


Dans un environnement familial, il est souvent demandé aux membres de la famille de placer la télécommande sur le meuble TV. Parfois, même les chiens de compagnie ne sont pas à l’abri. Mais il y a toujours des moments où les gens se trouvent dans des situations où ils sont incapables de contrôler les autres. Et les chiens de compagnie peuvent ne pas être en mesure de comprendre les instructions. Les êtres humains attendent des robots qu'ils nous aident à accomplir ces tâches. C'est notre rêve ultime pour les robots.
Récemment, l'Université de New York et Meta ont collaboré pour développer un robot capable d'agir de manière autonome. Lorsque vous lui dites : « S'il vous plaît, posez les cornflakes sur la table de chevet », il accomplira la tâche avec succès en recherchant indépendamment les cornflakes et en planifiant le meilleur itinéraire et les actions correspondantes. De plus, le robot a également la capacité d’organiser les objets et de gérer les déchets pour vous offrir plus de commodité.



Ce robot s'appelle OK-Robot et a été construit par des chercheurs de l'Université de New York et de Meta. Ils ont intégré les modules de base du modèle de langage visuel, de la navigation et de la saisie dans un cadre ouvert basé sur la connaissance pour fournir une solution pour des opérations efficaces de sélection et de placement des robots. Cela signifie qu’en vieillissant, acheter un robot pour nous aider à servir du thé et à verser de l’eau pourrait devenir une réalité.
Le positionnement « connaissance ouverte » d’OK-Robot fait référence à son modèle d’apprentissage formé sur de grands ensembles de données publiques. Lorsque OK-Robot est placé dans un nouvel environnement domestique, il récupère les résultats de l'analyse depuis l'iPhone. Sur la base de ces analyses, il calcule des représentations de langage visuel denses à l'aide de LangSam et CLIP et les stocke dans la mémoire sémantique. Ensuite, lorsqu'une requête linguistique concernant un objet à récupérer est soumise, la représentation linguistique de la requête est comparée à la mémoire sémantique. Ensuite, OK-Robot appliquera progressivement les modules de navigation et de sélection, se déplacera vers l'objet requis et le récupérera. Un processus similaire peut être utilisé pour éliminer des objets.
Pour étudier OK-Robot, les chercheurs l'ont testé dans 10 environnements domestiques réels. Grâce à des expériences, ils ont découvert que dans un environnement domestique naturel invisible, le taux de réussite du déploiement du système sans échantillon était en moyenne de 58,5 %. Cependant, ce taux de réussite dépend fortement du « caractère naturel » de l’environnement. Ils ont également constaté que ce taux de réussite pouvait être augmenté jusqu'à environ 82,4 % en améliorant la requête, en rangeant l'espace et en excluant les objets manifestement contradictoires (tels que trop grands, trop translucides ou trop glissants).
Dans 10 environnements domestiques à New York, OK-Robot a tenté 171 tâches de ramassage.
En résumé, grâce à des expériences, ils sont arrivés aux conclusions suivantes :
Afin d'encourager et de soutenir les travaux d'autres chercheurs dans le domaine de la robotique à connaissances ouvertes, l'auteur a déclaré qu'il partagerait le code et les modules d'OK-Robot. Plus d'informations peuvent être trouvées sur : https://ok-robot.github.io.
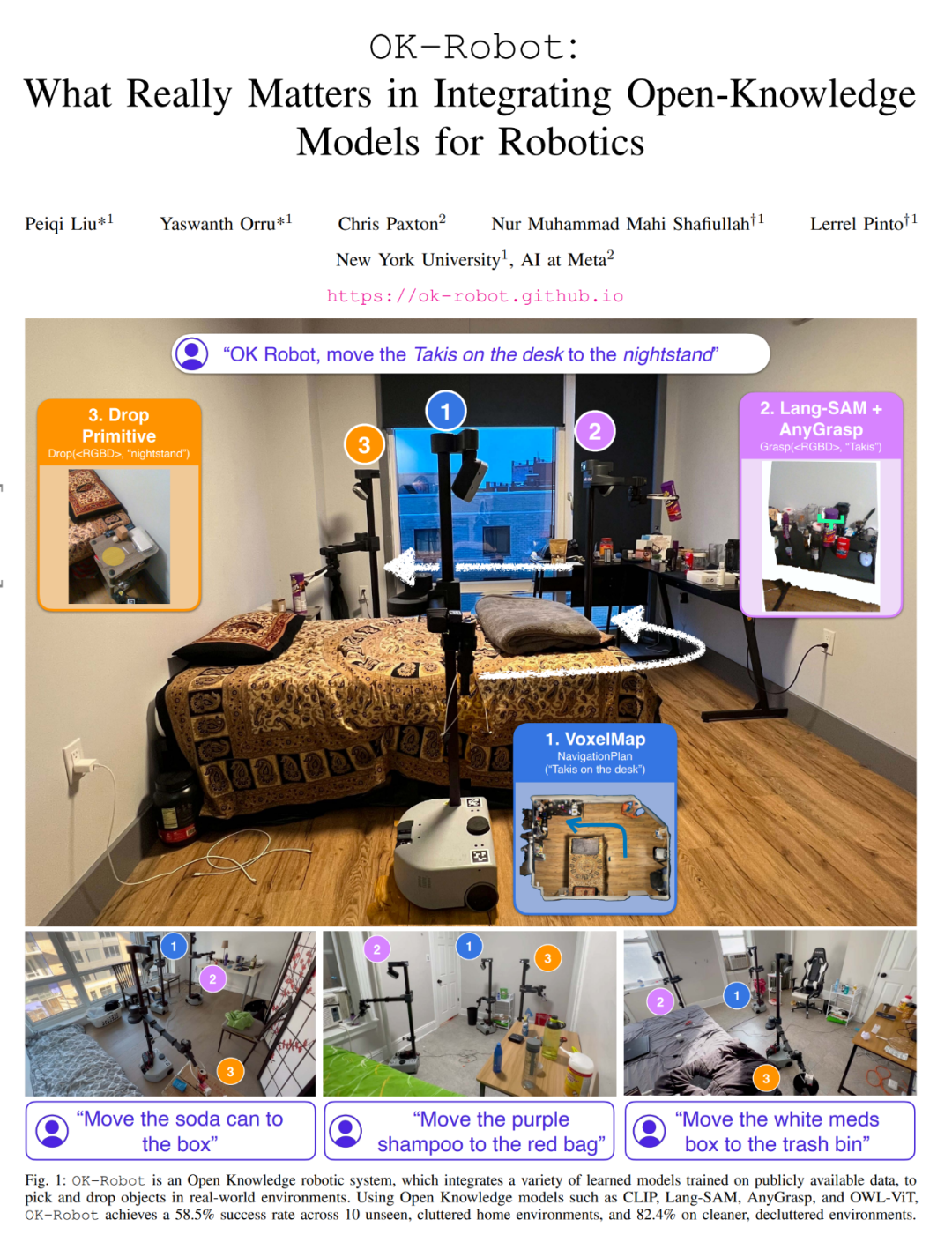
Cette recherche résout principalement ce problème : récupérer A de B et le placer sur C, où A est un objet et B et C sont quelque part dans l'environnement du monde réel. Pour y parvenir, le système proposé doit inclure les modules suivants : un module de navigation d'objets à vocabulaire ouvert, un module de saisie RVB-D à vocabulaire ouvert et un module heuristique pour libérer ou placer des objets (heuristique de chute).
Ouvrez la navigation des objets de vocabulaire
Commencez par scanner la pièce. La navigation par objets de vocabulaire ouvert suit l'approche CLIP-Fields et suppose une phase de pré-cartographie d'analyse manuelle de l'environnement domestique à l'aide d'un iPhone. Cette analyse manuelle capture simplement une vidéo personnelle à l'aide de l'application Record3D sur un iPhone, qui produira une série d'images RVB-D avec des emplacements.
Il faut moins d'une minute pour numériser chaque pièce, et une fois les informations collectées, l'image RVB-D ainsi que la pose et la position de la caméra sont exportées vers la bibliothèque du projet pour la création de cartes. L'enregistrement doit capturer la surface du sol ainsi que les objets et conteneurs dans l'environnement.
La prochaine étape est la détection d'objets. Sur chaque image numérisée, un détecteur d'objets à vocabulaire ouvert traite le contenu numérisé. Cet article choisit le détecteur d'objets OWL-ViT car cette méthode est plus performante sur les requêtes préliminaires. Nous appliquons le détecteur sur chaque image et extrayons chaque boîte englobante d'objet, l'intégration CLIP et la confiance du détecteur et les transmettons au module de stockage d'objets du module de navigation.
Effectuez ensuite un stockage sémantique centré sur les objets. Cet article utilise VoxelMap pour accomplir cette étape. Plus précisément, ils utilisent l'image de profondeur et la pose collectées par la caméra pour rétroprojeter le masque d'objet en coordonnées réelles. De cette manière, ils peuvent fournir un nuage de points dans lequel chaque point a un associatif. vecteurs sémantiques de CLIP.
Suivi du module mémoire de requêtes : étant donné une requête de langage, cet article utilise l'encodeur de langage CLIP pour la convertir en vecteurs sémantiques. Étant donné que chaque voxel est associé à un emplacement réel dans la maison, l'emplacement où l'objet de requête est le plus susceptible d'être trouvé peut être trouvé, comme dans la figure 2 (a).
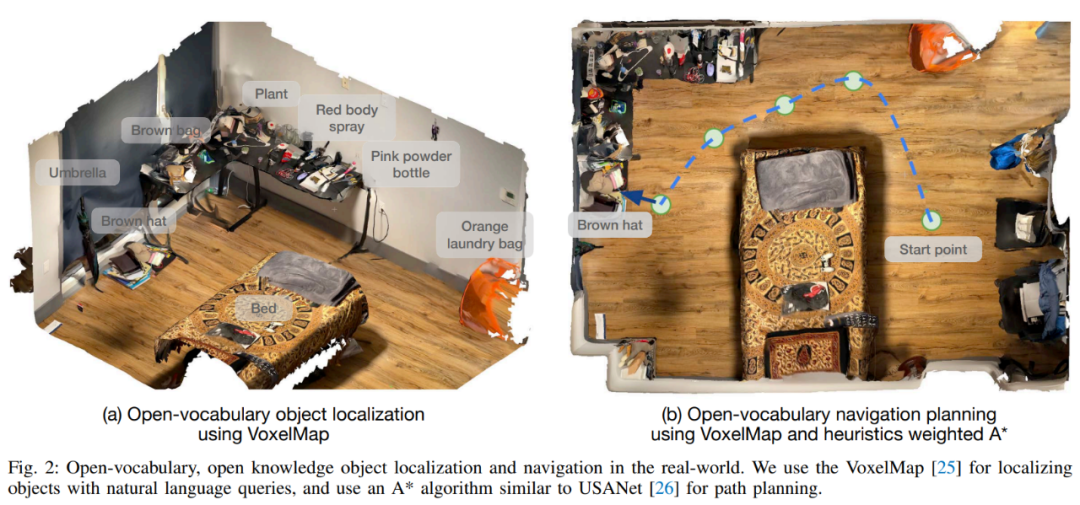
Si nécessaire, cet article implémentera "A sur B" comme "A proche B". Pour ce faire, la requête A sélectionne les 10 premiers points et la requête B sélectionne les 50 premiers points. Calculez ensuite la distance euclidienne par paire 10 × 50 et sélectionnez le point A associé à la distance la plus courte (A, B).
Après avoir terminé le processus ci-dessus, l'étape suivante consiste à naviguer vers l'objet dans le monde réel : une fois les coordonnées de position 3D dans le monde réel obtenues, elles peuvent être utilisées comme cible de navigation du robot pour initialiser le phase d'exploitation. Le module de navigation doit placer le robot à portée de main afin que le robot puisse ensuite manipuler l'objet cible.
Saisie robotique d'objets du monde réel
Contrairement à la navigation par vocabulaire ouvert, afin de terminer la tâche de saisie, l'algorithme doit interagir physiquement avec des objets arbitraires dans le monde réel, ce qui rend cette partie encore plus difficulté. Par conséquent, cet article choisit d'utiliser un modèle de préhension pré-entraîné pour générer des gestes de préhension du monde réel et d'utiliser VLM pour le filtrage des conditions de langage.
Le module de génération de saisie utilisé dans cet article est AnyGrasp, qui génère des saisies sans collision à l'aide de pinces à mâchoires parallèles dans une scène à partir d'une seule image RVB et d'un nuage de points.
AnyGrasp fournit les saisies possibles dans la scène (Figure 3, colonne 2), y compris le point de saisie, la largeur, la hauteur, la profondeur et le score de saisie, qui représente la confiance du modèle non calibré dans chaque saisie.

Filtrage des saisies à l'aide de requêtes linguistiques : pour les suggestions de saisies obtenues à partir d'AnyGrasp, cet article utilise LangSam pour filtrer les saisies. Cet article projette tous les points de préhension proposés sur l'image et trouve les points de préhension qui relèvent du masque d'objet (Figure 3, colonne 4).
Exécution de la poignée. Une fois la saisie optimale déterminée (Figure 3, colonne 5), une méthode simple de pré-saisie peut être utilisée pour saisir l’objet cible.
Module heuristique pour libérer ou placer des objets
Après avoir saisi l'objet, l'étape suivante consiste à savoir où placer l'objet. Contrairement à l'implémentation de base de HomeRobot, qui suppose que l'endroit où l'objet est déposé est une surface plane, cet article l'étend pour couvrir également les objets concaves tels que les éviers, les poubelles, les boîtes et les sacs.
Maintenant que la navigation, la préhension et le placement sont tous là, il ne reste plus qu'à les assembler, une méthode directement applicable à toute nouvelle maison. Pour les nouveaux environnements domestiques, l’étude peut scanner une pièce en moins d’une minute. Il faut ensuite moins de cinq minutes pour le transformer en VoxelMap. Une fois terminé, le robot peut être placé immédiatement sur le site choisi et commencer les opérations. De l’arrivée dans un nouvel environnement au début d’un fonctionnement autonome dans celui-ci, le système prend en moyenne moins de 10 minutes pour accomplir sa première tâche de sélection et de placement.
Dans plus de 10 expériences à domicile, OK-Robot a atteint un taux de réussite de 58,5 % sur les tâches de sélection et de placement.
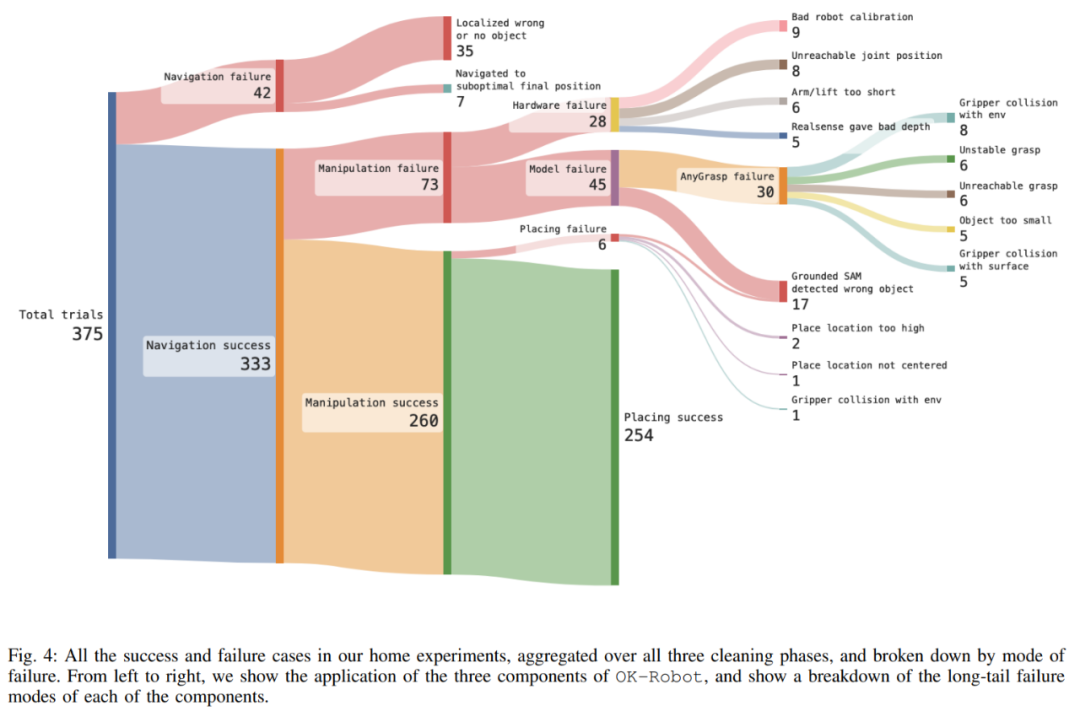
L'étude a également mené une exploration approfondie d'OK-Robot pour mieux comprendre ses modes de défaillance. L'étude a révélé que la principale cause de l'échec était un échec opérationnel. Cependant, après une observation minutieuse, il a été remarqué que la cause de l'échec était due à la longue queue. Comme le montre la figure 4, les trois principales raisons de l'échec comprenaient l'échec de la récupération. de la mémoire sémantique, l'emplacement vers lequel naviguer. du bon objet (9,3 %), la pose obtenue à partir du module de manipulation est difficile à réaliser (8,0 %) et des raisons matérielles (7,5 %).
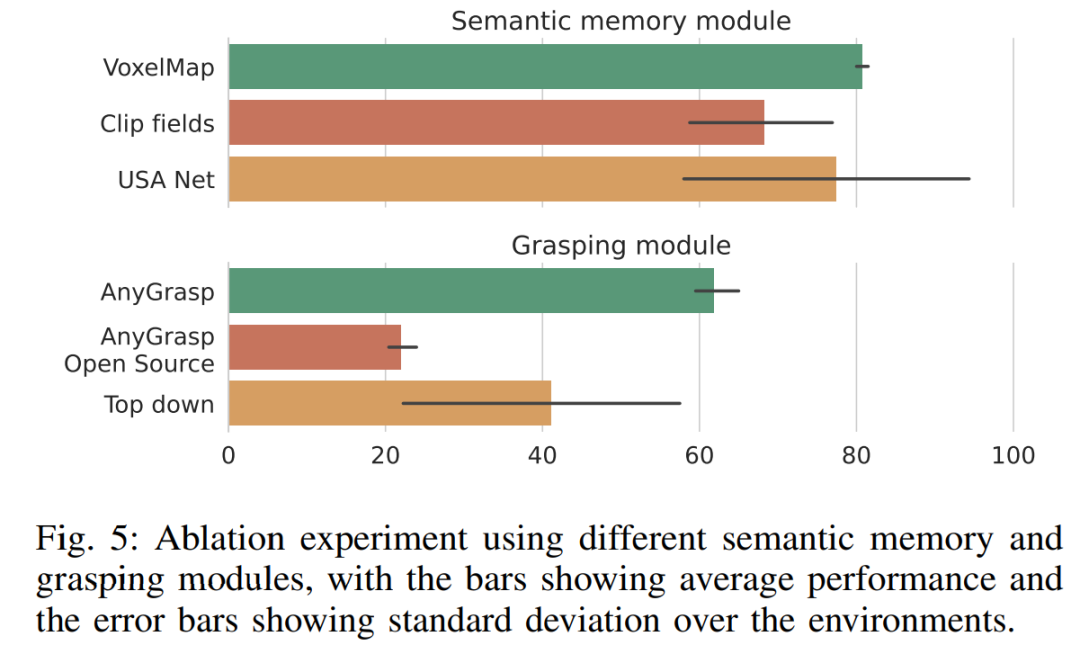
On peut voir sur la figure 5 que le VoxelMap utilisé dans OK-Robot est légèrement meilleur que les autres modules de mémoire sémantique. Quant au module de scraping, AnyGrasp surpasse considérablement les autres méthodes de scraping, surpassant le meilleur candidat (grattage descendant) de près de 50 % sur une échelle relative. Cependant, le fait que l'exploration descendante de HomeRobot basée sur l'heuristique ait dépassé la base de référence open source AnyGrasp et Contact-GraspNet démontre que la construction d'un modèle d'exploration véritablement universel reste difficile.
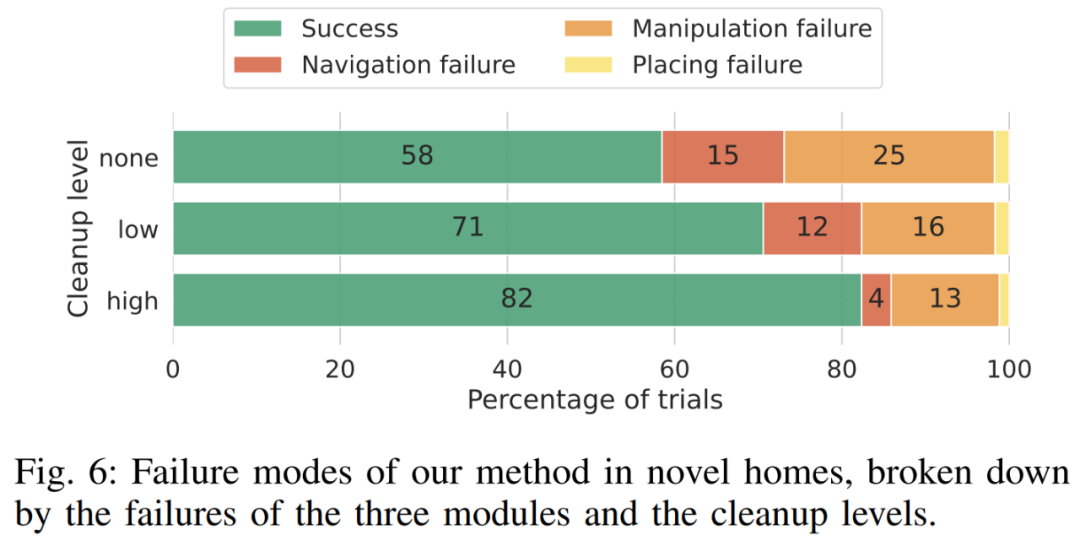
La figure 6 montre l'analyse complète de la défaillance d'OK-Robot à différentes étapes. Selon l'analyse, lorsque les chercheurs nettoient l'environnement et suppriment les objets flous, la précision de la navigation augmente et le taux d'erreur total passe de 15 % à 12 %, pour finalement tomber à 4 %. De même, la précision s'est améliorée lorsque les chercheurs ont débarrassé l'environnement, les taux d'erreur passant de 25 pour cent à 16 pour cent et finalement à 13 pour cent.
Pour plus d'informations, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 La différence et le lien entre le langage C et C++
La différence et le lien entre le langage C et C++
 L'ordinateur ne peut pas copier et coller
L'ordinateur ne peut pas copier et coller
 WeChat n'a pas réussi à charger les données
WeChat n'a pas réussi à charger les données
 c'est-à-dire que le raccourci ne peut pas être supprimé
c'est-à-dire que le raccourci ne peut pas être supprimé
 Qu'est-ce qu'un concepteur d'interface utilisateur ?
Qu'est-ce qu'un concepteur d'interface utilisateur ?
 BatterieMon
BatterieMon
 Solution à l'erreur de socket 10054
Solution à l'erreur de socket 10054








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



