



Éditeur | ScienceAI
Les modèles d'apprentissage profond ont eu un impact profond dans le domaine de la recherche scientifique en raison de leur capacité à apprendre des relations latentes à partir d'énormes quantités de données. Cependant, les modèles qui reposent uniquement sur des données révèlent progressivement leurs limites, notamment une dépendance excessive aux données, des limites dans les capacités de généralisation et des problèmes de cohérence avec le monde physique réel. Ces problèmes poussent les chercheurs à explorer des modèles plus interprétables et explicables pour combler les lacunes des modèles basés sur les données. Par conséquent, combiner la connaissance du domaine et les méthodes basées sur les données pour créer des modèles dotés de plus grandes capacités d’interprétabilité et de généralisation est devenu une direction importante dans la recherche scientifique actuelle. Ce genre de
Par exemple, le modèle texte-vidéo Sora développé par la société américaine OpenAI est très apprécié pour ses excellentes capacités de génération d'images et est considéré comme une avancée importante dans le domaine de l'intelligence artificielle. Bien qu'il soit capable de générer des images et des vidéos réalistes, Sora a encore quelques difficultés à gérer les lois de la physique, telles que la gravité et la fragmentation des objets. Bien que Sora ait fait des progrès significatifs dans la simulation de scénarios réels, il reste encore des progrès à faire dans la compréhension et la simulation précise des lois physiques. Le développement de la technologie de l’IA nécessite encore des efforts continus pour améliorer l’exhaustivité et la précision des modèles afin de mieux s’adapter aux diverses situations du monde réel.
Une façon potentielle de résoudre ce problème consiste à intégrer les connaissances humaines dans des modèles d’apprentissage profond. En combinant les connaissances et les données antérieures, la capacité de généralisation du modèle peut être améliorée, ce qui donne lieu à un modèle « d'apprentissage automatique éclairé » capable de comprendre les lois physiques. Cette approche devrait améliorer les performances et la précision des modèles, les rendant ainsi plus à même de faire face à des problèmes complexes du monde réel. En intégrant l'expérience et les connaissances d'experts humains dans les algorithmes d'apprentissage automatique, nous pouvons construire des systèmes plus intelligents et plus efficaces, favorisant ainsi le développement et l'application de la technologie de l'intelligence artificielle.
Actuellement, il manque encore une exploration approfondie de la valeur exacte des connaissances dans l’apprentissage profond. Il existe un problème urgent : déterminer quelles connaissances préalables peuvent être efficacement intégrées dans le modèle de « pré-apprentissage ». Dans le même temps, l’intégration aveugle de plusieurs règles peut conduire à l’échec du modèle, ce qui nécessite également une certaine attention. Ces limites posent des défis à l’exploration approfondie de la relation entre données et connaissances.
En réponse à ce problème, l'équipe de recherche de l'Eastern Institute of Technology (EIT) et de l'Université de Pékin a proposé le concept d'« importance des règles » et a développé un cadre capable de calculer avec précision la contribution de chaque règle à la précision des prédictions du modèle. Ce cadre révèle non seulement l'interaction complexe entre les données et les connaissances et fournit des conseils théoriques pour l'intégration des connaissances, mais aide également à équilibrer l'influence des connaissances et des données au cours du processus de formation. De plus, cette méthode peut également être utilisée pour identifier des règles a priori inappropriées, ouvrant ainsi de larges perspectives de recherche et d’application dans des domaines interdisciplinaires.
Cette recherche, intitulée « Prior Knowledge's Impact on Deep Learning », a été publiée le 8 mars 2024 dans la revue interdisciplinaire « Nexus » sous Cell Press. La recherche a retenu l'attention de l'AAAS (Association américaine pour l'avancement de la science) et d'EurekAlert !

Lorsque vous enseignez des puzzles aux enfants, vous pouvez soit les laisser trouver les réponses par essais et erreurs, soit les guider avec quelques règles et techniques de base. De même, l’intégration de règles et de techniques, telles que les lois de la physique, dans la formation en IA peut les rendre plus réalistes et plus efficaces. Cependant, comment évaluer la valeur de ces règles en intelligence artificielle a toujours été un problème difficile pour les chercheurs.
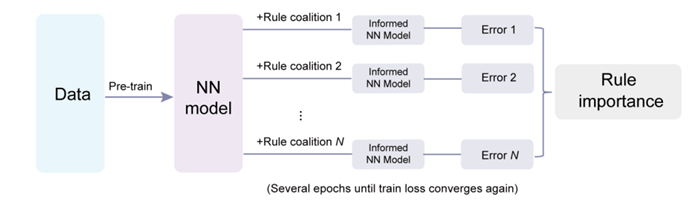
Compte tenu de la riche diversité des connaissances préalables, l'intégration des connaissances préalables dans les modèles d'apprentissage profond est une tâche d'optimisation multi-objectifs complexe. L’équipe de recherche propose de manière innovante un cadre pour quantifier le rôle de différentes connaissances antérieures dans l’amélioration des modèles d’apprentissage profond. Ils considèrent ce processus comme un jeu plein de coopération et de compétition et définissent l'importance des règles en évaluant leur contribution marginale aux prédictions des modèles. Tout d'abord, toutes les combinaisons de règles possibles (c'est-à-dire les « coalitions ») sont générées, un modèle est construit pour chaque combinaison et l'erreur quadratique moyenne est calculée.
Afin de réduire les coûts de calcul, ils ont adopté un algorithme efficace basé sur la perturbation : entraînez d'abord un réseau neuronal entièrement basé sur des données comme modèle de base, puis ajoutez chaque combinaison de règles une par une pour un entraînement supplémentaire, et enfin évaluez les performances du modèle. sur les données de test. En comparant les performances du modèle dans toutes les coalitions avec et sans règle, la contribution marginale de cette règle peut être calculée, et donc son importance.
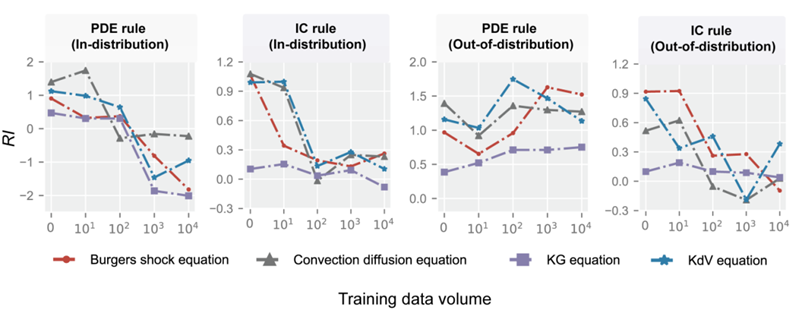
À travers des exemples de mécanique des fluides, les chercheurs ont exploré la relation complexe entre les données et les règles. Ils ont constaté que les données et les règles antérieures jouaient des rôles complètement différents dans différentes tâches. Lorsque la distribution des données de test et des données de formation est similaire (c'est-à-dire distribution interne), l'augmentation du volume de données affaiblira l'effet des règles.
Cependant, lorsque la similarité de distribution entre les données de test et les données d'entraînement est faible (c'est-à-dire hors distribution), l'importance des règles globales est soulignée, tandis que l'influence des règles locales est affaiblie. La différence entre ces deux types de règles réside dans le fait que les règles globales (telles que les équations gouvernantes) affectent l'ensemble du domaine, tandis que les règles locales (telles que les conditions aux limites) n'agissent que sur des domaines spécifiques.
L'équipe de recherche a découvert grâce à des expériences numériques que dans l'intégration des connaissances, il existe trois effets interactifs entre les règles : l'effet de dépendance et la synergie effet et effet de substitution.
L'effet de dépendance signifie que certaines règles doivent s'appuyer sur d'autres règles pour être efficaces ; l'effet de synergie montre que l'effet de plusieurs règles travaillant ensemble dépasse la somme de leurs effets indépendants ; données ou autres règles.
Ces trois effets existent en même temps et sont affectés par la quantité de données. En calculant l’importance des règles, ces effets peuvent être clairement démontrés, fournissant ainsi des indications importantes pour l’intégration des connaissances.
Au niveau de l'application, l'équipe de recherche a tenté de résoudre un problème central du processus d'intégration des connaissances : comment équilibrer le rôle des données et des règles pour améliorer l'efficacité de l'intégration et éliminer les connaissances antérieures inappropriées. Au cours du processus de formation du modèle, l’équipe a proposé une stratégie pour ajuster dynamiquement le poids des règles.
Plus précisément, à mesure que les étapes d'itération de formation augmentent, le poids des règles d'importance positive augmente progressivement, tandis que le poids des règles d'importance négative diminue. Cette stratégie peut ajuster l'attention du modèle sur différentes règles en temps réel en fonction des besoins du processus d'optimisation, permettant ainsi une intégration des connaissances plus efficace et plus précise.
De plus, enseigner les lois de la physique aux modèles d’IA peut les rendre « plus pertinents par rapport au monde réel et ainsi jouer un rôle plus important dans la science et l’ingénierie ». Par conséquent, ce cadre a un large éventail d’applications pratiques en ingénierie, en physique et en chimie. Les chercheurs ont non seulement optimisé le modèle d’apprentissage automatique pour résoudre des équations multivariées, mais ont également identifié avec précision des règles qui améliorent les performances du modèle de prédiction pour l’analyse par chromatographie sur couche mince.
Les résultats expérimentaux montrent qu'en incorporant ces règles efficaces, les performances du modèle sont considérablement améliorées et l'erreur quadratique moyenne sur l'ensemble de données de test est réduite de 0,052 à 0,036 (une réduction de 30,8 %). Cela signifie que le cadre peut transformer les informations empiriques en connaissances structurées, améliorant ainsi considérablement les performances du modèle.
En général, évaluer avec précision la valeur des connaissances permet de créer des modèles d'IA plus réalistes, d'améliorer la sécurité et la fiabilité, et revêt une grande importance pour le développement de l'apprentissage profond.

Ensuite, l'équipe de recherche prévoit de développer son cadre en un outil plug-in pouvant être utilisé par les développeurs d'intelligence artificielle. Leur objectif ultime est de développer des modèles capables d'extraire des connaissances et des règles directement à partir des données, puis de s'améliorer, créant ainsi un système en boucle fermée allant de la découverte des connaissances à l'intégration des connaissances, faisant du modèle un véritable scientifique en intelligence artificielle.
Lien papier : https://www.cell.com/nexus/fulltext/S2950-1601(24)00001-9
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que comprend le stockage par cryptage des données ?
Que comprend le stockage par cryptage des données ?
 Le rôle de l'attribut caption
Le rôle de l'attribut caption
 Historique des opérations de la table de vue Oracle
Historique des opérations de la table de vue Oracle
 Tutoriel de modification du logiciel C++ en chinois
Tutoriel de modification du logiciel C++ en chinois
 Qu'est-ce que le logiciel système
Qu'est-ce que le logiciel système
 Utilisation de caractères arbitraires dans les expressions régulières
Utilisation de caractères arbitraires dans les expressions régulières
 Quel navigateur est Edge ?
Quel navigateur est Edge ?
 Comment utiliser fusioncharts.js
Comment utiliser fusioncharts.js








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



