


En 2023, le statut de Transformer, acteur dominant dans le domaine des grands modèles d'IA, commencera à être remis en cause. Une nouvelle architecture appelée « Mamba » est apparue. Il s'agit d'un modèle d'espace d'état sélectif qui est comparable à Transformer en termes de modélisation du langage, et pourrait même le surpasser. Dans le même temps, Mamba peut atteindre une mise à l'échelle linéaire à mesure que la longueur du contexte augmente, ce qui lui permet de gérer des séquences d'un million de mots et d'améliorer de 5 fois le débit d'inférence lors du traitement de données réelles. Cette amélioration révolutionnaire des performances est accrocheuse et apporte de nouvelles possibilités au développement du domaine de l'IA.
Plus d'un mois après sa sortie, Mamba a commencé à montrer progressivement son influence et a donné naissance à de nombreux projets tels que MoE-Mamba, Vision Mamba, VMamba, U-Mamba, MambaByte, etc. Mamba a montré un grand potentiel en surmontant continuellement les lacunes de Transformer. Ces développements démontrent le développement et les progrès continus de Mamba, ouvrant de nouvelles possibilités dans le domaine de l’intelligence artificielle.
Cependant, cette « étoile » montante a rencontré un revers lors de la réunion ICLR 2024. Les derniers résultats publics montrent que l’article de Mamba est toujours en attente. Nous ne pouvons voir que son nom dans la colonne des décisions en attente, et nous ne pouvons pas déterminer s’il a été retardé ou rejeté.

Dans l'ensemble, Mamba a reçu des notes de quatre évaluateurs, qui étaient respectivement de 8/8/6/3. Certaines personnes ont dit qu'il était vraiment déroutant d'être encore rejeté après avoir reçu une telle note.

Pour comprendre la raison, nous devons regarder ce que disent les évaluateurs qui ont donné des notes faibles.
Page de révision de l'article : https://openreview.net/forum?id=AL1fq05o7H
Dans les commentaires de l'évaluation, l'évaluateur qui a donné une note de « 3 : rejeté, pas assez bon » a expliqué plusieurs opinions sur Mamba :
Réflexions sur la conception du modèle :
Réflexions sur l'expérience :
De plus, un autre critique a également souligné une lacune de Mamba : le modèle a encore des besoins en mémoire secondaire lors de l'entraînement comme Transformers.
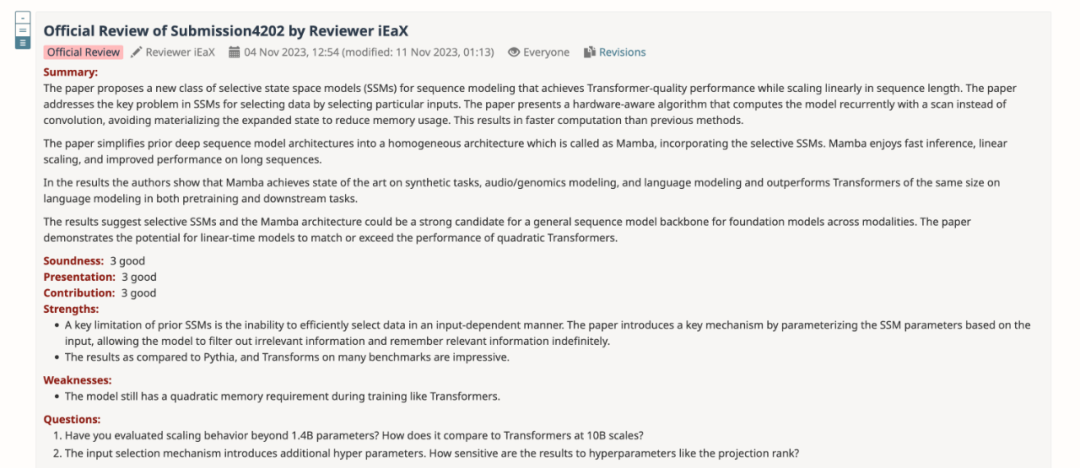
Après avoir résumé les opinions de tous les évaluateurs, l'équipe d'auteurs a également révisé et amélioré le contenu de l'article et ajouté de nouveaux résultats expérimentaux et analyses :
L'auteur a téléchargé le modèle H3 pré-entraîné d'une taille de paramètres 125M-2,7B et a mené une série d'évaluations. Mamba est nettement meilleur dans toutes les évaluations de langage. Il convient de noter que ces modèles H3 sont des modèles hybrides utilisant une attention quadratique, tandis que le modèle pur de l'auteur utilisant uniquement la couche Mamba en temps linéaire est nettement meilleur dans tous les indicateurs.
La comparaison d'évaluation avec le modèle H3 pré-entraîné est la suivante :
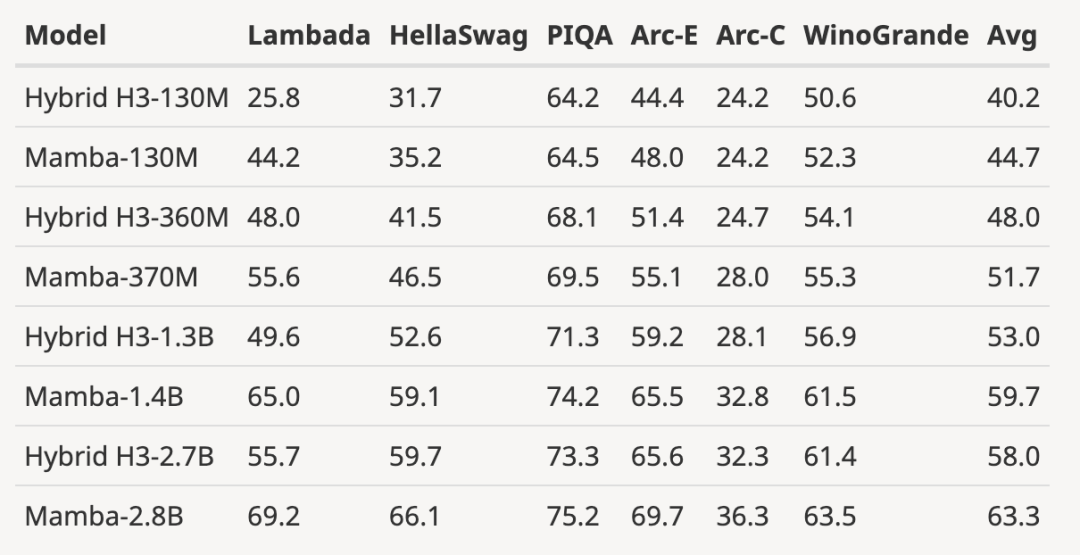
comme indiqué dans la figure ci-dessous , comparé à Par rapport au modèle open source 3B formé avec le même nombre de jetons (300B), Mamba est supérieur dans chaque résultat d'évaluation. Il est même comparable aux modèles à l'échelle 7B : en comparant Mamba (2,8B) avec OPT, Pythia et RWKV (7B), Mamba obtient le meilleur score moyen et le meilleur/deuxième meilleur sur chaque score de référence.
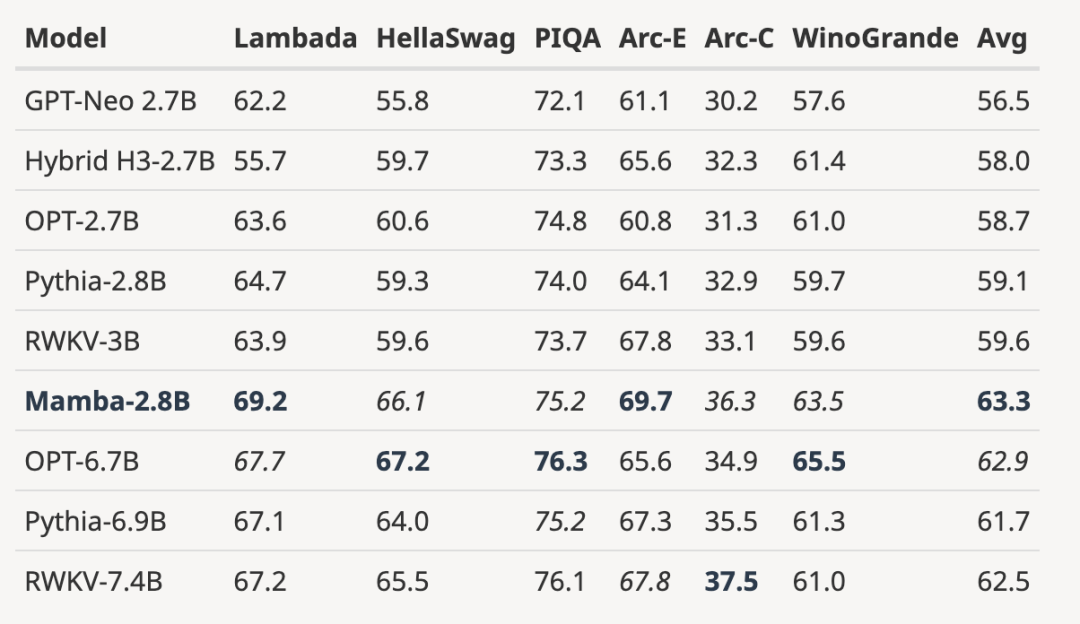
L'auteur a joint une figure évaluant l'extrapolation de longueur du modèle de langage paramétrique 3B pré-entraîné :
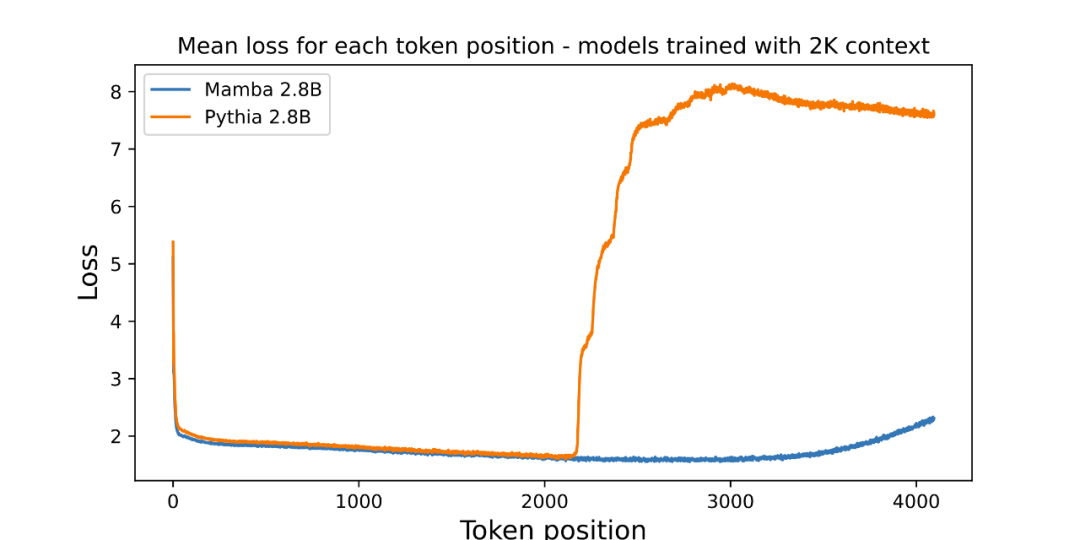
Le graphique trace la perte moyenne par position (lisibilité du journal). La perplexité du premier jeton est élevée car il n'a pas de contexte, tandis que la perplexité de Mamba et du Transformer de base (Pythia) augmente avant la longueur du contexte d'entraînement (2048). Il est intéressant de noter que la solvabilité de Mamba s'améliore considérablement au-delà de son contexte d'entraînement, jusqu'à une durée d'environ 3 000.
L'auteur souligne que l'extrapolation de longueur n'est pas la motivation directe du modèle dans cet article, mais la traite comme une fonctionnalité supplémentaire :
L'auteur a analysé les résultats de plusieurs articles, montrant que Mamba fonctionne nettement mieux sur WikiText-103 que les autres plus de 20 derniers modèles de séquences sous-quadratiques.
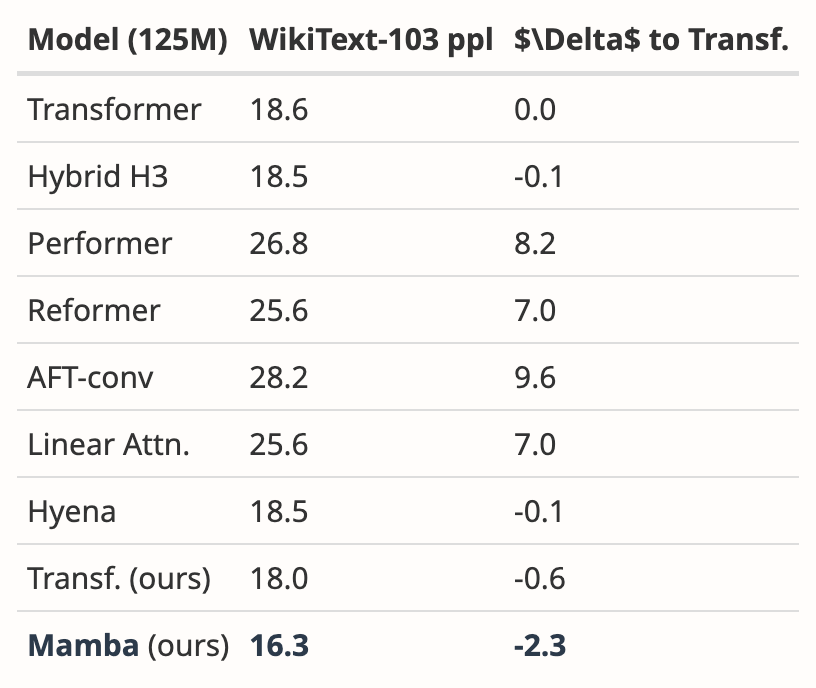
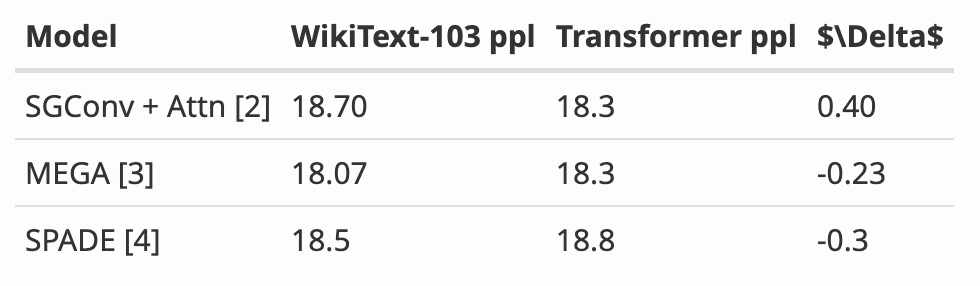
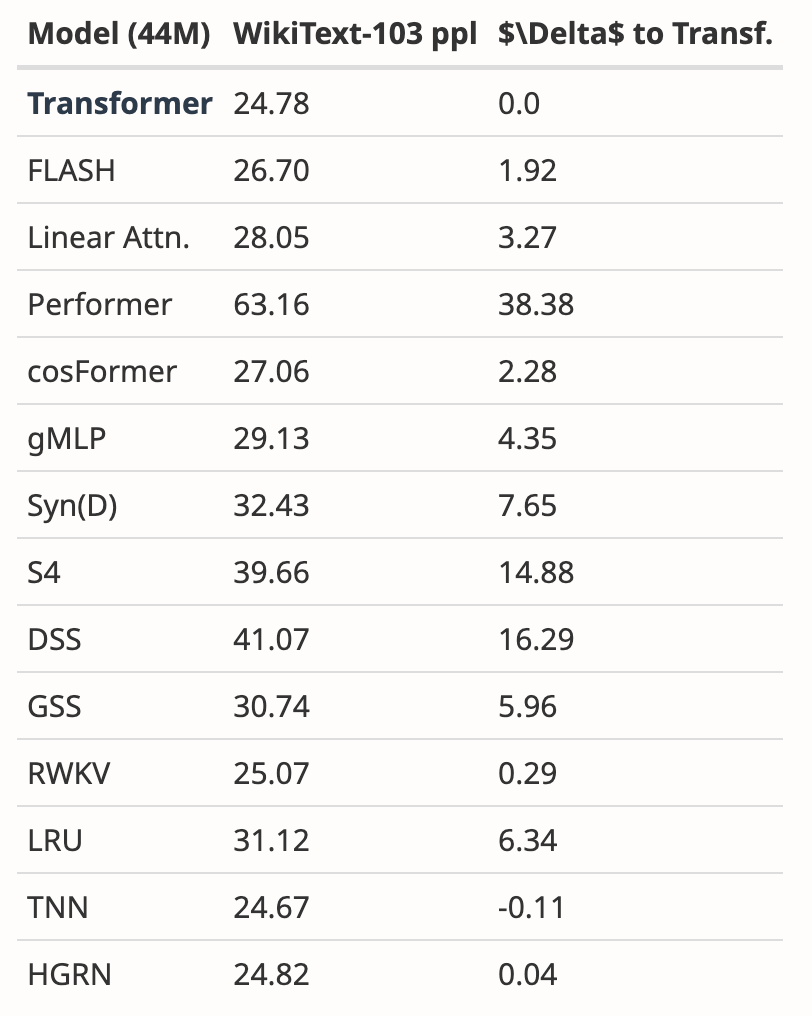
Malgré cela, deux mois se sont écoulés, et ce document est toujours dans le processus "Décision en attente", sans résultat clair d'"acceptation" ou de "rejet".
Dans les grandes conférences sur l'IA, « l'explosion du nombre de soumissions » est un problème gênant, donc les évaluateurs avec une énergie limitée feront inévitablement des erreurs. Cela a conduit au rejet de nombreux articles célèbres de l'histoire, notamment YOLO, Transformer XL, Dropout, Support Vector Machine (SVM), Knowledge Distillation, SIFT et l'algorithme de classement des pages Web du moteur de recherche Google, PageRank (voir : "Les célèbres YOLO et PageRank des recherches influentes ont été rejetées par la plus haute conférence CS").
Même Yann LeCun, l'un des trois géants du deep learning, est aussi un papetier majeur qui est souvent rejeté. Tout à l'heure, il a tweeté que son article « Deep Convolutional Networks on Graph-Structured Data », qui a été cité 1 887 fois, avait également été rejeté par la plus haute conférence.
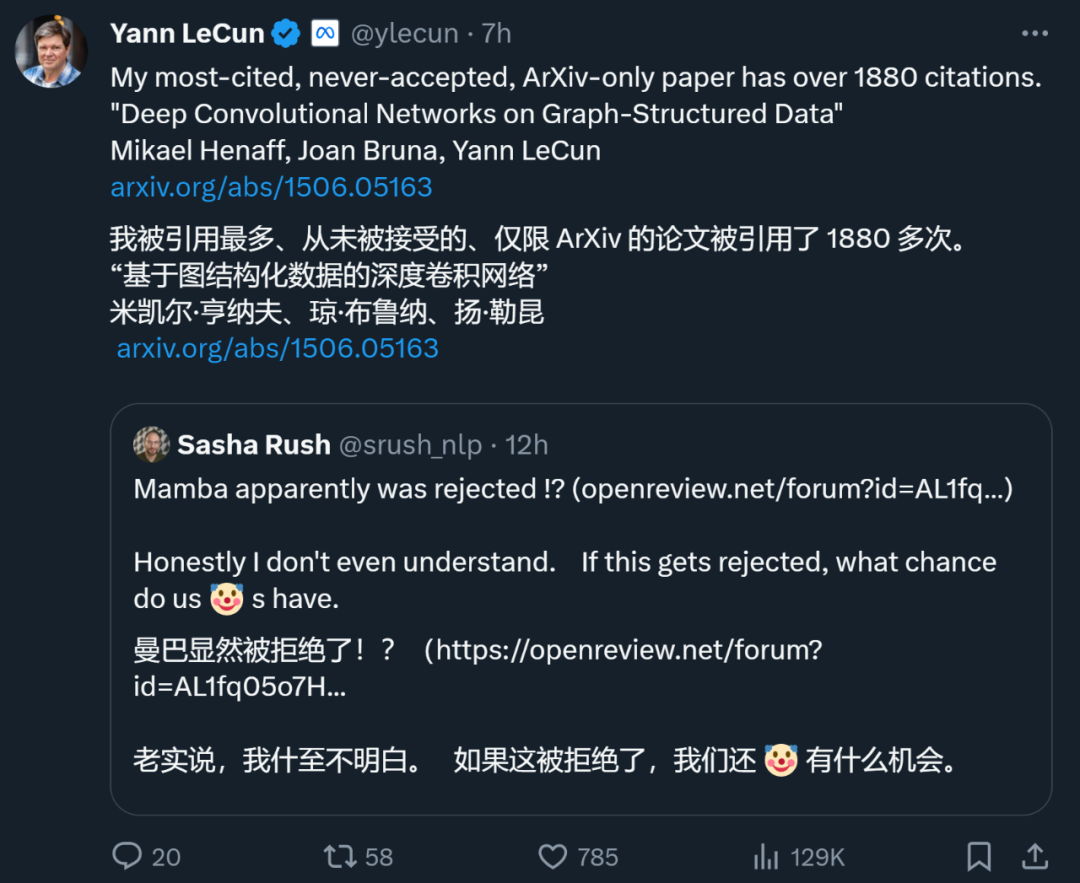
Lors de l'ICML 2022, il a même "soumis trois articles et trois ont été rejetés".

Donc, ce n'est pas parce que l'article est rejeté par une certaine grande conférence qu'il n'a aucune valeur. Parmi les articles rejetés mentionnés ci-dessus, beaucoup ont choisi d'être transférés à d'autres conférences et ont finalement été acceptés. Par conséquent, les internautes ont suggéré que Mamba passe au COLM, qui a été créé par de jeunes universitaires tels que Chen Danqi. COLM est un lieu universitaire dédié à la recherche sur la modélisation du langage, axé sur la compréhension, l'amélioration et les commentaires sur le développement de la technologie des modèles de langage, et peut constituer un meilleur choix pour des articles comme celui de Mamba.
Cependant, que Mamba puisse éventuellement être accepté par l'ICLR, il est devenu une œuvre influente et a également donné à la communauté l'espoir de briser les chaînes de Transformer, en injectant une exploration au-delà du modèle Transformer traditionnel. .Nouvelle énergie.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quel fichier est une ressource ?
Quel fichier est une ressource ?
 Comment définir un arrêt programmé dans UOS
Comment définir un arrêt programmé dans UOS
 Springcloud cinq composants principaux
Springcloud cinq composants principaux
 Le rôle de la fonction mathématique en langage C
Le rôle de la fonction mathématique en langage C
 Que signifie le wifi désactivé ?
Que signifie le wifi désactivé ?
 Jailbreak iPhone 4
Jailbreak iPhone 4
 La différence entre les fonctions fléchées et les fonctions ordinaires
La différence entre les fonctions fléchées et les fonctions ordinaires
 Comment ignorer la connexion à Internet après le démarrage de Windows 11
Comment ignorer la connexion à Internet après le démarrage de Windows 11








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



