


La liste chaînée est une structure de données couramment utilisée pour organiser des données ordonnées. Il connecte une série de nœuds de données dans une chaîne de données via des pointeurs et constitue une méthode de mise en œuvre importante des tableaux linéaires. Par rapport aux tableaux, les listes chaînées sont plus dynamiques. Lors de la création d'une liste chaînée, il n'est pas nécessaire de connaître la quantité totale de données à l'avance, l'espace peut être alloué de manière aléatoire et les données peuvent être insérées ou supprimées efficacement à n'importe quel endroit de la liste chaînée en temps réel. Le principal problème des listes chaînées est la séquentialité de l'accès et la perte d'espace liée à l'organisation de la chaîne.
Généralement, une structure de données de liste chaînée doit contenir au moins deux champs : un champ de données et un champ de pointeur. Le champ de données est utilisé pour stocker des données et le champ de pointeur est utilisé pour établir le contact avec le nœud suivant. Selon l'organisation du champ de pointeur et le formulaire de connexion entre chaque nœud, la liste chaînée peut être divisée en différents types tels que la liste chaînée simple, la liste chaînée double, la liste chaînée circulaire, etc. Voici des diagrammes schématiques de ces types de listes chaînées courants :
La liste chaînée unique est le type de liste chaînée le plus simple. Sa caractéristique est qu'il n'y a qu'un seul champ de pointeur pointant vers le nœud suivant (suivant). Par conséquent, la liste chaînée unique ne peut être parcourue que séquentiellement du début à la fin (généralement un pointeur NULL). ).
En concevant les deux champs de pointeur du prédécesseur et du successeur, la liste à double chaînage peut être parcourue dans deux directions, ce qui la distingue de la liste à chaînage unique. Si la relation de dépendance entre le prédécesseur et le successeur est perturbée, un « arbre binaire » peut être formé si le prédécesseur du premier nœud pointe vers le nœud de queue de la liste chaînée et que le successeur du nœud de queue pointe vers le premier nœud ; (comme le montre la ligne pointillée de la figure 2), une liste chaînée circulaire est formée. Si davantage de champs de pointeur sont conçus, diverses structures de données arborescentes complexes peuvent être formées.
La caractéristique d'une liste chaînée circulaire est que le successeur du nœud de queue pointe vers le premier nœud. Le diagramme schématique d'une liste chaînée double circulaire a été donné précédemment. Sa caractéristique est qu'à partir de n'importe quel nœud et dans les deux sens, toutes les données de la liste chaînée peuvent être trouvées. Si le pointeur prédécesseur est supprimé, il s’agit d’une seule liste chaînée circulaire.
Un grand nombre de structures de listes chaînées sont utilisées dans le noyau Linux pour organiser les données, y compris les listes de périphériques et l'organisation des données dans divers modules fonctionnels. La plupart de ces listes chaînées utilisent une structure de données de liste chaînée assez intéressante implémentée dans [include/linux/list.h]. Les sections suivantes de cet article présenteront en détail l’organisation et l’utilisation de cette structure de données à travers des exemples.
Bien que le noyau 2.6 soit utilisé comme base d'explication ici, en fait la structure de liste chaînée dans le noyau 2.4 n'est pas différente de celle de la version 2.6. La différence est que la version 2.6 étend deux structures de données de liste chaînée : la mise à jour de la copie en lecture de la liste chaînée (rcu) et la liste chaînée HASH (hlist). Les deux extensions sont basées sur la structure de liste la plus élémentaire. Par conséquent, cet article présente principalement la structure de base des listes chaînées, puis présente brièvement rcu et hlist.
La définition de la structure de données de la liste chaînée est très simple (extraits de [include/linux/list.h], tous les codes suivants, sauf indication contraire, sont extraits de ce fichier) :
struct list_head {
struct list_head *next, *prev;
};
La structure list_head contient deux pointeurs prev et next pointant vers la structure list_head. On peut voir que la liste chaînée du noyau a la fonction d'une liste chaînée double. En fait, elle est généralement organisée en une liste chaînée double circulaire.
Différent du modèle de structure de liste à double lien introduit dans la première section, le list_head n'a ici aucun champ de données. Dans la liste chaînée du noyau Linux, au lieu de contenir des données dans la structure de liste chaînée, les nœuds de la liste chaînée sont contenus dans la structure de données.
Dans les manuels de structure de données, la définition classique d'une liste chaînée est généralement la suivante (en prenant comme exemple une liste chaînée) :
struct list_node {
struct list_node *next;
ElemType data;
};
En raison d'ElemType, chaque type d'élément de données doit définir sa propre structure de liste chaînée. Les programmeurs C++ expérimentés doivent savoir que la bibliothèque de modèles standard utilise le modèle C++, qui utilise des modèles pour résumer les interfaces d'opération de liste chaînée indépendantes des types d'éléments de données.
在Linux内核链表中,需要用链表组织起来的数据通常会包含一个struct list_head成员,例如在[include/linux/netfilter.h]中定义了一个nf_sockopt_ops结构来描述Netfilter为某一协议族准备的getsockopt/setsockopt接口,其中就有一个(struct list_head list)成员,各个协议族的nf_sockopt_ops结构都通过这个list成员组织在一个链表中,表头是定义在[net/core/netfilter.c]中的nf_sockopts(struct list_head)。从下图中我们可以看到,这种通用的链表结构避免了为每个数据项类型定义自己的链表的麻烦。Linux的简捷实用、不求完美和标准的风格,在这里体现得相当充分。

实际上Linux只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看LIST_HEAD()这个宏:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
当我们用LIST_HEAD(nf_sockopts)声明一个名为nf_sockopts的链表头时,它的next、prev指针都初始化为指向自己,这样,我们就有了一个空链表,因为Linux用头指针的next是否指向自己来判断链表是否为空:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
除了用LIST_HEAD()宏在声明的时候初始化一个链表以外,Linux还提供了一个INIT_LIST_HEAD宏用于运行时初始化链表:
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); (ptr)->prev = (ptr); /
} while (0)
我们用INIT_LIST_HEAD(&nf_sockopts)来使用它。
a) 插入
对链表的插入操作有两种:在表头插入和在表尾插入。Linux为此提供了两个接口:
static inline void list_add(struct list_head *new, struct list_head *head); static inline void list_add_tail(struct list_head *new, struct list_head *head);
因为Linux链表是循环表,且表头的next、prev分别指向链表中的第一个和最末一个节点,所以,list_add和list_add_tail的区别并不大,实际上,Linux分别用
__list_add(new, head, head->next);
和
__list_add(new, head->prev, head);
来实现两个接口,可见,在表头插入是插入在head之后,而在表尾插入是插入在head->prev之后。
假设有一个新nf_sockopt_ops结构变量new_sockopt需要添加到nf_sockopts链表头,我们应当这样操作:
list_add(&new_sockopt.list, &nf_sockopts);
从这里我们看出,nf_sockopts链表中记录的并不是new_sockopt的地址,而是其中的list元素的地址。如何通过链表访问到new_sockopt呢?下面会有详细介绍。
b) 删除
static inline void list_del(struct list_head *entry);
当我们需要删除nf_sockopts链表中添加的new_sockopt项时,我们这么操作:
list_del(&new_sockopt.list);
被剔除下来的new_sockopt.list,prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问–对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。与之相对应,list_del_init()函数将节点从链表中解下来之后,调用LIST_INIT_HEAD()将节点置为空链状态。
c) 搬移
Linux提供了将原本属于一个链表的节点移动到另一个链表的操作,并根据插入到新链表的位置分为两类:
static inline void list_move(struct list_head *list, struct list_head *head); static inline void list_move_tail(struct list_head *list, struct list_head *head);
例如list_move(&new_sockopt.list,&nf_sockopts)会把new_sockopt从它所在的链表上删除,并将其再链入nf_sockopts的表头。
d) 合并
除了针对节点的插入、删除操作,Linux链表还提供了整个链表的插入功能:
static inline void list_splice(struct list_head *list, struct list_head *head);
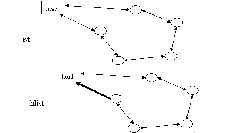
假设当前有两个链表,表头分别是list1和list2(都是struct list_head变量),当调用list_splice(&list1,&list2)时,只要list1非空,list1链表的内容将被挂接在list2链表上,位于list2和list2.next(原list2表的第一个节点)之间。新list2链表将以原list1表的第一个节点为首节点,而尾节点不变。如图(虚箭头为next指针):
图4 链表合并list_splice(&list1,&list2)

当list1被挂接到list2之后,作为原表头指针的list1的next、prev仍然指向原来的节点,为了避免引起混乱,Linux提供了一个list_splice_init()函数:
static inline void list_splice_init(struct list_head *list, struct list_head *head);
该函数在将list合并到head链表的基础上,调用INIT_LIST_HEAD(list)将list设置为空链。
遍历是链表最经常的操作之一,为了方便核心应用遍历链表,Linux链表将遍历操作抽象成几个宏。在介绍遍历宏之前,我们先看看如何从链表中访问到我们真正需要的数据项。
a) 由链表节点到数据项变量
我们知道,Linux链表中仅保存了数据项结构中list_head成员变量的地址,那么我们如何通过这个list_head成员访问到作为它的所有者的节点数据呢?Linux为此提供了一个list_entry(ptr,type,member)宏,其中ptr是指向该数据中list_head成员的指针,也就是存储在链表中的地址值,type是数据项的类型,member则是数据项类型定义中list_head成员的变量名,例如,我们要访问nf_sockopts链表中首个nf_sockopt_ops变量,则如此调用:
list_entry(nf_sockopts->next, struct nf_sockopt_ops, list);
这里”list”正是nf_sockopt_ops结构中定义的用于链表操作的节点成员变量名。
list_entry的使用相当简单,相比之下,它的实现则有一些难懂:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
container_of宏定义在[include/linux/kernel.h]中:
#define container_of(ptr, type, member) ({ /
const typeof( ((type *)0)->member ) *__mptr = (ptr); /
(type *)( (char *)__mptr - offsetof(type,member) );})
offsetof宏定义在[include/linux/stddef.h]中:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
size_t最终定义为unsigned int(i386)。
这里使用的是一个利用编译器技术的小技巧,即先求得结构成员在与结构中的偏移量,然后根据成员变量的地址反过来得出属主结构变量的地址。
container_of()和offsetof()并不仅用于链表操作,这里最有趣的地方是((type *)0)->member,它将0地址强制”转换”为type结构的指针,再访问到type结构中的member成员。在container_of宏中,它用来给typeof()提供参数(typeof()是gcc的扩展,和sizeof()类似),以获得member成员的数据类型;在offsetof()中,这个member成员的地址实际上就是type数据结构中member成员相对于结构变量的偏移量。
如果这么说还不好理解的话,不妨看看下面这张图:
图5 offsetof()宏的原理

对于给定一个结构,offsetof(type,member)是一个常量,list_entry()正是利用这个不变的偏移量来求得链表数据项的变量地址。
b) 遍历宏
在[net/core/netfilter.c]的nf_register_sockopt()函数中有这么一段话:
……
struct list_head *i;
……
list_for_each(i, &nf_sockopts) {
struct nf_sockopt_ops *ops = (struct nf_sockopt_ops *)i;
……
}
……
函数首先定义一个(struct list_head *)指针变量i,然后调用list_for_each(i,&nf_sockopts)进行遍历。在[include/linux/list.h]中,list_for_each()宏是这么定义的:
#define list_for_each(pos, head) / for (pos = (head)->next, prefetch(pos->next); pos != (head); / pos = pos->next, prefetch(pos->next))
它实际上是一个for循环,利用传入的pos作为循环变量,从表头head开始,逐项向后(next方向)移动pos,直至又回到head(prefetch()可以不考虑,用于预取以提高遍历速度)。
那么在nf_register_sockopt()中实际上就是遍历nf_sockopts链表。为什么能直接将获得的list_head成员变量地址当成struct nf_sockopt_ops数据项变量的地址呢?我们注意到在struct nf_sockopt_ops结构中,list是其中的第一项成员,因此,它的地址也就是结构变量的地址。更规范的获得数据变量地址的用法应该是:
struct nf_sockopt_ops *ops = list_entry(i, struct nf_sockopt_ops, list);
大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。对此Linux给出了一个list_for_each_entry()宏:
#define list_for_each_entry(pos, head, member) ……
与list_for_each()不同,这里的pos是数据项结构指针类型,而不是(struct list_head *)。nf_register_sockopt()函数可以利用这个宏而设计得更简单:
……
struct nf_sockopt_ops *ops;
list_for_each_entry(ops,&nf_sockopts,list){
……
}
……
某些应用需要反向遍历链表,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()来完成这一操作,使用方法和上面介绍的list_for_each()、list_for_each_entry()完全相同。
如果遍历不是从链表头开始,而是从已知的某个节点pos开始,则可以使用list_for_each_entry_continue(pos,head,member)。有时还会出现这种需求,即经过一系列计算后,如果pos有值,则从pos开始遍历,如果没有,则从链表头开始,为此,Linux专门提供了一个list_prepare_entry(pos,head,member)宏,将它的返回值作为list_for_each_entry_continue()的pos参数,就可以满足这一要求。
在并发执行的环境下,链表操作通常都应该考虑同步安全性问题,为了方便,Linux将这一操作留给应用自己处理。Linux链表自己考虑的安全性主要有两个方面:
a) list_empty()判断
La liste chaînée de base () détermine uniquement si la liste chaînée est vide selon que le prochain pointeur de tête pointe vers lui-même. La liste chaînée Linux fournit une macro list_empty_careful(), qui détermine simultanément le prochain et le précédent du pointeur de tête, uniquement. si les deux pointent vers lui-même, renvoie vrai alors seulement. Il s'agit principalement de faire face à la situation dans laquelle next et prev sont incohérents en raison d'un autre processeur traitant la même liste chaînée. Cependant, les commentaires du code admettent également que cette capacité de garantie de sécurité est limitée : à moins que l'opération de liste chaînée d'autres CPU ne soit uniquement list_del_init(), la sécurité ne peut pas être garantie, c'est-à-dire qu'une protection par verrouillage est toujours requise.
b) Les nœuds sont supprimés pendant la traversée
Plusieurs macros pour le parcours de liste chaînée ont été introduites précédemment. Elles atteignent toutes l'objectif de parcours en déplaçant le pointeur pos. Mais si l'opération de parcours inclut la suppression du nœud pointé par le pointeur pos, le mouvement du pointeur pos sera interrompu, car list_del(pos) définira le suivant et le précédent de pos sur les valeurs spéciales de LIST_POSITION2 et LISTE_POSITION1.
Bien sûr, l'appelant peut lui-même mettre en cache le pointeur suivant pour rendre l'opération de traversée cohérente, mais par souci de cohérence de programmation, les listes chaînées Linux fournissent toujours deux interfaces "_safe" correspondant aux opérations de traversée de base : list_for_each_safe(pos, n, head ), list_for_each_entry_safe(pos, n, head, member), ils nécessitent que l'appelant fournisse un autre pointeur n du même type que pos, et stocke temporairement l'adresse du nœud suivant de pos dans la boucle for pour éviter les erreurs causées par le libération du nœud pos. Chaîne cassée.
Liste et hlist de la figure 6
Le concepteur de listes chaînées Linux qui vise l'excellence (car list.h n'est pas signé, donc il s'agit probablement de Linus Torvalds) estime que la liste à double chaînage (suivant, précédent) est "trop de gaspillage" pour le HASH La structure de données hlist utilisée dans la table HASH est une liste chaînée double circulaire à en-tête à pointeur unique. Comme le montre la figure ci-dessus, l'en-tête hlist n'a qu'un pointeur vers le premier nœud et. pas de pointeur vers le nœud de queue. Cela peut être un problème majeur. L'en-tête stocké dans la table HASH peut réduire la consommation d'espace de moitié.
Les structures de données de l'en-tête et du nœud étant différentes, si l'opération d'insertion a lieu entre l'en-tête et le premier nœud, la méthode précédente ne fonctionnera pas : le premier pointeur de l'en-tête doit être modifié pour pointer vers le nœud nouvellement inséré , mais il ne peut pas être utilisé comme list_add() pour une description unifiée. Pour cette raison, le prev du nœud hlist n'est plus un pointeur vers le nœud précédent, mais un pointeur vers next (premier pour l'en-tête) dans le nœud précédent (éventuellement l'en-tête) (struct list_head **pprev), donc Le l'opération d'insertion en tête de table permet d'accéder et de modifier le pointeur suivant (ou premier) du nœud prédécesseur via le "*(node->pprev)" cohérent.
Il existe également une série de macros se terminant par "_rcu" dans l'interface des fonctions de liste chaînée Linux, qui correspondent à de nombreuses fonctions présentées ci-dessus. RCU (Read-Copy Update) est une nouvelle technologie introduite dans le noyau 2.5/2.6 qui améliore les performances de synchronisation en retardant les opérations d'écriture.
Nous savons qu'il y a beaucoup plus d'opérations de lecture de données que d'opérations d'écriture dans le système, et les performances du mécanisme rwlock diminueront rapidement à mesure que le nombre de processeurs augmente dans l'environnement SMP (voir référence 4). En réponse à ce contexte d'application, Paul E. McKenney du IBM Linux Technology Center a proposé la technologie "read copy update" et l'a appliquée au noyau Linux. Le cœur de la technologie RCU est que l'opération d'écriture est divisée en deux étapes : l'écriture et la mise à jour, ce qui permet un accès débloqué pour les opérations de lecture à tout moment. Lorsque le système effectue une opération d'écriture, l'action de mise à jour est retardée jusqu'à ce que toutes les opérations de lecture sur le système soient effectuées. les données sont complétées. La fonction RCU dans la liste chaînée Linux ne représente qu'une petite partie de Linux RCU. L'analyse de l'implémentation de RCU dépasse la portée de cet article. Les lecteurs intéressés peuvent se référer aux documents de référence de cet article et à l'utilisation de la liste chaînée RCU ; l'utilisation de la liste chaînée de base est fondamentalement la même.
Le programme dans la pièce jointe n'a aucun effet pratique, sauf qu'il peut générer des fichiers dans les sens avant et arrière. Il est uniquement utilisé pour démontrer l'utilisation des listes chaînées Linux.
Pour plus de simplicité, l'exemple utilise un modèle de programme en mode utilisateur. Si vous devez l'exécuter, vous pouvez utiliser la commande suivante pour le compiler :
gcc -D__KERNEL__ -I/usr/src/linux-2.6.7/include pfile.c -o pfile
因为内核链表限制在内核态使用,但实际上对于数据结构本身而言并非只能在核态运行,因此,在笔者的编译中使用”-D__KERNEL__”开关”欺骗”编译器。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!





























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



