


Il est bien connu que les grands modèles de langage (LLM) peuvent apprendre à partir d'un petit nombre d'exemples grâce à l'apprentissage contextuel sans avoir besoin d'affiner le modèle. Actuellement, ce phénomène d’apprentissage contextuel ne peut être observé que dans de grands modèles. Par exemple, les grands modèles comme GPT-4, Llama, etc. ont montré d'excellentes performances dans de nombreux domaines, mais en raison de contraintes de ressources ou d'exigences élevées en temps réel, les grands modèles ne peuvent pas être utilisés dans de nombreux scénarios
Ensuite, régulier- modèles de taille Avez-vous cette capacité ? Afin d'explorer les capacités d'apprentissage contextuel des petits modèles, des équipes de recherche de Byte et de l'East China Normal University ont mené des recherches sur les tâches de reconnaissance de texte de scène.
À l'heure actuelle, dans les scénarios d'application réels, la reconnaissance de texte de scène est confrontée à une variété de défis : différentes scènes, disposition du texte, déformation, changements d'éclairage, écriture floue, diversité des polices, etc., il est donc difficile de former une machine qui peut faire face à tous les scénarios. Un modèle de reconnaissance de texte unifié.
Un moyen direct de résoudre ce problème consiste à collecter les données correspondantes et à affiner le modèle dans des scénarios spécifiques. Cependant, ce processus nécessite un recyclage du modèle, qui nécessite beaucoup de calculs, et nécessite de sauvegarder plusieurs pondérations du modèle pour s'adapter à différents scénarios. Si le modèle de reconnaissance de texte peut avoir des capacités d'apprentissage du contexte, lorsqu'il est confronté à de nouvelles scènes, il n'a besoin que d'une petite quantité de données annotées comme invites pour améliorer ses performances sur de nouvelles scènes, résolvant ainsi les problèmes ci-dessus. Cependant, la reconnaissance de texte de scène est une tâche sensible aux ressources, et l'utilisation d'un grand modèle comme outil de reconnaissance de texte consommera beaucoup de ressources. Grâce à des observations expérimentales préliminaires, les chercheurs ont découvert que les méthodes traditionnelles de formation de grands modèles ne conviennent pas aux tâches de reconnaissance de texte de scène.
Afin de résoudre ce problème, l'équipe de recherche de ByteDance et de l'East China Normal University a proposé un outil de reconnaissance de texte auto-évolutif, E2STR (Reconnaissance de texte de scène évolutive de l'ego). Il s'agit d'un outil de reconnaissance de texte de taille normale qui intègre des capacités d'apprentissage du contexte et peut s'adapter rapidement à différents scénarios de reconnaissance de texte sans avoir besoin de réglages précis

Lien papier : https://arxiv.org/pdf/2311.13120 .pdf
E2STR est équipé d'un mode de formation contextuelle et de raisonnement contextuel, qui atteint non seulement le niveau SOTA sur des ensembles de données conventionnels, mais peut également utiliser un modèle unique pour améliorer les performances de reconnaissance dans divers scénarios et réaliser une adaptation rapide à Nouveaux scénarios, dépassant même les performances de reconnaissance des modèles spécialisés après un réglage fin. E2STR démontre que les modèles de taille normale sont suffisants pour obtenir des capacités d'apprentissage contextuel efficaces dans les tâches de reconnaissance de texte.
in Figure 1, le processus de formation et d'inférence de E2STR est montré
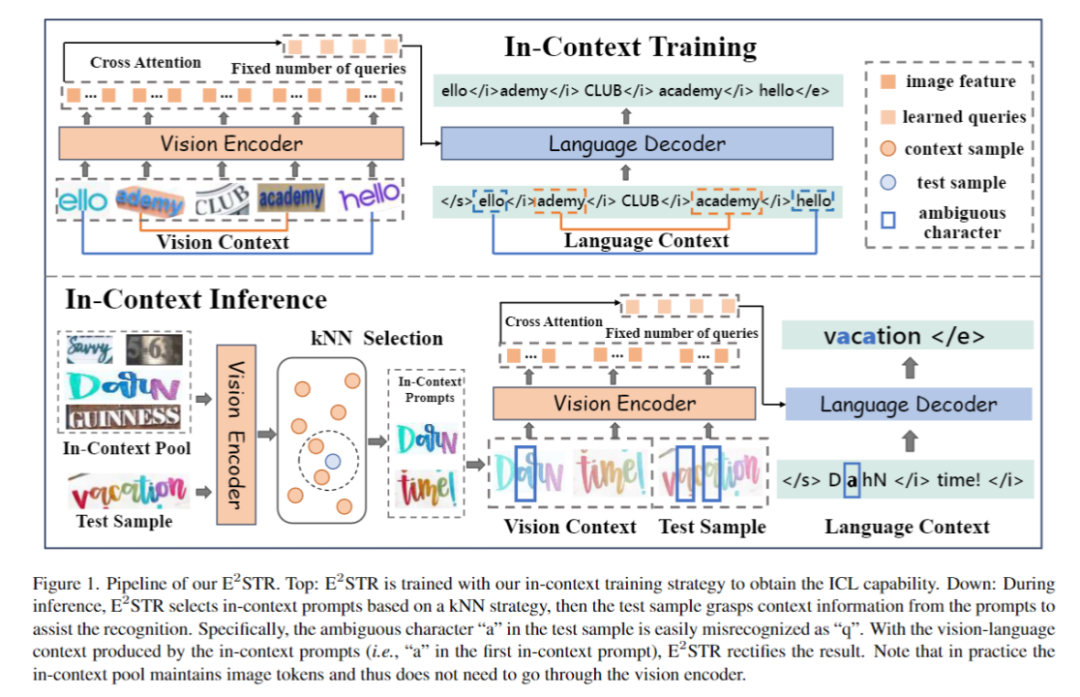
1. framework Le but de la formation de l'encodeur visuel et du décodeur de langage est d'obtenir des capacités de reconnaissance de texte :
2 Formation contextuelle 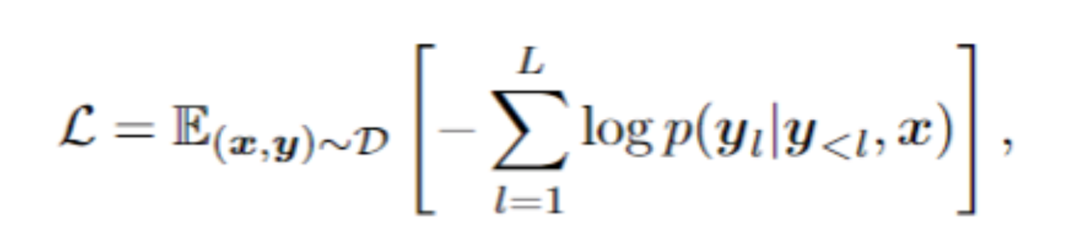
Phase de formation contextuelle E2STR sera davantage formé selon le paradigme de formation contextuelle proposé. dans l'article. À ce stade, E2STR apprendra à comprendre les liens entre différents échantillons pour acquérir des capacités de raisonnement à partir d'indices contextuels.
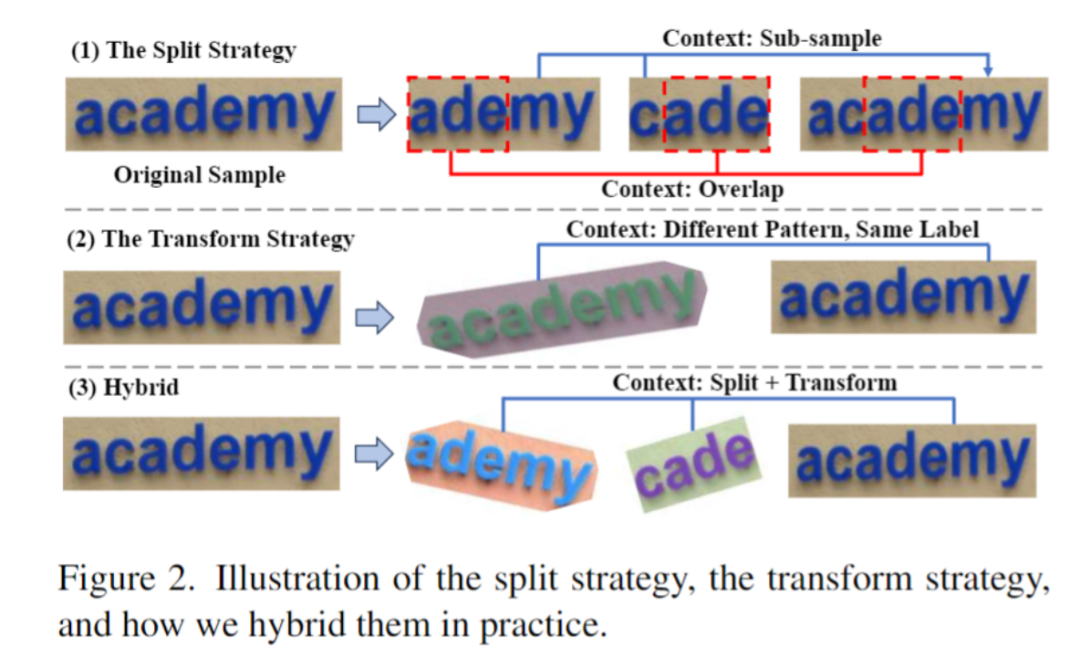
Comme le montre la figure 2, cet article propose la stratégie ST pour segmenter et transformer de manière aléatoire les données de texte de la scène pour générer un ensemble de « sous-échantillons ». Les sous-échantillons sont intrinsèquement liés visuellement et linguistiquement. Ces échantillons liés en interne sont fusionnés en une séquence, et le modèle apprend des connaissances contextuelles à partir de ces séquences sémantiquement riches, acquérant ainsi la capacité d'apprendre le contexte. Cette étape utilise également le cadre autorégressif pour l'entraînement :
Le contenu à réécrire est : 3. Le raisonnement contextuel
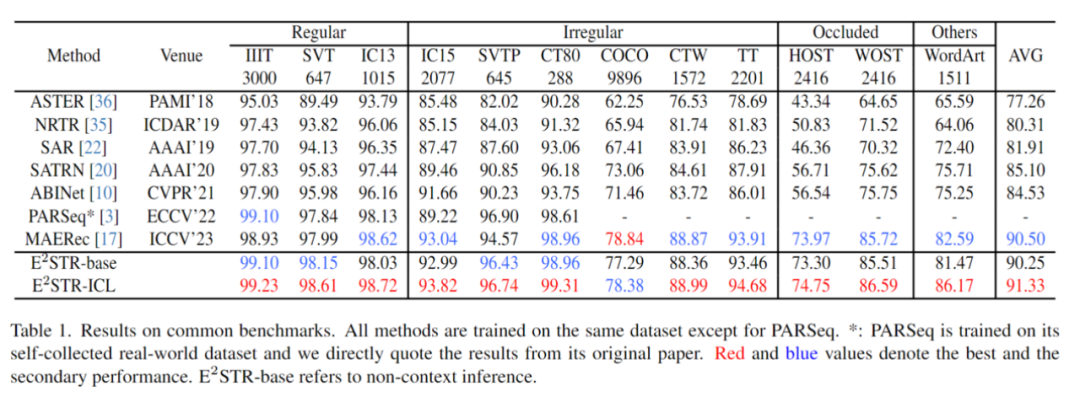
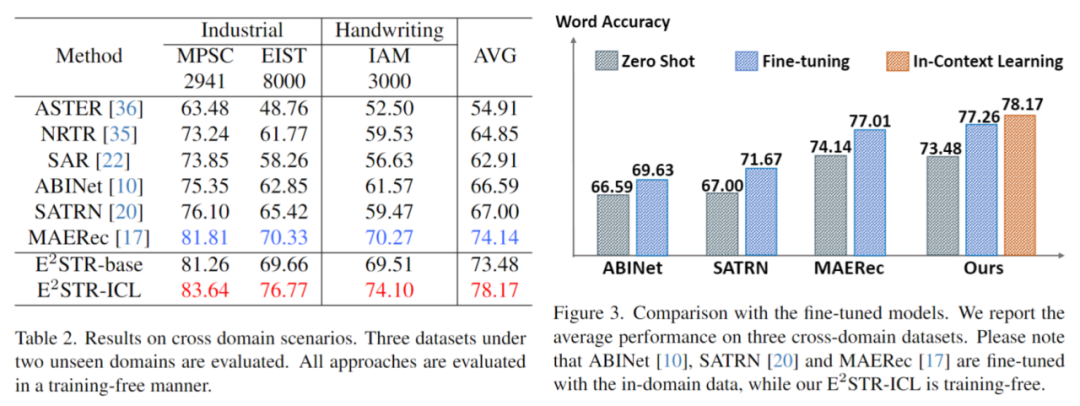
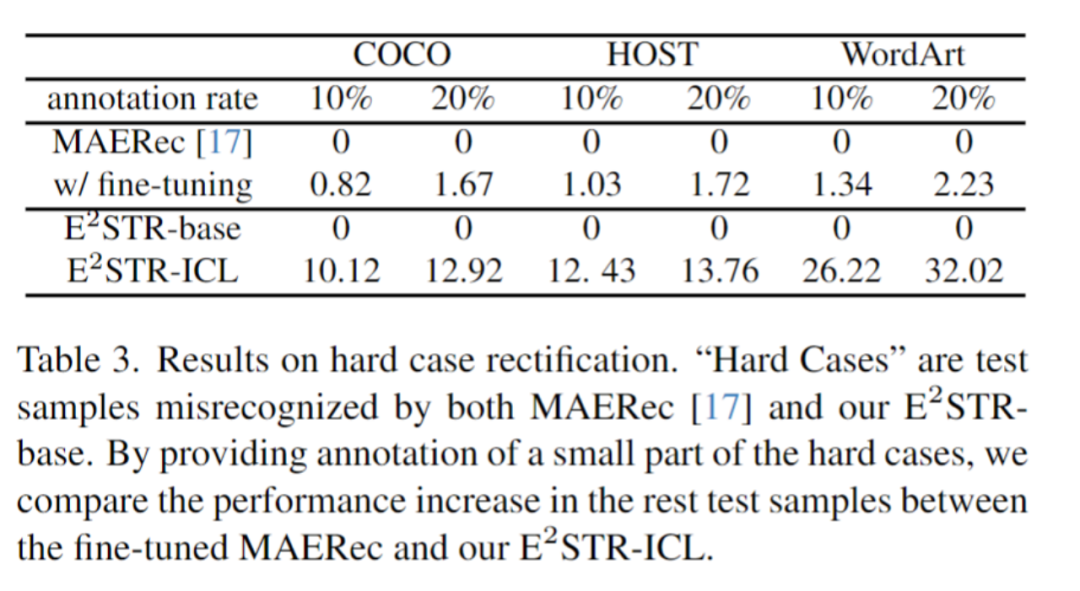
Contenu réécrit : 3. Raisonnement basé sur le contexte Pour un échantillon de test, le framework sélectionnera N échantillons dans le pool de signaux contextuels qui ont la plus grande similitude avec l'échantillon de test dans l'espace visuel latent. Plus précisément, cet article calcule l'intégration d'image I en faisant la moyenne du regroupement sur la séquence de jetons visuels. Ensuite, les N premiers échantillons présentant la similarité cosinusoïdale la plus élevée entre les incorporations d'images et I sont sélectionnés dans le pool de contexte, formant ainsi des indices contextuels. Une fois les indices contextuels et les échantillons de test assemblés et introduits dans le modèle, E2STR apprendra de nouvelles connaissances à partir des indices contextuels sans formation, améliorant ainsi la précision de reconnaissance des échantillons de test. Il est important de noter que le pool de repères contextuels ne conserve que les jetons émis par l'encodeur visuel, ce qui rend le processus de sélection des repères contextuels très efficace. De plus, étant donné que le pool d'indices contextuels est petit et que E2STR peut effectuer des inférences sans formation, la charge de calcul supplémentaire est également minimisée Les expériences sont principalement menées sous trois aspects : la reconnaissance de texte traditionnelle, respectivement -reconnaissance de scène de domaine et correction d'échantillons difficiles 1. Ensemble de données traditionnel Sélectionnez au hasard quelques échantillons (1 000, 0,025 % du nombre d'échantillons dans l'ensemble d'entraînement) dans l'ensemble d'entraînement pour former un pool d'invites de contexte, le test a été effectué sur 12 ensembles de tests de reconnaissance de texte de scène courants, et les résultats sont les suivants : On peut constater qu'E2STR s'est encore amélioré par rapport à l'ensemble de données traditionnel où les performances de reconnaissance sont presque saturé, dépassant les performances du modèle SOTA . Le contenu qui doit être réécrit est : 2. Scénario inter-domaines Dans le scénario inter-domaines, chaque ensemble de tests ne fournit que 100 échantillons de formation dans le domaine. Les résultats de comparaison entre aucune formation. et le réglage fin sont les suivants, E2STR dépasse même les résultats de réglage fin de la méthode SOTA. Le contenu qui doit être réécrit est le suivant : 3. Modifier les échantillons difficiles Les chercheurs ont collecté un lot d'échantillons difficiles et ont fourni 10 % à 20 % d'annotations pour ces échantillons par rapport à E2STR. Les résultats de la méthode d'apprentissage du contexte sans formation et de la méthode d'apprentissage de réglage fin de la méthode SOTA sont les suivants : Par rapport à la méthode de réglage fin, E2STR-ICL réduit considérablement le taux d'erreur des échantillons difficiles E2STR prouve qu'en utilisant des stratégies de formation et d'inférence appropriées, les petits modèles peuvent également avoir des capacités d'apprentissage en contexte similaires à celles du LLM. Dans certaines tâches nécessitant de fortes exigences en temps réel, de petits modèles peuvent également être utilisés pour s'adapter rapidement à de nouveaux scénarios. Plus important encore, cette méthode consistant à utiliser un modèle unique pour parvenir à une adaptation rapide à de nouveaux scénarios rapproche un peu plus de la construction d’un petit modèle unifié et efficace. 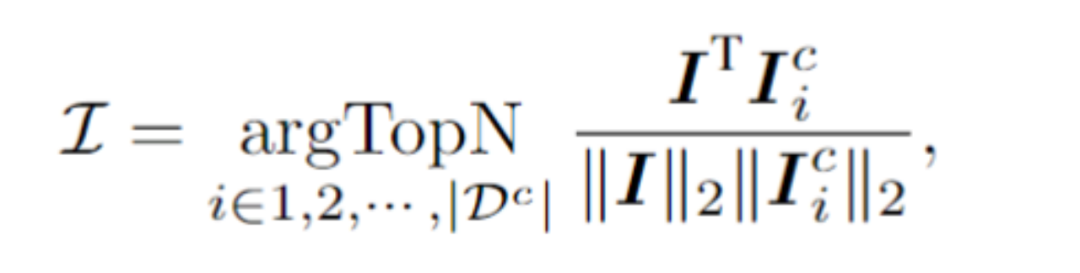
Expériences
Future Outlook
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Convertir le texte en valeur numérique
Convertir le texte en valeur numérique
 Le port 8080 est occupé
Le port 8080 est occupé
 psrpc.dll solution introuvable
psrpc.dll solution introuvable
 Comment trouver la somme des éléments pairs dans un tableau en php
Comment trouver la somme des éléments pairs dans un tableau en php
 La fonction principale de l'unité arithmétique dans un micro-ordinateur est d'effectuer
La fonction principale de l'unité arithmétique dans un micro-ordinateur est d'effectuer
 Comment activer la même fonction de ville sur Douyin
Comment activer la même fonction de ville sur Douyin
 Comment installer l'interpréteur pycharm
Comment installer l'interpréteur pycharm
 Carte graphique de qualité passionnée
Carte graphique de qualité passionnée








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



