Le modèle de langage visuel à grande échelle (LVLM) peut améliorer les performances en mettant à l'échelle le modèle. Cependant, augmenter la taille des paramètres augmente les coûts de formation et d'inférence car le calcul de chaque jeton active tous les paramètres du modèle.
Des chercheurs de l'Université de Pékin, de l'Université Sun Yat-sen et d'autres institutions ont proposé conjointement une nouvelle stratégie de formation appelée MoE-Tuning pour résoudre le problème de dégradation des performances lié à l'apprentissage multimodal et à la rareté des modèles. MoE-Tuning est capable de construire des modèles clairsemés avec un nombre surprenant de paramètres mais un coût de calcul constant. En outre, les chercheurs ont également proposé une nouvelle architecture LVLM clairsemée basée sur MoE, appelée framework MoE-LLaVA. Dans ce cadre, seuls les k meilleurs experts sont activés via l’algorithme de routage, et les experts restants restent inactifs. De cette manière, le cadre MoE-LLaVA peut utiliser plus efficacement les ressources du réseau d'experts pendant le processus de déploiement. Ces résultats de recherche fournissent de nouvelles solutions pour résoudre les défis de l’apprentissage multimodal et de la rareté des modèles LVLM.

Adresse papier : https://arxiv.org/abs/2401.15947
Adresse du projet : https://github.com/PKU-YuanGroup/MoE-LLaVA
Adresse de démonstration : https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
Titre de l'article : MoE-LLaVA : Mélange d'experts pour les modèles de langage à grande vision
MoE-LLaVA n'a que 3B de paramètres d'activation clairsemés, de performances Cependant, il est équivalent à LLaVA-1.5-7B sur divers ensembles de données de compréhension visuelle, et surpasse même LLaVA-1.5-13B dans le test de référence sur l'illusion d'objet. Grâce à MoE-LLaVA, cette étude vise à établir une référence pour les LVLM clairsemés et à fournir des informations précieuses pour les recherches futures visant à développer des systèmes d'apprentissage multimodaux plus efficaces et efficients. L’équipe MoE-LLaVA a rendu ouvertes toutes les données, codes et modèles.
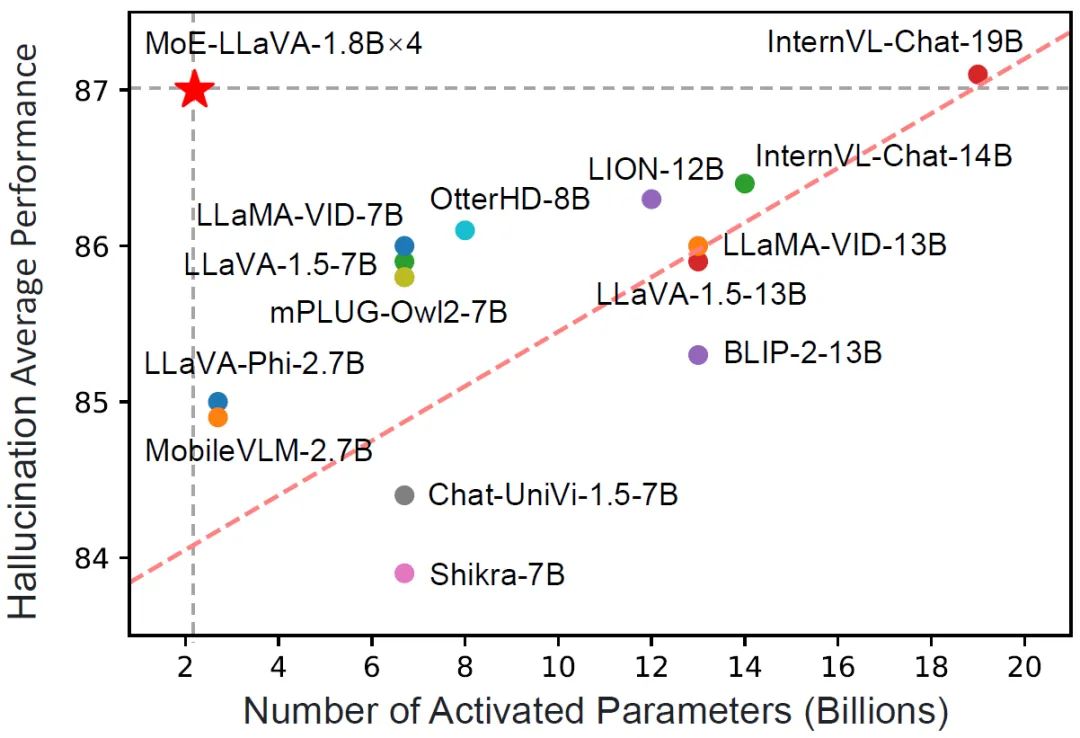
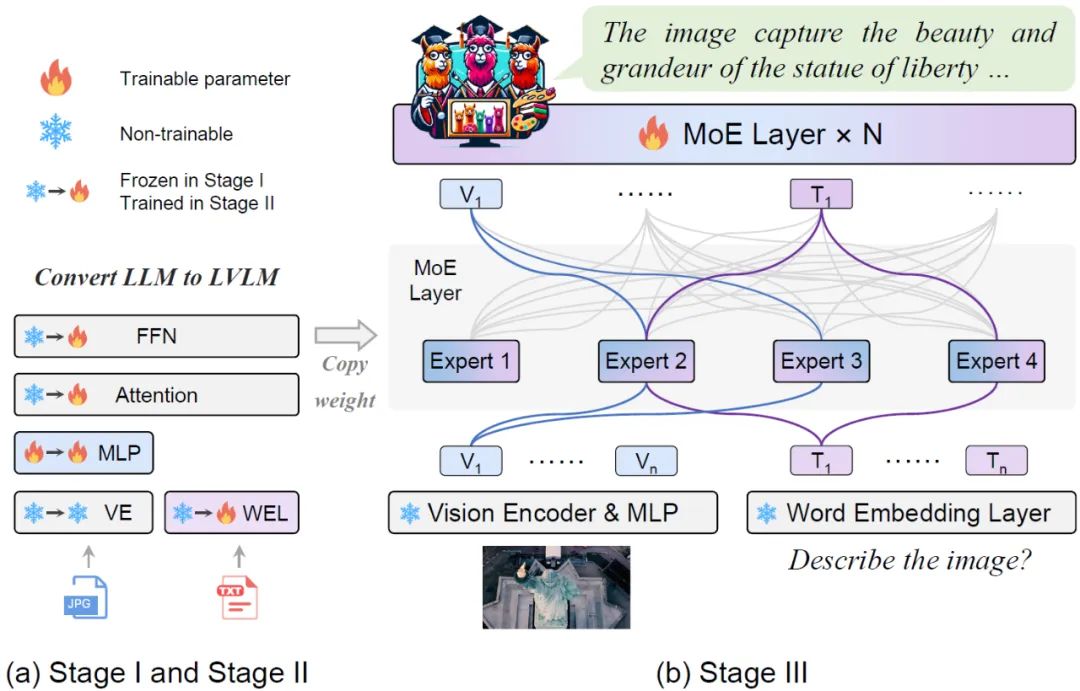
Figure 1 Comparaison du MoE-LLaVA et d'autres LVLM dans la performance des hallucinationsIntroduction à la méthodeMoE-LLaVA adopte une stratégie de formation par étapes. Comme le montre la figure 2, le codeur de vision traite l'image d'entrée pour obtenir la séquence de jetons visuels. Une couche de projection est utilisée pour mapper les jetons visuels dans des dimensions acceptables pour le LLM. De même, le texte associé à l'image est projeté à travers une couche d'incorporation de mots pour obtenir le jeton de texte de séquence.
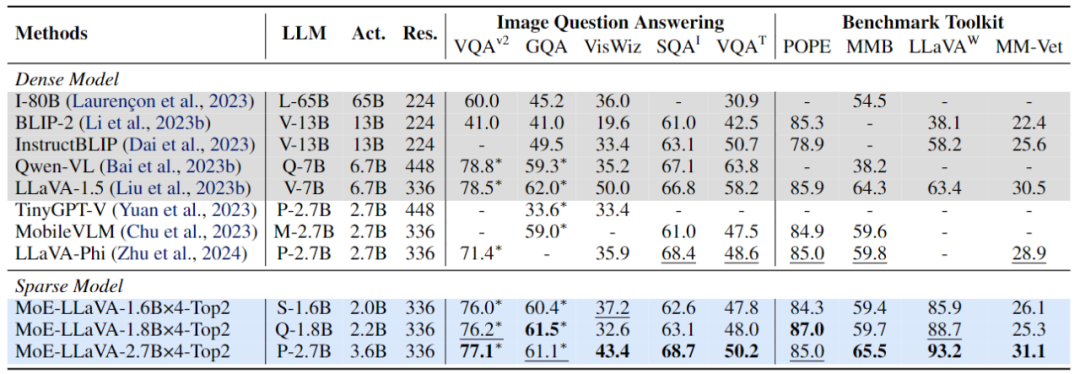
Phase 1 : Comme le montre la figure 2, l'objectif de la phase 1 est d'adapter le jeton visuel à LLM et de donner à LLM la capacité de comprendre les entités de l'image. MoE-LLaVA utilise un MLP pour projeter des jetons d'image dans le domaine d'entrée de LLM, ce qui signifie que les petits patchs d'image sont traités comme des jetons de pseudo-texte par LLM. À ce stade, LLM est formé pour décrire des images et comprendre la sémantique des images de niveau supérieur. La couche MoE ne sera pas appliquée au LVLM à ce stade. Figure 3 Cadre de formation et stratégie de formation plus spécifiquesPhase 2 : L'utilisation de données d'instructions multimodales pour affiner est une technologie clé pour améliorer la capacité et la contrôlabilité des grands modèles, et à ce stade LLM LVLM optimisé pour une compréhension multimodale. À ce stade, la recherche ajoute des instructions plus complexes, y compris des tâches avancées telles que le raisonnement logique d’images et la reconnaissance de texte, qui nécessitent que le modèle ait de plus fortes capacités de compréhension multimodale. De manière générale, le LVLM du modèle dense est formé à ce stade. Cependant, l'équipe de recherche a constaté qu'il est difficile de convertir le LLM en LVLM et de disperser le modèle en même temps. Par conséquent, le MoE-LLaVA utilisera les poids de la deuxième étape comme initialisation de la troisième étape pour réduire la difficulté de l'apprentissage de modèles clairsemés. Phase 3 : MoE-LLaVA copie plusieurs copies de FFN comme poids d'initialisation de l'ensemble expert. Lorsque les jetons visuels et les jetons de texte sont introduits dans la couche MoE, le routeur calculera le poids correspondant de chaque jeton et des experts, puis chaque jeton sera envoyé aux experts les plus correspondants pour traitement, et enfin en fonction du poids du routeur La somme pondérée est agrégée dans la sortie. Lorsque les experts top-k sont activés, les experts restants restent inactifs, et ce modèle constitue le MoE-LLaVA avec une infinité de voies clairsemées possibles. Comme le montre la figure 4, puisque MoE-LLaVA est le premier modèle clairsemé basé sur LVLM équipé d'un routeur logiciel, cette étude résume le modèle précédent comme un modèle dense. L’équipe de recherche a vérifié les performances du MoE-LLaVA sur 5 tests de questions et réponses d’images, et a signalé la quantité de paramètres activés et la résolution de l’image. Par rapport à la méthode SOTA LLaVA-1.5, MoE-LLaVA-2.7B×4 démontre de fortes capacités de compréhension d'images et ses performances sont très proches de LLaVA-1.5 sur 5 benchmarks. Parmi eux, MoE-LLaVA utilise 3,6 milliards de paramètres d'activation clairsemés et dépasse LLaVA-1,5-7B sur SQAI de 1,9 %. Il convient de noter qu’en raison de la structure clairsemée de MoE-LLaVA, seuls 2,6 B de paramètres d’activation sont nécessaires pour dépasser complètement IDEFICS-80B.
Figure 4 Performances de MoE-LLaVA sur 9 benchmarksDe plus, l'équipe de recherche a également prêté attention au récent petit modèle de langage visuel TinyGPT-V, MoE-LLaVA-1.8B × 4 dépasse TinyGPT-V de 27,5 % et 10 % respectivement dans GQA et VisWiz avec des paramètres d'activation comparables, ce qui marque la puissante capacité de compréhension du MoE-LLaVA en vision naturelle. Afin de vérifier de manière plus complète les capacités de compréhension multimodale du MoE-LLaVA, cette étude a évalué les performances du modèle sur 4 boîtes à outils de référence. La boîte à outils de référence est une boîte à outils permettant de vérifier si le modèle peut répondre aux questions en langage naturel. Généralement, les réponses sont ouvertes et n'ont pas de modèle fixe. Comme le montre la figure 4, MoE-LLaVA-1,8B × 4 surpasse Qwen-VL, qui utilise une résolution d'image plus grande. Ces résultats montrent que MoE-LLaVA, un modèle clairsemé, peut atteindre des performances comparables, voire supérieures, à celles des modèles denses avec moins de paramètres d'activation.
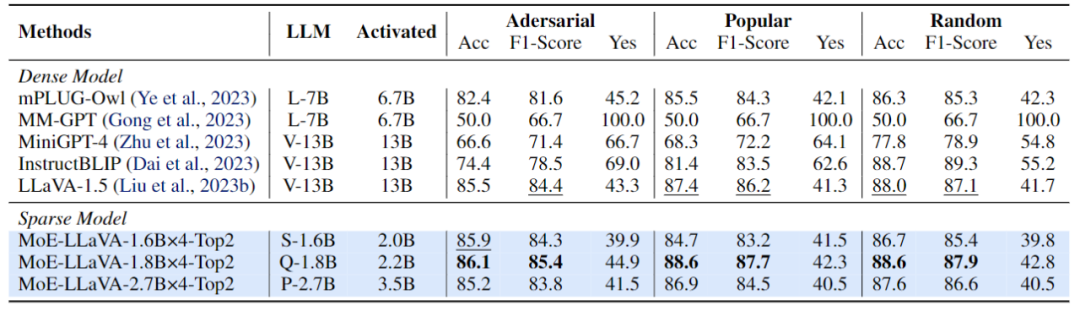
Figure 5 Évaluation des performances de MoE-LLaVA sur la détection d'objets hallucinésCette étude utilise le pipeline d'évaluation POPE pour vérifier l'hallucination d'objets de MoE-LLaVA. Les résultats sont présentés dans la figure 5. . MoE -LLaVA présente les meilleures performances, ce qui signifie que MoE-LLaVA a tendance à générer des objets cohérents avec l'image donnée. Plus précisément, MoE-LLaVA-1,8B × 4 a surpassé LLaVA avec un paramètre d'activation de 2,2B. De plus, l’équipe de recherche a observé que le rapport oui de MoE-LLaVA est dans un état relativement équilibré, ce qui montre que le modèle clairsemé MoE-LLaVA peut effectuer une rétroaction correcte en fonction du problème.
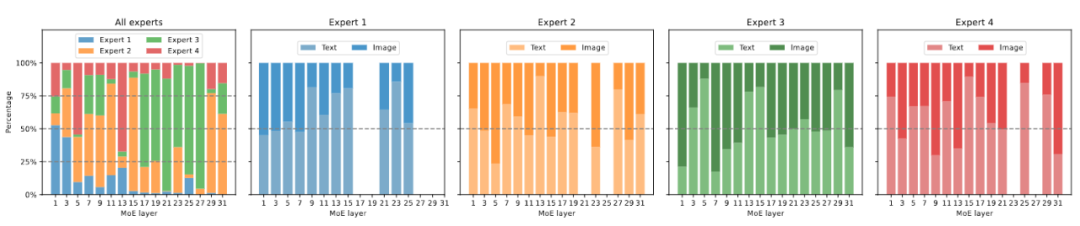
Figure 6 Visualisation de la charge experte La figure 6 montre la charge experte de MoE-LLaVA-2.7B×4-Top2 sur ScienceQA. Dans l’ensemble, lors de l’initialisation de la formation, la charge d’experts dans tous les niveaux du MoE est relativement équilibrée. Cependant, à mesure que le modèle se raréfie progressivement, la charge d'experts sur les couches 17 à 27 augmente soudainement, et couvre même presque tous les jetons. Pour les couches peu profondes 5 à 11, les experts 2, 3 et 4 travaillent principalement ensemble. Il convient de noter qu'Expert 1 fonctionne presque exclusivement sur les couches 1 à 3 et abandonne progressivement le travail à mesure que le modèle s'approfondit. Par conséquent, les experts du MoE-LLaVA ont appris un modèle spécifique qui permet une division experte du travail selon certaines règles.
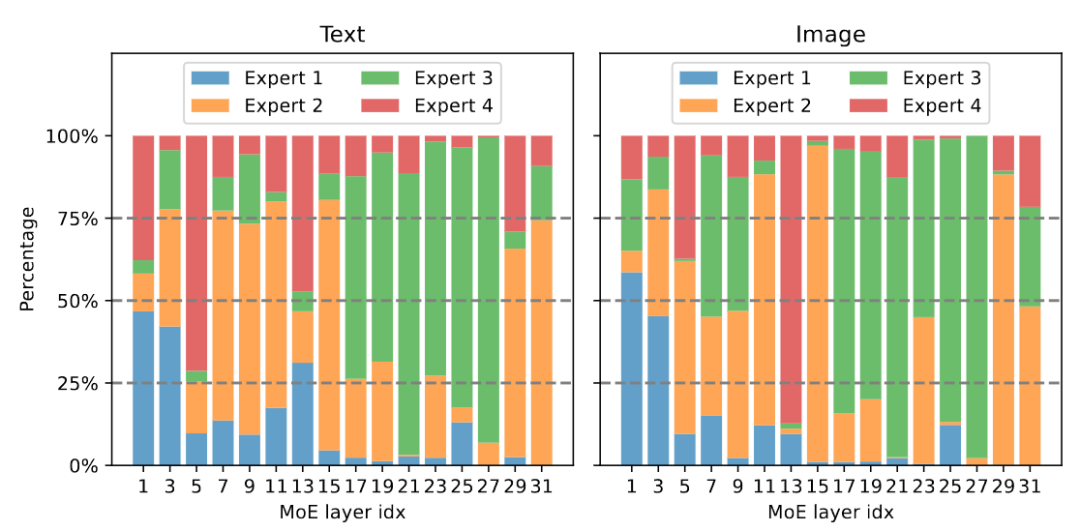
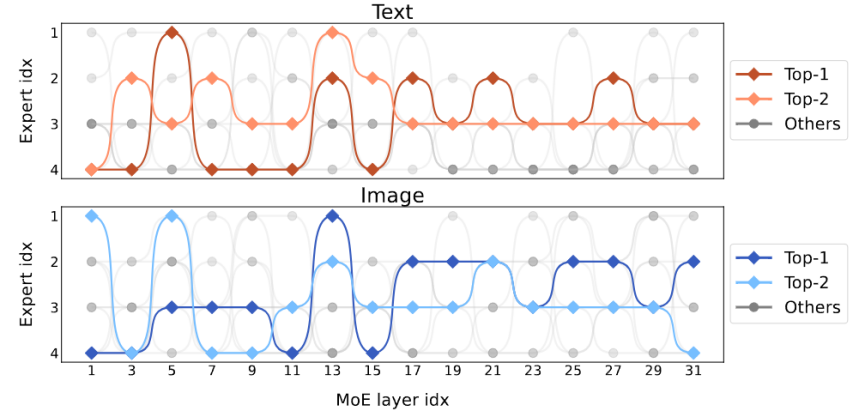
Figure 7 Visualisation de la distribution modale La figure 7 montre la distribution modale de différents experts. L'étude a révélé que la répartition du routage du texte et de l'image est très similaire. Par exemple, lorsque l'expert 3 travaille dur sur les couches 17 à 27, la proportion de texte et d'image qu'il traite est similaire. Cela montre que le MoE-LLaVA n’a pas de préférence évidente en matière de modalité. L'étude a également observé le comportement des experts au niveau des jetons et a suivi la trajectoire de tous les jetons du réseau clairsemé sur les tâches en aval. Pour toutes les voies activées de texte et d'image, cette étude a utilisé la réduction de dimensionnalité PCA pour obtenir les 10 voies principales, comme le montre la figure 8. L'équipe de recherche a découvert que pour un jeton de texte ou un jeton d'image invisible, le MoE-LLaVA préfère toujours envoyer des experts 2 et 3 pour gérer la profondeur du modèle. Les experts 1 et 4 ont tendance à traiter des jetons initialisés. Ces résultats peuvent nous aider à mieux comprendre le comportement des modèles clairsemés dans l'apprentissage multimodal et à explorer des possibilités inconnues.
Figure 8 Visualisation de la voie d'activationCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 Comment gérer les caractères chinois tronqués sous Linux
Comment gérer les caractères chinois tronqués sous Linux
 Ordre recommandé pour apprendre le langage C++ et C
Ordre recommandé pour apprendre le langage C++ et C
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP
 Méthode de réparation des doutes sur la base de données
Méthode de réparation des doutes sur la base de données
 Solution de délai d'expiration des requêtes du serveur
Solution de délai d'expiration des requêtes du serveur
 Solution d'erreur inattendue IIS 0x8ffe2740
Solution d'erreur inattendue IIS 0x8ffe2740
 navigateur.useragent
navigateur.useragent
 Comment obtenir un jeton
Comment obtenir un jeton








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



