



Actualités du 10 novembre, les grands modèles de langage (LLM) se développent rapidement, montrant de brillantes perspectives en matière de génération et de compréhension du langage, et leur influence dépasse le domaine du langage et s'étend à la logique, aux mathématiques, à la physique et à d'autres domaines.
Cependant, vous devez payer un prix élevé pour débloquer cette « énergie extraordinaire ». Par exemple, la formation d'un modèle 540B nécessite 6144 puces TPUv4 du Projet PaLM et la formation de 175B GPT-3 nécessite des milliers de pétaflops/s ; jour.
Une bonne solution consiste à s'entraîner avec une faible précision, ce qui peut augmenter la vitesse de traitement et réduire l'utilisation de la mémoire et les coûts de communication. Les systèmes de formation traditionnels actuels incluent Megatron-LM, MetaSeq et Colossal-AI, qui utilisent par défaut la précision mixte FP16/BF16 ou la pleine précision FP32 pour former de grands modèles de langage
Bien que ces niveaux de précision soient essentiels pour les grands modèles de langage, mais ils le sont coûteux en calcul.
Si vous adoptez la faible précision FP8, vous pouvez augmenter la vitesse de 2 fois, réduire le coût de la mémoire de 50 % à 75 % et économiser les coûts de communication.
Actuellement, seul le Nvidia Transformer Engine est compatible avec le framework FP8, exploitant principalement cette précision pour les calculs GEMM (multiplication matricielle générale) tout en conservant les poids et gradients principaux avec une haute précision FP16 ou FP32.
Pour relever ce défi, une équipe de chercheurs de Microsoft Azure et Microsoft Research a introduit un framework FP8 efficace à précision mixte, adapté à la formation de grands modèles de langage.
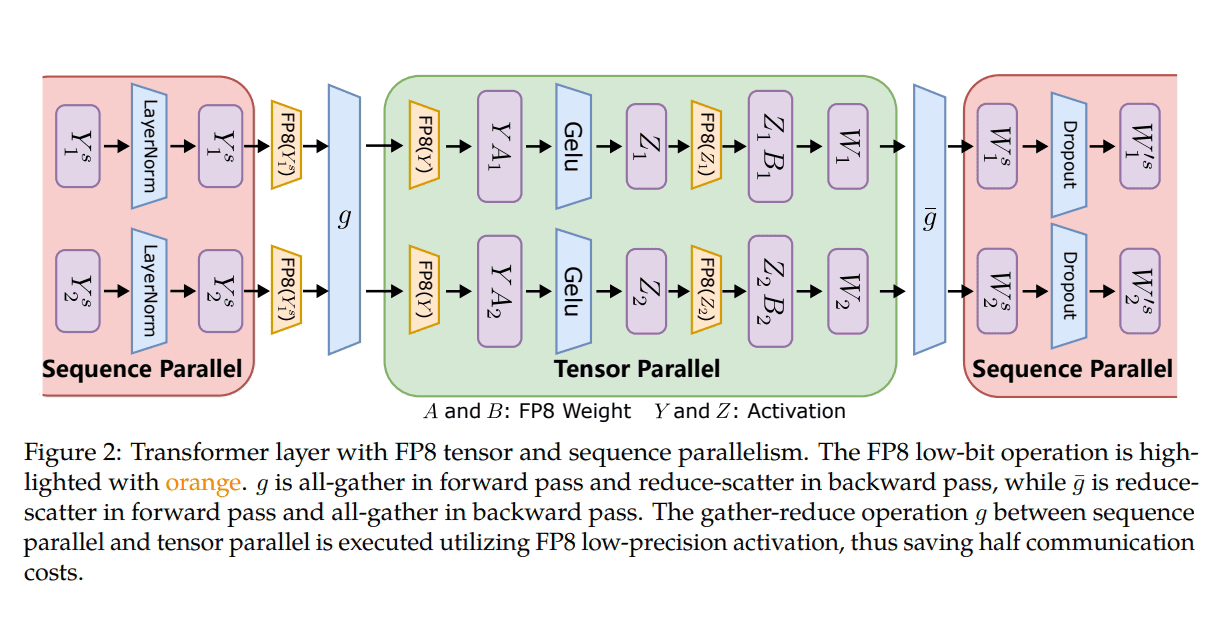
Microsoft a introduit trois étapes d'optimisation pour tirer parti du FP8 pour l'entraînement de précision distribué et mixte. À mesure que ces niveaux progressent, une intégration accrue du FP8 devient évidente, suggérant un impact plus important sur le processus de formation LLM.
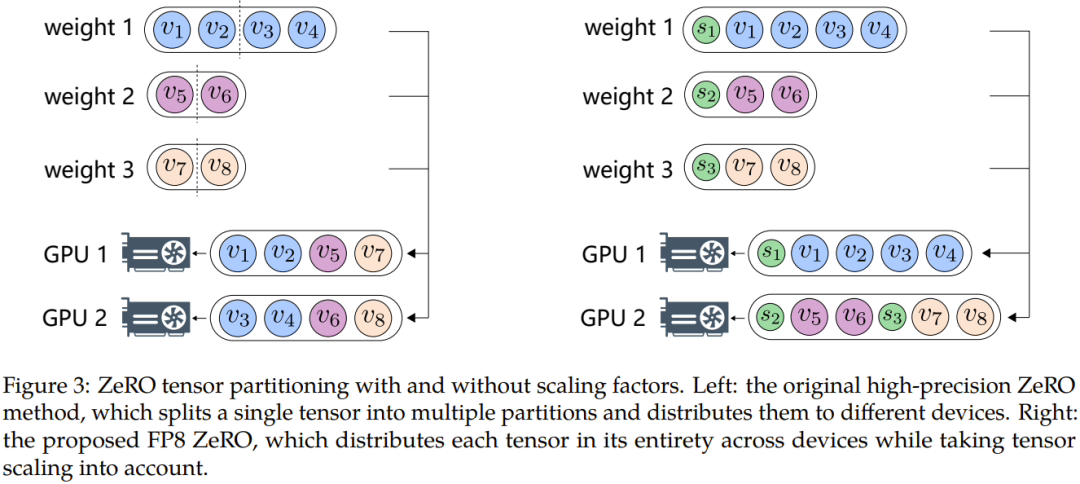
De plus, afin de surmonter des problèmes tels que le débordement ou le sous-débordement de données, les chercheurs de Microsoft ont proposé deux méthodes clés : l'échantillonnage automatique et le découplage précis. La première implique des composants qui ne sont pas sensibles à la précision, réduisant la précision et ajustant dynamiquement l'échantillonnage Tensor. facteur pour garantir que la valeur du gradient est maintenue dans la plage de représentation du FP8. Cela évite les événements de débordement et de débordement pendant une communication complète, garantissant ainsi un processus de formation plus fluide.
Microsoft a testé que, par rapport à la méthode de précision mixte BF16 largement adoptée, l'utilisation de la mémoire est réduite de 27 % à 42 % et la surcharge de communication par gradient de poids est considérablement réduite de 63 % à 65 %. Fonctionne 64 % plus rapidement que les frameworks BF16 largement adoptés tels que Megatron-LM et 17 % plus rapide que le Nvidia Transformer Engine.
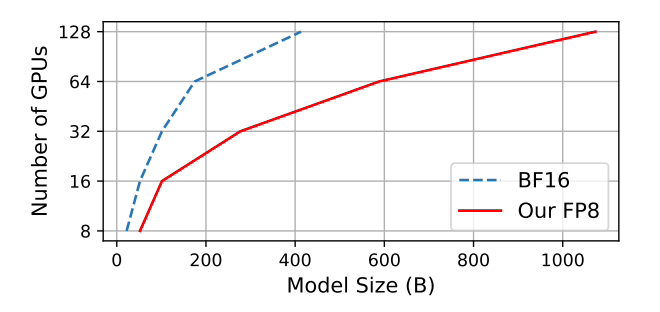
Lors de la formation du modèle GPT-175B, le framework de précision hybride FP8 économise 21 % de mémoire sur la plate-forme GPU H100 et réduit le temps de formation de 17 % par rapport au TE (Transformer Engine).
Ci-joint voici l'adresse GitHubet l'adresse papier ://m.sbmmt.com/link/7b3564b05f78b6739d06a2ea3187f5ca
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Solution à l'échec de la connexion entre wsus et le serveur Microsoft
Solution à l'échec de la connexion entre wsus et le serveur Microsoft
 Modifier le nom du fichier sous Linux
Modifier le nom du fichier sous Linux
 Comment définir la couleur de la police en HTML
Comment définir la couleur de la police en HTML
 Comment formater le disque dur sous Linux
Comment formater le disque dur sous Linux
 saut de ligne forcé de mot
saut de ligne forcé de mot
 Comment configurer l'ordinateur pour qu'il se connecte automatiquement au WiFi
Comment configurer l'ordinateur pour qu'il se connecte automatiquement au WiFi
 utilisation de la fonction
utilisation de la fonction
 que signifie OEM
que signifie OEM








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



