



L'apprentissage différenciable de bout en bout pour la conduite autonome est récemment devenu un paradigme important. Un goulot d’étranglement majeur réside dans l’énorme demande de données étiquetées de haute qualité, telles que les boîtes 3D et la segmentation sémantique, dont l’annotation manuelle est notoirement coûteuse. Cette difficulté est aggravée par le fait saillant que le comportement au sein de l’échantillon dans l’AD a souvent des distributions à longue traîne. En d’autres termes, la plupart des données collectées peuvent être triviales (par exemple, rouler sur une route droite), seules quelques situations étant critiques pour la sécurité. Dans cet article, nous explorons une question pratiquement importante mais sous-explorée, à savoir comment atteindre l’efficacité des échantillons et des étiquettes dans l’AD de bout en bout.
Plus précisément, l'article conçoit une méthode d'apprentissage actif orientée planification qui annote progressivement des parties des données brutes collectées en fonction de la diversité et des critères d'utilité des itinéraires de planification proposés. Empiriquement, l’approche proposée axée sur le plan peut surpasser dans une large mesure les approches générales d’apprentissage actif. Notamment, notre méthode atteint des performances comparables aux méthodes AD de bout en bout de pointe en utilisant seulement 30 % des données nuScenes. Espérons que notre travail inspirera les travaux futurs dans une perspective centrée sur les données, en plus des efforts méthodologiques.
Lien papier : https://arxiv.org/pdf/2403.02877.pdf
Contribution principale de cet article :
ActiveAD est décrit en détail dans le cadre AD de bout en bout, et les indicateurs de diversité et d'incertitude sont conçus en fonction des caractéristiques des données d'AD.
Pour l'apprentissage actif en vision par ordinateur, la sélection initiale d'échantillons est généralement basée uniquement sur l'image originale sans informations supplémentaires ni fonctionnalités apprises, ce qui conduit à la pratique courante de l'initialisation aléatoire. Dans le cas de la MA, des informations préalables supplémentaires sont disponibles. Plus précisément, lors de la collecte de données provenant de capteurs, des informations traditionnelles telles que la vitesse et la trajectoire du véhicule autonome peuvent être enregistrées simultanément. De plus, les conditions météorologiques et d’éclairage sont souvent continues et faciles à annoter au niveau des fragments. Ces informations facilitent la prise de décisions éclairées pour la sélection initiale des ensembles. Par conséquent, nous avons conçu une mesure d’auto-diversité pour la sélection initiale.
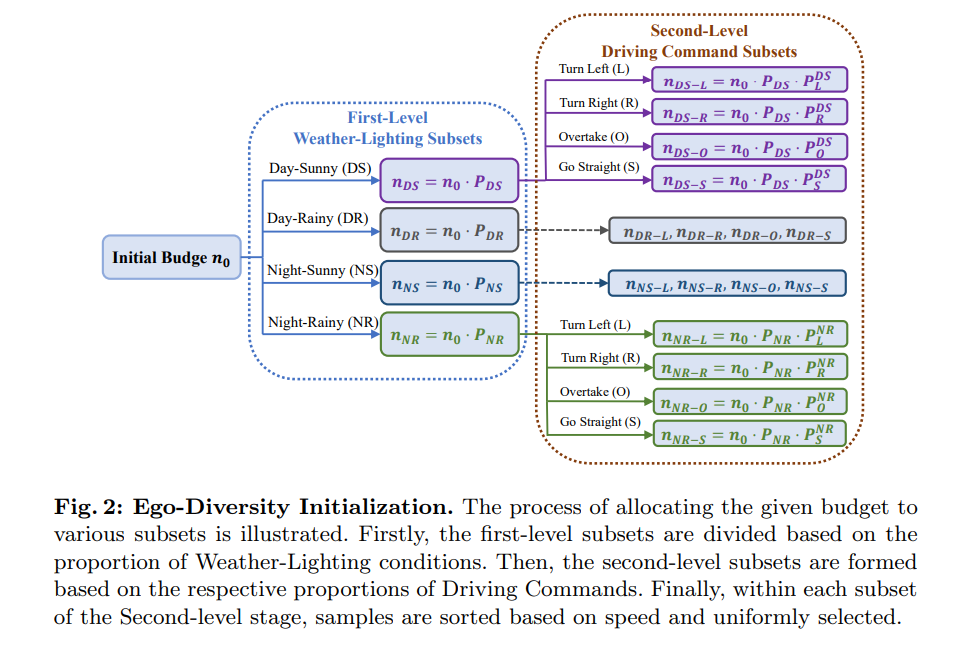
Ego Diversity : Se compose de trois parties : 1) Éclairage météo 2) Instructions de conduite 3) Vitesse moyenne. Tout d'abord, utilisez la description dans nuScenes pour diviser l'ensemble de données complet en quatre sous-ensembles mutuellement exclusifs : Day Sunny (DS), Day Rainy (DR), Night Sunny (NS), NightRainy (NR). Deuxièmement, chaque sous-ensemble est divisé en quatre catégories en fonction du nombre de commandes de conduite à gauche, à droite et en ligne droite dans un segment complet : virage à gauche (L), virage à droite (R), dépassement (O) et aller tout droit (S). L'article conçoit un seuil τc, où si le nombre de commandes gauche et droite dans un clip est supérieur ou égal au seuil τc, nous le considérons comme un comportement transcendant dans le clip. Si seul le nombre de commandes à gauche est supérieur au seuil τc, cela indique un virage à gauche. Si seul le nombre de commandes vers la droite est supérieur au seuil τc, cela indique un virage à droite. Tous les autres cas sont considérés comme directs. Troisièmement, calculez la vitesse moyenne dans chaque scène et triez-la par ordre croissant au sein du sous-ensemble concerné.
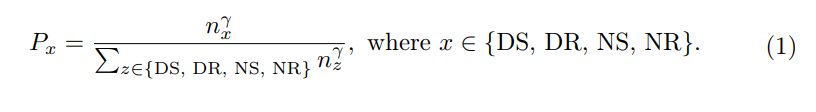
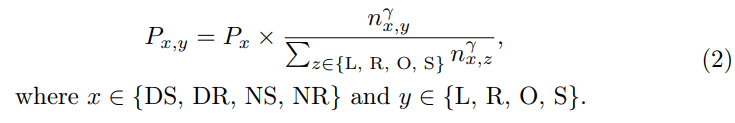
La figure 2 donne le processus intuitif détaillé du processus de sélection initial basé sur des arbres multi-voies.
Dans cette section, nous présenterons comment annoter de manière incrémentale de nouvelles parties d'un fragment sur la base d'un modèle entraîné à l'aide de fragments déjà annotés. Nous utiliserons le modèle intermédiaire pour effectuer une inférence sur des segments non étiquetés, et les sélections ultérieures seront basées sur ces sorties. Néanmoins, une perspective orientée vers la planification est adoptée et trois critères pour la sélection ultérieure des données sont introduits : les erreurs de déplacement, les collisions douces et les incertitudes proxy.
Standard 1 : Erreur de déplacement (DE). sera exprimée comme la distance entre l’itinéraire prévu τ du modèle et les trajectoires humaines τ* enregistrées dans l’ensemble de données.
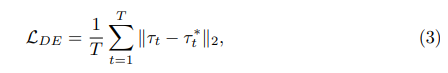
où T représente le cadre dans la scène. Puisque l’erreur de déplacement est elle-même une mesure de performance (aucune annotation requise), elle devient naturellement le premier et le plus critique critère de sélection active.
Standard 2 : Collision douce (SC). Le LSC est défini comme la distance entre la trajectoire prédite du véhicule autonome et la trajectoire prédite de l’agent. Les prédictions des agents de faible confiance seront filtrées par le seuil ε. Dans chaque scénario, la distance la plus courte est choisie comme mesure du coefficient de risque. Dans le même temps, une corrélation positive est maintenue entre terme et distance la plus proche :
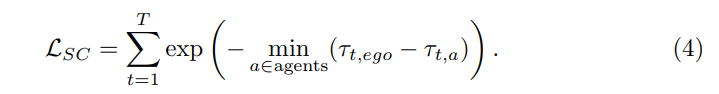
Utiliser la « collision douce » comme critère car : D'une part, contrairement à « l'erreur de déplacement », le calcul du « taux de collision » dépend sur la 3D de la cible Annotations pour les cases qui ne sont pas disponibles dans les données non étiquetées. Par conséquent, il devrait être possible de calculer le critère uniquement sur la base des résultats d’inférence du modèle. D'un autre côté, considérons un critère de collision dure : si la trajectoire prédite du véhicule personnel entre en collision avec les trajectoires d'autres agents prédits, attribuez-lui 1, sinon attribuez-lui 0. Cependant, cela peut entraîner un nombre insuffisant d'échantillons avec l'étiquette 1, car le taux de collision des modèles de pointe en AD est généralement faible (moins de 1 %). Par conséquent, il a été choisi d’utiliser la distance la plus proche des autres paires de cibles au lieu de la métrique du « taux de collision ». Le risque est considéré comme beaucoup plus élevé lorsque la distance par rapport aux autres véhicules ou aux piétons est trop proche. En bref, les « collisions légères » constituent une mesure efficace de la probabilité de collision et peuvent fournir une surveillance intensive.
Critère III : Incertitude de l'agent (AU). Les prédictions des trajectoires futures des agents environnants sont naturellement incertaines, de sorte que les modules de prédiction de mouvement génèrent généralement plusieurs modalités et scores de confiance correspondants. Notre objectif est de sélectionner les données pour lesquelles les agents proches ont une forte incertitude. Plus précisément, les sujets distants sont filtrés par un seuil de distance δ, et l'entropie pondérée des probabilités prédites de plusieurs modes pour les sujets restants est calculée. Supposons que le nombre de modalités est et que le score de confiance de l'agent dans différentes modalités est Pi(a), où i∈{1,…,Nm}. Ensuite, l'incertitude de l'agent peut être définie comme :
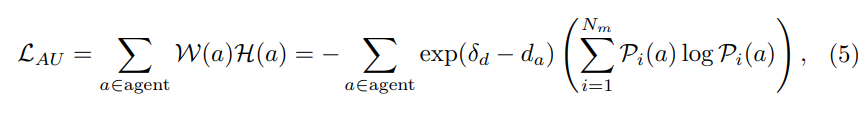
Perte globale :
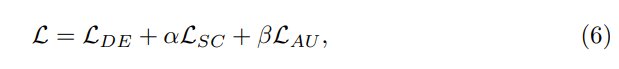
Alg1 présente l'ensemble du flux de travail de la méthode. Étant donné un budget disponible B, une taille de sélection initiale n0, le nombre de sélections d'activités effectuées à chaque étape ni et un total de M étapes de sélection. La sélection est d'abord initialisée à l'aide des méthodes de randomisation ou d'auto-diversité décrites ci-dessus. Ensuite, les données actuellement annotées sont utilisées pour entraîner le réseau. Sur la base du réseau formé, nous faisons des prédictions sur ceux non étiquetés et calculons la perte totale. Enfin, les échantillons sont triés en fonction de la perte globale et les ni meilleurs échantillons à annoter dans l'itération en cours sont sélectionnés. Ce processus est répété jusqu'à ce que l'itération atteigne la limite supérieure M et que le nombre d'échantillons sélectionnés atteigne la limite supérieure B.

Des expériences ont été menées sur l'ensemble de données nuScenes largement utilisé. Toutes les expériences sont mises en œuvre à l'aide de PyTorch et exécutées sur les GPU RTX 3090 et A100.
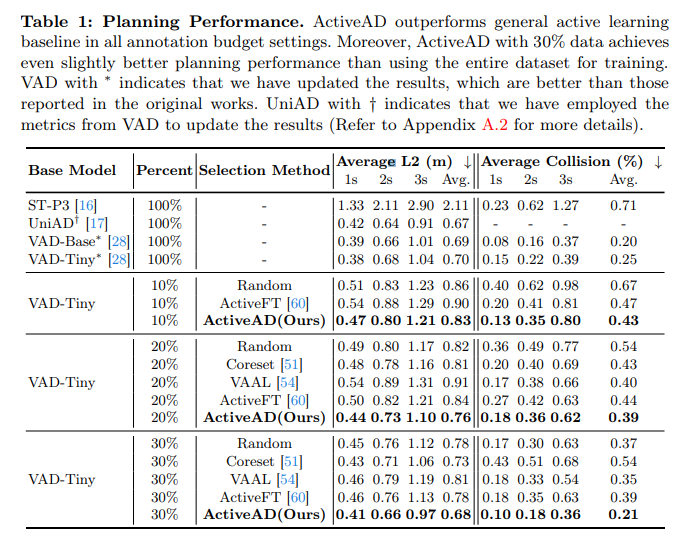
Tableau 1 : Performance de la planification. ActiveAD surpasse les références générales d'apprentissage actif dans tous les paramètres de budget d'annotation. De plus, ActiveAD avec 30 % des données a obtenu des performances de planification légèrement meilleures par rapport à la formation utilisant l'intégralité de l'ensemble de données. Les VAD avec * indiquent des résultats mis à jour qui sont meilleurs que ceux rapportés dans le travail original. UniAD avec † indique que les indicateurs de VAD ont été utilisés pour mettre à jour les résultats.
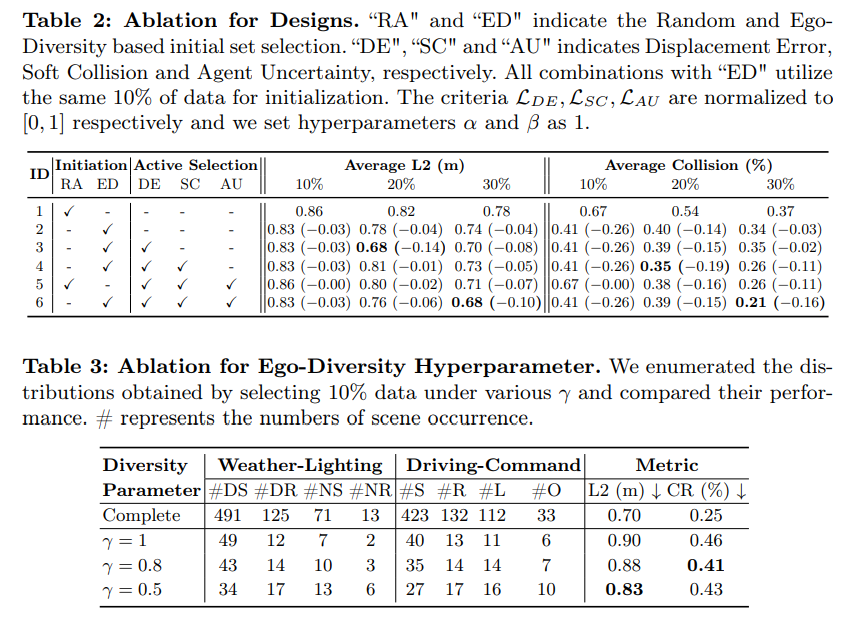
Tableau 2 : Expérience d'ablation conçue. « RA » et « ED » représentent la sélection initiale de l'ensemble basée sur le caractère aléatoire et l'auto-diversité. «DE», «SC» et «AU» représentent respectivement les erreurs de déplacement, qui sont respectivement une collision douce et une incertitude d'agent. Toutes les combinaisons avec « ED » sont initialisées avec les mêmes données à 10 %. LDE, LSC et LAU sont respectivement normalisés à [0, 1] et les hyperparamètres α et β sont définis sur 1.
Figure 3 : Visualisation des scènes sélectionnées. Critères d'erreur de déplacement (col 1), de collision douce (col 2), d'incertitude de l'agent (col 3) et hybride (col 4) basés sur des images de caméra frontale sélectionnées sur la base d'un modèle entraîné sur 10 % des données. Mixed représente notre stratégie de choix final, ActiveAD, et prend en considération les trois premiers scénarios !

Tableau 4, performances dans divers scénarios. Plus le taux de collision moyen L2(m)/moyen (%) du modèle actif utilisant 30 % des données est faible, meilleures sont les performances dans diverses conditions météorologiques/d'éclairage et de commande de conduite.
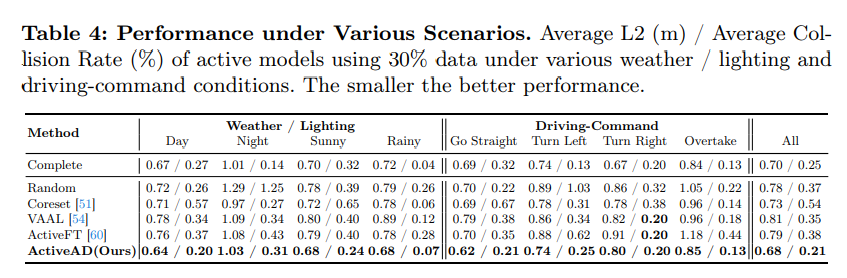
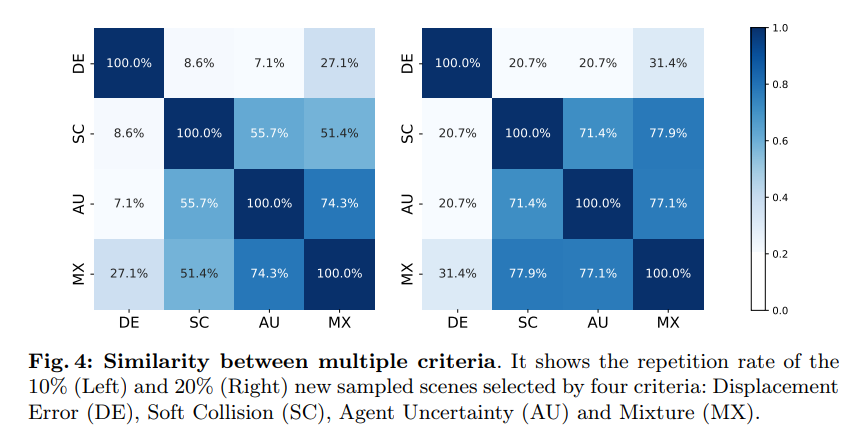
Figure 4 : Similitude entre plusieurs critères. Il montre le nouveau scénario d'échantillonnage avec 10 % (à gauche) et 20 % (à droite) sélectionnés selon quatre critères : erreur de déplacement (DE), collision douce (SC), incertitude de l'agent (AU) et mélange (MX)
Afin de résoudre les problèmes de coût élevé et de longue traîne de l'annotation de bout en bout des données de conduite autonome, nous avons pris l'initiative de développer une solution d'apprentissage actif sur mesure, ActiveAD. ActiveAD introduit de nouvelles mesures de diversité et d'incertitude spécifiques aux tâches, basées sur une philosophie orientée planification. Un grand nombre d'expériences prouvent l'efficacité de la méthode, utilisant seulement 30 % des données, elle dépasse largement les méthodes générales précédentes et atteint des performances comparables aux modèles de l'état de l'art. Cela représente une exploration significative de la conduite autonome de bout en bout dans une perspective centrée sur les données, et nous espérons que nos travaux pourront inspirer de futures recherches et découvertes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre un téléphone de remplacement officiel et un téléphone neuf
La différence entre un téléphone de remplacement officiel et un téléphone neuf
 Utilisation de strncpy
Utilisation de strncpy
 Méthode d'enregistrement du compte Google
Méthode d'enregistrement du compte Google
 Solution à l'autorisation refusée
Solution à l'autorisation refusée
 Marquage de couleur du filtre en double Excel
Marquage de couleur du filtre en double Excel
 Windows change le type de fichier
Windows change le type de fichier
 La différence et le lien entre le langage C et C++
La différence et le lien entre le langage C et C++
 impossible d'ouvrir la page Web
impossible d'ouvrir la page Web








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



