Afin de réécrire le contenu sans changer le sens original, la langue doit être réécrite en chinois et la phrase originale n'a pas besoin d'apparaître
Le département éditorial de ce site
L'émergence de PowerInfer rend l'exécution de l'IA sur du matériel grand public plus efficace
L'équipe de l'Université Jiao Tong de Shanghai vient de lancer PowerInfer, un processeur/GPU LLM d'inférence à grande vitesse super puissant moteur. 
Adresse du projet : https://github.com/SJTU-IPADS/PowerInfer
Adresse papier : https://ipads.se .sj tu .edu.cn/_media/publications/powerinfer-20231219.pdfSur un seul RTX 4090 (24G) exécutant Falcon (ReLU)-40B-FP16, PowerInfer a atteint une accélération 11x par rapport à lama.cpp ! 
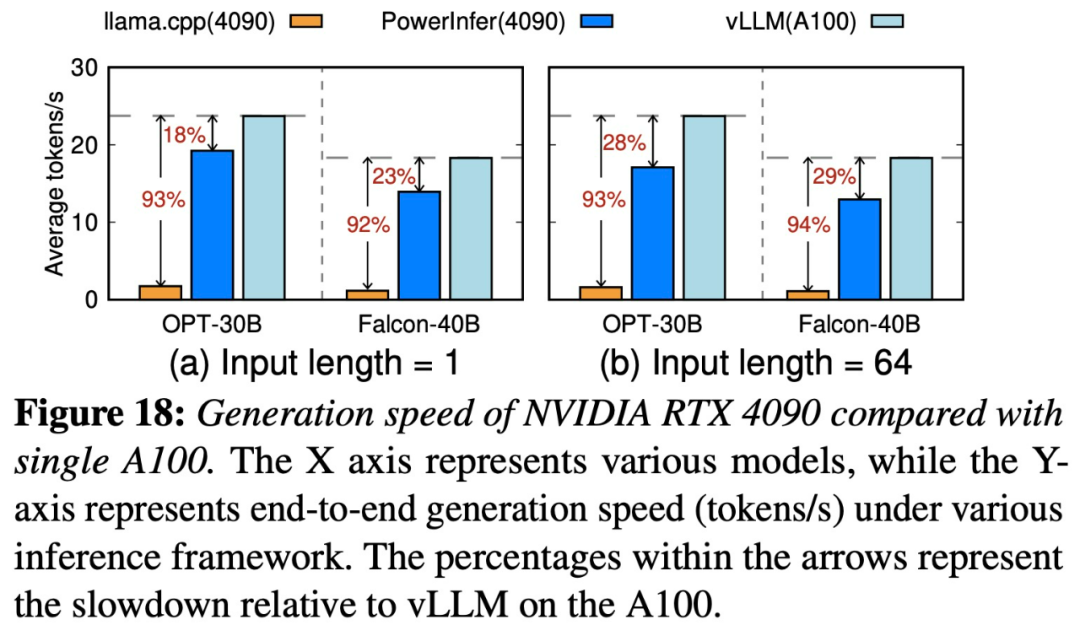
PowerInfer et llama.cpp fonctionnent tous deux sur le même matériel et profitent pleinement de la VRAM du RTX 4090. Sur différents LLM sur un seul GPU NVIDIA RTX 4090, le taux moyen de génération de jetons de PowerInfer est de 13,20 jetons/seconde, avec un pic de 29,08 jetons/seconde, soit seulement 18 % de moins que le meilleur A100 de qualité serveur. GPU. 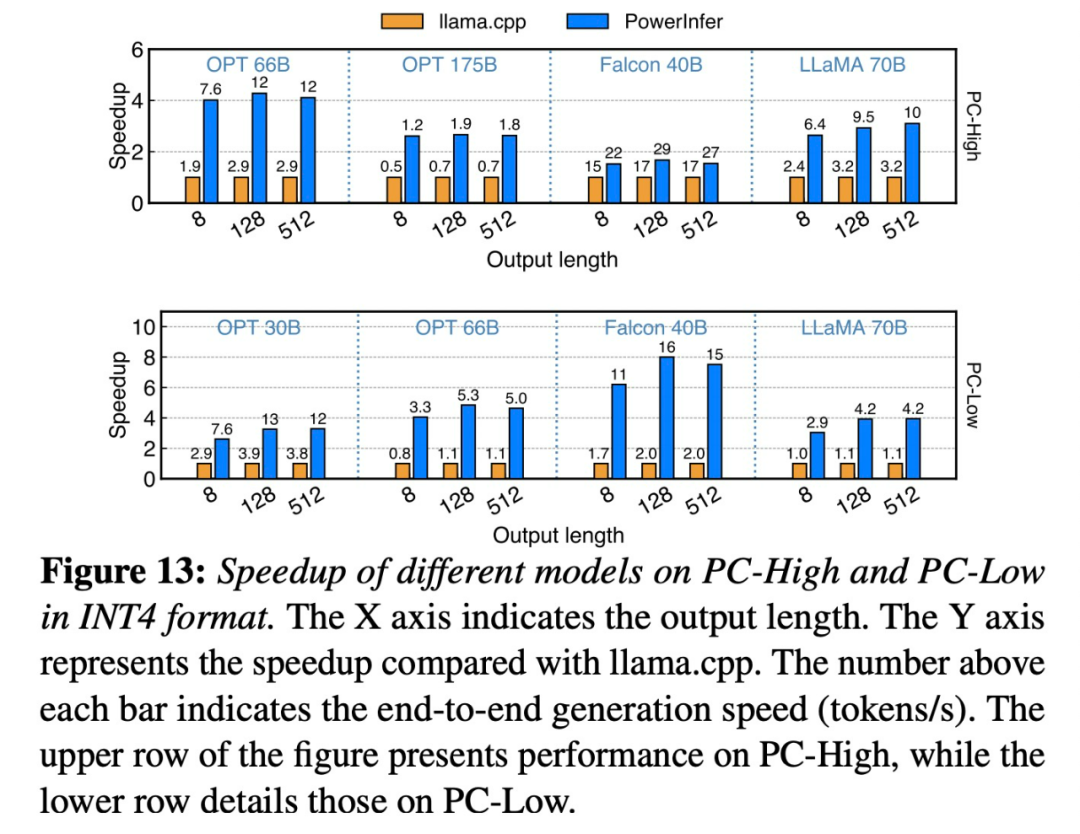
Plus précisément, PowerInfer est un moteur d'inférence à grande vitesse pour le LLM déployé localement. Il exploite la haute localité de l’inférence LLM pour concevoir un moteur d’inférence hybride GPU-CPU. Les neurones activés à chaud sont préchargés sur le GPU pour un accès rapide, tandis que les neurones activés à froid sont (principalement) calculés sur le CPU. Cette approche réduit considérablement les besoins en mémoire GPU et les transferts de données CPU-GPU. PowerInfer peut exécuter de grands modèles de langage (LLM) à grande vitesse sur un ordinateur personnel (PC) équipé d'un seul GPU grand public. Les utilisateurs peuvent désormais utiliser PowerInfer avec Llama 2 et Faclon 40B, avec la prise en charge de Mistral-7B bientôt disponible. La clé de la conception de PowerInfer est d'exploiter le degré élevé de localité inhérent à l'inférence LLM, qui se caractérise par une distribution en loi de puissance dans les activations neuronales. 
La figure 7 ci-dessous montre l'aperçu architectural de PowerInfer, y compris les composants hors ligne et en ligne. 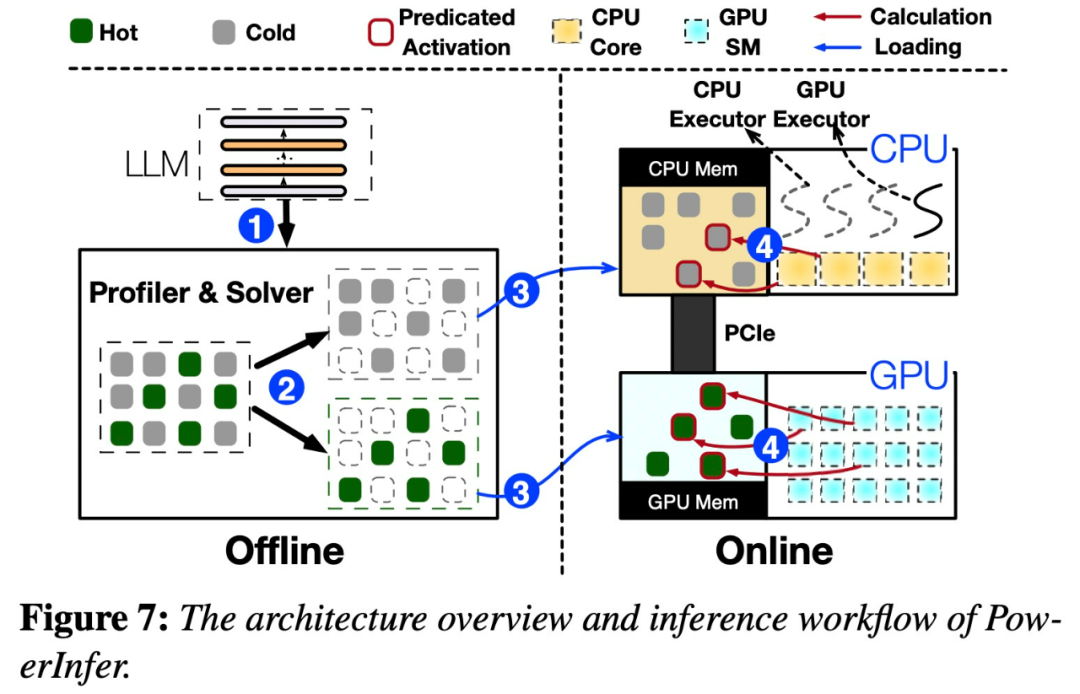
Cette distribution montre qu'un petit sous-ensemble de neurones, appelés neurones chauds, s'activent de manière cohérente selon les entrées, tandis que la majorité des neurones froids varient en fonction des entrées spécifiques. PowerInfer exploite ce mécanisme pour concevoir un moteur d'inférence hybride GPU-CPU. 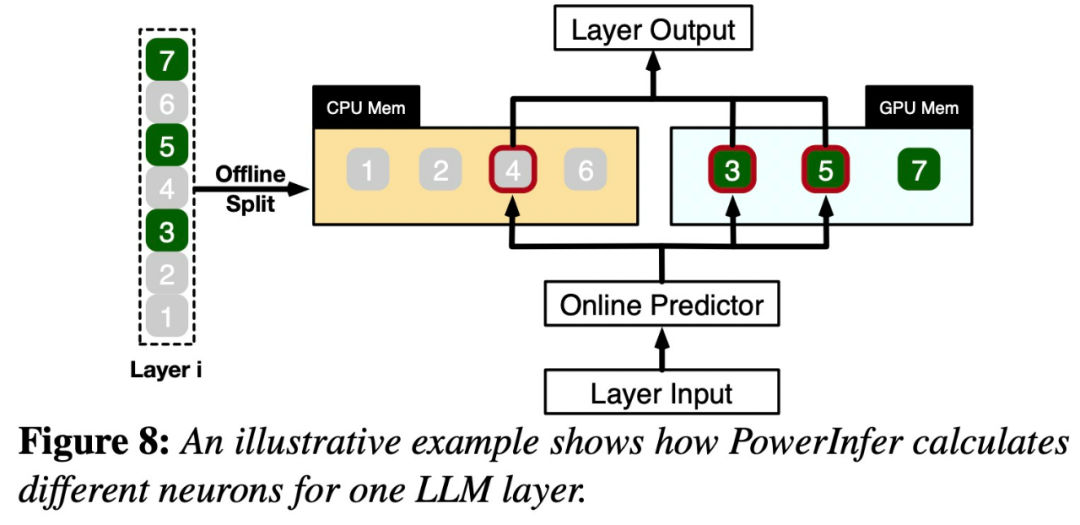
PowerInfer intègre en outre des prédicteurs adaptatifs et des opérateurs de parcimonie prenant en compte les neurones, optimisant ainsi l'efficacité de l'activation des neurones et de la parcimonie informatique. Après avoir vu cette étude, les internautes ont déclaré avec enthousiasme : ce n'est plus un rêve de faire fonctionner un grand modèle 175B avec une seule carte 4090. 
Pour plus d'informations, veuillez consulter l'article original. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Quelle pièce est le NFT ?
Quelle pièce est le NFT ?
 Méthode d'implémentation de la fonction js barrage
Méthode d'implémentation de la fonction js barrage
 Comment arrêter après avoir exécuté la commande nohup
Comment arrêter après avoir exécuté la commande nohup
 Comment basculer entre pleine largeur et demi-largeur
Comment basculer entre pleine largeur et demi-largeur
 Méthodes d'analyse des données
Méthodes d'analyse des données
 Quelle est la différence entre RabbitMQ et Kafka
Quelle est la différence entre RabbitMQ et Kafka
 qu'est-ce que la plage Python
qu'est-ce que la plage Python
 exigences de configuration matérielle du serveur Web
exigences de configuration matérielle du serveur Web








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



