



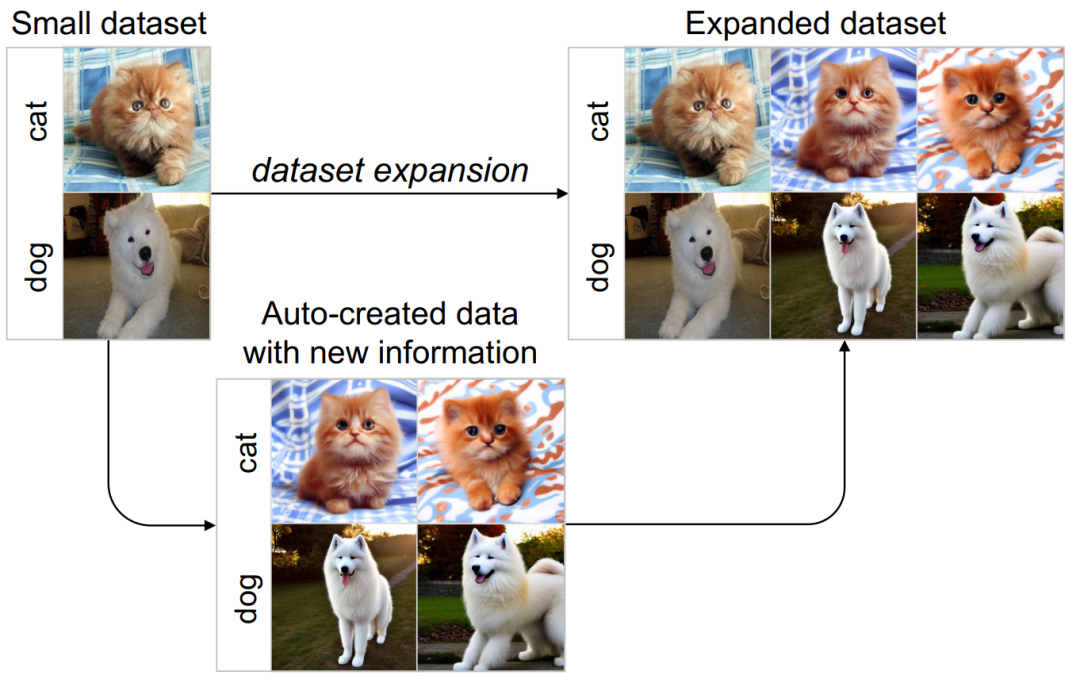
Comme nous le savons tous, les performances des réseaux de neurones profonds dépendent en grande partie de la quantité et de la qualité des données d'entraînement, ce qui rend difficile l'application généralisée de l'apprentissage profond à des tâches de petites données. Par exemple, dans des scénarios d’application de petites données dans des domaines médicaux et autres, la collecte et l’étiquetage manuels d’ensembles de données à grande échelle prennent souvent du temps et sont laborieux. Pour résoudre ce problème de rareté des données et minimiser les coûts de collecte de données, cet article explore un nouveau paradigme d'augmentation des ensembles de données, qui vise à générer automatiquement de nouvelles données pour étendre le petit ensemble de données de la tâche cible en un Big Data plus grand et plus informatif. ensembles. Ces ensembles de données étendus sont dédiés à l'amélioration des performances et des capacités de généralisation du modèle, et peuvent être utilisés pour former différentes structures de réseau
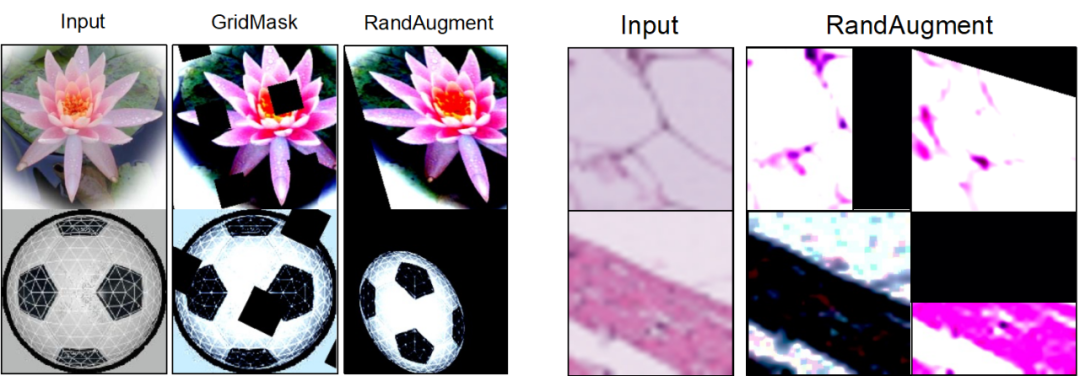
Ce travail a révélé que la simple utilisation des méthodes existantes ne peut pas bien étendre l'ensemble de données. (1) L'amélioration des données aléatoires modifie principalement les caractéristiques visuelles de la surface de l'image, mais ne peut pas créer d'images avec un nouveau contenu d'objet (le lotus dans l'image ci-dessous est toujours le même, aucun nouveau lotus n'est généré), donc la quantité d'informations introduites est limité. Ce qui est plus grave, c'est que l'amélioration aléatoire des données peut recadrer la position de la lésion (changer) de l'image médicale, entraînant la réduction d'informations importantes sur l'échantillon et même la génération de données bruitées. (2) L'utilisation directe de modèles génératifs (diffusion) pré-entraînés pour l'amplification des ensembles de données ne peut pas vraiment améliorer les performances du modèle sur la tâche cible. En effet, les données de pré-entraînement de ces modèles génératifs présentent souvent de grandes différences de distribution avec les données cibles, ce qui entraîne un certain écart de distribution et de catégorie entre les données qu'ils génèrent et la tâche cible, et il est impossible de garantir que les données générées. les échantillons ont les étiquettes de catégorie correctes et sont utiles pour la formation du modèle.
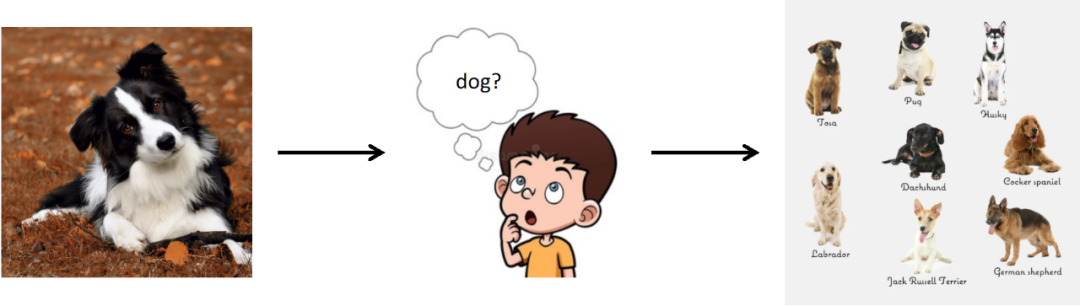
Pour augmenter plus efficacement les ensembles de données, les chercheurs ont exploré l'apprentissage associatif humain. Lorsque les humains ont une connaissance préalable d'un objet, ils peuvent facilement imaginer différentes variations de l'objet, telles que des variations du chien dans différents types, couleurs, formes ou arrière-plans dans l'image ci-dessous. Ce processus d'apprentissage imaginatif est très instructif pour l'augmentation des ensembles de données car il va au-delà de la simple perturbation de l'apparence des animaux dans l'image, mais applique de riches connaissances préalables pour créer des images variantes avec de nouvelles informations
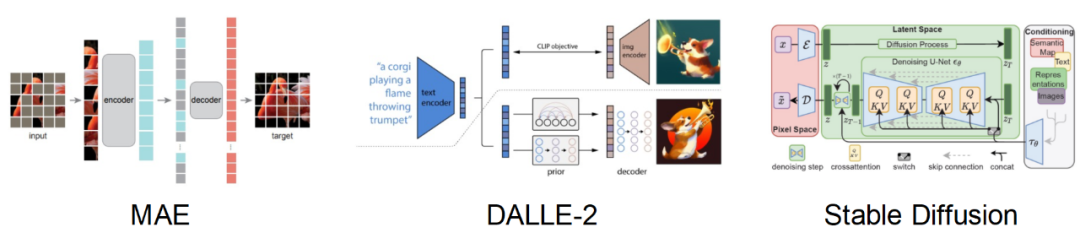
Cependant, nous ne pouvons pas. modéliser directement les humains comme modèle préalable pour l’imagination des données. Heureusement, les modèles génératifs récents (tels que Stable Diffusion, DALL-E2) ont démontré une puissante capacité à s'adapter à la distribution d'ensembles de données à grande échelle et peuvent générer des images riches et réalistes. Cela a inspiré cet article à utiliser des modèles génératifs pré-entraînés comme modèles antérieurs, en tirant parti de leurs solides connaissances préalables pour effectuer une association et une amplification efficaces de données sur de petits ensembles de données.
Basé sur les idées ci-dessus, ce travail propose un nouveau cadre d'imagination guidée (GIF). Cette méthode peut améliorer efficacement les performances de classification et la capacité de généralisation des réseaux neuronaux profonds sur les tâches d'imagerie naturelle et médicale, et réduire considérablement les coûts énormes entraînés par la collecte et l'annotation manuelles des données. Dans le même temps, l’ensemble de données élargi contribue également à promouvoir l’apprentissage par transfert du modèle et à atténuer le problème de la longue traîne.
Voyons ensuite comment ce nouveau paradigme d'amplification des ensembles de données est conçu.
Défis et normes directrices pour l'amplification des ensembles de données Il y a deux défis clés dans la conception d'une méthode d'amplification d'ensemble de données : (1) Comment faire en sorte que les échantillons générés aient les étiquettes de catégorie correctes ? (2) Comment s'assurer que les échantillons générés contiennent de nouvelles informations pour promouvoir la formation de modèles ? Pour relever ces deux défis, ce travail a découvert deux critères directeurs d'amplification grâce à des expériences approfondies : (1) amélioration de l'information cohérente par catégorie (2) amélioration de la diversité des échantillons ;

Method Framework Basé sur les normes de guidage d'amplification découvertes, ce travail propose le cadre d'augmentation guidée de l'imagination (GIF). Pour chaque échantillon de départ x, GIF extrait d'abord l'échantillon de caractéristique f à l'aide de l'extracteur de caractéristiques du modèle génératif précédent, et effectue une perturbation du bruit sur la caractéristique : 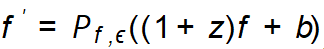 . Le moyen le plus simple de définir le bruit (z, b) consiste à utiliser un bruit aléatoire gaussien, mais cela ne peut pas garantir que les échantillons générés ont l'étiquette de classe correcte et apportent plus d'informations. Par conséquent, pour une amplification efficace de l'ensemble de données, GIF optimise la perturbation du bruit en fonction de sa directive d'amplification découverte, c'est-à-dire
. Le moyen le plus simple de définir le bruit (z, b) consiste à utiliser un bruit aléatoire gaussien, mais cela ne peut pas garantir que les échantillons générés ont l'étiquette de classe correcte et apportent plus d'informations. Par conséquent, pour une amplification efficace de l'ensemble de données, GIF optimise la perturbation du bruit en fonction de sa directive d'amplification découverte, c'est-à-dire 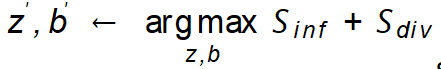 .
.
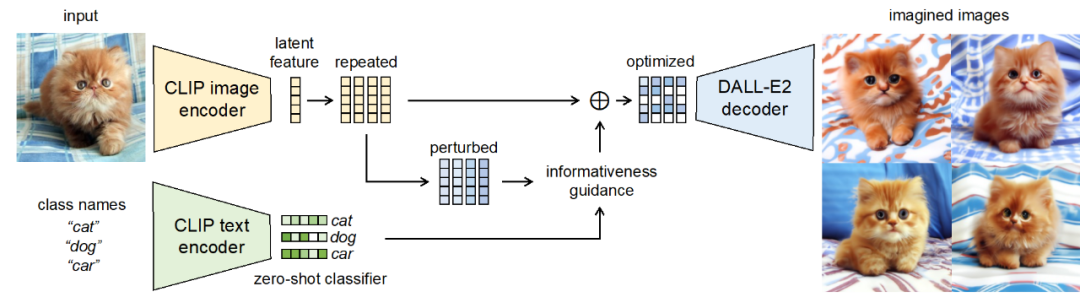
Les normes de guidage d'amplification utilisées sont mises en œuvre comme suit. Indice de quantité d'informations cohérent avec la classe : 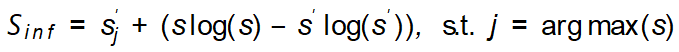 ; indice de diversité des échantillons :
; indice de diversité des échantillons : 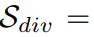
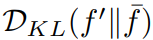 . En maximisant ces deux indicateurs, GIF peut optimiser efficacement la perturbation du bruit, générant ainsi des échantillons qui maintiennent la cohérence des catégories et apportent un plus grand contenu d'informations.
. En maximisant ces deux indicateurs, GIF peut optimiser efficacement la perturbation du bruit, générant ainsi des échantillons qui maintiennent la cohérence des catégories et apportent un plus grand contenu d'informations.
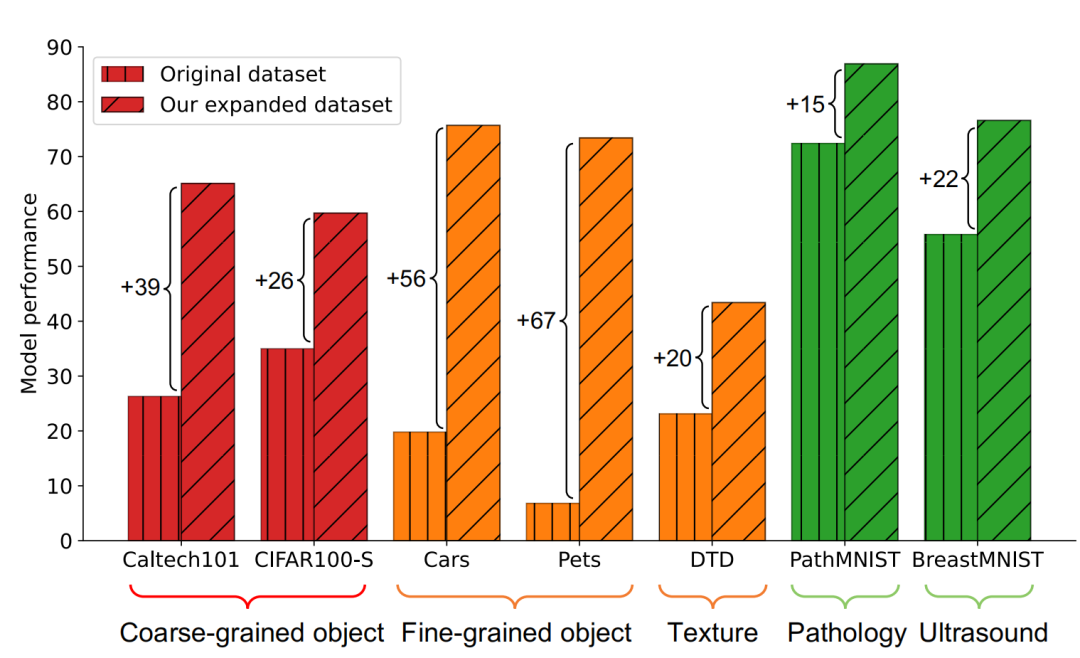
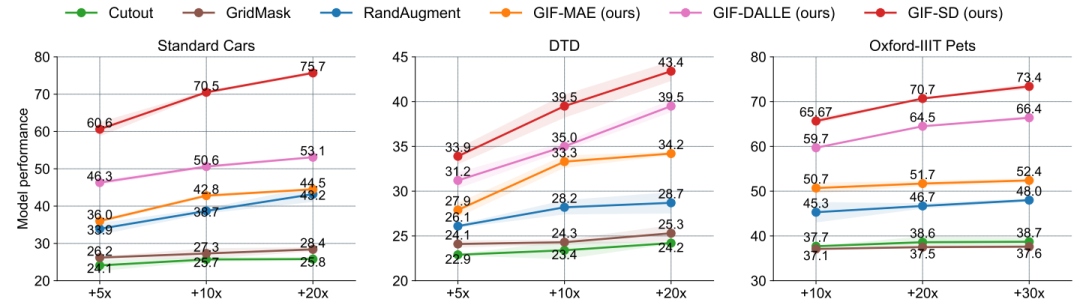
Validité d'amplification GIF a une validité d'amplification plus forte : GIF-SD améliore la précision de la classification de 36,9 % en moyenne sur 6 ensembles de données naturelles et sur 3 ensembles de données médicales. La précision moyenne de la classification sur l'ensemble de données est amélioré de 13,5%.
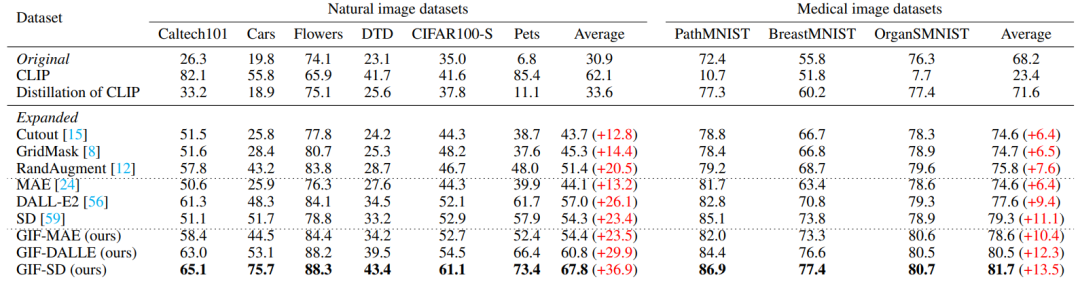
Efficacité d'amplification GIF a une efficacité d'amplification plus forte : sur les ensembles de données Cars et DTD, l'effet de l'utilisation de GIF-SD pour une amplification 5 fois dépasse même celui de l'utilisation d'une augmentation aléatoire des données. L'effet de 20 -amplification fois.
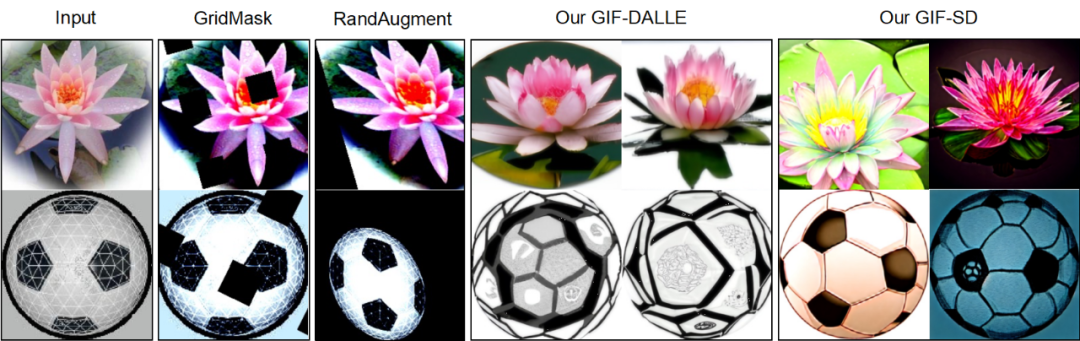
Résultats de visualisation Les méthodes d'augmentation de données existantes ne peuvent pas générer de nouveau contenu d'image, tandis que GIF peut mieux générer des échantillons avec un nouveau contenu.
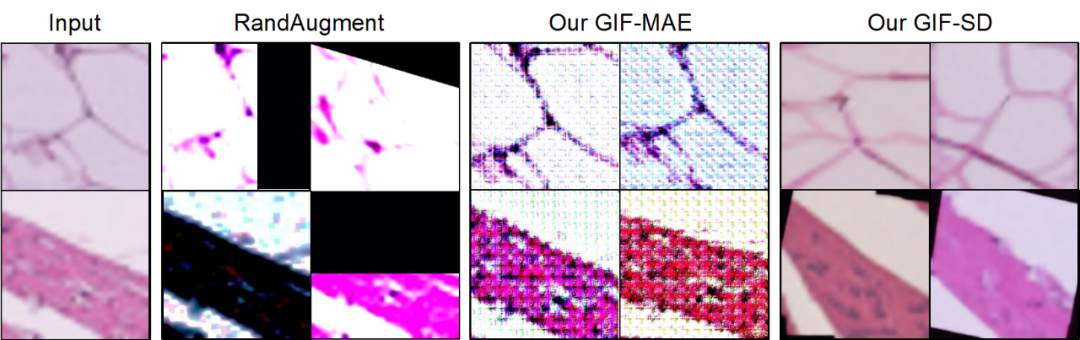
Les méthodes d'amélioration existantes peuvent réduire l'emplacement des lésions dans les images médicales, ce qui entraîne une réduction des informations sur les échantillons et la génération de bruit, tandis que les GIF peuvent mieux conserver la sémantique de leur catégorie
Coût de calcul et de temps Par rapport à la collecte et à l'annotation manuelles de données, le GIF peut réduire considérablement le temps et le coût de l'amplification des ensembles de données.

Universalité des données amplifiées Une fois amplifiés, ces ensembles de données peuvent être directement utilisés pour entraîner diverses structures de modèles de réseaux neuronaux.

Améliorer la capacité de généralisation du modèle GIF aide à améliorer les performances de généralisation hors distribution du modèle (généralisation OOD).

Soulager le problème de la longue traîne GIF aide à atténuer le problème de la longue traîne.

Contrôle de sécurité Les images générées par GIF sont sûres et inoffensives.
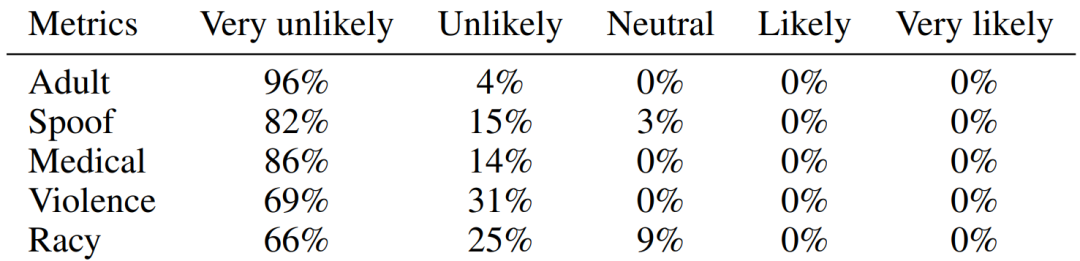
Sur la base des résultats expérimentaux ci-dessus, nous avons des raisons de croire qu'en simulant l'apprentissage de l'analogie humaine et de l'imagination, la méthode conçue dans cet article peut étendre efficacement de petits ensembles de données, améliorant ainsi les performances des réseaux neuronaux profonds dans mise en œuvre et application de scénarios de tâches de petites données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment vérifier le plagiat sur CNKI Étapes détaillées pour vérifier le plagiat sur CNKI
Comment vérifier le plagiat sur CNKI Étapes détaillées pour vérifier le plagiat sur CNKI
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Vérifiez le statut en ligne de vos amis sur TikTok
Vérifiez le statut en ligne de vos amis sur TikTok
 Utilisation des commandes NTSD
Utilisation des commandes NTSD
 Comment résoudre le problème signalé par le lien MySQL 10060
Comment résoudre le problème signalé par le lien MySQL 10060
 WeChat restaure l'historique des discussions
WeChat restaure l'historique des discussions
 La différence entre ancrer et viser
La différence entre ancrer et viser
 Quelle est la différence entre Douyin et Douyin Express Edition ?
Quelle est la différence entre Douyin et Douyin Express Edition ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



