


Dans la vague actuelle de changements technologiques rapides, l’intelligence artificielle (IA), l’apprentissage automatique (ML) et l’apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l’information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère.
Alors jetons d’abord un coup d’œil à cette photo.

On peut constater qu'il existe une corrélation étroite et une relation progressive entre l'apprentissage profond, l'apprentissage automatique et l'intelligence artificielle. L’apprentissage profond est un domaine spécifique de l’apprentissage automatique, qui constitue une composante importante de l’intelligence artificielle. Les connexions et la promotion mutuelle entre ces domaines permettent le développement et l’amélioration continus de la technologie de l’intelligence artificielle.
L'intelligence artificielle (IA) est un concept vaste dont l'objectif principal est de développer des systèmes informatiques capables de simuler, d'étendre, voire de surpasser l'intelligence humaine. Elle a des applications spécifiques dans de nombreux domaines, tels que :
Ces technologies haut de gamme sont recherchées et appliquées autour du concept principal de « simulation de l'intelligence humaine ». Ils se concentrent sur le développement de différentes dimensions de perception (telles que la vision, l'audition, la logique de la pensée, etc.) et promeuvent conjointement le développement et les progrès continus de la technologie de l'intelligence artificielle.
Le Machine Learning (ML) est une branche cruciale dans le domaine de l'intelligence artificielle (IA). Il utilise divers algorithmes pour permettre aux systèmes informatiques d'apprendre automatiquement des règles et des modèles à partir des données afin de faire des prédictions et des décisions, améliorant et élargissant ainsi les capacités de l'intelligence humaine.
Par exemple, lors de la formation d'un modèle de reconnaissance de chat, le processus d'apprentissage automatique est le suivant :
Les 10 principaux algorithmes d'apprentissage automatique couramment utilisés sont : l'arbre de décision, la forêt aléatoire, la régression logistique, SVM, Naive Bayes, l'algorithme K le plus proche voisin, l'algorithme K-means, l'algorithme Adaboost, le réseau neuronal, Markov, etc.
Le Deep Learning (DL) est une forme spéciale d'apprentissage automatique. Il simule la façon dont le cerveau humain traite les informations via une structure de réseau neuronal profond, extrayant ainsi automatiquement des représentations de caractéristiques complexes à partir des données.
Par exemple, lors de la formation d'un modèle de reconnaissance de chat, le processus d'apprentissage en profondeur est le suivant :
(1) Prétraitement et préparation des données :
(2) Conception et construction du modèle :
(3) Paramètres d'initialisation et définition des hyperparamètres :
(4) Propagation avant :
(5) Fonction de perte et rétropropagation :
(6) Optimisation et mise à jour des paramètres :
(7) Vérification et évaluation :
(8) Achèvement de la formation et tests :
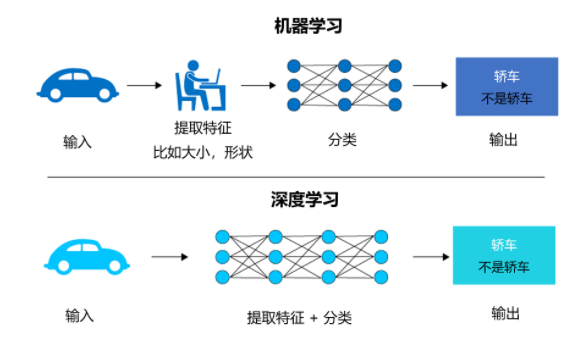
La différence entre l'apprentissage profond et l'apprentissage automatique est la suivante :
Les algorithmes d'apprentissage automatique reposent généralement sur une ingénierie de fonctionnalités conçue par l'homme, c'est-à-dire pré. -extraction basée sur la connaissance de base du problème Fonctionnalités clés, puis création d'un modèle basé sur ces fonctionnalités et exécution de solutions d'optimisation.
Le Deep Learning adopte une méthode d'apprentissage de bout en bout, générant automatiquement des fonctionnalités abstraites de haut niveau grâce à une transformation non linéaire multicouche, et ces fonctionnalités sont continuellement optimisées pendant tout le processus de formation. Il n'est pas nécessaire de les sélectionner et de les sélectionner manuellement. construire des caractéristiques plus proches du style de traitement cognitif du cerveau.
Par exemple, si vous souhaitez écrire un logiciel pour reconnaître une voiture, si vous utilisez l'apprentissage automatique, vous devez extraire manuellement les caractéristiques de la voiture, telles que la taille et la forme et si vous utilisez l'apprentissage profond, alors l'intelligence artificielle ; neuronal Le réseau extrait ces fonctionnalités lui-même, mais il nécessite un grand nombre d'images étiquetées comme des voitures pour les apprendre.
L'application de l'apprentissage automatique dans la reconnaissance d'empreintes digitales, la détection d'objets caractéristiques et d'autres domaines a fondamentalement atteint les exigences de commercialisation.
Le deep learning est principalement utilisé dans la reconnaissance de texte, la technologie faciale, l'analyse sémantique, la surveillance intelligente et d'autres domaines. À l'heure actuelle, il se déploie également rapidement dans les secteurs du matériel intelligent, de l'éducation, de la médecine et autres.
Les algorithmes d'apprentissage automatique peuvent également montrer de bonnes performances dans de petits exemples de cas. Pour certaines tâches simples ou problèmes où les fonctionnalités sont faciles à extraire, moins de données peuvent obtenir des résultats satisfaisants.
L'apprentissage profond nécessite généralement une grande quantité de données annotées pour former des réseaux de neurones profonds. Son avantage est qu'il peut apprendre directement des modèles et des représentations complexes à partir des données d'origine, en particulier lorsque la taille des données augmente, ce qui améliore les performances du modèle d'apprentissage profond. est plus significatif.
Pendant la phase de formation, en raison du plus grand nombre de couches de modèles d'apprentissage profond et du grand nombre de paramètres, le processus de formation prend souvent du temps et nécessite le support de ressources informatiques hautes performances, telles que Clusters GPU.
En comparaison, les algorithmes d'apprentissage automatique (en particulier les modèles légers) nécessitent généralement moins de temps de formation et de ressources informatiques, et sont plus adaptés à une itération rapide et à une vérification expérimentale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 WeChat restaure l'historique des discussions
WeChat restaure l'historique des discussions
 Une liste complète des DNS publics couramment utilisés
Une liste complète des DNS publics couramment utilisés
 Que signifie le routage Java ?
Que signifie le routage Java ?
 Quelles sont les nouvelles fonctionnalités d'es6
Quelles sont les nouvelles fonctionnalités d'es6
 Explication détaillée de l'événement onbeforeunload
Explication détaillée de l'événement onbeforeunload
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



