


Optimiser à partir des racines des grands modèles. On peut dire que l'
Transformer architecture est la principale force derrière de nombreuses réussites récentes dans le domaine de l'apprentissage profond. Un moyen simple de créer une architecture Transformer approfondie consiste à empiler plusieurs « blocs » Transformer identiques les uns après les autres, mais chaque « bloc » est plus complexe et se compose de nombreux composants différents qui nécessitent un agencement et une combinaison spécifiques pour obtenir de bonnes performances.
Depuis la naissance de l'architecture Transformer en 2017, les chercheurs ont lancé un grand nombre d'études dérivées basées sur celle-ci, mais quasiment aucune modification n'a été apportée au "bloc" Transformer.
La question est donc la suivante : le bloc Transformer standard peut-il être simplifié ?
Dans un article récent, des chercheurs de l'ETH Zurich expliquent comment simplifier le bloc Transformer standard nécessaire au LLM sans affecter les propriétés de convergence et les performances des tâches en aval. Sur la base de la théorie de la propagation du signal et de preuves empiriques, ils ont découvert que certaines parties telles que les connexions résiduelles, les couches de normalisation (LayerNorm), les paramètres de projection et de valeur et les sous-blocs de sérialisation MLP (favorisant la disposition parallèle) peuvent être supprimés pour simplifier GPT- comme l'architecture du décodeur et le modèle BERT de style encodeur.
Les chercheurs ont étudié si les composants impliqués pouvaient être retirés sans affecter la vitesse d'entraînement et quelles modifications architecturales devraient être apportées au bloc Transformer.

Lien de l'article : https://arxiv.org/pdf/2311.01906.pdf
Lightning AI Le fondateur et chercheur en apprentissage automatique, Sebastian Raschka, appelle cette recherche son "article préféré de l'année" One :
Mais certains chercheurs se sont interrogés : "Il est difficile de commenter à moins d'avoir vu le processus de formation complet. S'il n'y a pas de couche de normalisation ni de connexion résiduelle, comment peut-il être supérieur à 1 "
Sebastian Raschka était d'accord : "Oui, l'architecture qu'ils ont expérimentée est relativement petite, Reste à savoir si cela peut être généralisé à un transformateur avec des milliards de paramètres. Mais il a quand même dit que le travail était impressionnant et le pensait." la suppression réussie des connexions résiduelles était tout à fait raisonnable (compte tenu de son schéma d'initialisation).
À cet égard, Yann LeCun, lauréat du prix Turing, a commenté : « Nous n'avons qu'effleuré la surface du domaine de l'architecture du deep learning. Il s'agit d'un espace de grande dimension, donc le volume est presque entièrement contenu dans la surface, mais nous n'avons fait qu'effleurer la surface Une petite partie de ‖

Pourquoi devons-nous simplifier le bloc Transformateur ?
Les chercheurs ont déclaré que simplifier le bloc Transformer sans affecter la vitesse d'entraînement est un problème de recherche intéressant.
Tout d'abord, les architectures de réseaux neuronaux modernes sont de conception complexe et contiennent de nombreux composants, et le rôle que jouent ces différents composants dans la dynamique de la formation des réseaux neuronaux et la manière dont ils interagissent les uns avec les autres n'est pas bien compris. Cette question concerne l’écart entre la théorie et la pratique du deep learning et est donc très importante.
La théorie de la propagation du signal s'est avérée influente dans la mesure où elle motive des choix de conception pratiques dans les architectures de réseaux neuronaux profonds. La propagation du signal étudie l'évolution des informations géométriques dans les réseaux de neurones lors de l'initialisation, capturées par le produit interne des représentations hiérarchiques à travers les entrées, et a conduit à de nombreux résultats impressionnants dans la formation de réseaux de neurones profonds.
Cependant, actuellement, cette théorie ne considère le modèle que lors de l'initialisation, et ne considère souvent que la passe avant initiale, elle ne peut donc pas révéler de nombreux problèmes complexes dans la dynamique d'entraînement des réseaux neuronaux profonds, tels que la contribution des connexions résiduelles à la vitesse d'entraînement. Bien que la propagation du signal soit essentielle à la motivation des modifications, les chercheurs ont déclaré qu'ils ne pouvaient pas dériver un module Transformer simplifié à partir de la seule théorie et qu'ils devaient s'appuyer sur des informations empiriques.
En termes d'applications pratiques, étant donné le coût élevé actuel de la formation et du déploiement de grands modèles Transformer, toute amélioration de l'efficacité des pipelines de formation et d'inférence de l'architecture Transformer représente d'énormes économies potentielles. Si le module Transformer peut être simplifié en supprimant les composants inutiles, cela peut à la fois réduire le nombre de paramètres et améliorer le débit du modèle.
Cet article mentionne également qu'après avoir supprimé la connexion résiduelle, les paramètres de valeur, les paramètres de projection et les sous-blocs de sérialisation, il peut correspondre au Transformer standard en termes de vitesse de formation et de performance des tâches en aval. Au final, les chercheurs ont réduit le nombre de paramètres de 16 % et ont observé une augmentation de 16 % du débit en termes de temps de formation et d'inférence.
Comment simplifier le bloc Transformateur ?
Sur la base de la théorie de la propagation du signal et d'observations empiriques, le chercheur a présenté comment générer le bloc transformateur le plus simple à partir du module pré-LN (comme indiqué ci-dessous).
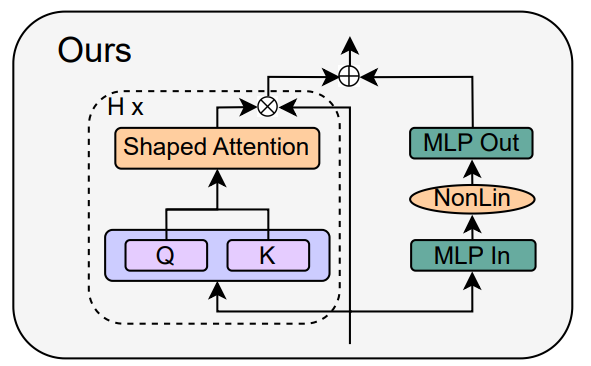
Dans chaque section du chapitre 4 de l'article, l'auteur présente comment supprimer un composant de bloc à la fois sans affecter la vitesse d'entraînement.
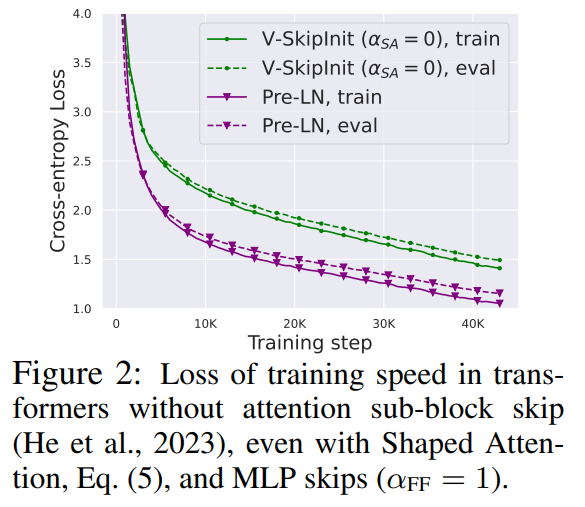
Toutes les expériences de cette partie utilisent un modèle GPT de 18 blocs de 768 largeurs avec décodeur causal uniquement sur l'ensemble de données CodeParrot Cet ensemble de données est suffisamment grand pour que lorsque l'auteur est en mode époque d'entraînement unique, l'écart de généralisation est. très petit (voir Figure 2), ce qui leur permet de se concentrer sur la vitesse d'entraînement.
Supprimer les connexions résiduelles
Les chercheurs ont d'abord envisagé de supprimer les connexions résiduelles dans le sous-bloc attention. Dans la notation de l'équation (1), cela équivaut à fixer α_SA à 0. La simple suppression des connexions résiduelles d'attention peut entraîner une dégradation du signal, c'est-à-dire un effondrement des rangs, entraînant une mauvaise capacité d'entraînement. Dans la section 4.1 de l'article, les chercheurs expliquent leur méthode en détail.
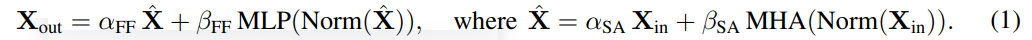
Supprimer les paramètres de projection/valeur
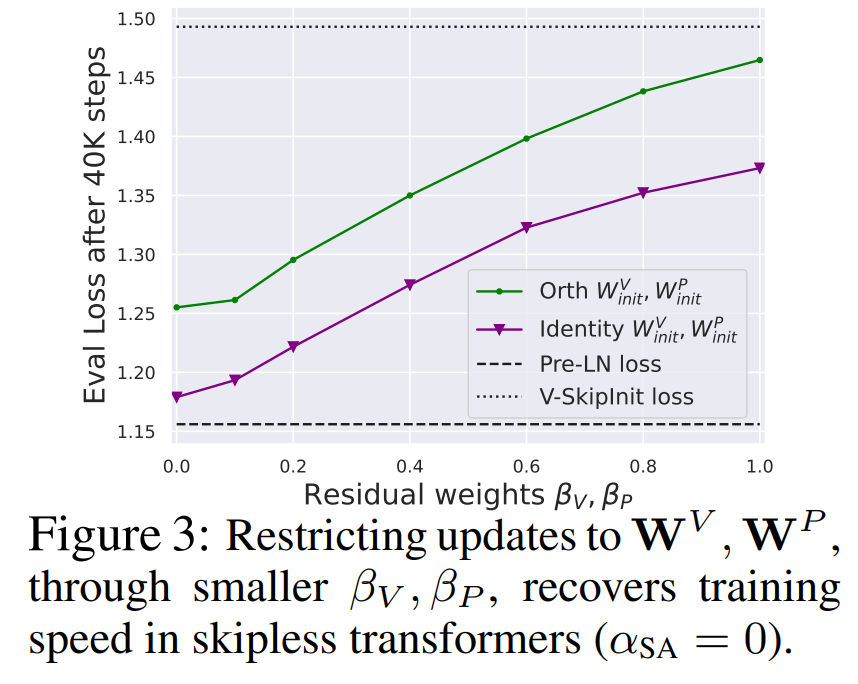
De la figure 3, on peut conclure que la suppression complète des paramètres de valeur et de projection W^V, W^P est possible avec une perte minimale de vitesse d'entraînement par mise à jour. C'est-à-dire que lorsque β_V = β_P = 0 et identité initialisée
, après le même nombre d'étapes de formation, cette étude peut fondamentalement atteindre les performances du bloc Pré-LN. Dans ce cas, W^V = W^P = I a W^V = W^P = I tout au long du processus de formation, c'est-à-dire que les valeurs et les paramètres de projection sont cohérents. Les auteurs présentent des méthodes détaillées dans la section 4.2.
Suppression des connexions résiduelles du sous-bloc MLP
Par rapport aux modules ci-dessus, la suppression des connexions résiduelles du sous-bloc MLP est plus difficile. Comme dans des recherches précédentes, les auteurs ont constaté qu'en utilisant Adam, sans connexions résiduelles MLP, rendre les activations plus linéaires via la propagation du signal entraînait toujours une diminution significative de la vitesse d'entraînement par mise à jour, comme le montre la figure 22.
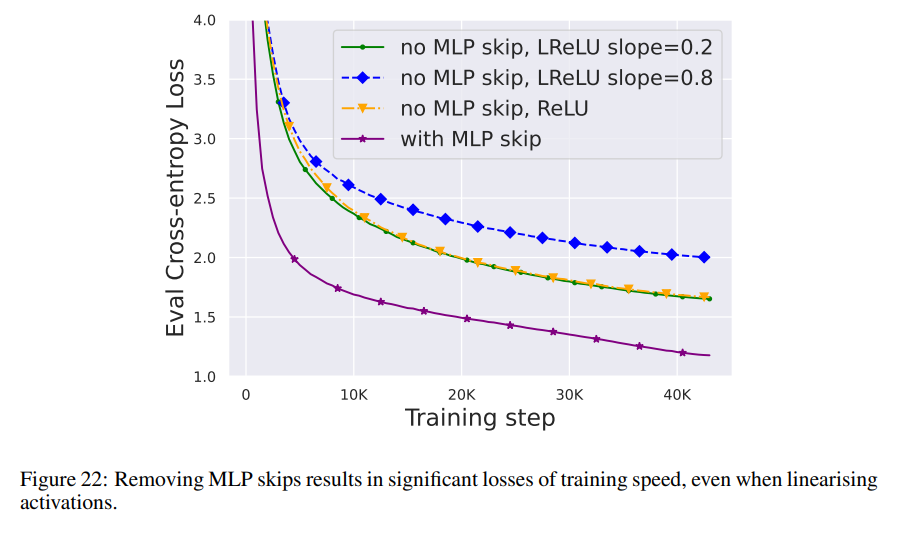
Ils ont également essayé diverses variantes de l'initialisation Looks Linear, notamment les poids gaussiens, les poids orthogonaux ou les poids d'identité, mais en vain. Par conséquent, ils utilisent des activations standards (par exemple ReLU) tout au long de leur travail et une initialisation dans des sous-blocs MLP.
Les auteurs se tournent vers le concept de sous-blocs parallèles MHA et MLP, qui s'est avéré populaire dans plusieurs modèles récents de grands transformateurs, tels que PALM et ViT-22B. Le bloc transformateur parallèle est illustré dans la figure ci-dessous.
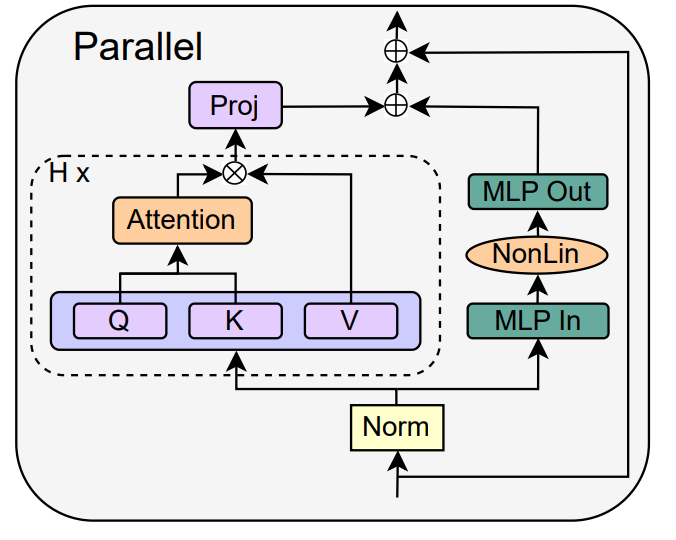
L'auteur détaille l'opération spécifique de suppression des connexions résiduelles du sous-bloc MLP dans la section 4.3 de l'article.
Supprimer la couche de normalisation
La dernière chose à supprimer est la couche de normalisation, vous obtenez donc le bloc le plus simple dans le coin supérieur droit de la figure 1. Du point de vue de l'initialisation de la propagation du signal, les auteurs peuvent supprimer la couche de normalisation à n'importe quelle étape de la simplification dans cette section. Leur idée est que la normalisation dans le bloc Pre-LN réduit implicitement le poids des branches résiduelles, et cet effet bénéfique peut être répliqué sans la couche de normalisation via un autre mécanisme : soit lors de l'utilisation de connexions résiduelles, réduire explicitement le poids de la branche résiduelle , ou biaiser la matrice d'attention vers l'identité/convertir la non-linéarité MLP en « plus » de linéarité.
Étant donné que l'auteur a pris en compte ces mécanismes lors du processus de modification (comme la réduction du poids de MLP β_FF et Shaped Attention), une normalisation n'est pas nécessaire. Les auteurs présentent plus d'informations dans la section 4.4.
Résultats expérimentaux
Expansion en profondeur
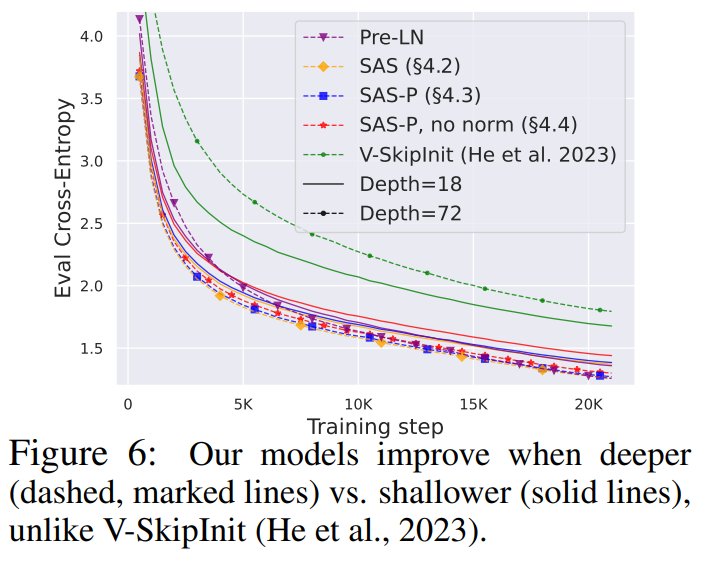
Étant donné que la théorie de la propagation du signal se concentre généralement sur de grandes profondeurs, une dégradation du signal se produit généralement dans ce cas. Une question naturelle se pose donc : la vitesse d’entraînement améliorée obtenue grâce à notre bloc transformateur simplifié s’adapte-t-elle également à de plus grandes profondeurs ?
On peut observer sur la figure 6 qu'après avoir étendu la profondeur de 18 blocs à 72 blocs, les performances du modèle et du transformateur pré-LN dans cette étude sont améliorées, ce qui montre que le modèle simplifié dans cette étude n'est pas seulement plus rapide à l'entraînement Plus rapide et capable de tirer parti des capacités supplémentaires fournies par une plus grande profondeur. En fait, lorsque la normalisation est utilisée, les trajectoires par mise à jour du bloc simplifié et du pré-LN dans cette étude sont presque impossibles à distinguer à différentes profondeurs.
BERT
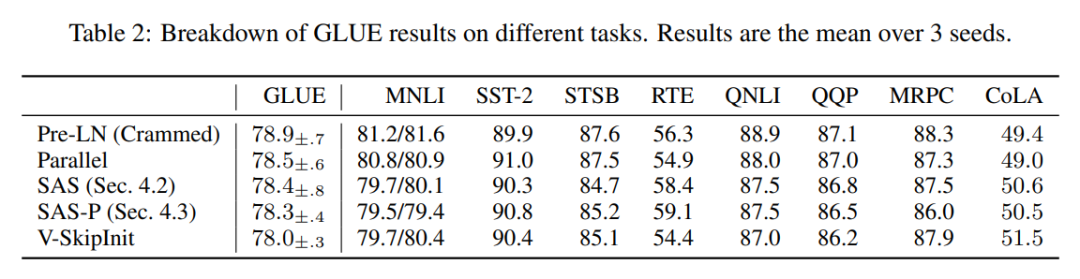
Ensuite, les auteurs montrent que leurs performances de bloc simplifiées s'appliquent à différents ensembles de données et architectures en plus des décodeurs autorégressifs, ainsi qu'aux tâches en aval. Ils ont choisi le paramètre populaire du modèle BERT à encodeur bidirectionnel uniquement pour la modélisation du langage masqué et ont utilisé le benchmark GLUE en aval.
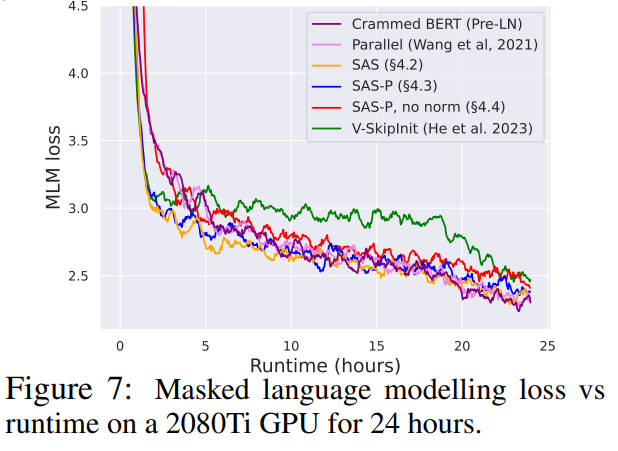
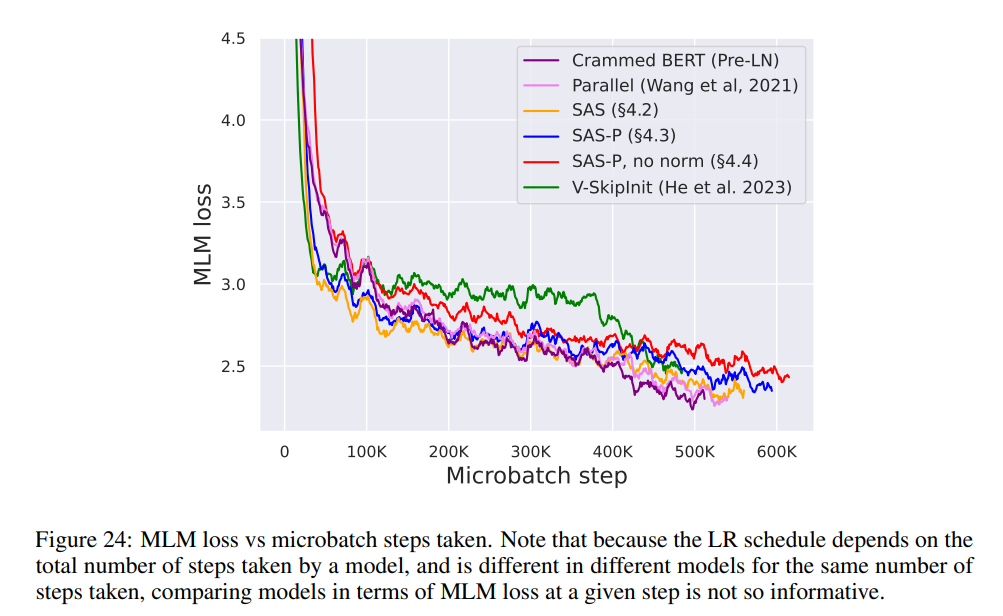
Comme le montre la figure 7, dans les 24 heures suivant l'exécution, les blocs simplifiés de cette étude sont comparables à la vitesse de pré-entraînement de la tâche de modélisation de langage masqué par rapport à la ligne de base (Crammed) Pre-LN. En revanche, supprimer les connexions résiduelles sans modifier les valeurs et les projections entraîne là encore une diminution significative de la vitesse d'entraînement. Dans la figure 24, les auteurs fournissent un diagramme équivalent de l’étape microbatch.
De plus, dans le tableau 1, les chercheurs ont constaté que leur méthode, après avoir été affinée sur le benchmark GLUE, fonctionnait de manière comparable à celle du benchmark Crammed BERT.
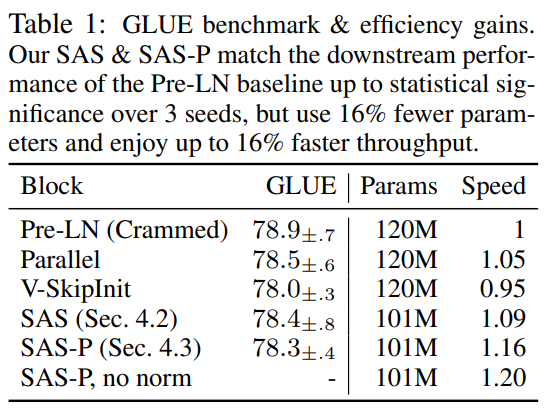
Ils répartissent les tâches en aval dans le tableau 2. Pour une comparaison équitable, ils ont utilisé le même protocole de réglage fin que Geiping & Goldstein (2023) (5 époques, hyperparamètres constants pour chaque tâche, régularisation des abandons).
Efficacité améliorée
Dans le tableau 1, les chercheurs ont également détaillé le nombre de paramètres et la vitesse de formation des modèles utilisant différents blocs Transformer dans la tâche de modélisation de langage masqué. Ils ont calculé la vitesse comme le rapport entre le nombre d'étapes de microbatch effectuées pendant 24 heures de pré-entraînement et le BERT pré-LN Crammed de base. La conclusion est que le modèle utilise 16 % de paramètres en moins et que SAS-P et SAS sont respectivement 16 % et 9 % plus rapides par itération que le bloc Pre-LN.
On peut noter que dans l'implémentation ici, le bloc parallèle n'est que 5 % plus rapide que le bloc Pre-LN, tandis que la vitesse d'entraînement observée par Chowdhery et al. (2022) est 15 % plus rapide, ce qui montre qu'avec un mise en œuvre plus optimisée, il est possible que la vitesse globale d'entraînement puisse être encore augmentée. Comme Geiping & Goldstein (2023), cette implémentation utilise également la technologie de fusion d'opérateurs automatiques dans PyTorch (Sarofeen et al., 2022).
Entraînement plus long
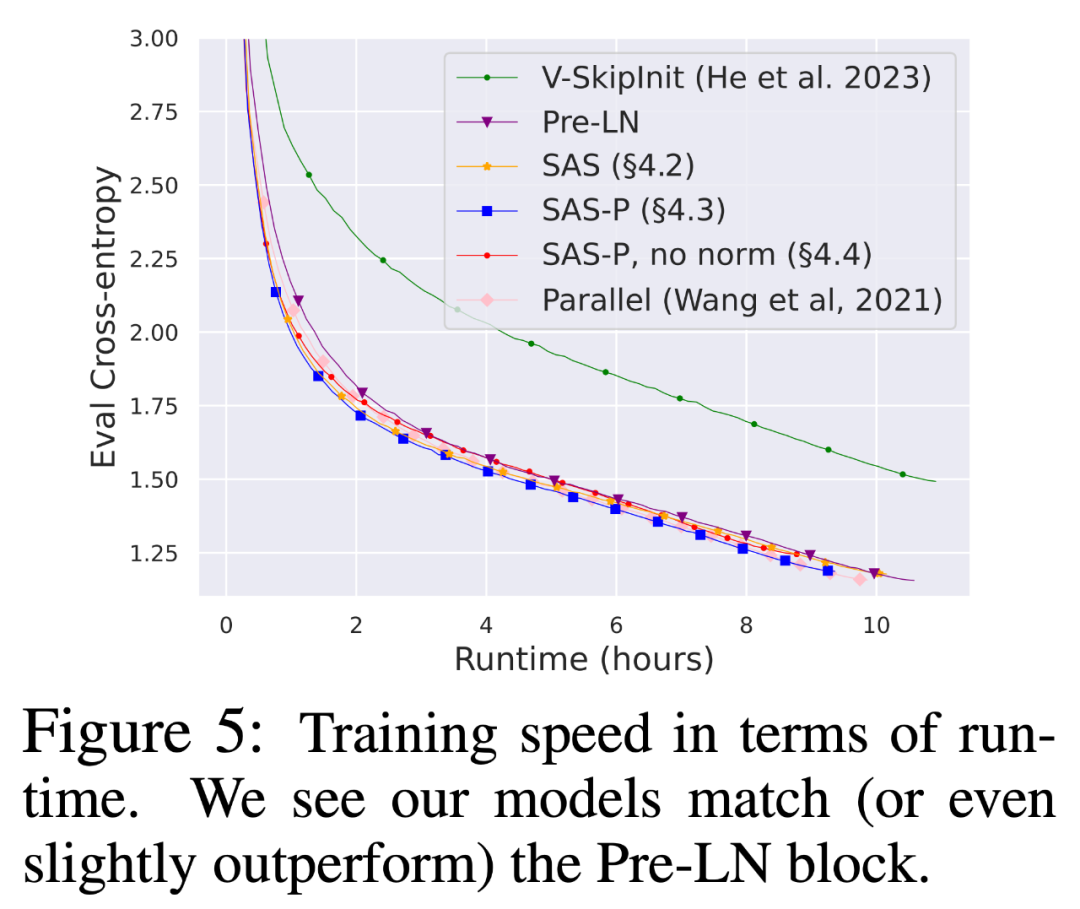
Enfin, étant donné la tendance actuelle à entraîner des modèles plus petits sur plus de données pendant des périodes plus longues, les chercheurs ont discuté de la question de savoir si les blocs simplifiés pouvaient toujours réaliser l'entraînement des blocs pré-LN après une longue vitesse d'entraînement. Pour ce faire, ils utilisent le modèle de la figure 5 sur CodeParrot et s'entraînent avec 3x tokens. Pour être précis, la formation prend environ 120 000 étapes (au lieu de 40 000 étapes) avec une taille de lot de 128 et une longueur de séquence de 128, ce qui donne environ 2 milliards de jetons.
Comme le montre la figure 8, lorsque davantage de jetons sont utilisés pour la formation, la vitesse de formation des blocs de code SAS et SAS-P simplifiés est toujours comparable, voire meilleure, que celle des blocs de code PreLN.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment définir les numéros de page dans Word
Comment définir les numéros de page dans Word
 Comment obtenir un jeton
Comment obtenir un jeton
 Quels sont les systèmes d'exploitation cloud ?
Quels sont les systèmes d'exploitation cloud ?
 Refroidissement d'un ordinateur portable ASUS
Refroidissement d'un ordinateur portable ASUS
 Utilisation de la fonction d'écriture
Utilisation de la fonction d'écriture
 Qu'est-ce que le réseau local
Qu'est-ce que le réseau local
 La différence entre les threads et les processus
La différence entre les threads et les processus
 De quels mécanismes de mise en cache dispose PHP ?
De quels mécanismes de mise en cache dispose PHP ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



