


Yuanxiang a publié le premier grand modèle open source au monde XVERSE-Long-256K avec une longueur de fenêtre contextuelle de 256K. Ce modèle prend en charge la saisie de 250 000 caractères chinois, permettant aux applications de grands modèles d'entrer dans « l'ère des textes longs ». Le modèle est entièrement open source et peut être utilisé commercialement gratuitement sans aucune condition. Il est également accompagné de didacticiels de formation détaillés, étape par étape, qui permettent à un grand nombre de petites et moyennes entreprises, de chercheurs et de développeurs de réaliser des « grandes ». liberté de modèle" plus tôt.
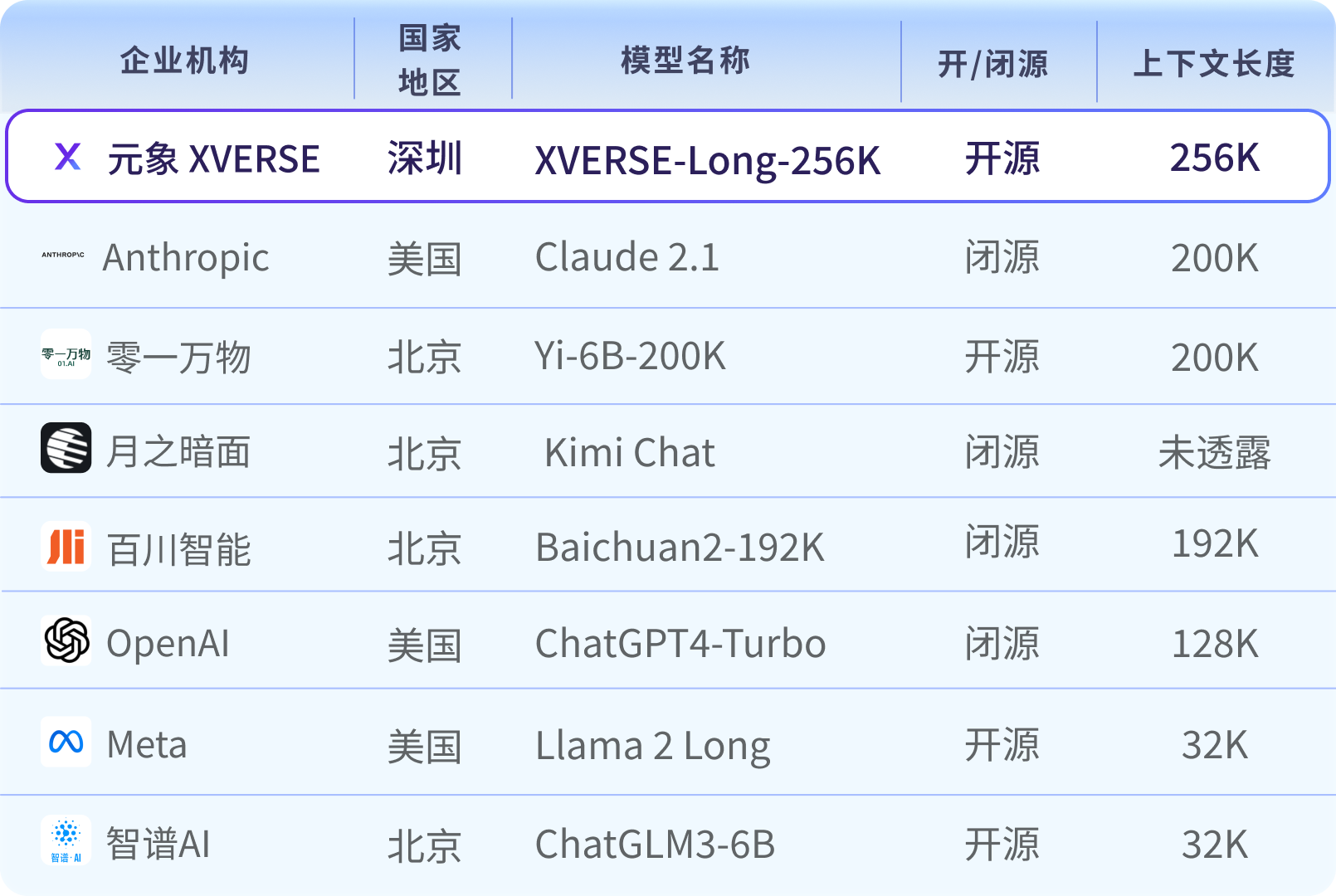 Carte mondiale de grands modèles de texte long grand public
Carte mondiale de grands modèles de texte long grand public
La quantité de paramètres et la quantité de données de haute qualité déterminent la complexité de calcul des grands modèles, et la technologie de texte long (Contexte Long) est le « tueur » dans le développement d'applications de grands modèles. En raison de la nouvelle technologie, la R&D est difficile et la plupart d'entre elles sont actuellement fournies par des sources fermées payantes.
XVERSE-Long-256K prend en charge la saisie de texte ultra-longue et peut être utilisé pour l'analyse de données à grande échelle, la compréhension en lecture de plusieurs documents et l'intégration de connaissances inter-domaines, améliorant efficacement la profondeur et l'étendue des applications de grands modèles : 1. Pour les avocats, les analystes financiers ou les consultants, les enseignants, les ingénieurs rapides, les chercheurs scientifiques, etc. peuvent résoudre le travail d'analyse et de traitement de textes plus longs. 2. Dans les applications de jeux de rôle ou de chat, cela peut atténuer le problème de mémoire du modèle « oubli » ; le dialogue précédent, ou le problème des « hallucinations » du non-sens ; 3. Mieux soutenir les agents d'IA dans la planification et la prise de décision basées sur des informations historiques ; 4. Aider les applications natives d'IA à maintenir une expérience utilisateur cohérente et personnalisée ;
Jusqu'à présent, XVERSE-Long-256K a comblé le vide de l'écosystème open source et a également formé un « seau familial haute performance » avec les précédents grands modèles de 7 milliards, 13 milliards et 65 milliards de paramètres de Yuanxiang, augmentant ainsi l'open source national au niveau de première classe mondial. 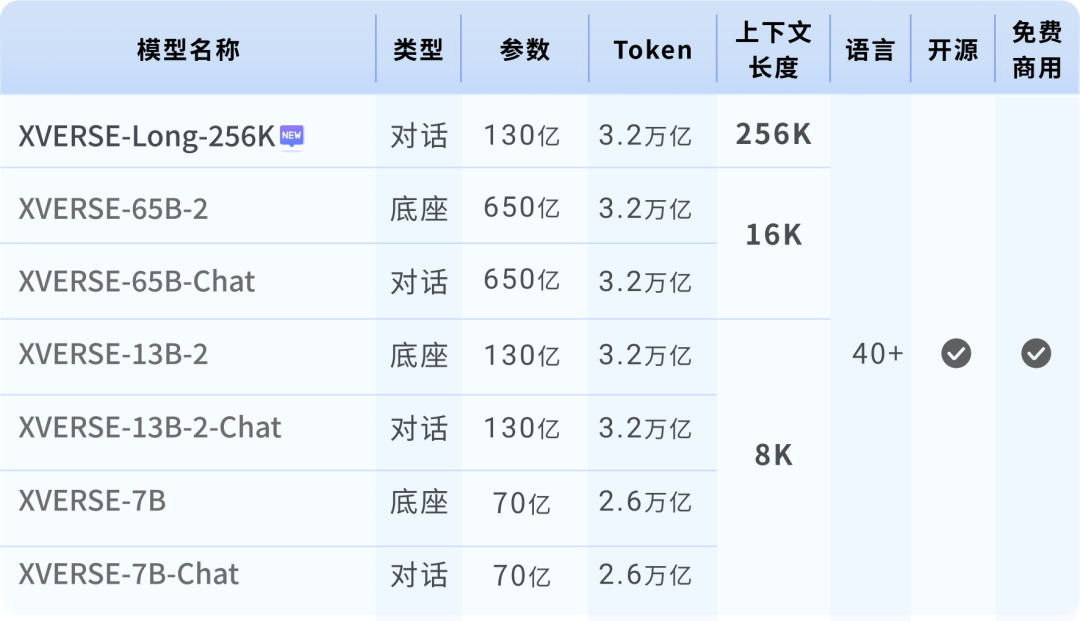 Série grand modèle Yuanxiang
Série grand modèle Yuanxiang
Téléchargement gratuit du grand modèle Yuanxiang
Afin de garantir que l'industrie a une compréhension complète, objective et à long terme du grand modèle Yuanxiang, les chercheurs se sont référés à des évaluations faisant autorité dans l'industrie et ont développé une évaluation complète en 9 éléments. système d’évaluation en six dimensions. XVERSE-Long-256K fonctionnent tous bien, surpassant les autres modèles de texte long.
Résultats de l'évaluation des grands modèles de texte long open source grand public à l'échelle mondiale XVERSE-Long-256K a réussi le test de stress de performance commun de grand modèle de texte long "Trouver une aiguille dans une botte de foin". Ce test masque une phrase dans un long corpus de texte qui n'a rien à voir avec son contenu et utilise des questions en langage naturel pour permettre au grand modèle d'extraire la phrase avec précision.
Roman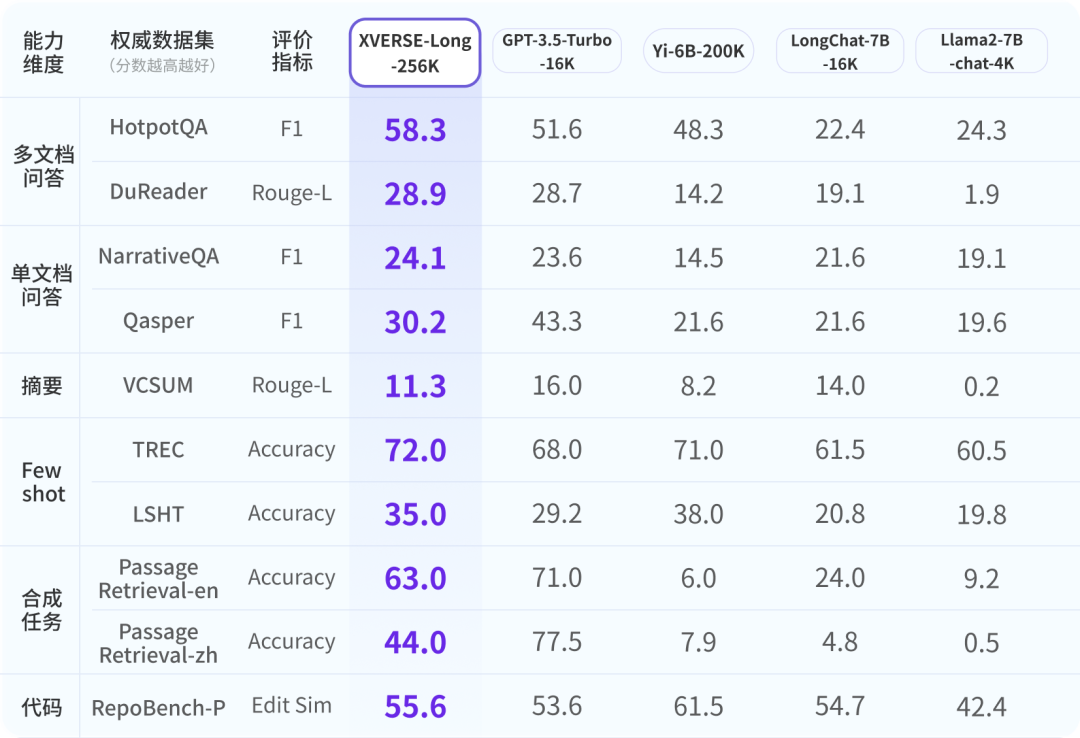
Compréhension en lecture
Actuellement, la plupart des modèles à grande échelle en Chine ne prennent en charge que les bilingues chinois et anglais, mais Yuanxiang prend en charge plus de 40 langues. Nous avons testé le roman classique russe de 160 000 caractères « Comment l'acier a été trempé » et la biographie historique allemande de 410 000 caractères « Quand brillent les étoiles de l'humanité ». Test "Comment l'acier a été trempé (version russe)"
Test "Quand les étoiles humaines brillent (version allemande)"Lois et règlements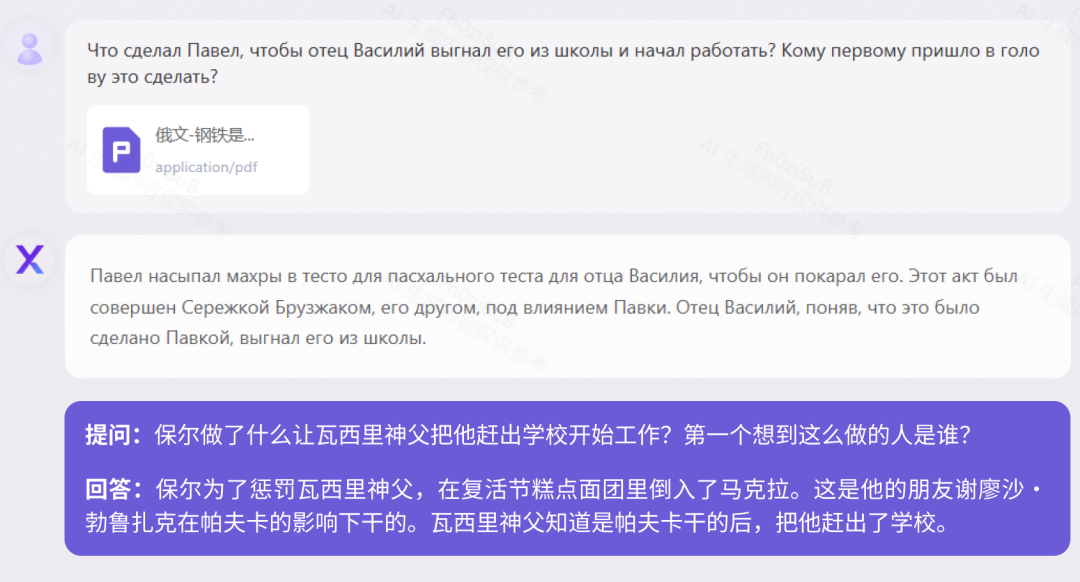
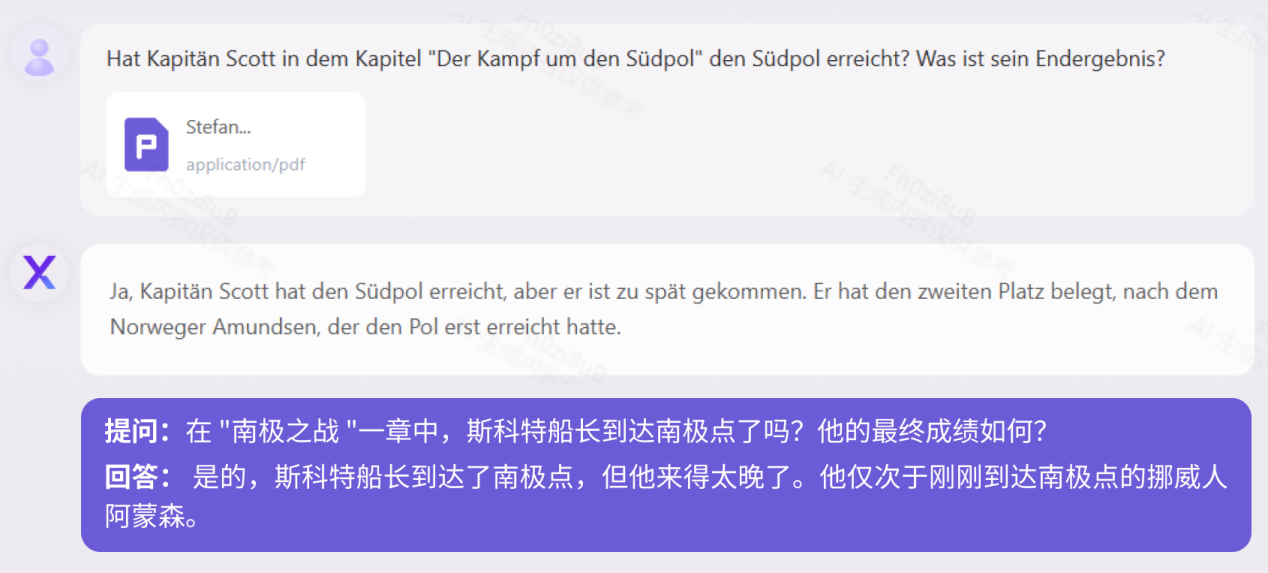
Application précise
Basé sur "La Chine prend le civil Code de la République populaire de Chine à titre d'exemple, il montre l'interprétation des termes juridiques, ainsi que l'analyse logique des cas et une application flexible en combinaison avec la réalité : Test "Code civil"
Apprenez-vous l'étape par étape, comment entraîner de grands modèles de texte long 


Défi technique
2. Route technique Yuanxiang
La technologie des grands modèles de texte long est une nouvelle technologie développée au cours de l'année écoulée. Sa principale solution technique est la suivante :
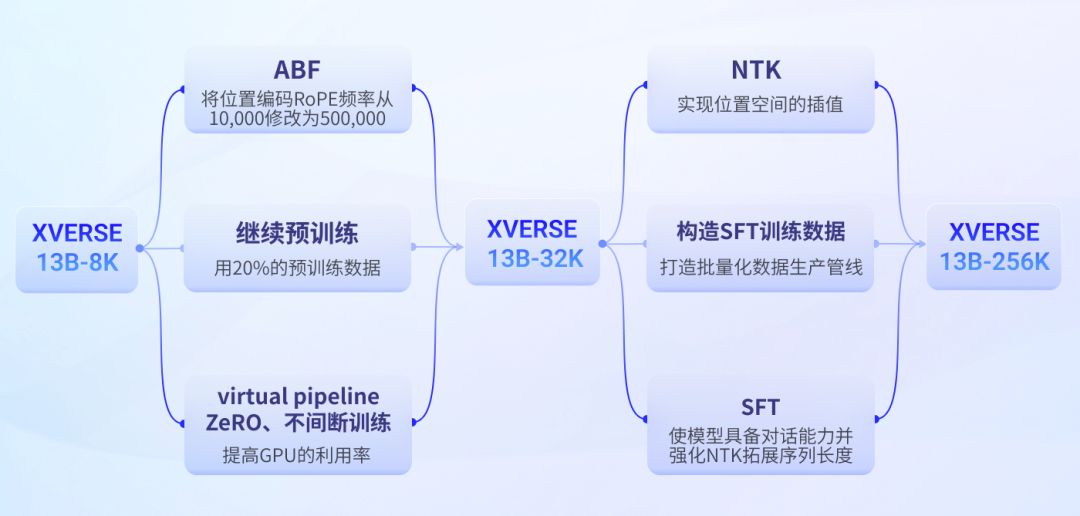
Processus de formation sur grand modèle de texte long Yuanxiang
Première étape : ABF+Continuer la pré-formation
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre obtenir et publier
La différence entre obtenir et publier
 numéro de série cad2012 et collection de clés
numéro de série cad2012 et collection de clés
 Comment illuminer le moment des amis proches de Douyin
Comment illuminer le moment des amis proches de Douyin
 Quel logiciel est l'âme ?
Quel logiciel est l'âme ?
 Quelles sont les méthodes de tri ?
Quelles sont les méthodes de tri ?
 Quelle est la différence entre passer par valeur et passer par référence en Java
Quelle est la différence entre passer par valeur et passer par référence en Java
 Explication détaillée du fichier de configuration du quartz
Explication détaillée du fichier de configuration du quartz
 À quel point le Dimensity 6020 est-il équivalent à Snapdragon ?
À quel point le Dimensity 6020 est-il équivalent à Snapdragon ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



