


Les exigences matérielles sont de plus en plus faibles et la vitesse de génération devient de plus en plus rapide.
Stability AI, en tant que pionnier de la conversion texte-image, non seulement mène la tendance, mais continue également de faire de nouvelles avancées en matière de qualité des modèles. Cette fois, il a réalisé une percée en termes de rapport coût/performance.
Il y a quelques jours à peine, Stability AI a pris une autre décision : la version préliminaire de recherche de Stable Cascade a été lancée. Ce modèle de conversion texte-image innove en introduisant une approche en trois étapes qui établit de nouvelles références en matière de qualité, de flexibilité, de réglage fin et d'efficacité, en mettant l'accent sur la suppression des barrières matérielles. De plus, Stability AI publie du code de formation et d'inférence, permettant une personnalisation plus poussée du modèle et de sa sortie. Le modèle est disponible pour inférence dans la bibliothèque des diffuseurs. Ce modèle est publié sous une licence non commerciale, autorisant uniquement une utilisation non commerciale.


Source : https://twitter.com/multimodalart/status/1757391981074903446
Une cascade stable est générée extrêmement rapide. L'utilisateur de la plate-forme X @GozukaraFurkan a déclaré qu'il ne nécessite qu'environ 9 Go de mémoire GPU et que la vitesse peut toujours être bien maintenue.
. la précision de la génération de mots/phrases plus courts est relativement élevée, des phrases longues peuvent également être complétées avec une certaine probabilité (en anglais uniquement), et l'intégration du texte et des images est également très bonne. #
 L'utilisateur @AIWarper a essayé différents tests de style d'artiste.
L'utilisateur @AIWarper a essayé différents tests de style d'artiste.
invite : Cauchemar sur Elm Street. Les références de style d'artiste sont les suivantes : Makoto Shinkai en haut à gauche, Tomer Hanuka en bas à gauche, Raphael Kirchner en haut à droite, Takato Yamamoto en bas à droite.

Cependant, lors de la génération du visage du personnage, vous pouvez constater que les détails de la peau du personnage ne sont pas très bons, et cela ressemble à un « meulage de peau de dixième niveau ».
Source de l'image : https://twitter.com/vitor_dlucca/status/ 1757511080287355093
Détails techniques Stable Cascade est différent de la série de modèles Stable Diffusion. Il est construit sur trois modèles différents. modèles Sur le pipeline composé de : étapes A, B et C. Cette architecture peut effectuer une compression hiérarchique des images et utiliser un espace latent hautement compressé pour obtenir un résultat supérieur. Comment ces pièces s’emboîtent-elles ?
L'étape de génération d'images latentes (étape C) convertit l'entrée de l'utilisateur en une représentation latente compacte 24x24, qui est ensuite transmise à l'étape de décodage latente (étapes A et B) pour compresser l'image, ce qui est similaire au travail de VAE dans Diffusion Stable, mais peut atteindre une compression plus élevée.
En dissociant la génération de conditions de texte (étape C) du décodage à l'espace de pixels haute résolution (étapes A et B), nous pouvons effectuer une formation supplémentaire ou affiner l'étape C, y compris ControlNets et LoRA, similaire à la formation par rapport à la Modèle à diffusion stable de même taille, le coût peut être réduit au seizième. Les étapes A et B peuvent éventuellement être affinées pour un contrôle supplémentaire, mais cela sera similaire au réglage fin de la VAE dans le modèle de diffusion stable. Dans la plupart des cas, les avantages d’une telle démarche sont minimes. Par conséquent, dans la plupart des cas, Stability AI recommande officiellement de former uniquement la phase C et d'utiliser l'état d'origine des phases A et B.
Les phases C et B lanceront deux modèles différents : les modèles de paramètres 1B et 3,6B pour la phase C, et les modèles de paramètres 700M et 1,5B pour la phase B. Un modèle avec des paramètres 3,6B est recommandé pour l'étape C car ce modèle offre la plus haute qualité de sortie. Cependant, pour ceux qui souhaitent disposer de la configuration matérielle minimale requise, une version de paramètres 1B est disponible. Pour l'étape B, les deux versions obtiennent de bons résultats, mais la version avec paramètres 1,5B est plus performante en termes de détails de reconstruction. Grâce à l'approche modulaire de Stable Cascade, les besoins en VRAM attendus pour l'inférence peuvent être limités à environ 20 Go. Ceci peut être encore réduit en utilisant des variantes plus petites, avec l'avertissement que cela peut également réduire la qualité du résultat final.
Comparaison
Lors de l'évaluation, Stable Cascade a obtenu les meilleurs résultats en termes d'alignement rapide et de qualité esthétique par rapport à presque tous les modèles comparés. La figure ci-dessous montre les résultats de l'évaluation humaine utilisant un mélange d'invites partielles et d'invites esthétiques :
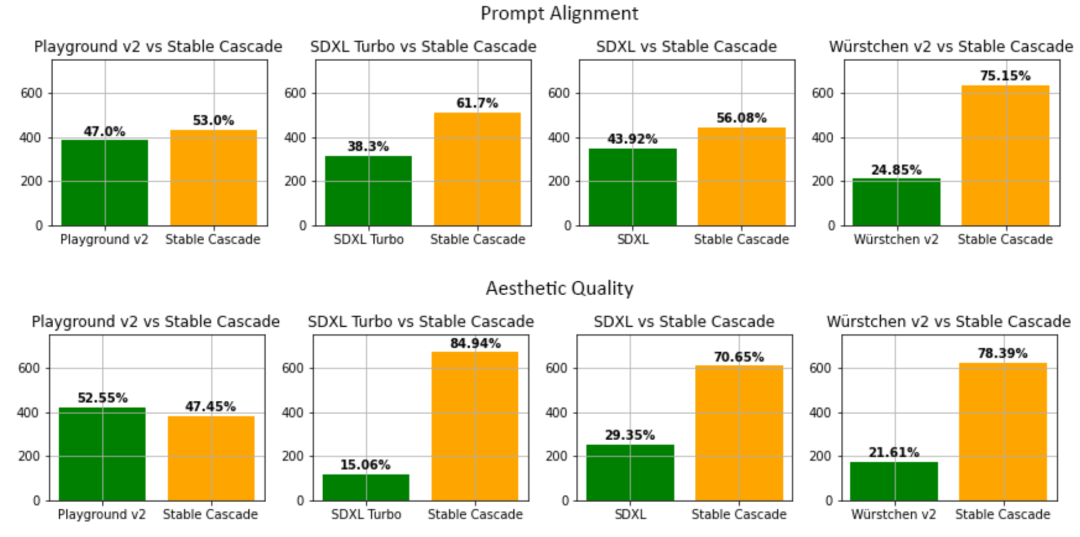
Stable Cascade (30 étapes d'inférence) vs. Playground v2 (50 étapes d'inférence), SDXL (50 étapes d'inférence) , SDXL Turbo (1 étape de raisonnement) et Würstchen V2 (30 étapes de raisonnement) sont comparés
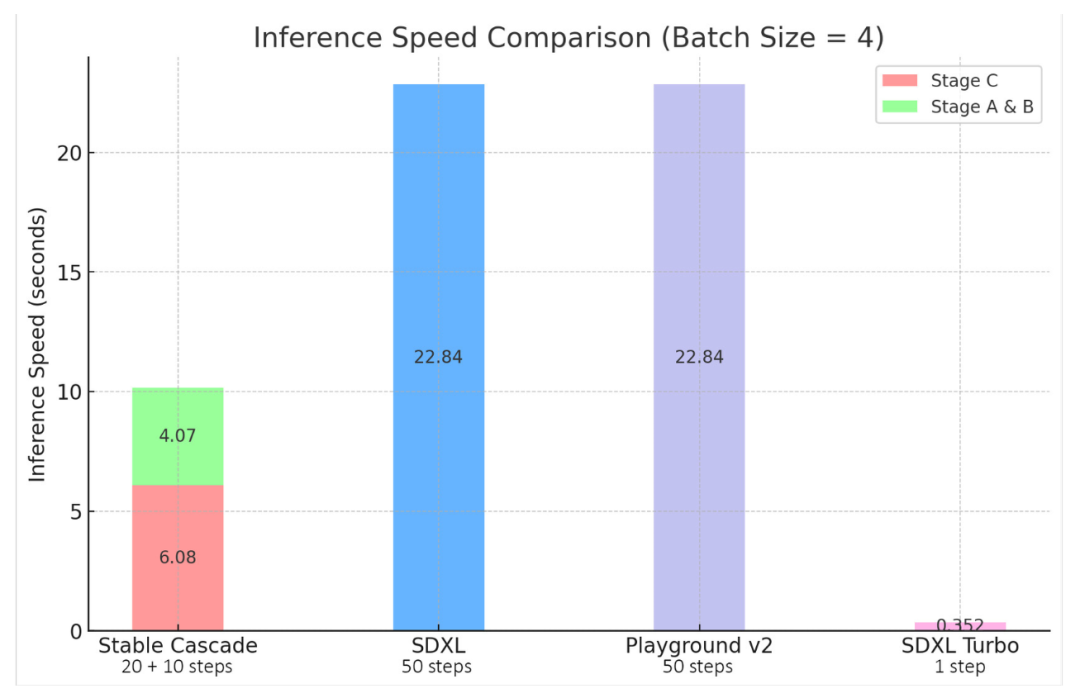
Stable Cascade, SDXL, Playground V2 et SDXL Turbo L'accent mis par Stable Cascade sur l'efficacité est démontré à travers son architecture et. potentiel de compression plus élevé. Même si le plus grand modèle comporte 1,4 milliard de paramètres de plus que Stable Diffusion XL, il offre toujours des temps d'inférence plus rapides.
Fonctionnalités ajoutées
En plus de la génération texte-image standard, Stable Cascade peut également générer des variations d'image et une génération image-image.
La variante d'image extrait les intégrations d'images d'une image donnée à l'aide de CLIP, puis les renvoie au modèle. L'image ci-dessous est un exemple de sortie. L'image de gauche montre l'image originale, tandis que les quatre à droite sont les variantes générées.Image à image en ajoutant simplement du bruit à une image donnée, puis en générant une image à partir de celle-ci comme point de départ. Vous trouverez ci-dessous un exemple d'ajout de bruit à l'image de gauche, puis de génération à partir de là. 
 Code pour la formation, le réglage fin, ControlNet et LoRA
Code pour la formation, le réglage fin, ControlNet et LoRA
Avec la sortie de Stable Cascade, Stability AI publiera tout le code pour la formation, le réglage fin, ControlNet et LoRA afin de réduire les exigences d'expérimentation ultérieure avec cette architecture. Voici quelques ControlNets qui seront publiés avec le modèle :
Patch/Enlarge : saisissez une image et ajoutez un masque pour correspondre à l'invite de texte. Le modèle remplira ensuite la partie masquée de l'image en fonction des indications textuelles fournies.Canny Edge : génère de nouvelles images basées sur les bords des images existantes introduites dans le modèle. Selon les tests Stability AI, il peut également mettre à l’échelle des croquis.型 Le haut est l'esquisse du modèle d'entrée et le bas est le résultat de sortie 
Super-résolution 2x : l'augmentation de la résolution d'une image à 2x sa longueur de côté, par exemple en convertissant une image 1024 x 1024 en une sortie 2048 x 2048, peut également être utilisée pour la représentation latente générée par l'étape C.

Vous aimez ce rapport qualité/prix ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Méthode BigDecimal pour comparer les tailles
Méthode BigDecimal pour comparer les tailles
 Comment désactiver le pare-feu
Comment désactiver le pare-feu
 éditeur HTML en ligne
éditeur HTML en ligne
 Processus d'achat et de vente de Bitcoin sur Huobi.com
Processus d'achat et de vente de Bitcoin sur Huobi.com
 Le serveur est introuvable sur la solution informatique
Le serveur est introuvable sur la solution informatique
 Comment Oracle crée une base de données
Comment Oracle crée une base de données
 Introduction à l'utilisation de la fonction sort() en python
Introduction à l'utilisation de la fonction sort() en python
 Sur quelle touche dois-je appuyer pour récupérer lorsque je ne parviens pas à taper sur le clavier de mon ordinateur ?
Sur quelle touche dois-je appuyer pour récupérer lorsque je ne parviens pas à taper sur le clavier de mon ordinateur ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



