


Nous discuterons des moyens de créer un système de génération augmentée de récupération (RAG) en utilisant le grand langage multimodal open source. Notre objectif est d'y parvenir sans compter sur l'index LangChain ou Lllama pour éviter d'ajouter davantage de dépendances au framework.

Dans le domaine de l'intelligence artificielle, l'émergence de la technologie de génération augmentée et de récupération (RAG) a apporté des améliorations révolutionnaires aux grands modèles de langage (Large Language Models). L’essence de RAG est d’améliorer la réactivité de l’intelligence artificielle en permettant aux modèles de récupérer dynamiquement des informations en temps réel à partir de sources externes. L’introduction de cette technologie permet à l’IA de répondre plus spécifiquement aux besoins des utilisateurs. En récupérant et en fusionnant des informations provenant de sources externes, RAG est en mesure de générer des réponses plus précises et plus complètes, offrant ainsi aux utilisateurs un contenu plus précieux. Cette amélioration des capacités a ouvert des perspectives plus larges aux domaines d'application de l'intelligence artificielle, notamment le service client intelligent, la recherche intelligente et les systèmes de questions et réponses de connaissances. L'émergence de RAG marque le développement ultérieur des modèles de langage, apportant
à l'intelligence artificielle. Cette architecture combine de manière transparente le processus de récupération dynamique avec des capacités de génération, permettant à l'intelligence artificielle de s'adapter aux informations changeantes dans divers domaines. Contrairement au réglage fin et au recyclage, RAG fournit une solution rentable qui permet à l'IA d'obtenir les informations les plus récentes et pertinentes sans modifier l'ensemble du modèle. Cette combinaison de capacités donne à RAG un avantage pour répondre à des environnements d'information en évolution rapide.
1. Améliorer la précision et la fiabilité :
résout le problème de l'imprévisibilité des grands modèles de langage (LLM) en les dirigeant vers des sources de connaissances fiables, réduisant ainsi le risque de fournir les informations fausses ou obsolètes rendent les réponses plus précises et plus fiables.
2. Augmenter la transparence et la confiance :
Les modèles d'IA générative comme LLM manquent souvent de transparence, ce qui rend difficile pour les gens de faire confiance à leurs résultats. RAG répond aux préoccupations concernant la partialité, la fiabilité et la conformité en offrant un meilleur contrôle.
3. Réduire les hallucinations :
LLM est sujet à des réactions hallucinatoires - fournissant des informations cohérentes mais inexactes ou fabriquées. RAG réduit le risque de conseils trompeurs aux secteurs clés en s’appuyant sur des sources faisant autorité pour garantir la réactivité.
4. Adaptabilité rentable :
RAG fournit un moyen rentable d'améliorer la production de l'IA sans nécessiter de recyclage/réglage approfondi. Les informations peuvent être maintenues à jour et pertinentes en récupérant dynamiquement des détails spécifiques selon les besoins, garantissant ainsi l'adaptabilité de l'IA à l'évolution des informations.
Le multimodal implique d'avoir plusieurs entrées et de les combiner en une seule sortie, en prenant CLIP comme exemple : les données d'entraînement de CLIP sont des paires texte-image, et grâce à l'apprentissage contrastif, le modèle Capacité à apprendre les relations de correspondance entre les paires texte-image.
Ce modèle génère le même vecteur d'intégration (très similaire) pour différentes entrées qui représentent la même chose.
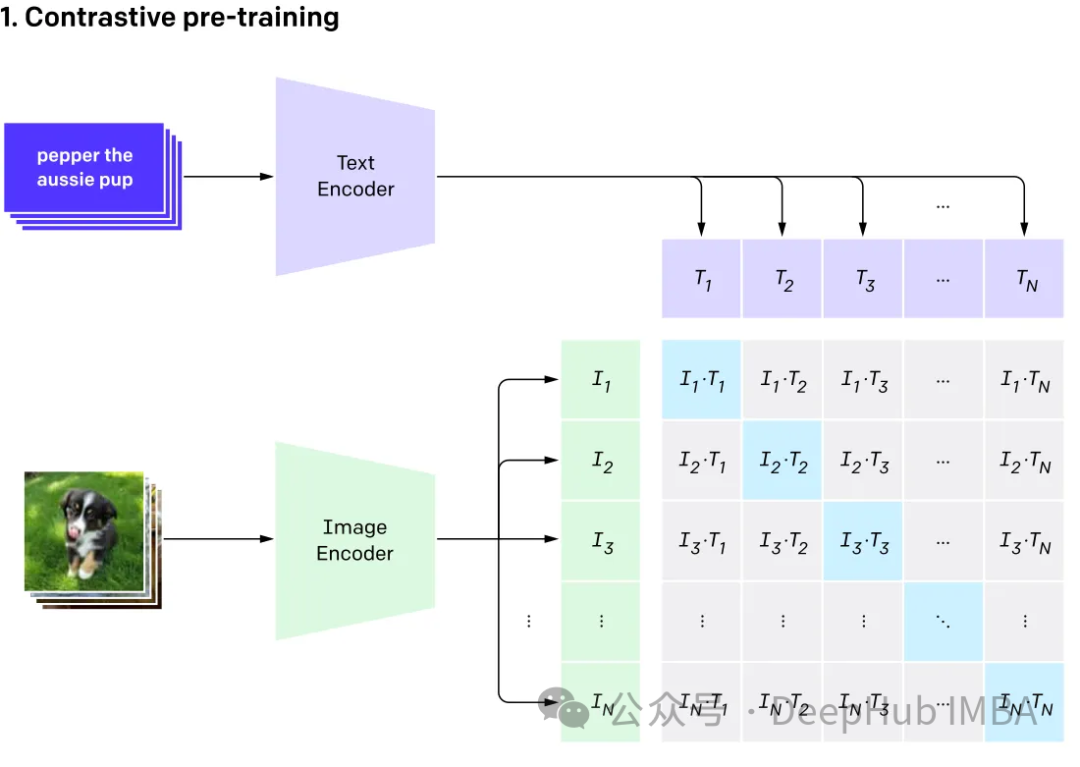
GPT4V et Gemini Vision explorer et intégrer divers types de données (y compris les images, le texte, langage, audio, etc.) modèle de langage multimodal (MLLM). Bien que les grands modèles de langage (LLM) comme GPT-3, BERT et RoBERTa fonctionnent bien sur les tâches basées sur du texte, ils sont confrontés à des défis dans la compréhension et le traitement d'autres types de données. Pour remédier à cette limitation, les modèles multimodaux combinent différentes modalités pour permettre une compréhension plus complète des différentes données.
Grand modèle de langage multimodal Il va au-delà des méthodes traditionnelles basées sur le texte. En prenant GPT-4 comme exemple, ces modèles peuvent traiter de manière transparente divers types de données, notamment des images et du texte, pour comprendre les informations de manière plus complète.
Ici, nous utiliserons Clip pour intégrer des images et du texte, stockerons ces intégrations dans la base de données vectorielles ChromDB. Le grand modèle sera ensuite exploité pour participer à des sessions de discussion avec les utilisateurs sur la base des informations récupérées.
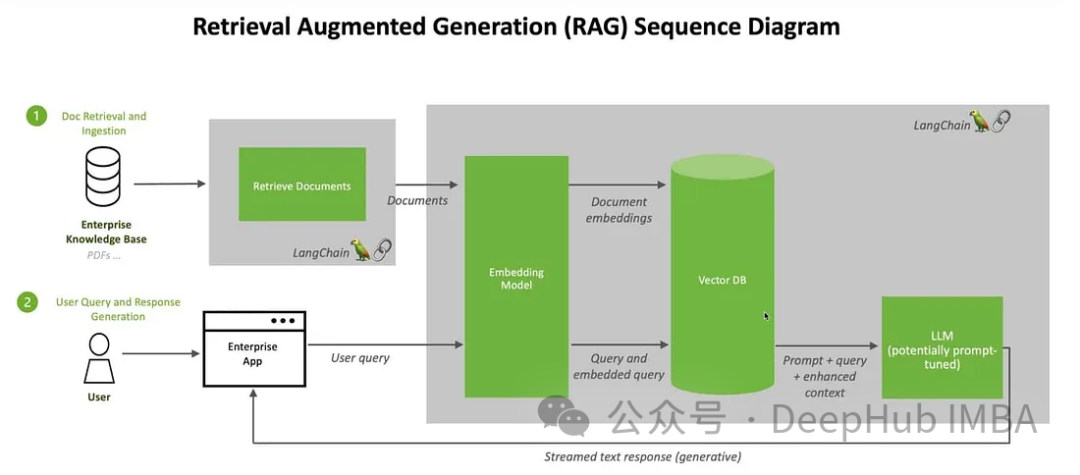
Nous utiliserons des images de Kaggle et des informations de Wikipédia pour créer un chatbot expert en fleurs
Nous installons d'abord le package :
! pip install -q timm einops wikipedia chromadb open_clip_torch !pip install -q transformers==4.36.0 !pip install -q bitsandbytes==0.41.3 accelerate==0.25.0
Les étapes pour prétraiter les données sont très simples mettez simplement les images et le texte dans un dossier
可以随意使用任何矢量数据库,这里我们使用ChromaDB。
import chromadb from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction from chromadb.utils.data_loaders import ImageLoader from chromadb.config import Settings client = chromadb.PersistentClient(path="DB") embedding_function = OpenCLIPEmbeddingFunction() image_loader = ImageLoader() # must be if you reads from URIs
ChromaDB需要自定义嵌入函数
from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction):def __call__(self, input: Documents) -> Embeddings:# embed the documents somehow or imagesreturn embeddings
这里将创建2个集合,一个用于文本,另一个用于图像
collection_images = client.create_collection(name='multimodal_collection_images', embedding_functinotallow=embedding_function, data_loader=image_loader) collection_text = client.create_collection(name='multimodal_collection_text', embedding_functinotallow=embedding_function, ) # Get the Images IMAGE_FOLDER = '/kaggle/working/all_data' image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')]) ids = [str(i) for i in range(len(image_uris))] collection_images.add(ids=ids, uris=image_uris) #now we have the images collection对于Clip,我们可以像这样使用文本检索图像
from matplotlib import pyplot as plt retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3) for img in retrieved['data'][0]:plt.imshow(img)plt.axis("off")plt.show()
也可以使用图像检索相关的图像

文本集合如下所示
# now the text DB from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')]) list_of_text = [] for text in text_pth:with open(text, 'r') as f:text = f.read()list_of_text.append(text) ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))] ids_txt_list collection_text.add(documents = list_of_text,ids =ids_txt_list )然后使用上面的文本集合获取嵌入
results = collection_text.query(query_texts=["What is the bellflower?"],n_results=1 ) results
结果如下:
{'ids': [['id0']],'distances': [[0.6072186183744086]],'metadatas': [[None]],'embeddings': None,'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']],'uris': None,'data': None}或使用图片获取文本
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]

上图的结果如下:
A rose is either a woody perennial flowering plant of the genus Rosa (), in the family Rosaceae (), or the flower it bears. There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Their flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant. Roses have acquired cultural significance in many societies. Rose plants range in size from compact, miniature roses, to climbers that can reach seven meters in height. Different species hybridize easily, and this has been used in the development of the wide range of garden roses.
这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。
from huggingface_hub import hf_hub_download hf_hub_download(repo_, filename="configuration_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="configuration_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="processing_llava.py", local_dir="./", force_download=True)
我们是用visheratin/LLaVA-3b
from modeling_llava import LlavaForConditionalGeneration import torch model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b") model = model.to("cuda")加载tokenizer
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")然后定义处理器,方便我们以后调用
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor image_processor = OpenCLIPImageProcessor(model.config.preprocess_config) processor = LlavaProcessor(image_processor, tokenizer)
下面就可以直接使用了
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?' query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0] plt.imshow(raw_image) plt.show() imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3) for img in imgs['data'][0][1:]:plt.imshow(img)plt.axis("off")plt.show()得到的结果如下:

结果还包含了我们需要的大部分信息

这样我们整合就完成了,最后就是创建聊天模板,
prompt = """system A chat between a curious human and an artificial intelligence assistant. The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions. The assistant does not hallucinate and pays very close attention to the details. user <image> {question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document. assistant """.format(questinotallow='question', article=doc)</image>如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
//m.sbmmt.com/link/71eee742e4c6e094e6af364597af3f05
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment résoudre le problème du serveur DNS qui ne répond pas
Comment résoudre le problème du serveur DNS qui ne répond pas
 Comment utiliser DataReader
Comment utiliser DataReader
 Le moteur de stockage de MySQL pour modifier les tables de données
Le moteur de stockage de MySQL pour modifier les tables de données
 Tableau de comparaison des codes ASCII
Tableau de comparaison des codes ASCII
 La principale raison pour laquelle les ordinateurs utilisent le binaire
La principale raison pour laquelle les ordinateurs utilisent le binaire
 Utilisation d'indexof en Java
Utilisation d'indexof en Java





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



