


Grand modèle Eagle7B sans attention : basé sur RWKV, le coût d'inférence est réduit de 10 à 100 fois
Dans le domaine de l'IA, les petits modèles ont récemment attiré beaucoup d'attention, par rapport aux modèles avec des centaines de milliards de paramètres. Par exemple, le modèle Mistral-7B publié par la startup française d'IA a surpassé Llama 2 de 13B dans chaque benchmark, et a surpassé Llama 1 de 34B en code, mathématiques et inférence.
Par rapport aux grands modèles, les petits modèles présentent de nombreux avantages, tels que de faibles besoins en puissance de calcul et la possibilité de fonctionner côté appareil.
Récemment, un nouveau modèle de langage est apparu, à savoir le paramètre 7.52B Eagle 7B, de l'organisation open source à but non lucratif RWKV, qui présente les caractéristiques suivantes :


Eagle 7B est construit sur la base de l'architecture RWKV-v5. RWKV (Receptance Weighted Key Value) est une nouvelle architecture qui combine les avantages de RNN et Transformer et évite leurs défauts. Il est très bien conçu et peut atténuer les goulots d'étranglement de mémoire et d'extension de Transformer et obtenir une expansion linéaire plus efficace. Dans le même temps, RWKV conserve également certaines des propriétés qui ont rendu Transformer dominant dans le domaine.
Actuellement, le RWKV a été itéré jusqu'à la sixième génération du RWKV-6, avec des performances et une taille similaires à celles du Transformer. Les futurs chercheurs pourront utiliser cette architecture pour créer des modèles plus efficaces.
Pour plus d'informations sur RWKV, vous pouvez vous référer à "Reshaping RNN in the Transformer era, RWKV étend l'architecture non-Transformer à des dizaines de milliards de paramètres".
Il convient de mentionner que le RWKV-v5 Eagle 7B peut être utilisé à des fins personnelles ou commerciales sans restrictions.
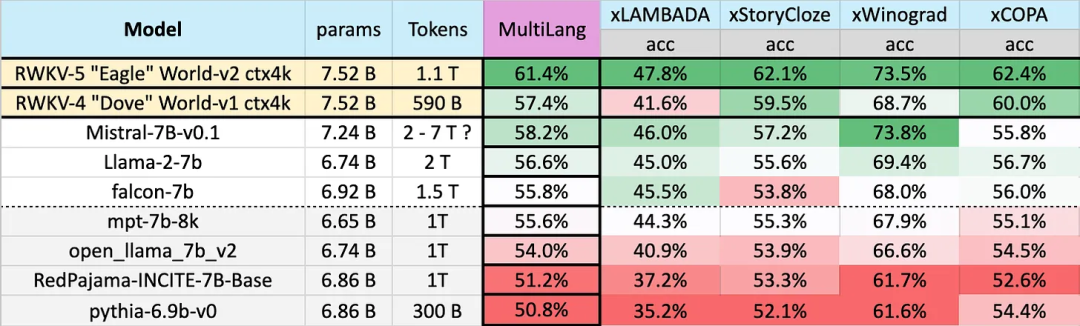
Résultats des tests sur 23 langues
Les performances des différents modèles sur plusieurs langues sont les suivantes. Les tests de référence incluent xLAMBDA, xStoryCloze, xWinograd, xCopa.
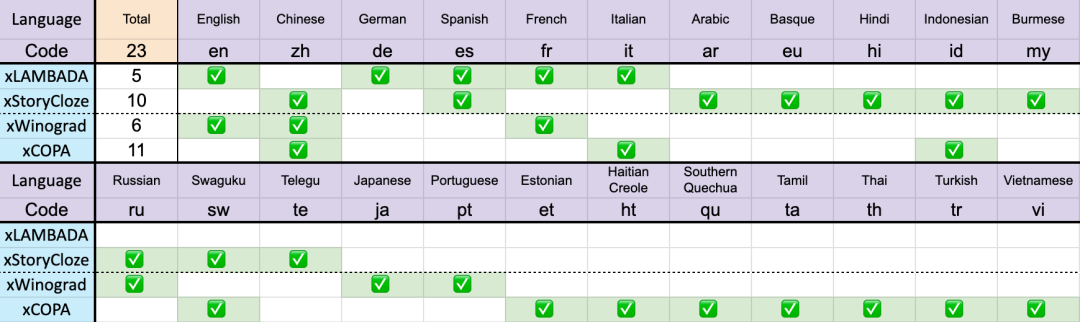
23 langues au total
Ces benchmarks incluent la plupart des raisonnements de bon sens, montrant l'énorme bond en avant dans les performances multilingues de l'architecture RWKV à partir de la v4 à la v5. Cependant, en raison du manque de références multilingues, l'étude ne peut tester ses capacités que dans 23 langues les plus couramment utilisées, et la capacité dans les 75 langues restantes ou plus est encore inconnue.
Performance en anglais
La performance de différents modèles en anglais est jugée à travers 12 critères, y compris le raisonnement de bon sens et la connaissance du monde.

D’après les résultats, nous pouvons une fois de plus constater l’énorme saut de RWKV de l’architecture v4 à l’architecture v5. La v4 a déjà perdu face au jeton 1T MPT-7b, mais la v5 a commencé à rattraper son retard dans les tests de référence, et dans certains cas (même dans certains tests de référence LAMBADA, StoryCloze16, WinoGrande, HeadQA_en, Sciq), elle peut surpasser Falcon, ou même lama2. .
De plus, les performances de la v5 commencent à s'aligner sur les niveaux de performances attendus de Transformer compte tenu des statistiques approximatives de formation des jetons.
Auparavant, Mistral-7B utilisait une méthode d'entraînement de 2 à 7 billions de jetons pour maintenir son avance dans le modèle à l'échelle 7B. L'étude espère combler cet écart afin que le RWKV-v5 Eagle 7B dépasse les performances du lama2 et atteigne le niveau du Mistral.
La figure ci-dessous montre que les points de contrôle du RWKV-v5 Eagle 7B proches de 300 milliards de points de jeton affichent des performances similaires à celles du pythia-6.9b :
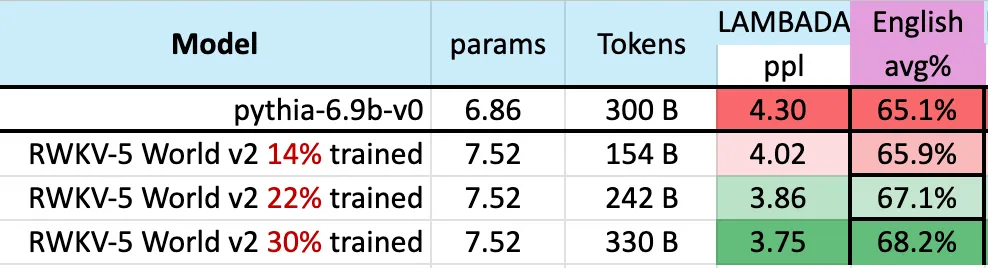
Cela est cohérent avec les travaux précédents sur l'architecture expérimentale du RWKV-v4 ( basé sur des piles) est que les transformateurs linéaires comme le RWKV ont un niveau de performance similaire à celui des transformateurs et sont formés avec le même nombre de jetons.
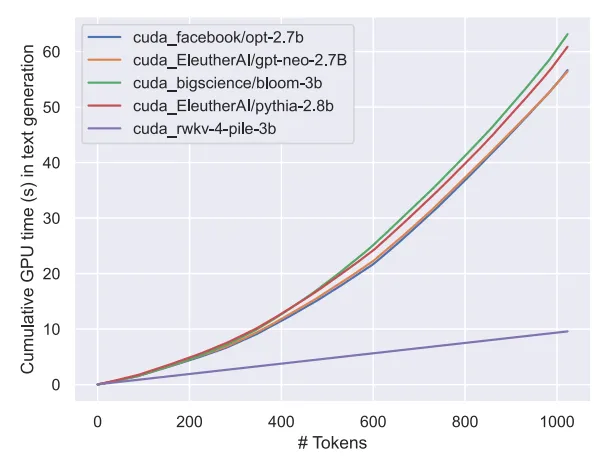
Comme on pouvait s'y attendre, l'émergence de ce modèle marque l'arrivée du transformateur linéaire le plus puissant (en termes de critères d'évaluation) à ce jour.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Quels sont les outils d'analyse des données ?
Quels sont les outils d'analyse des données ?
 qu'est-ce que jpa
qu'est-ce que jpa
 Comment utiliser l'étiquette htmllabel
Comment utiliser l'étiquette htmllabel
 Le rôle de la fonction mathématique en langage C
Le rôle de la fonction mathématique en langage C
 Quelle devise est le BTC ?
Quelle devise est le BTC ?
 Comment redémarrer le service dans le framework swoole
Comment redémarrer le service dans le framework swoole
 Outils Flash recommandés
Outils Flash recommandés








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



