


À mesure que les grands modèles multimodaux (LMM) continuent de progresser, le besoin d'évaluer les performances des LMM augmente également. Surtout dans l’environnement chinois, il devient plus important d’évaluer les connaissances avancées et la capacité de raisonnement du LMM.
Dans ce contexte, afin d'évaluer les capacités de compréhension multimodale de niveau expert du modèle de base dans diverses tâches en chinois, la communauté open source M-A-P, l'Université des sciences et technologies de Hong Kong, l'Université de Waterloo et Zero One Thing a lancé conjointement le benchmark CMMMU (Chinese Massive Multi -discipline Multimodal Understanding and Reasoning). Ce benchmark vise à fournir une plateforme d'évaluation complète pour la compréhension et le raisonnement multidisciplinaires et multimodaux à grande échelle en chinois. Le benchmark permet aux chercheurs de tester des modèles sur diverses tâches et de comparer leurs capacités de compréhension multimodale aux niveaux professionnels. L'objectif de ce projet commun est de promouvoir le développement du domaine de la compréhension et du raisonnement multimodal chinois et de fournir une référence standardisée pour la recherche connexe.
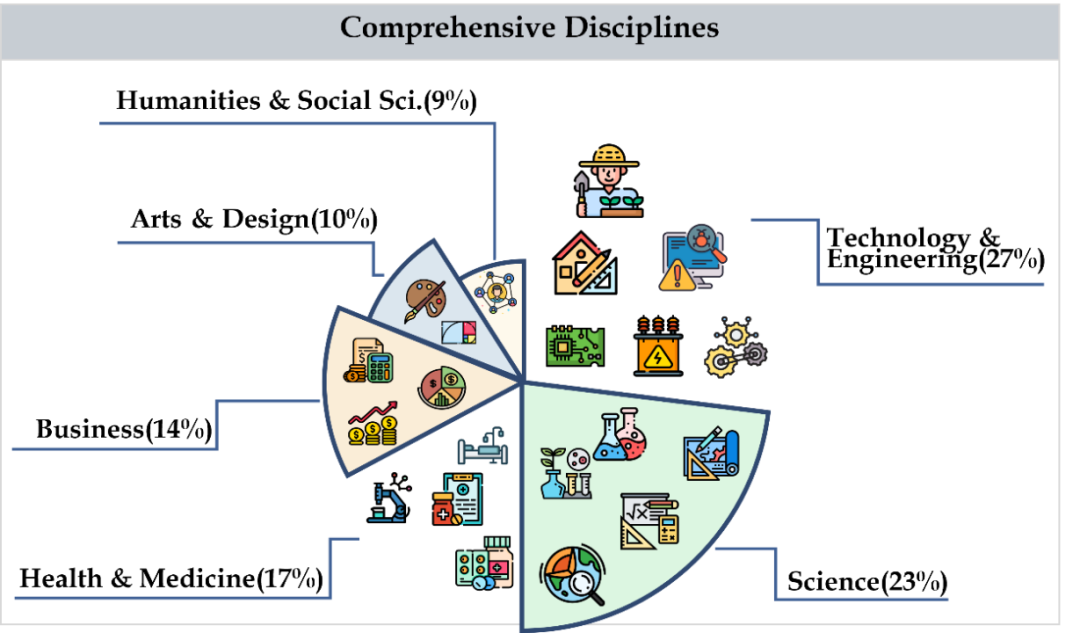
CMMMU couvre six grandes catégories de matières, dont les arts, les affaires, la santé et la médecine, les sciences, les sciences humaines et sociales, la technologie et l'ingénierie, impliquant plus de 30 subdivisions. La figure ci-dessous montre un exemple de question pour chaque sous-domaine. CMMMU est l'un des premiers benchmarks multimodaux dans le contexte chinois et l'un des rares benchmarks multimodaux à examiner les capacités complexes de compréhension et de raisonnement du LMM.

Collecte de données
La collecte de données est divisée en trois étapes. Premièrement, les chercheurs ont collecté des sources de questions pour chaque sujet répondant aux exigences de licence en matière de droit d'auteur, y compris les pages Web ou les livres. Au cours de ce processus, ils ont travaillé dur pour éviter la duplication des sources de questions afin de garantir la diversité et l'exactitude des données. Deuxièmement, les chercheurs ont transmis les sources des questions à des annotateurs participatifs pour une annotation ultérieure. Tous les annotateurs sont des personnes titulaires d'un baccalauréat ou d'un diplôme supérieur afin de garantir qu'ils peuvent vérifier les questions annotées et les explications associées. Pendant le processus d'annotation, les chercheurs exigent que les annotateurs suivent strictement les principes d'annotation. Par exemple, filtrez les questions qui ne nécessitent pas de réponses avec des images, filtrez les questions qui utilisent les mêmes images autant que possible et filtrez les questions qui ne nécessitent pas de connaissances spécialisées pour répondre. Enfin, afin d'équilibrer le nombre de questions pour chaque sujet de l'ensemble de données, les chercheurs ont spécifiquement complété les sujets avec moins de questions. Cela garantit l’exhaustivité et la représentativité de l’ensemble de données, permettant aux analyses et recherches ultérieures d’être plus précises et plus complètes.
Nettoyage des ensembles de données
Afin d'améliorer encore la qualité des données du CMMMU, les chercheurs suivent des protocoles stricts de contrôle de la qualité des données. Premièrement, chaque question est vérifiée personnellement par au moins un des auteurs de l'article. Deuxièmement, afin d'éviter les problèmes de pollution des données, ils ont également éliminé les questions auxquelles plusieurs LLM pouvaient répondre sans recourir à la technologie OCR. Ces mesures garantissent la fiabilité et l’exactitude des données de la CMMMU.
Aperçu de l'ensemble de données
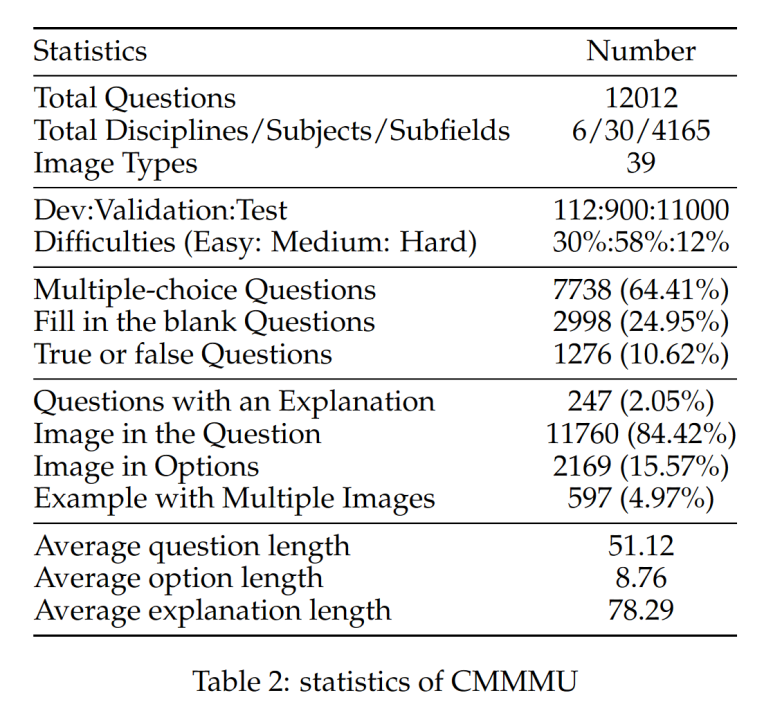
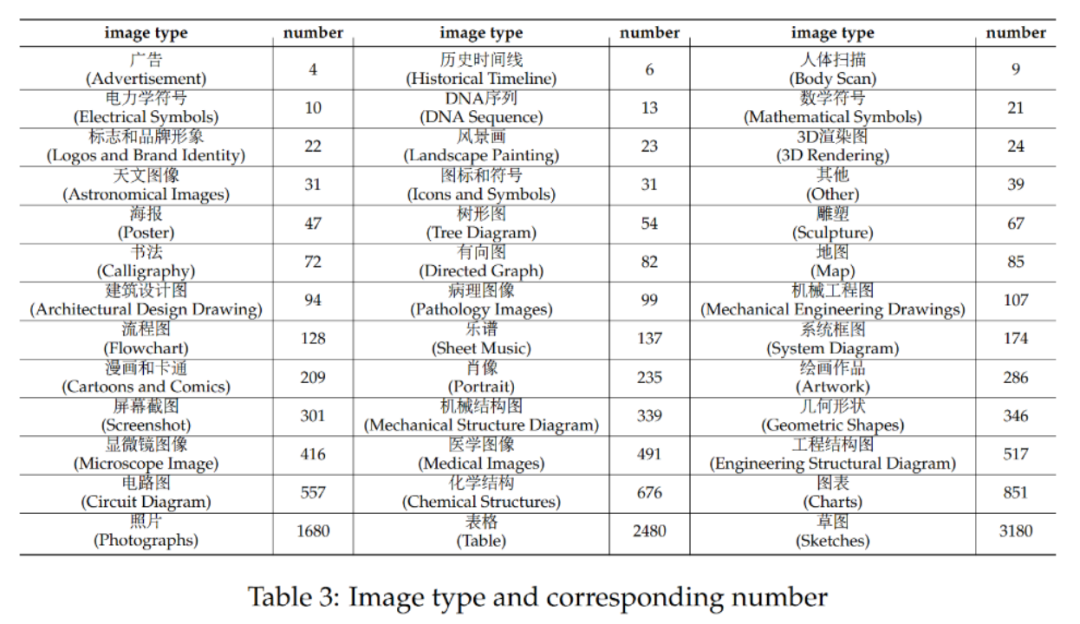
CMMMU contient un total de 12 000 questions, qui sont divisées en un ensemble de développement de quelques échantillons, un ensemble de vérification et un ensemble de test. L'ensemble de développement à quelques échantillons contient environ 5 questions pour chaque sujet, l'ensemble de validation comprend 900 questions et l'ensemble de test contient 11 000 questions. Les questions couvrent 39 types d'images, dont des diagrammes pathologiques, des diagrammes de notation musicale, des schémas de circuits, des diagrammes de structure chimique, etc. Les questions sont divisées en trois niveaux de difficulté : facile (30 %), moyen (58 %) et difficile (12 %) basés sur la difficulté logique plutôt que sur la difficulté intellectuelle. D’autres statistiques sur les questions peuvent être trouvées dans les tableaux 2 et 3. L’équipe a testé les performances d’une variété de LMM bilingues chinois et anglais traditionnels et de plusieurs LLM sur CMMMU. Les modèles fermés et open source sont inclus. Le processus d'évaluation utilise des paramètres zéro-shot au lieu de réglages fins ou de quelques-shots pour vérifier les capacités brutes du modèle. LLM a également ajouté des expériences dans lesquelles les résultats de l'OCR d'image + le texte sont utilisés comme entrée. Toutes les expériences ont été réalisées sur un processeur graphique NVIDIA A100.
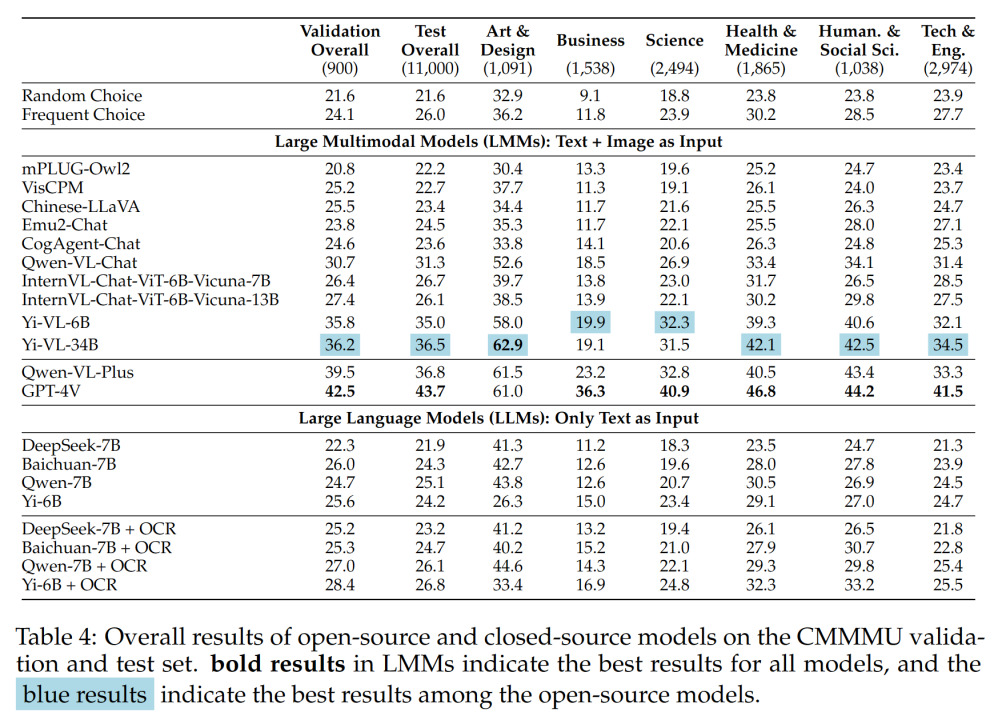
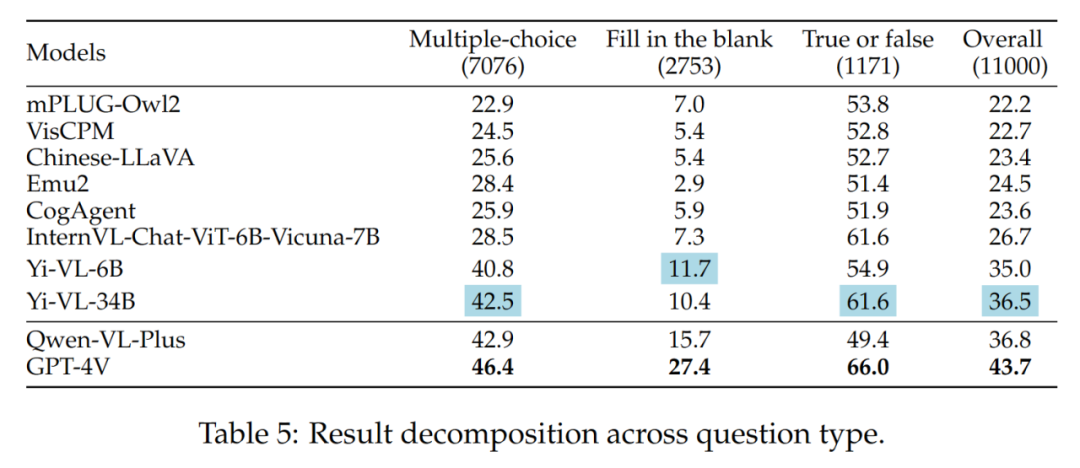
 Le tableau 4 présente les résultats expérimentaux :
Le tableau 4 présente les résultats expérimentaux :
Certaines conclusions importantes incluent :
- CMMMU est plus difficile que MMMU, et cela part du principe que MMMU est déjà très difficile. La précision du
GPT-4V dans le contexte chinois n'est que de 41,7 %, tandis que sa précision dans le contexte anglais est de 55,7 %. Cela montre que les méthodes de généralisation multilingue existantes ne sont pas assez performantes, même pour les LMM à source fermée de pointe.
- Par rapport au MMMU, l'écart entre les modèles open source représentatifs nationaux et le GPT-4V est relativement faible.
La différence entre Qwen-VL-Chat et GPT-4V sur MMMU est de 13,3%, tandis que la différence entre BLIP2-FLAN-T5-XXL et GPT-4V sur MMMU est de 21,9%. Étonnamment, Yi-VL-34B réduit même l'écart entre le LMM bilingue open source et le GPT-4V sur CMMMU à 7,5 %, ce qui signifie que dans l'environnement chinois, le LMM bilingue open source est équivalent au GPT-4V, ce qui est est un développement prometteur dans la communauté open source.
- Dans la communauté open source, la partie à la recherche de l'intelligence générale artificielle (AGI) multimodale experte chinoise vient de commencer. L'équipe
a souligné que, à l'exception des Qwen-VL-Chat, Yi-VL-6B et Yi-VL-34B récemment publiés, tous les LMM bilingues de la communauté open source ne peuvent atteindre qu'une précision comparable à celle des fréquents CMMMU. choix.
Analyse de différentes difficultés de questions et types de questions
- Différents types de questions
Les différences entre les séries Yi-VL, Qwen-VL-Plus et GPT-4V sont principalement dues à Ils diffèrent par leur capacité à répondre à des questions à choix multiples.
Les résultats des différents types de questions sont présentés dans le tableau 5 :
- Différentes difficultés de questions
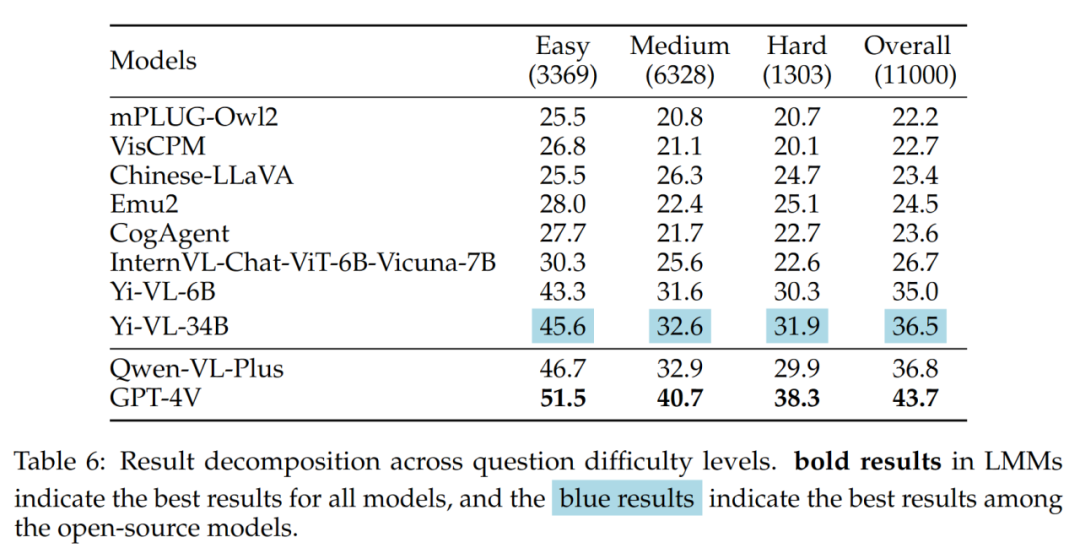
Ce qu'il convient de noter dans les résultats, c'est que le meilleur LMM open source (c'est-à-dire Yi -VL- 34B) et GPT-4V ont un grand écart face à des problèmes moyens et difficiles. Cela constitue une preuve supplémentaire que la principale différence entre les LMM open source et le GPT-4V réside dans la capacité à calculer et à raisonner dans des conditions complexes.
Les résultats des différentes difficultés des questions sont présentés dans le tableau 6 :
Analyse des erreurs
Les chercheurs ont soigneusement analysé les mauvaises réponses du GPT-4V. Comme le montre la figure ci-dessous, les principaux types d’erreurs sont les erreurs de perception, le manque de connaissances, les erreurs de raisonnement, le refus de répondre et les erreurs d’annotation. L'analyse de ces types d'erreurs est essentielle pour comprendre les capacités et les limites des LMM actuels et peut également guider les futures améliorations des modèles de conception et de formation.
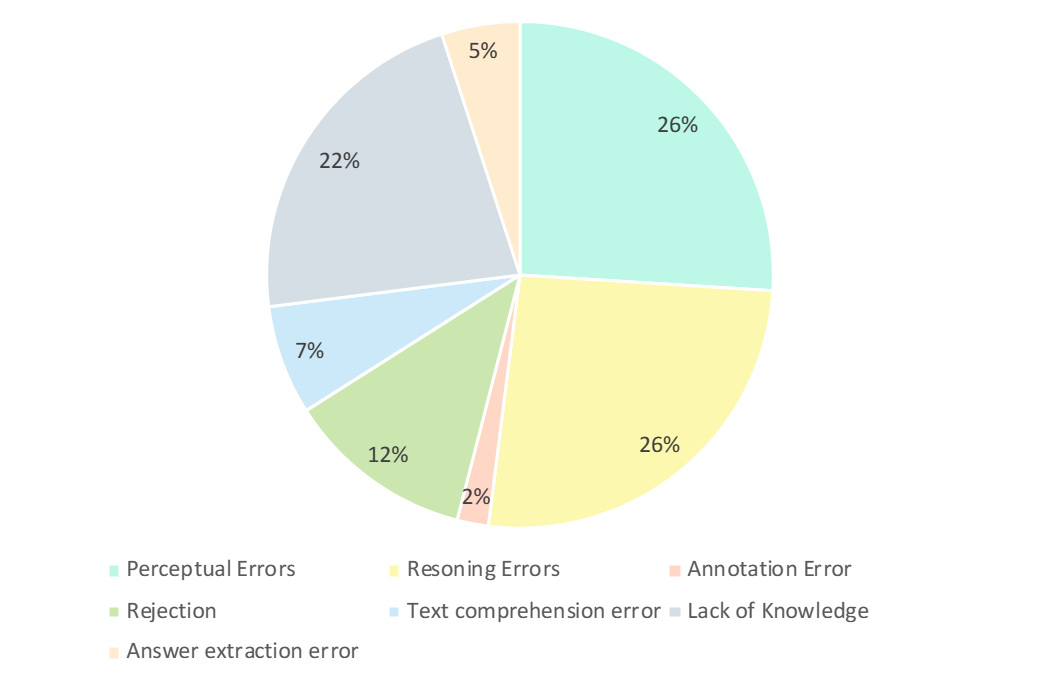
- Erreur de perception (26%) : L'erreur de perception est l'une des principales raisons pour lesquelles GPT-4V produit des exemples incorrects. D’une part, lorsque le modèle ne peut pas comprendre l’image, il introduit un biais dans la perception sous-jacente de l’image, conduisant à des réponses incorrectes. D’un autre côté, lorsqu’un modèle rencontre des ambiguïtés dans les connaissances spécifiques à un domaine, des significations implicites ou des formules peu claires, il présente souvent des erreurs de perception spécifiques à un domaine. Dans ce cas, GPT-4V a tendance à s'appuyer davantage sur des réponses basées sur des informations textuelles (c'est-à-dire des questions et des options), donnant la priorité aux informations textuelles par rapport à la saisie visuelle, ce qui entraîne un biais dans la compréhension des données multimodales.
- Erreurs d'inférence (26%) : Les erreurs d'inférence sont un autre facteur majeur dans la production d'exemples erronés par GPT-4V. Même lorsque les modèles perçoivent correctement le sens véhiculé par les images et le texte, des erreurs peuvent toujours survenir lors du raisonnement lors de la résolution de problèmes nécessitant un raisonnement logique et mathématique complexe. Généralement, cette erreur est causée par les faibles capacités de raisonnement logique et mathématique du modèle.
- Manque de connaissances (22%) : Le manque d'expertise est également l'une des raisons des réponses incorrectes au GPT-4V. Étant donné que CMMMU est une référence pour évaluer l’AGI expert LMM, des connaissances de niveau expert dans différentes disciplines et sous-domaines sont requises. Par conséquent, l’injection de connaissances de niveau expert dans LMM est également l’une des directions sur lesquelles travailler.
- Refus de répondre (12%) : C'est aussi un phénomène courant que les mannequins refusent de répondre. Grâce à l'analyse, ils ont souligné plusieurs raisons pour lesquelles le modèle a refusé de répondre à la question : (1) Le modèle n'a pas réussi à percevoir les informations de l'image (2) Il s'agissait d'une question impliquant des questions religieuses ou des informations personnelles réelles, et le modèle ; l'éviterait activement ; (3) Lorsque les questions impliquent le genre et des facteurs subjectifs, le modèle évite de fournir des réponses directes.
- Ses erreurs : Les erreurs restantes incluent des erreurs de compréhension de texte (7%), des erreurs d'annotation (2%) et des erreurs d'extraction de réponses (5%). Ces erreurs sont causées par divers facteurs tels que des capacités de suivi de structure complexes, une compréhension complexe de la logique du texte, des limitations dans la génération de réponses, des erreurs dans l'annotation des données et des problèmes rencontrés lors de l'extraction de correspondance de réponses.
Le benchmark CMMMU marque des progrès significatifs dans le développement de l'intelligence artificielle générale avancée (AGI). CMMMU est conçu pour évaluer rigoureusement les derniers grands modèles multimodaux (LMM) et tester les compétences perceptuelles de base, le raisonnement logique complexe et une expertise approfondie dans un domaine spécifique. Cette étude a mis en évidence les différences en comparant la capacité de raisonnement des LMM dans des contextes bilingues chinois et anglais. Cette évaluation détaillée est essentielle pour déterminer dans quelle mesure le modèle se compare aux compétences de professionnels expérimentés dans chaque domaine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Les huit fonctions les plus couramment utilisées dans Excel
Les huit fonctions les plus couramment utilisées dans Excel
 Méthodes de défense contre les attaques du serveur
Méthodes de défense contre les attaques du serveur
 Quelles sont les méthodes permettant à Docker d'entrer dans le conteneur ?
Quelles sont les méthodes permettant à Docker d'entrer dans le conteneur ?
 logiciel erp gratuit
logiciel erp gratuit
 rayon de frontière
rayon de frontière
 La différence entre le lecteur C et le lecteur D
La différence entre le lecteur C et le lecteur D
 Comment ralentir la vidéo sur Douyin
Comment ralentir la vidéo sur Douyin








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



