


Après l'article précédent"PyTorch Concise Tutorial Part 1", continuez à apprendre le perceptron multicouche, le réseau neuronal convolutif et LSTMNet.
Le perceptron multicouche est un simple réseau neuronal et une base importante pour l'apprentissage profond. Il surmonte les limitations des modèles linéaires en ajoutant une ou plusieurs couches cachées au réseau. Le schéma spécifique est le suivant :
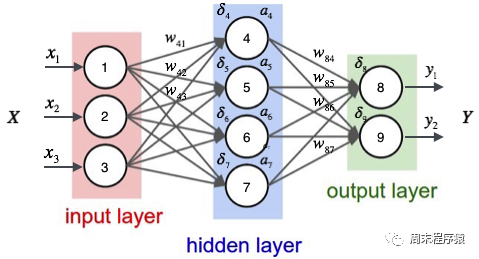
import numpy as npimport torchfrom torch.autograd import Variablefrom torch import optimfrom data_util import load_mnistdef build_model(input_dim, output_dim):return torch.nn.Sequential(torch.nn.Linear(input_dim, 512, bias=False),torch.nn.ReLU(),torch.nn.Dropout(0.2),torch.nn.Linear(512, 512, bias=False),torch.nn.ReLU(),torch.nn.Dropout(0.2),torch.nn.Linear(512, output_dim, bias=False),)def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)n_examples, n_features = trX.size()n_classes = 10model = build_model(n_features, n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.Adam(model.parameters())batch_size = 100for i in range(100):cost = 0.num_batches = n_examples // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[start:end], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%"% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()(1) Le code ci-dessus est similaire au code d'un réseau neuronal monocouche. La différence est que build_model construit un modèle de réseau neuronal contenant trois couches linéaires et deux activations ReLU. fonctions :
(3) Qu'est-ce que la couche Dropout ? La couche d'abandon est une technique utilisée dans les réseaux de neurones pour éviter le surajustement. Pendant le processus d'entraînement, la couche Dropout définira aléatoirement la sortie de certains neurones sur 0, c'est-à-dire "éliminera" ces neurones. Le but est de réduire l'interdépendance entre les neurones et ainsi d'améliorer la capacité de généralisation du réseau.
(4)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY))) Enfin , le cycle d'entraînement en cours, la valeur de perte et les acc sont imprimés. Le résultat du code ci-dessus est le suivant :
...Epoch 91, cost = 0.011129, acc = 98.45%Epoch 92, cost = 0.007644, acc = 98.58%Epoch 93, cost = 0.011872, acc = 98.61%Epoch 94, cost = 0.010658, acc = 98.58%Epoch 95, cost = 0.007274, acc = 98.54%Epoch 96, cost = 0.008183, acc = 98.43%Epoch 97, cost = 0.009999, acc = 98.33%Epoch 98, cost = 0.011613, acc = 98.36%Epoch 99, cost = 0.007391, acc = 98.51%Epoch 100, cost = 0.011122, acc = 98.59%
On peut voir que la même classification finale des données a une précision supérieure à celle du réseau neuronal monocouche (98,59 % > 97,68). %).
2. Réseau neuronal convolutif
import numpy as npimport torchfrom torch.autograd import Variablefrom torch import optimfrom data_util import load_mnistclass ConvNet(torch.nn.Module):def __init__(self, output_dim):super(ConvNet, self).__init__()self.conv = torch.nn.Sequential()self.conv.add_module("conv_1", torch.nn.Conv2d(1, 10, kernel_size=5))self.conv.add_module("maxpool_1", torch.nn.MaxPool2d(kernel_size=2))self.conv.add_module("relu_1", torch.nn.ReLU())self.conv.add_module("conv_2", torch.nn.Conv2d(10, 20, kernel_size=5))self.conv.add_module("dropout_2", torch.nn.Dropout())self.conv.add_module("maxpool_2", torch.nn.MaxPool2d(kernel_size=2))self.conv.add_module("relu_2", torch.nn.ReLU())self.fc = torch.nn.Sequential()self.fc.add_module("fc1", torch.nn.Linear(320, 50))self.fc.add_module("relu_3", torch.nn.ReLU())self.fc.add_module("dropout_3", torch.nn.Dropout())self.fc.add_module("fc2", torch.nn.Linear(50, output_dim))def forward(self, x):x = self.conv.forward(x)x = x.view(-1, 320)return self.fc.forward(x)def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)trX = trX.reshape(-1, 1, 28, 28)teX = teX.reshape(-1, 1, 28, 28)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)n_examples = len(trX)n_classes = 10model = ConvNet(output_dim=n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)batch_size = 100for i in range(100):cost = 0.num_batches = n_examples // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[start:end], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%"% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()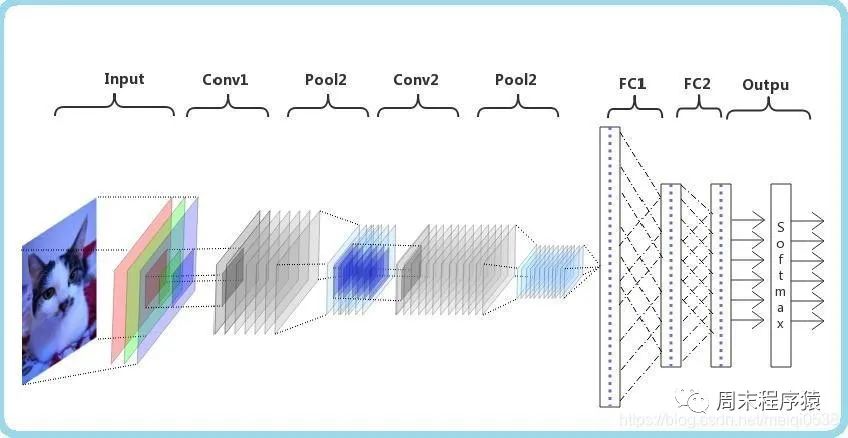 (1) Le code ci-dessus définit une classe nommée ConvNet, qui hérite de la classe torch.nn.Module et représente un réseau neuronal convolutif dans la méthode __init__ Deux sous-modules conv et fc sont définis, représentant respectivement la couche convolutive et la couche entièrement connectée. Dans le sous-module conv, nous définissons deux couches convolutives (torch.nn.Conv2d), deux couches de pooling maximum (torch.nn.MaxPool2d), deux fonctions d'activation ReLU (torch.nn.ReLU) et une couche Dropout (torch.nn. Abandonner). Dans le sous-module fc, deux couches linéaires (torch.nn.Linear), une fonction d'activation ReLU et une couche Dropout sont définies
(1) Le code ci-dessus définit une classe nommée ConvNet, qui hérite de la classe torch.nn.Module et représente un réseau neuronal convolutif dans la méthode __init__ Deux sous-modules conv et fc sont définis, représentant respectivement la couche convolutive et la couche entièrement connectée. Dans le sous-module conv, nous définissons deux couches convolutives (torch.nn.Conv2d), deux couches de pooling maximum (torch.nn.MaxPool2d), deux fonctions d'activation ReLU (torch.nn.ReLU) et une couche Dropout (torch.nn. Abandonner). Dans le sous-module fc, deux couches linéaires (torch.nn.Linear), une fonction d'activation ReLU et une couche Dropout sont définies
La couche de pooling joue un rôle important dans CNN, et ses principaux objectifs sont les suivants : :
(3)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
...Epoch 91, cost = 0.047302, acc = 99.22%Epoch 92, cost = 0.049026, acc = 99.22%Epoch 93, cost = 0.048953, acc = 99.13%Epoch 94, cost = 0.045235, acc = 99.12%Epoch 95, cost = 0.045136, acc = 99.14%Epoch 96, cost = 0.048240, acc = 99.02%Epoch 97, cost = 0.049063, acc = 99.21%Epoch 98, cost = 0.045373, acc = 99.23%Epoch 99, cost = 0.046127, acc = 99.12%Epoch 100, cost = 0.046864, acc = 99.10%
可以看出最后相同的数据分类,准确率比多层感知机要高(99.10% > 98.59%)。
LSTMNet是使用长短时记忆网络(Long Short-Term Memory, LSTM)构建的神经网络,核心思想是引入了一个名为"记忆单元"的结构,该结构可以在一定程度上保留长期依赖信息,LSTM中的每个单元包括一个输入门(input gate)、一个遗忘门(forget gate)和一个输出门(output gate),这些门的作用是控制信息在记忆单元中的流动,以便网络可以学习何时存储、更新或输出有用的信息。
import numpy as npimport torchfrom torch import optim, nnfrom data_util import load_mnistclass LSTMNet(torch.nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(LSTMNet, self).__init__()self.hidden_dim = hidden_dimself.lstm = nn.LSTM(input_dim, hidden_dim)self.linear = nn.Linear(hidden_dim, output_dim, bias=False)def forward(self, x):batch_size = x.size()[1]h0 = torch.zeros([1, batch_size, self.hidden_dim])c0 = torch.zeros([1, batch_size, self.hidden_dim])fx, _ = self.lstm.forward(x, (h0, c0))return self.linear.forward(fx[-1])def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)train_size = len(trY)n_classes = 10seq_length = 28input_dim = 28hidden_dim = 128batch_size = 100epochs = 100trX = trX.reshape(-1, seq_length, input_dim)teX = teX.reshape(-1, seq_length, input_dim)trX = np.swapaxes(trX, 0, 1)teX = np.swapaxes(teX, 0, 1)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)model = LSTMNet(input_dim, hidden_dim, n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)for i in range(epochs):cost = 0.num_batches = train_size // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[:, start:end, :], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%" %(i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()(1)以上这段代码通用的部分就不解释了,具体说LSTMNet类:
(2)print("第%d轮,损失值=%f,准确率=%.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))。打印出当前训练轮次的信息,其中包括损失值和准确率,以上代码的输出结果如下:
Epoch 91, cost = 0.000468, acc = 98.57%Epoch 92, cost = 0.000452, acc = 98.57%Epoch 93, cost = 0.000437, acc = 98.58%Epoch 94, cost = 0.000422, acc = 98.57%Epoch 95, cost = 0.000409, acc = 98.58%Epoch 96, cost = 0.000396, acc = 98.58%Epoch 97, cost = 0.000384, acc = 98.57%Epoch 98, cost = 0.000372, acc = 98.56%Epoch 99, cost = 0.000360, acc = 98.55%Epoch 100, cost = 0.000349, acc = 98.55%
两篇文章的from data_util import load_mnist的data_util.py代码如下:
import gzip
import os
import urllib.request as request
from os import path
import numpy as np
DATASET_DIR = 'datasets/'
MNIST_FILES = ["train-images-idx3-ubyte.gz", "train-labels-idx1-ubyte.gz", "t10k-images-idx3-ubyte.gz", "t10k-labels-idx1-ubyte.gz"]
def download_file(url, local_path):
dir_path = path.dirname(local_path)
if not path.exists(dir_path):
print("创建目录'%s' ..." % dir_path)
os.makedirs(dir_path)
print("从'%s'下载中 ..." % url)
request.urlretrieve(url, local_path)
def download_mnist(local_path):
url_root = "http://yann.lecun.com/exdb/mnist/"
for f_name in MNIST_FILES:
f_path = os.path.join(local_path, f_name)
if not path.exists(f_path):
download_file(url_root + f_name, f_path)
def one_hot(x, n):
if type(x) == list:
x = np.array(x)
x = x.flatten()
o_h = np.zeros((len(x), n))
o_h[np.arange(len(x)), x] = 1
return o_h
def load_mnist(ntrain=60000, ntest=10000, notallow=True):
data_dir = os.path.join(DATASET_DIR, 'mnist/')
if not path.exists(data_dir):
download_mnist(data_dir)
else:
# 检查所有文件
checks = [path.exists(os.path.join(data_dir, f)) for f in MNIST_FILES]
if not np.all(checks):
download_mnist(data_dir)
with gzip.open(os.path.join(data_dir, 'train-images-idx3-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
trX = loaded[16:].reshape((60000, 28 * 28)).astype(float)
with gzip.open(os.path.join(data_dir, 'train-labels-idx1-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
trY = loaded[8:].reshape((60000))
with gzip.open(os.path.join(data_dir, 't10k-images-idx3-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
teX = loaded[16:].reshape((10000, 28 * 28)).astype(float)
with gzip.open(os.path.join(data_dir, 't10k-labels-idx1-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
teY = loaded[8:].reshape((10000))
trX /= 255.
teX /= 255.
trX = trX[:ntrain]
trY = trY[:ntrain]
teX = teX[:ntest]
teY = teY[:ntest]
if onehot:
trY = one_hot(trY, 10)
teY = one_hot(teY, 10)
else:
trY = np.asarray(trY)
teY = np.asarray(teY)
return trX, teX, trY, teYCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 qu'est-ce que l'index MySQL
qu'est-ce que l'index MySQL
 Qu'est-ce qui est mis en évidence dans jquery
Qu'est-ce qui est mis en évidence dans jquery
 Requête blockchain du navigateur Ethereum
Requête blockchain du navigateur Ethereum
 Comment récupérer les flammes Douyin après leur disparition ?
Comment récupérer les flammes Douyin après leur disparition ?
 Comment résoudre le problème des 400 requêtes incorrectes lorsque la page Web s'affiche
Comment résoudre le problème des 400 requêtes incorrectes lorsque la page Web s'affiche
 Outils de recherche couramment utilisés
Outils de recherche couramment utilisés
 Logiciel gratuit pour créer des sites Web
Logiciel gratuit pour créer des sites Web
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



