


Au cours de la dernière année, une série de modèles de diffusion de graphes vincentiens représentés par Stable Diffusion ont complètement changé le domaine de la création visuelle. D'innombrables utilisateurs ont amélioré leur productivité grâce aux images produites par des modèles de diffusion. Cependant, la vitesse de génération des modèles de diffusion constitue un problème courant. Étant donné que le modèle de débruitage repose sur un débruitage en plusieurs étapes pour transformer progressivement le bruit gaussien initial en image, il nécessite plusieurs calculs du réseau, ce qui entraîne une vitesse de génération très lente. Cela rend le modèle de diffusion de graphes vincentiens à grande échelle très peu convivial pour certaines applications axées sur le temps réel et l'interactivité. Avec l'introduction d'une série de technologies, le nombre d'étapes nécessaires pour échantillonner à partir d'un modèle de diffusion est passé de quelques centaines d'étapes initiales à des dizaines d'étapes, voire même à seulement 4 à 8 étapes.
Récemment, une équipe de recherche de Google a proposé le modèle UFOGen, une variante du modèle de diffusion qui permet d'échantillonner extrêmement rapidement. En affinant la diffusion stable avec la méthode proposée dans l'article, UFOGen peut générer des images de haute qualité en une seule étape. Dans le même temps, les applications en aval de Stable Diffusion, telles que la génération de graphiques, ControlNet et d'autres fonctionnalités, peuvent également être conservées.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2311.09257
Comme vous pouvez le voir sur l'image ci-dessous, UFOGen peut générer des images en une seule étape.

Améliorer la vitesse de génération des modèles de diffusion n'est pas une nouvelle direction de recherche. Les recherches antérieures dans ce domaine se sont principalement concentrées sur deux directions. Une direction consiste à concevoir des méthodes de calcul numérique plus efficaces, afin d'atteindre l'objectif de résoudre l'ODE d'échantillonnage du modèle de diffusion en utilisant moins d'étapes discrètes. Par exemple, la série de solveurs numériques DPM proposée par l'équipe de Zhu Jun de l'Université Tsinghua s'est avérée très efficace en diffusion stable et peut réduire considérablement le nombre d'étapes de solution, passant de 50 étapes par défaut de DDIM à moins de 20 étapes. Une autre direction consiste à utiliser la méthode de distillation des connaissances pour compresser le chemin d'échantillonnage basé sur l'ODE du modèle en un plus petit nombre d'étapes. Des exemples dans cette direction sont la distillation guidée, l'un des meilleurs candidats papier au CVPR2023, et le modèle de cohérence latente (LCM) récemment populaire. LCM, en particulier, peut réduire le nombre d'étapes d'échantillonnage à seulement 4 en distillant l'objectif de cohérence, ce qui a donné naissance à de nombreuses applications de génération en temps réel.
Cependant, l'équipe de recherche de Google n'a pas suivi la direction générale ci-dessus dans le modèle UFOGen, elle a plutôt adopté une approche différente et a utilisé l'idée de modèle hybride du modèle de diffusion et du GAN proposée il y a plus d'un an. Ils pensent que l'échantillonnage et la distillation basés sur l'ODE susmentionnés ont leurs limites fondamentales et qu'il est difficile de comprimer le nombre d'étapes d'échantillonnage à la limite. Par conséquent, si vous souhaitez atteindre l’objectif d’une génération en une seule étape, vous devez ouvrir de nouvelles idées.
Le modèle hybride fait référence à une méthode qui combine un modèle de diffusion et un réseau contradictoire génératif (GAN). Cette méthode a été proposée pour la première fois par l'équipe de recherche de NVIDIA à l'ICLR 2022 et s'appelle DDGAN (« Using Denoising Diffusion GAN to Solve Three Problems in Generative Learning »). DDGAN s'inspire des lacunes des modèles de diffusion ordinaires qui font des hypothèses gaussiennes sur les distributions de réduction du bruit. En termes simples, le modèle de diffusion suppose que la distribution de débruitage (la distribution conditionnelle qui, étant donné un échantillon bruyant, génère un échantillon moins bruyant) est une simple distribution gaussienne. Cependant, la théorie des équations différentielles stochastiques prouve qu’une telle hypothèse n’est vraie que lorsque la taille du pas de réduction du bruit s’approche de 0. Par conséquent, le modèle de diffusion nécessite un grand nombre d'étapes de débruitage répétées pour garantir une petite taille d'étape de débruitage, ce qui entraîne une vitesse de génération lente. DDGAN propose d'abandonner l'hypothèse gaussienne de distribution de débruitage et d'utiliser à la place un GAN conditionnel pour la simuler. Cette distribution de réduction du bruit. Étant donné que le GAN possède des capacités de représentation extrêmement puissantes et peut simuler des distributions complexes, un pas de réduction du bruit plus grand peut être utilisé pour réduire le nombre d'étapes. Cependant, DDGAN modifie l'objectif de formation à la reconstruction stable du modèle de diffusion en objectif de formation du GAN, ce qui peut facilement provoquer une instabilité de la formation et rendre difficile son extension à des tâches plus complexes. Lors de NeurIPS 2023, la même équipe de recherche de Google qui a créé UGGen a proposé SIDDM (titre de l'article Semi-Implicit Denoising Diffusion Models), qui a réintroduit la fonction d'objectif de reconstruction dans l'objectif de formation du DDGAN, améliorant ainsi la stabilité de la formation et la qualité de la génération. sont significativement améliorés par rapport au DDGAN.
SIDDM, en tant que prédécesseur d'UFOGen, peut générer des images de haute qualité sur CIFAR-10, ImageNet et d'autres ensembles de données de recherche en seulement 4 étapes. Mais Le SIDDM a deux problèmes qui doivent être résolus : premièrement, il ne peut pas générer de conditions idéales en une seule étape. Deuxièmement, il n'est pas simple de l'étendre au domaine plus concerné des graphiques vincentiens ; Pour cela, l’équipe de recherche de Google a proposé UFOGen pour résoudre ces deux problèmes.
Plus précisément, pour la première question, grâce à une simple analyse mathématique, l'équipe a découvert qu'en changeant la méthode de paramétrage du générateur et en changeant la méthode de calcul de la fonction de perte de reconstruction, le modèle théorique peut être généré en une seule étape. Pour la deuxième question, l'équipe a proposé d'utiliser le modèle de diffusion stable existant pour l'initialisation afin de permettre au modèle UFOGen d'être étendu plus rapidement et mieux aux tâches du diagramme de Vincent. Il convient de noter que SIDDM a proposé que le générateur et le discriminateur adoptent l'architecture UNet. Par conséquent, sur la base de cette conception, le générateur et le discriminateur d'UFOGen sont initialisés par le modèle de diffusion stable. Cela permet de tirer le meilleur parti des informations internes de Stable Diffusion, notamment sur la relation entre les images et le texte. De telles informations sont difficiles à obtenir par l’apprentissage contradictoire. L'algorithme et le diagramme de formation sont présentés ci-dessous.

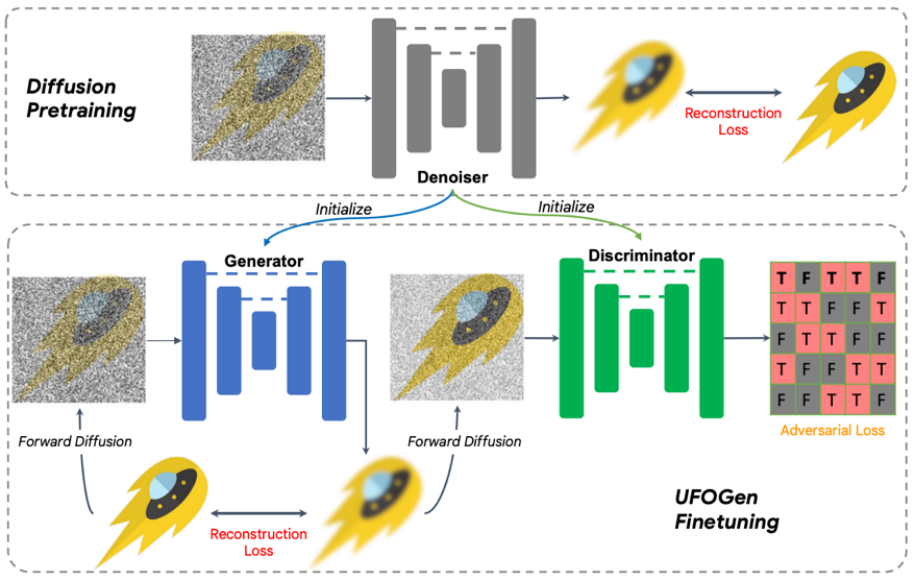
Il convient de noter que certains travaux antérieurs ont utilisé GAN pour créer des graphiques vincentiens, tels que StyleGAN-T de NVIDIA et GigaGAN d'Adobe, qui ont étendu l'architecture de base de StyleGAN à une plus grande taille. .échelle, afin que l'image puisse être créée en une seule étape. L'auteur d'UFOGen a souligné que par rapport aux travaux précédents basés sur le GAN, en plus de la qualité de la génération, UFOGen présente plusieurs avantages :
Contenu réécrit : 1. Dans la tâche de graphe vincentien, la formation pure sur le réseau contradictoire génératif (GAN) est très instable. Le discriminateur doit non seulement juger la texture de l'image, mais également comprendre le degré de correspondance entre l'image et le texte, ce qui est une tâche très difficile, en particulier au début de la formation. Par conséquent, les modèles GAN précédents, tels que GigaGAN, introduisaient un grand nombre de pertes auxiliaires pour faciliter la formation, ce qui rendait la formation et l'ajustement des paramètres extrêmement difficiles. Cependant, UFOGen fait jouer au GAN un rôle auxiliaire à cet égard en introduisant une perte de reconstruction, permettant ainsi d'obtenir une formation très stable
2. La formation du GAN directement à partir de zéro est non seulement instable mais aussi extrêmement coûteuse, en particulier sur les graphiques Vincent. une grande quantité de données et d’étapes de formation. Étant donné que deux ensembles de paramètres doivent être mis à jour en même temps, la formation du GAN consomme plus de temps et de mémoire que le modèle de diffusion. La conception innovante d'UFOGen peut initialiser les paramètres de diffusion stable, ce qui permet d'économiser considérablement du temps de formation. Habituellement, la convergence ne nécessite que des dizaines de milliers d’étapes de formation.
3. L'un des charmes du modèle de diffusion de graphes Vincent est qu'il peut être appliqué à d'autres tâches, y compris des applications qui ne nécessitent pas de réglage fin comme les graphes, et des applications qui nécessitent déjà un réglage fin comme génération contrôlée. Les modèles GAN précédents étaient difficiles à adapter à ces tâches en aval, car le réglage fin des GAN était difficile. En revanche, UFOGen a le cadre d’un modèle de diffusion et peut donc être plus facilement appliqué à ces tâches. La figure ci-dessous montre le graphique de génération de graphiques d'UFOGen et des exemples de génération contrôlable. Notez que ces générations ne nécessitent qu'une seule étape d'échantillonnage.

Les expériences montrent qu'UFOGen peut générer des images de haute qualité qui correspondent aux descriptions textuelles en une seule étape d'échantillonnage. Comparé aux méthodes d'échantillonnage à grande vitesse récemment proposées pour les modèles de diffusion (tels que Instaflow et LCM), UFOGen fait preuve d'une forte compétitivité. Même comparés à la diffusion stable, qui nécessite 50 étapes d'échantillonnage, les échantillons générés par UFOGen ne sont pas inférieurs en apparence. Voici quelques résultats de comparaison :

L'équipe de Google a proposé un modèle puissant appelé UFOGen, qui est implémenté en améliorant le modèle de diffusion existant et un modèle hybride de GAN. Ce modèle est affiné par Stable Diffusion et, tout en garantissant la possibilité de générer des graphiques en une seule étape, il convient également à différentes applications en aval. En tant que l'un des premiers travaux visant à réaliser une synthèse texte-image ultra-rapide, UFOGen a ouvert une nouvelle voie dans le domaine des modèles génératifs à haute efficacité
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Tutoriel PHP
Tutoriel PHP
 Erreur d'application plugin.exe
Erreur d'application plugin.exe
 diablotin oracle
diablotin oracle
 Quelles sont les méthodes pour implémenter la surcharge d'opérateurs en langage Go ?
Quelles sont les méthodes pour implémenter la surcharge d'opérateurs en langage Go ?
 Comment configurer l'environnement pycharm
Comment configurer l'environnement pycharm
 Comment écrire un triangle en CSS
Comment écrire un triangle en CSS
 Comment définir le retour à la ligne automatique dans Word
Comment définir le retour à la ligne automatique dans Word
 La différence entre maître et hôte
La différence entre maître et hôte








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



