser les poids des images DiT pré-entraînées pour continuer l'entraînement sur les données vidéo.
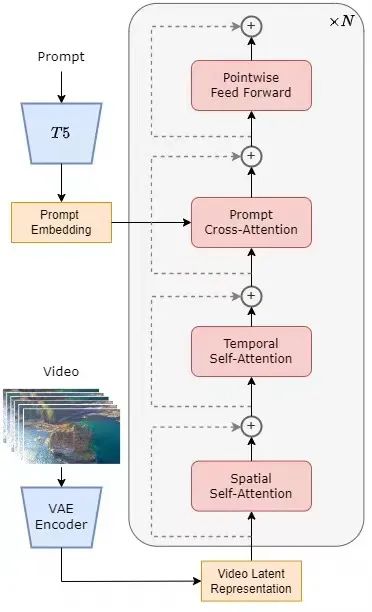
Schéma structurel STDiT
Le processus de formation et d'inférence de l'ensemble du modèle est le suivant. Il est entendu que dans la phase de formation, l'encodeur Variational Autoencoder (VAE) pré-entraîné est d'abord utilisé pour compresser les données vidéo, puis le modèle de diffusion STDiT est formé avec l'intégration de texte dans l'espace latent compressé. Lors de l'étape d'inférence, un bruit gaussien est échantillonné de manière aléatoire dans l'espace latent de VAE et entré dans STDiT avec une intégration rapide pour obtenir les caractéristiques débruitées. Enfin, il est entré dans le décodeur de VAE et décodé pour obtenir la vidéo.

Processus de formation du modèle
Nous avons appris de l'équipe que le plan de reproduction d'Open-Sora fait référence au travail de diffusion vidéo stable (SVD)[3]. Il se compose de trois. étapes, à savoir :
Chaque étape continuera l'entraînement en fonction des poids de l'étape précédente. Par rapport à la formation en une seule étape à partir de zéro, la formation en plusieurs étapes atteint plus efficacement l'objectif de génération vidéo de haute qualité en développant progressivement les données.

Trois étapes du plan d'entraînement
La première étape utilise une pré-formation d'images à grande échelle et utilise le modèle de graphique vincentien mature pour réduire efficacement le coût de la pré-formation vidéo.
L'équipe d'auteurs nous a révélé que grâce aux riches données d'images à grande échelle sur Internet et à la technologie avancée des graphiques Vincent, nous pouvons former un modèle de graphique Vincent de haute qualité, qui servira de poids d'initialisation pour la prochaine étape. de pré-formation vidéo. Dans le même temps, comme il n’existe actuellement pas de VAE spatio-temporelle de haute qualité, ils ont utilisé la VAE d’image pré-entraînée par le modèle Stable Diffusion [5]. Cette stratégie garantit non seulement les performances supérieures du modèle initial, mais réduit également considérablement le coût global de la pré-formation vidéo.
La deuxième étape effectue un pré-entraînement vidéo à grande échelle pour augmenter la capacité de généralisation du modèle et saisir efficacement la corrélation des séries chronologiques des vidéos.
Nous comprenons que cette étape nécessite une grande quantité de formation sur les données vidéo pour assurer la diversité des thèmes vidéo, augmentant ainsi la capacité de généralisation du modèle. Le modèle de deuxième étape ajoute un module d'attention temporelle au modèle graphique vincentien de première étape pour apprendre les relations temporelles dans les vidéos. Les modules restants restent cohérents avec la première étape et chargent les poids de la première étape comme initialisation, tout en initialisant la sortie du module d'attention temporelle à zéro pour obtenir une convergence plus efficace et plus rapide. L'équipe Colossal-AI a utilisé les poids open source de PixArt-alpha [2] comme initialisation pour le modèle STDiT de deuxième étape, et le modèle T5 [6] comme encodeur de texte. Dans le même temps, ils ont utilisé une petite résolution de 256 x 256 pour la pré-formation, ce qui a encore augmenté la vitesse de convergence et réduit les coûts de formation.
La troisième étape affine les données vidéo de haute qualité pour améliorer considérablement la qualité de la génération vidéo.
L'équipe d'auteurs a mentionné que la taille des données vidéo utilisées dans la troisième étape est d'un ordre de grandeur inférieure à celle de la deuxième étape, mais que la longueur, la résolution et la qualité de la vidéo sont supérieures. En ajustant ainsi, ils ont obtenu une mise à l'échelle efficace de la génération vidéo de courte à longue, de basse à haute résolution et de basse à haute fidélité.
L'équipe d'auteurs a déclaré que dans le processus de reproduction Open-Sora, ils ont utilisé 64 blocs H800 pour l'entraînement. Le volume total de formation de la deuxième étape est de 2 808 heures GPU, soit environ 7 000 $, et le volume de formation de la troisième étape est de 1 920 heures GPU, soit environ 4 500 $. Après des estimations préliminaires, l'ensemble du programme de formation a réussi à contrôler le processus de reproduction d'Open-Sora à environ 10 000 $ US.
Afin de réduire davantage le seuil et la complexité de la reproduction de Sora, l'équipe Colossal-AI fournit également un script de prétraitement des données vidéo pratique dans l'entrepôt de code, afin que tout le monde puisse facilement démarrer la reproduction de Sora. -la formation comprend le téléchargement d'ensembles de données vidéo publiques, la segmentation de longues vidéos en courts clips vidéo en fonction de la continuité des plans et l'utilisation du grand modèle de langage open source LLaVA [7] pour générer des mots d'invite précis. L'équipe d'auteurs a mentionné que le code de génération de titres vidéo par lots qu'ils ont fourni peut annoter une vidéo avec deux cartes et 3 secondes, et que la qualité est proche de GPT-4V. Les couples vidéo/texte résultants peuvent être utilisés directement pour la formation. Avec le code open source qu'ils fournissent sur GitHub, nous pouvons générer facilement et rapidement les paires vidéo/texte nécessaires à la formation sur notre propre ensemble de données, réduisant ainsi considérablement le seuil technique et la préparation préliminaire au démarrage d'un projet de réplication Sora.

Paire vidéo/texte générée automatiquement en fonction du script de prétraitement des données
Jetons un coup d'œil à l'effet de génération vidéo réel d'Open-Sora. Par exemple, laissez Open-Sora générer une séquence aérienne d’eau de mer clapotant contre les rochers d’une falaise.

Laissez Open-Sora capturer la vue aérienne majestueuse des montagnes et des cascades jaillissant des falaises et se jetant finalement dans le lac.

En plus d'aller vers le ciel, vous pouvez également entrer dans la mer. Entrez simplement l'invite et laissez Open-Sora générer une photo du monde sous-marin. Dans la photo, une tortue de mer nage tranquillement parmi. les récifs coralliens.

Open-Sora peut également nous montrer la Voie lactée avec des étoiles scintillantes grâce à la photographie accélérée.

Si vous avez des idées plus intéressantes pour la génération de vidéos, vous pouvez visiter la communauté open source Open-Sora pour obtenir les poids des modèles pour une expérience gratuite. Lien : https://github.com/hpcaitech/Open-Sora
Il est à noter que l'équipe d'auteurs a mentionné sur Github que la version actuelle n'utilise que 400 000 données d'entraînement, la qualité de génération du modèle et la possibilité de suivre du texte. Tout doit être amélioré. Par exemple, dans la vidéo de tortue ci-dessus, la tortue résultante a une patte supplémentaire. Open-Sora 1.0 n'est pas non plus efficace pour générer des portraits et des images complexes. L'équipe d'auteurs a répertorié une série de plans à réaliser sur Github, visant à résoudre en permanence les défauts existants et à améliorer la qualité de la production.
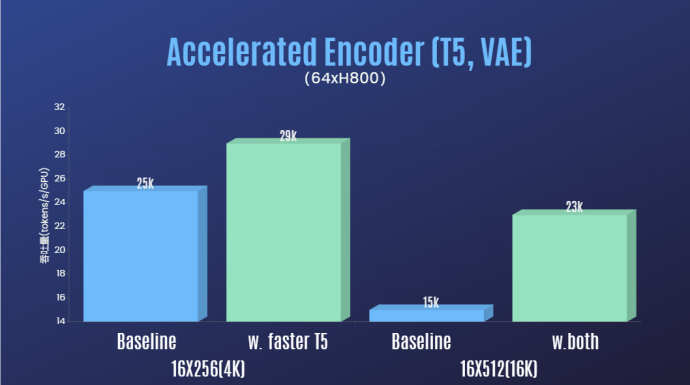
En plus de réduire considérablement le seuil technique de reproduction Sora et d'améliorer la qualité de la génération vidéo dans de multiples dimensions telles que la durée, la résolution et le contenu, l'équipe d'auteur fournit également l'accélération Colossal-AI système pour la reproduction de Sora. Support de formation efficace maintenant. Grâce à des stratégies de formation efficaces telles que l'optimisation des opérateurs et le parallélisme hybride, un effet d'accélération de 1,55 fois a été obtenu lors de la formation au traitement de vidéos de 64 images, d'une résolution de 512 x 512. Dans le même temps, grâce au système de gestion de mémoire hétérogène de Colossal-AI, une tâche de formation vidéo haute définition 1080p d'une minute peut être effectuée sans entrave sur un seul serveur (8*H800).
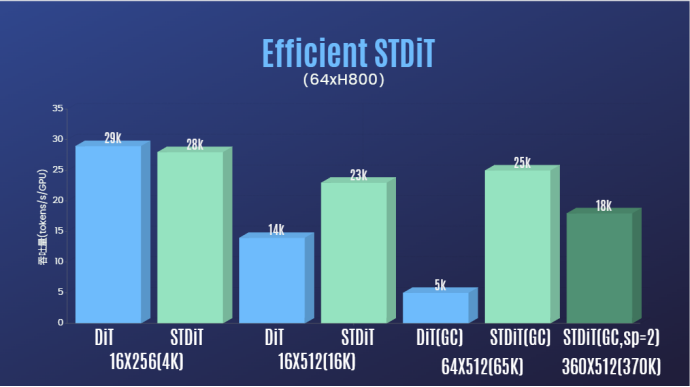
De plus, dans le rapport de l'équipe d'auteurs, nous avons également constaté que l'architecture du modèle STDiT a également montré une excellente efficacité lors de la formation. Comparé à DiT, qui utilise un mécanisme d'attention totale, STDiT atteint une accélération jusqu'à 5 fois supérieure à mesure que le nombre d'images augmente, ce qui est particulièrement critique dans les tâches du monde réel telles que le traitement de longues séquences vidéo.
Bienvenue pour continuer à prêter attention au projet open source Open-Sora : https://github.com/hpcaitech/Open-Sora
L'équipe d'auteur a déclaré qu'elle continuerait à maintenir et à optimiser le projet Open-Sora et devraient utiliser davantage de données de formation vidéo pour générer un contenu vidéo plus long et de meilleure qualité, et prendre en charge des fonctionnalités multi-résolution pour promouvoir efficacement la mise en œuvre de la technologie de l'IA dans les films, les jeux, la publicité et d'autres domaines.
Lien de référence :
[1] https://arxiv.org/abs/2212.09748 Modèles de diffusion évolutifs avec transformateurs.
[2] https://arxiv.org/abs/2310.00426 PixArt-α : Formation rapide du transformateur de diffusion pour la synthèse photoréaliste de texte en image.
[3] https://arxiv.org/abs/2311.15127 Diffusion vidéo stable : mise à l'échelle des modèles de diffusion vidéo latente vers de grands ensembles de données.
[4] https://arxiv.org/abs/2401.03048 Latte : Transformateur de diffusion latente pour la génération vidéo.
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original.
[6] https://github.com/google-research/text-to-text-transfer-transformer.
[7] https://github.com/haotian-liu/LLaVA.
[8] https://hpc-ai.com/blog/open-sora-v1.0.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comparez les similitudes et les différences entre deux colonnes de données dans Excel
Comparez les similitudes et les différences entre deux colonnes de données dans Excel
 Le câble réseau est débranché
Le câble réseau est débranché
 Comment résoudre les problèmes lors de l'analyse des packages
Comment résoudre les problèmes lors de l'analyse des packages
 Qu'est-ce que la carte de contrôle d'accès NFC
Qu'est-ce que la carte de contrôle d'accès NFC
 Quels sont les logiciels de sauvegarde de données ?
Quels sont les logiciels de sauvegarde de données ?
 Le rôle de l'enregistrement d'un serveur cloud
Le rôle de l'enregistrement d'un serveur cloud








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



