Une interaction simple et efficace entre les humains et les robots quadrupèdes est le moyen de créer des robots assistants intelligents et performants, pointant vers un avenir où la technologie améliorera nos vies bien au-delà de notre imagination. Pour de tels systèmes d’interaction homme-robot, la clé est de donner au robot quadrupède la capacité de répondre aux commandes en langage naturel. Les modèles de langage à grande échelle (LLM) se sont développés rapidement récemment et ont montré leur potentiel pour effectuer une planification de haut niveau. Cependant, il est encore difficile pour LLM de comprendre les instructions de bas niveau, telles que les objectifs d'angle des articulations ou les couples moteurs, en particulier pour les robots à pattes qui sont intrinsèquement instables et nécessitent des signaux de commande à haute fréquence. Par conséquent, la plupart des travaux existants supposent que le LLM est doté d'une API de haut niveau qui détermine le comportement du robot, ce qui limite fondamentalement les capacités d'expression du système. Dans l'article CoRL 2023 « SayTap : Language to Quadrupedal Locomotion », Google DeepMind et l'Université de Tokyo ont proposé une nouvelle méthode qui utilise les modèles de contact avec les pieds comme lien entre les instructions du langage naturel humain et les commandes de bas niveau. Pont de contrôleur de mouvement. 
- Adresse papier : https://arxiv.org/abs/2306.07580
- Site Web du projet : https://saytap.github.io/
Modèle de contact du pied (pied modèle de contact) fait référence à l'ordre et à la manière dont un agent quadrupède pose ses pieds sur le sol lorsqu'il se déplace. Sur cette base, ils ont développé un système de robot quadrupède interactif qui permet aux utilisateurs de développer de manière flexible différents comportements de mouvement. Par exemple, les utilisateurs peuvent utiliser un langage simple pour commander au robot de marcher, courir, sauter ou effectuer d'autres actions. Leurs contributions incluent une conception d'invite LLM, une fonction de récompense et une méthode qui permet au contrôleur SayTap d'utiliser des distributions de modèles de contact réalisables. La recherche montre que le contrôleur SayTap peut réaliser plusieurs modes de mouvement, et ces capacités peuvent également être transférées au matériel réel du robot. La méthode SayTap utilise un modèle de mode contact, qui est un 4 Les pieds touchent le sol. De haut en bas, chaque rangée de la matrice donne respectivement le modèle de contact du pied de l'avant-pied gauche (FL), de l'avant-pied droit (FR), de l'arrière-pied gauche (RL) et de l'arrière-pied droit (RR). La fréquence de contrôle de SayTap est de 50 Hz, ce qui signifie que chaque 0 ou 1 dure 0,02 seconde. Cette étude définit le modèle de contact du pied souhaité comme une fenêtre coulissante cyclique de taille L_w et de forme 4 X L_w. Cette fenêtre coulissante extrait les quadruples drapeaux de mise à la terre du modèle de motif de contact, qui indiquent si le pied du robot était au sol ou dans les airs entre les instants t + 1 et t + L_w. La figure ci-dessous donne un aperçu de la méthode SayTap. 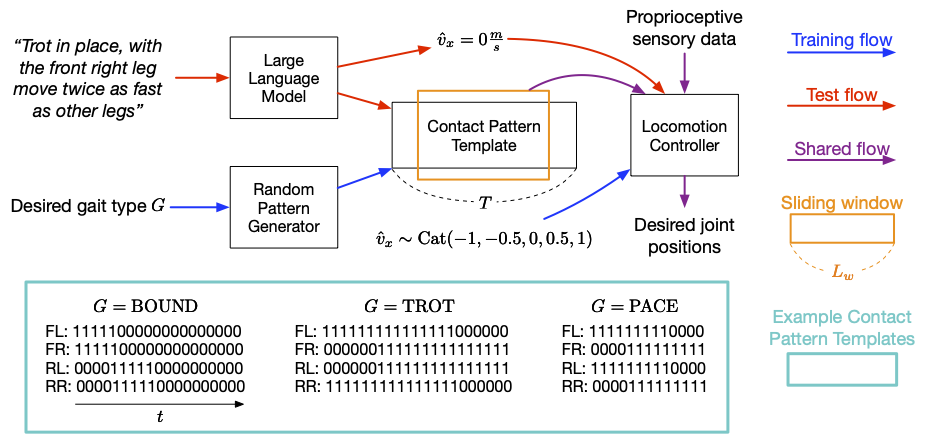
Présentation de la méthode SayTap SayTap introduit les modèles de contact du pied souhaités en tant que nouvelle interface entre les commandes utilisateur en langage naturel et les contrôleurs de mouvement. Le contrôleur de mouvement est utilisé pour effectuer des tâches principales (telles que suivre une vitesse spécifiée) et pour placer le pied du robot sur le sol à des moments précis afin que le modèle de contact du pied obtenu soit aussi proche que possible du modèle de contact souhaité. Pour ce faire, à chaque pas de temps, le contrôleur de mouvement prend en entrée le modèle de contact du pied souhaité, ainsi que des données proprioceptives (telles que les positions et les vitesses des articulations) et des entrées liées à la tâche (telles que les commandes de vitesse spécifiques à l'utilisateur). ). DeepMind a utilisé l'apprentissage par renforcement pour entraîner le contrôleur de mouvement et l'a représenté comme un réseau neuronal profond. Au cours de la formation du contrôleur, les chercheurs ont utilisé un générateur aléatoire pour échantillonner les modèles de contact du pied souhaités, puis ont optimisé la politique pour générer des actions de robot de bas niveau permettant d'obtenir les modèles de contact du pied souhaités. Au moment du test, LLM est utilisé pour traduire les commandes de l'utilisateur en modèles de contact avec le pied. 
SayTap utilise des modèles de contact avec les pieds comme pont entre les commandes utilisateur en langage naturel et les commandes de contrôle de bas niveau. SayTap prend en charge à la fois des instructions simples et directes (telles que « Avancez lentement en jogging ») et des commandes utilisateur vagues (telles que « Bonne nouvelle, nous allons faire un pique-nique ce week-end ! ») Grâce à des contrôleurs de mouvement basés sur l'apprentissage par renforcement, quatre Le). Le robot à pied réagit en fonction des commandes
La recherche montre qu'en utilisant des invites correctement conçues, LLM a la capacité de mapper avec précision les commandes de l'utilisateur dans des formats spécifiques de modèles de modèles de contact du pied, même si les commandes de l'utilisateur ne sont pas structurées ou floues. Lors de la formation, les chercheurs ont utilisé un générateur de modèles aléatoires pour générer plusieurs modèles de modèles de contact, qui ont différentes longueurs de modèle T et sont basés sur le rapport de contact pied-sol d'un type de démarche G donné dans un cycle, tel que le mouvement. Le contrôleur est capable d'apprendre sur une large gamme de distributions de modèles de mouvement et d'obtenir de meilleures capacités de généralisation. Voir l'article pour plus de détails En utilisant seulement trois pieds communs. Exemples de contexte en mode contact, LLM peut traduire avec précision diverses commandes humaines en modes de contact, même en généralisant à des situations où il n'y a pas de spécification explicite sur la façon dont le robot doit se comporter.
L'invite SayTap est simple et compacte :
(1) Une description générale pour décrire les tâches que le LLM doit accomplir
(2) Une définition de la démarche pour rappeler au LLM de prêter attention aux connaissances de base sur la démarche quadrupède et leur association avec les émotions ; (3) Définition du format de sortie ;
(4) Exemple de démonstration pour permettre à LLM d'apprendre des situations en contexte
Les chercheurs ont également défini cinq vitesses pour que le robot puisse avancer ou reculer, vite ou lentement, ou rester. toujours
Suivez des commandes simples et directesL'animation ci-dessous montre un exemple de SayTap exécutant avec succès une commande directe et claire. La commande n'est pas incluse dans les trois exemples contextuels, mais elle peut quand même guider. LLM pour exprimer les connaissances internes acquises au cours de la phase de pré-formation. Cela utilisera le « module de définition de la démarche » dans l'invite, qui est la deuxième invite du module d'invite ci-dessus.

 Suivez des commandes non structurées ou ambiguës
Suivez des commandes non structurées ou ambiguës
Mais la capacité de SayTap à gérer des instructions non structurées et ambiguës est encore plus intéressante. Il suffit de quelques indices pour relier certaines allures à des impressions émotionnelles générales, comme par exemple le robot qui saute de haut en bas après avoir entendu quelque chose d'excitant (comme « Allons pique-niquer ! »). De plus, il peut représenter avec précision des scènes. Par exemple, lorsqu’on lui dit que le sol est très chaud, le robot se déplacera rapidement pour empêcher ses pieds de toucher le moins possible le sol.



SayTap est un système interactif pour robots quadrupèdes qui permet aux utilisateurs de formuler de manière flexible différents comportements de locomotion. SayTap introduit les modèles de contact du pied souhaités comme interface entre le langage naturel et les contrôleurs de bas niveau. La nouvelle interface est à la fois simple et flexible, et permet au robot de suivre à la fois des instructions directes et des commandes qui n'indiquent pas explicitement comment le robot doit se comporter. Les chercheurs de DeepMind ont déclaré qu'une direction de recherche future majeure consisterait à tester si les commandes qui impliquent des sentiments spécifiques peuvent permettre au LLM de produire la démarche souhaitée. Dans le module de définition de la démarche des résultats ci-dessus, les chercheurs ont fourni une phrase reliant les émotions heureuses à la démarche sautée. Fournir plus d'informations pourrait améliorer la capacité de LLM à interpréter les commandes, telles que le décodage des sentiments implicites. Dans les évaluations expérimentales, le lien entre les émotions heureuses et une démarche rebondissante a permis au robot de se comporter énergiquement tout en suivant de vagues instructions humaines. Une autre direction de recherche future intéressante est l’introduction d’entrées multimodales, telles que la vidéo et l’audio. Théoriquement, les modèles de contact du pied traduits à partir de ces signaux conviennent également au flux de travail nouvellement proposé ici et devraient ouvrir la voie à des cas d'utilisation plus intéressants. Lien original : https://blog.research.google/2023/08/saytap-lingual-to-quadrupedal.htmlCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 langage c sinon utilisation de l'instruction
langage c sinon utilisation de l'instruction
 La différence entre serveur et hôte cloud
La différence entre serveur et hôte cloud
 Quels plug-ins sont nécessaires pour que vscode exécute du HTML ?
Quels plug-ins sont nécessaires pour que vscode exécute du HTML ?
 Comment supprimer des pages vierges dans Word
Comment supprimer des pages vierges dans Word
 Utilisation de #include en langage C
Utilisation de #include en langage C
 Linux voir la carte réseau
Linux voir la carte réseau
 Comment résoudre le problème du serveur DNS qui ne répond pas
Comment résoudre le problème du serveur DNS qui ne répond pas
 Comment lire des fichiers et les convertir en chaînes en Java
Comment lire des fichiers et les convertir en chaînes en Java








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



