Le feedback d'intelligence artificielle (AIF) va-t-il remplacer le RLHF ?
Dans le domaine des grands modèles, la mise au point est une étape importante pour améliorer les performances du modèle. À mesure que le nombre de grands modèles open source augmente progressivement, les gens ont résumé de nombreuses méthodes de réglage fin, dont certaines ont obtenu de bons résultats. Récemment, des chercheurs de Meta et de l'Université de New York ont utilisé la « méthode d'auto-récompense » pour permettre à de grands modèles de générer leurs propres données de réglage fin, ce qui a provoqué un nouveau choc chez les gens. Dans la nouvelle méthode, l'auteur a affiné Llama 2 70B en trois itérations, et le modèle généré a surpassé un certain nombre de grands modèles importants existants dans le classement AlpacaEval 2.0, notamment Claude 2, Gemini Pro et GPT -4. . Le journal a donc attiré l’attention des gens quelques heures seulement après sa publication sur arXiv. Bien que la méthode ne soit pas encore open source, on pense que la méthode utilisée dans l'article est clairement décrite et ne devrait pas être difficile à reproduire. 
Il est connu que le réglage de grands modèles de langage (LLM) à l'aide de données de préférences humaines peut considérablement améliorer les performances de suivi des instructions des modèles pré-entraînés. Dans la série GPT, OpenAI a proposé une méthode standard d'apprentissage par renforcement par rétroaction humaine (RLHF), qui permet à de grands modèles d'apprendre des modèles de récompense à partir des préférences humaines, puis de geler les modèles de récompense et de les utiliser pour entraîner le LLM à l'aide de l'apprentissage par renforcement. La méthode a remporté un énorme succès. Une nouvelle idée qui a émergé récemment est d'éviter complètement la formation des modèles de récompense et d'utiliser directement les préférences humaines pour former le LLM, comme l'optimisation directe des préférences (DPO). Dans les deux cas ci-dessus, le réglage est gêné par la taille et la qualité des données de préférences humaines, et dans le cas du RLHF, la qualité du réglage est également gênée par la qualité des modèles de récompense gelés formés à partir de ceux-ci. Dans de nouveaux travaux sur Meta, les auteurs proposent de former un modèle de récompense auto-amélioré qui, plutôt que d'être gelé, est continuellement mis à jour pendant le réglage du LLM pour éviter ce goulot d'étranglement. La clé de cette approche est de développer un agent doté de toutes les capacités requises pendant la formation (plutôt que de le diviser en modèles de récompense et en modèles de langage), permettant une pré-formation aux tâches de suivi d'instructions et une formation multi-tâches pour permettre Entraînez simultanément plusieurs tâches pour réaliser la migration des tâches. Ainsi, les auteurs introduisent un modèle de langage auto-récompensé, dont les agents agissent à la fois en suivant les instructions du modèle, en générant des réponses aux invites données, et peuvent également générer et évaluer de nouvelles instructions basées sur des exemples à ajouter aux leurs. ensembles de formation. La nouvelle méthode utilise un framework similaire au DPO itératif pour former ces modèles. À partir d'un modèle de départ, comme le montre la figure 1, à chaque itération, il existe un processus de création d'auto-instruction, dans lequel le modèle génère des réponses candidates pour les invites nouvellement créées, et des récompenses sont ensuite attribuées par le même modèle. Ce dernier est réalisé grâce aux incitations du LLM-as-a-Judge, qui peut également être considérée comme une tâche de suivi d'instructions. Un ensemble de données de préférences est construit à partir des données générées et la prochaine itération du modèle est formée via DPO. 
Modèle de langage auto-récompensantL'approche proposée par l'auteur suppose d'abord : l'accès à un modèle de langage de base pré-entraîné et à une petite quantité de données de départ annotées par l'homme, puis construit un modèle qui vise à posséder les deux compétences : 1. Suivez les instructions : donnez des invites qui décrivent la demande de l'utilisateur et soyez capable de générer des réponses de haute qualité, utiles (et inoffensives). 2. Création d'auto-instructions : Capacité à générer et évaluer de nouvelles instructions en suivant des exemples à ajouter à votre propre ensemble de formation. Ces compétences sont utilisées pour permettre au modèle de s'auto-aligner, c'est-à-dire qu'elles sont les composants utilisés pour s'entraîner de manière itérative à l'aide du feedback d'intelligence artificielle (AIF). La création d'auto-instructions consiste à générer des réponses de candidats puis à laisser le modèle lui-même juger de sa qualité, c'est-à-dire qu'il agit comme son propre modèle de récompense, remplaçant ainsi le besoin d'un modèle externe. Ceci est réalisé grâce au mécanisme LLM-as-a-Judge [Zheng et al., 2023b], c'est-à-dire en formulant l'évaluation de la réponse comme une tâche suivant une instruction. Ces données de préférences AIF auto-créées ont été utilisées comme ensemble de formation. Ainsi lors du processus de mise au point, le même modèle est utilisé pour les deux rôles : en tant qu'« apprenant » et en tant que « juge ». Basé sur le rôle émergent du juge, le modèle peut encore améliorer les performances grâce à un ajustement contextuel. Le processus global d'auto-alignement est un processus itératif qui procède par la construction d'une série de modèles, chacun étant une amélioration par rapport au précédent. Ce qui est important ici, c'est que puisque le modèle peut à la fois améliorer ses capacités génératives et utiliser le même mécanisme génératif que son propre modèle de récompense, cela signifie que le modèle de récompense lui-même peut s'améliorer grâce à ces itérations, ce qui est cohérent avec la norme inhérente aux modèles de récompense. . Il existe des différences d’approche. Les chercheurs pensent que cette approche peut augmenter le potentiel de ces modèles d'apprentissage pour s'améliorer à l'avenir et éliminer les goulots d'étranglement restrictifs. La figure 1 montre un aperçu de la méthode. 

Dans l'expérience, le chercheur a utilisé Llama 2 70B comme modèle de base de pré-entraînement. Ils ont constaté que l’alignement LLM sur l’auto-récompense améliorait non seulement les performances de suivi des instructions, mais également les capacités de modélisation des récompenses par rapport au modèle de départ de base. Cela signifie que dans l'entraînement itératif, le modèle est capable de se fournir un ensemble de données de préférences de meilleure qualité dans une itération donnée que dans l'itération précédente. Bien que cet effet ait tendance à saturer dans le monde réel, il offre la possibilité intéressante que le modèle de récompense qui en résulte (et donc le LLM) soit meilleur qu'un modèle formé uniquement à partir de données brutes écrites par des humains. En termes d'instruction suivant la capacité, les résultats expérimentaux sont présentés dans la figure 3 : 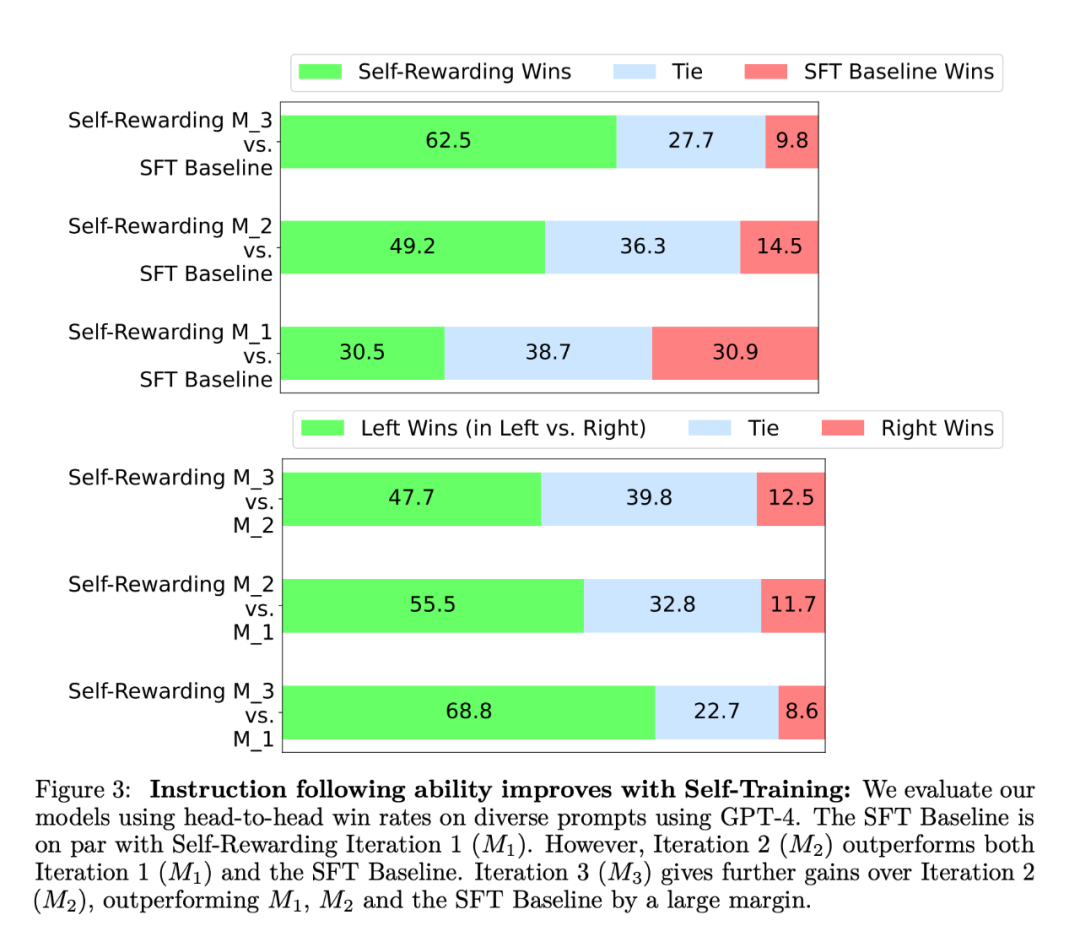 Les chercheurs ont évalué le modèle d'auto-récompense sur la liste de classement AlpacaEval 2, et les résultats sont présentés dans le tableau 1. Ils ont observé la même conclusion que l'évaluation face-à-face, c'est-à-dire que le taux de réussite des itérations de formation était supérieur à celui de GPT4-Turbo, de 9,94 % dans l'itération 1, à 15,38 % dans l'itération 2, à 20,44 % dans itération 3. Pendant ce temps, le modèle Iteration 3 surpasse de nombreux modèles existants, notamment Claude 2, Gemini Pro et GPT4 0613.
Les chercheurs ont évalué le modèle d'auto-récompense sur la liste de classement AlpacaEval 2, et les résultats sont présentés dans le tableau 1. Ils ont observé la même conclusion que l'évaluation face-à-face, c'est-à-dire que le taux de réussite des itérations de formation était supérieur à celui de GPT4-Turbo, de 9,94 % dans l'itération 1, à 15,38 % dans l'itération 2, à 20,44 % dans itération 3. Pendant ce temps, le modèle Iteration 3 surpasse de nombreux modèles existants, notamment Claude 2, Gemini Pro et GPT4 0613.

Les résultats de l'évaluation de la modélisation des récompenses sont présentés dans le tableau 2. Les conclusions comprennent :
L'EFT s'est amélioré par rapport à l'utilisation de l'IFT seul, en utilisant l'IFT+EFT, les cinq indicateurs de mesure se sont améliorés. Par exemple, l’accord de précision par paire avec les humains est passé de 65,1 % à 78,7 %.
Améliorez les capacités de modélisation des récompenses grâce à l'auto-formation. Après une série d'entraînement à l'auto-récompense, la capacité du modèle à fournir des auto-récompenses pour la prochaine itération est améliorée, ainsi que sa capacité à suivre les instructions.
L'importance des conseils LLMas-a-Judge. Les chercheurs ont utilisé divers formats d'invite et ont découvert que les invites LLMas-a-Judge avaient une précision par paire plus élevée lors de l'utilisation de la ligne de base SFT.
L'auteur estime que la méthode de formation d'auto-récompense améliore non seulement la capacité de suivi des instructions du modèle, mais améliore également la capacité de modélisation des récompenses du modèle par itérations. Bien qu'il ne s'agisse que d'une étude préliminaire, cela semble être une direction de recherche passionnante. De tels modèles peuvent mieux attribuer les récompenses dans les itérations futures pour améliorer le respect des instructions et parvenir à un cycle bénin. Cette méthode ouvre également certaines possibilités pour des méthodes de jugement plus complexes. Par exemple, les grands modèles peuvent vérifier l’exactitude de leurs réponses en effectuant une recherche dans une base de données, ce qui permet d’obtenir des résultats plus précis et plus fiables. Contenu de référence : https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_lingual_models_meta_2024/Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 Comment insérer des images en CSS
Comment insérer des images en CSS
 Comment résoudre l'erreur 500 du serveur interne
Comment résoudre l'erreur 500 du serveur interne
 Comment résoudre un périphérique USB non reconnu
Comment résoudre un périphérique USB non reconnu
 Les moments WeChat ne peuvent pas être actualisés
Les moments WeChat ne peuvent pas être actualisés
 Comment modifier element.style
Comment modifier element.style
 Comment obtenir des données en HTML
Comment obtenir des données en HTML
 Pourquoi l'imprimante n'imprime-t-elle pas ?
Pourquoi l'imprimante n'imprime-t-elle pas ?
 Qu'est-ce que le logiciel système
Qu'est-ce que le logiciel système








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



