


Dans le domaine de la science des données et de l'apprentissage automatique, de nombreux modèles supposent que les données sont normalement distribuées ou que les données fonctionnent mieux sous une distribution normale. Par exemple, la régression linéaire suppose que les résidus sont distribués normalement et l'analyse discriminante linéaire (LDA) est dérivée d'hypothèses telles que la distribution normale. Par conséquent, comprendre comment tester la normalité des données est crucial pour les data scientists et les praticiens de l'apprentissage automatique

Cet article vise à présenter 11 méthodes de base pour tester la normalité des données afin d'aider les lecteurs à mieux comprendre les caractéristiques de la distribution des données et à apprendre comment appliquer des méthodes d’analyse appropriées. Cela permet de mieux gérer l'impact de la distribution des données sur les performances du modèle et de devenir plus à l'aise dans le processus d'apprentissage automatique et de modélisation des données
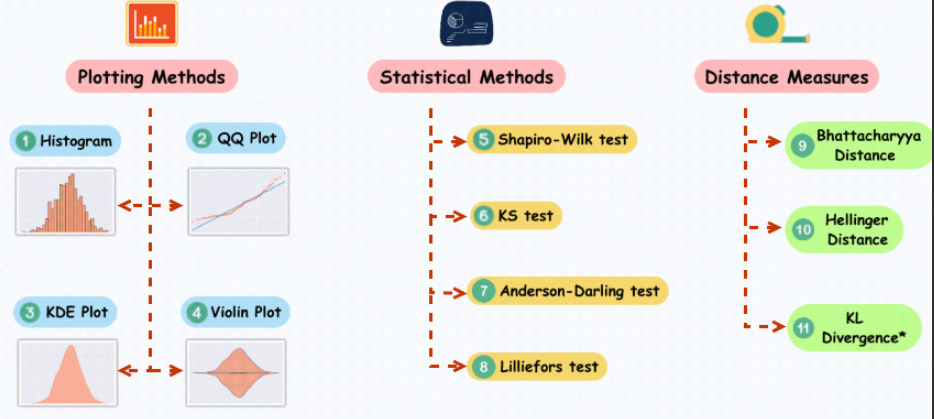
Pour démontrer le Tracé QQ, ce qui suit L'exemple de code génère un ensemble de données aléatoires qui suivent une distribution normale. Après avoir exécuté le code, vous pouvez voir le tracé QQ ainsi que la courbe de distribution normale correspondante. En observant la distribution des points sur le graphique, vous pouvez dans un premier temps juger si les données sont proches d'une distribution normale
import numpy as npimport scipy.stats as statsimport matplotlib.pyplot as plt# 生成一组随机数据,假设它们服从正态分布data = np.random.normal(0, 1, 1000)# 绘制QQ图stats.probplot(data, dist="norm", plot=plt)plt.title('Q-Q Plot')plt.show()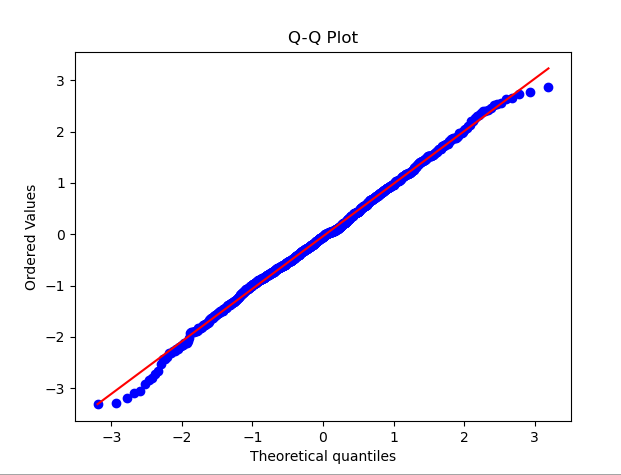 2 KDE Plot
2 KDE Plot
Pour démontrer le tracé KDE, l'exemple de code suivant génère un ensemble de données aléatoires qui obéit à un répartition normale. Après avoir exécuté le code, vous pouvez voir le tracé KDE et la courbe de distribution normale correspondante, et utiliser la visualisation pour détecter si la distribution des données est conforme à la normalité
import numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# 生成随机数据np.random.seed(0)data = np.random.normal(loc=0, scale=1, size=1000)# 创建KDE Plotsns.kdeplot(data, shade=True, label='KDE Plot')# 添加正态分布曲线mu, sigma = np.mean(data), np.std(data)x = np.linspace(min(data), max(data), 100)y = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)plt.plot(x, y, 'r--', label='Normal Distribution')# 显示图表plt.legend()plt.show()
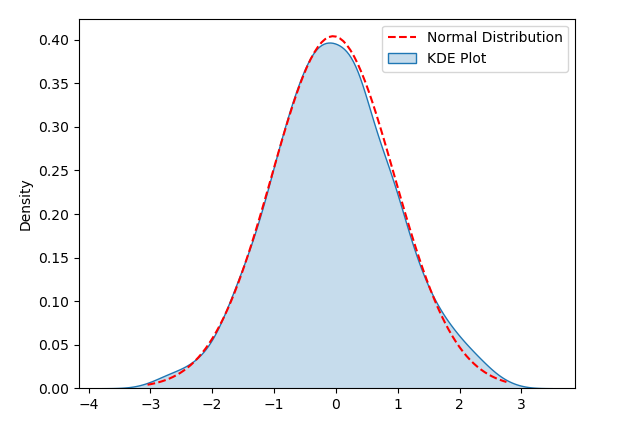 3. Vous pouvez découvrir la distribution des données. en observant la forme du Violin Plot pour déterminer initialement si les données sont proches d'une distribution normale. Si le tracé en violon prend la forme d'une courbe en cloche, les données sont probablement distribuées à peu près normalement. Si votre tracé Violin est fortement asymétrique ou présente plusieurs pics, les données risquent de ne pas être distribuées normalement.
3. Vous pouvez découvrir la distribution des données. en observant la forme du Violin Plot pour déterminer initialement si les données sont proches d'une distribution normale. Si le tracé en violon prend la forme d'une courbe en cloche, les données sont probablement distribuées à peu près normalement. Si votre tracé Violin est fortement asymétrique ou présente plusieurs pics, les données risquent de ne pas être distribuées normalement.
import numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# 生成随机数据np.random.seed(0)data = np.random.normal(loc=0, scale=1, size=100)# 创建 Violin Plotsns.violinplot(data, inner="points")# 添加正态分布曲线mu, sigma = np.mean(data), np.std(data)x = np.linspace(min(data), max(data), 100)y = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)plt.plot(x, y, 'r--', label='Normal Distribution')# 显示图表plt.legend()plt.show()
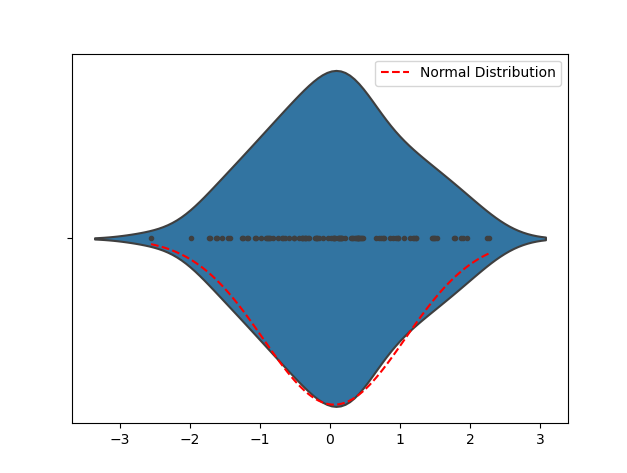 L'utilisation d'un histogramme (Histogramme) pour détecter la normalité de la distribution des données est également courante méthode. L'histogramme peut nous aider à comprendre intuitivement la distribution des données et peut déterminer de manière préliminaire si les données sont proches d'une distribution normale
L'utilisation d'un histogramme (Histogramme) pour détecter la normalité de la distribution des données est également courante méthode. L'histogramme peut nous aider à comprendre intuitivement la distribution des données et peut déterminer de manière préliminaire si les données sont proches d'une distribution normale
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as stats# 生成一组随机数据,假设它们服从正态分布data = np.random.normal(0, 1, 1000)# 绘制直方图plt.hist(data, bins=30, density=True, alpha=0.6, color='g')plt.title('Histogram of Data')plt.xlabel('Value')plt.ylabel('Frequency')# 绘制正态分布的概率密度函数xmin, xmax = plt.xlim()x = np.linspace(xmin, xmax, 100)p = stats.norm.pdf(x, np.mean(data), np.std(data))plt.plot(x, p, 'k', linewidth=2)plt.show()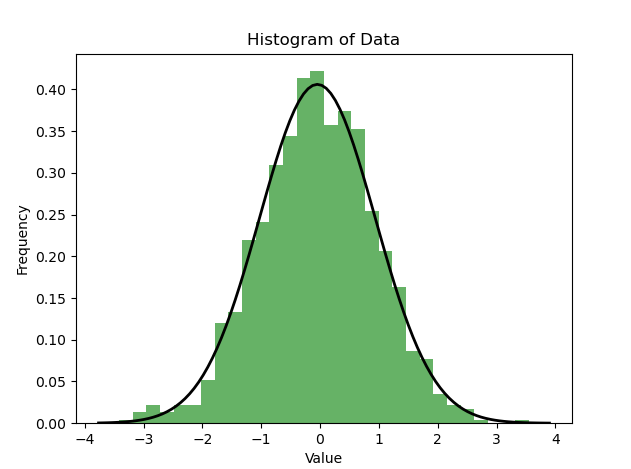 Méthodes statistiques
Méthodes statistiques
5. Test de Shapiro-Wilk
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Shapiro-Wilk检验stat, p = stats.shapiro(data)print('Shapiro-Wilk Statistic:', stat)print('P-value:', p)# 根据P值判断正态性alpha = 0.05if p > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
KS检验(Kolmogorov-Smirnov检验)是一种用于检验数据是否符合特定分布(例如正态分布)的统计方法。它通过计算观测数据与理论分布的累积分布函数(CDF)之间的最大差异来评估它们是否来自同一分布。其基本步骤如下:
Python中使用KS检验来检验数据是否符合正态分布时,可以使用Scipy库中的kstest函数。下面是一个简单的示例,演示了如何使用Python进行KS检验来检验数据是否符合正态分布。
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行KS检验statistic, p_value = stats.kstest(data, 'norm')print('KS Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
Anderson-Darling检验是一种用于检验数据是否来自特定分布(例如正态分布)的统计方法。它特别强调观察值在分布尾部的差异,因此在检测极端值的偏差方面非常有效
下面的代码使用stats.anderson函数执行Anderson-Darling检验,并获取检验统计量、临界值以及显著性水平。然后通过比较统计量和临界值,可以判断样本数据是否符合正态分布
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Anderson-Darling检验result = stats.anderson(data, dist='norm')print('Anderson-Darling Statistic:', result.statistic)print('Critical Values:', result.critical_values)print('Significance Level:', result.significance_level)# 判断正态性if result.statistic <p style="text-align:center;"><img src="https://img.php.cn/upload/article/000/887/227/170255826239547.png" alt="11 méthodes de base pour déterminer la normalité des distributions de données"></p><h4>8.Lilliefors检验</h4><p>Lilliefors检验(也被称为Kolmogorov-Smirnov-Lilliefors检验)是一种用于检验数据是否符合正态分布的统计检验方法。它是Kolmogorov-Smirnov检验的一种变体,专门用于小样本情况。与K-S检验不同,Lilliefors检验不需要假定数据的分布类型,而是基于观测数据来评估是否符合正态分布</p><p>在下面的例子中,我们使用lilliefors函数进行Lilliefors检验,并获得了检验统计量和P值。通过将P值与显著性水平进行比较,我们可以判断样本数据是否符合正态分布</p><pre class="brush:php;toolbar:false">import numpy as npfrom statsmodels.stats.diagnostic import lilliefors# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Lilliefors检验statistic, p_value = lilliefors(data)print('Lilliefors Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
距离测量(Distance measures)是一种有效的测试数据正态性的方法,它提供了更直观的方式来比较观察数据分布与参考分布之间的差异。
下面是一些常见的距离测量方法及其在测试正态性时的应用:
(1) "巴氏距离(Bhattacharyya distance)"的定义是:
(2) 「海林格距离(Hellinger distance)」:
(3) "KL 散度(KL Divergence)":
运用这些距离测量方法,我们能够比对观测到的分布与多个参考分布之间的差异,进而更好地评估数据的正态性。通过找出与观察到的分布距离最短的参考分布,我们可以更精确地判断数据是否符合正态分布
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Connexion Internet impossible
Connexion Internet impossible
 quel nœud peut faire
quel nœud peut faire
 javac n'est pas reconnu comme une commande interne ou externe ou un programme exploitable. Comment résoudre le problème ?
javac n'est pas reconnu comme une commande interne ou externe ou un programme exploitable. Comment résoudre le problème ?
 monnaie numérique virtuelle
monnaie numérique virtuelle
 Quelles sont les technologies de base nécessaires au développement Java ?
Quelles sont les technologies de base nécessaires au développement Java ?
 Comment résoudre le crash du Webstorm
Comment résoudre le crash du Webstorm
 Quelle est la différence entre l'héritage et l'uefi ?
Quelle est la différence entre l'héritage et l'uefi ?
 Le dossier devient exe
Le dossier devient exe








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



