


Des chercheurs de l'Université de Fudan et du laboratoire Noah's Ark de Huawei ont proposé une solution itérative pour générer des vidéos de haute qualité basée sur le modèle de diffusion d'images (LDM) - VidRD (Reuse and Diffuse). Cette solution vise à réaliser des percées dans la qualité et la longueur des séquences des vidéos générées, et à parvenir à une génération vidéo contrôlable de haute qualité de longues séquences. Il réduit efficacement le problème de gigue entre les images vidéo générées, a une grande valeur de recherche et pratique et contribue à la communauté AIGC actuelle.
Latent Diffusion Model (LDM) est un modèle génératif basé sur Denoising Autoencoder, qui peut générer des échantillons de haute qualité à partir de données initialisées de manière aléatoire en supprimant progressivement le bruit. Cependant, en raison des limitations de calcul et de mémoire lors de la formation et de l'inférence du modèle, un seul LDM ne peut généralement générer qu'un nombre très limité d'images vidéo. Bien que les travaux existants tentent d'utiliser un modèle de prédiction distinct pour générer davantage d'images vidéo, cela entraîne également des coûts de formation supplémentaires et produit une gigue au niveau des images.
Dans cet article, inspiré par le succès remarquable des modèles de diffusion latente (MLD) en synthèse d'images, un cadre appelé "Réutilisation et diffusion", ou VidRD en abrégé, est proposé. Ce cadre peut générer davantage d'images vidéo après le petit nombre d'images vidéo déjà générées par LDM, générant ainsi de manière itérative un contenu vidéo plus long, de meilleure qualité et diversifié. VidRD charge un modèle LDM d'image pré-entraîné pour une formation efficace et utilise un réseau U-Net avec des informations temporelles supplémentaires pour la suppression du bruit.

Les principales contributions de cet article sont les suivantes :
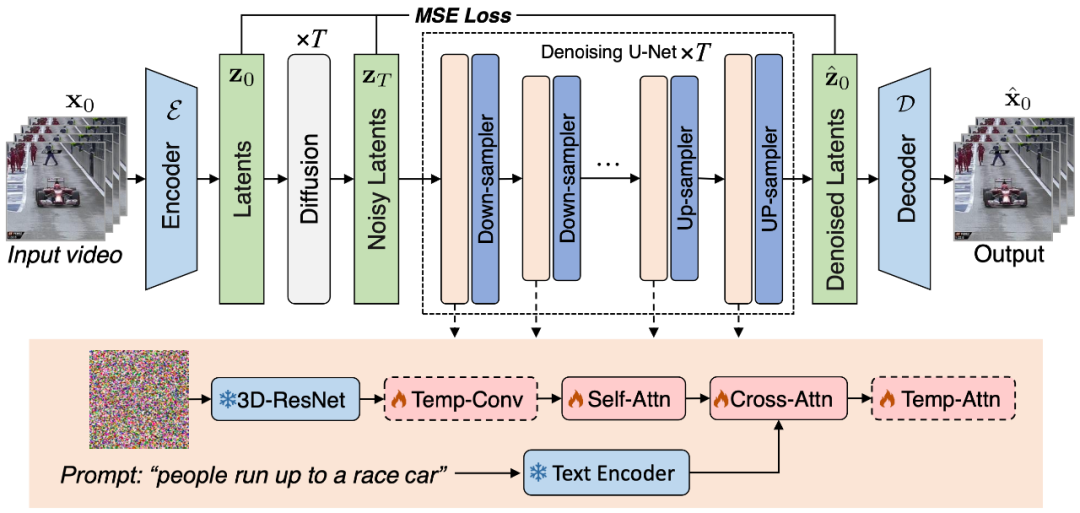
Figure 1. Diagramme schématique du cadre de génération vidéo VidRD proposé dans cet article
Cet article estime que l'utilisation d'images LDM pré-entraînées comme point de départ pour la formation LDM pour une synthèse vidéo de haute qualité, c'est un moyen efficace et choisissez judicieusement. Dans le même temps, ce point de vue est étayé par des travaux de recherche tels que [1, 2]. Dans ce contexte, le modèle soigneusement conçu dans cet article est construit sur la base du modèle de diffusion stable pré-entraîné, apprenant pleinement et héritant de ses excellentes caractéristiques. Ceux-ci incluent un auto-encodeur variationnel (VAE) pour une représentation latente précise et un puissant réseau de débruitage U-Net. La figure 1 montre l'architecture globale du modèle de manière claire et intuitive.
Dans la conception du modèle de cet article, une caractéristique notable est l'utilisation complète des poids de modèle pré-entraînés. Plus précisément, la plupart des couches réseau, y compris les composants de VAE et les couches de suréchantillonnage et de sous-échantillonnage d'U-Net, sont initialisées à l'aide de poids pré-entraînés du modèle de diffusion stable. Cette stratégie accélère non seulement considérablement le processus de formation du modèle, mais garantit également que le modèle présente une bonne stabilité et fiabilité dès le début. Notre modèle peut générer de manière itérative des images supplémentaires à partir d'un clip vidéo initial contenant un petit nombre d'images en réutilisant les caractéristiques latentes d'origine et en imitant le processus de diffusion précédent. De plus, pour l'auto-encodeur utilisé pour convertir entre l'espace de pixels et l'espace latent, nous injectons des couches de réseau liées au timing dans son décodeur et affinons ces couches pour améliorer la cohérence temporelle.
Afin d'assurer la continuité entre les images vidéo, cet article ajoute les couches 3D Temp-conv et Temp-attn au modèle. La couche Temp-conv suit le 3D ResNet, qui implémente des opérations de convolution 3D pour capturer les corrélations spatiales et temporelles afin de comprendre la dynamique et la continuité de l'agrégation de séquences vidéo. La structure Temp-Attn est similaire à Self-attention et est utilisée pour analyser et comprendre la relation entre les images de la séquence vidéo, permettant au modèle de synchroniser avec précision les informations en cours d'exécution entre les images. Ces paramètres sont initialisés de manière aléatoire pendant la formation et sont conçus pour fournir au modèle une compréhension et un codage de la structure temporelle. De plus, afin de s'adapter à la structure du modèle, la saisie des données a également été adaptée et ajustée en conséquence.
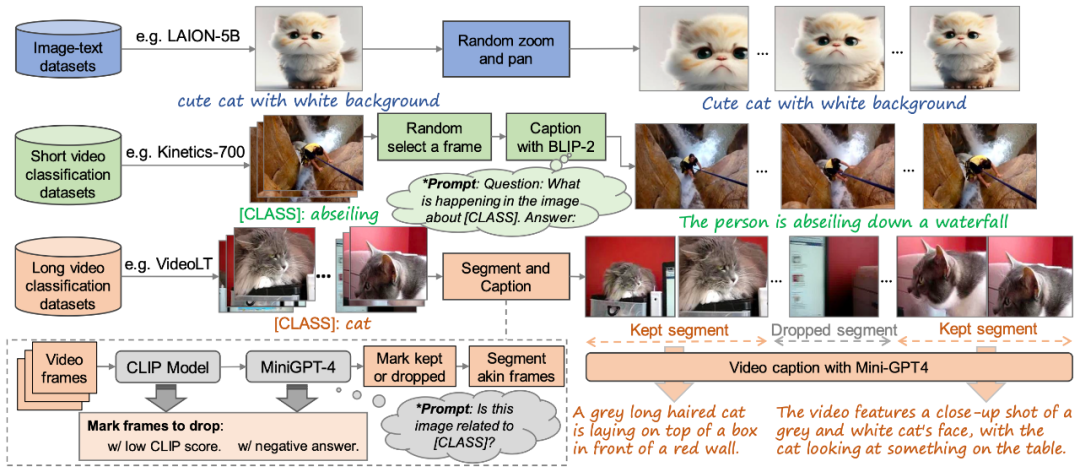
Figure 2. La méthode de construction de l'ensemble de données d'entraînement "texte-vidéo" de haute qualité proposée dans cet article
Afin d'entraîner le modèle VidRD, cet article propose une méthode pour construire un grand- Ensemble de données de formation à l'échelle « texte-vidéo » La méthode, comme le montre la figure 2, peut gérer des données « texte-image » et des données « texte-vidéo » sans description. De plus, afin d'obtenir une génération vidéo de haute qualité, cet article tente également de supprimer les filigranes sur les données d'entraînement.
Bien que les ensembles de données de description vidéo de haute qualité soient relativement rares sur le marché actuel, il existe un grand nombre d'ensembles de données de classification vidéo. Ces ensembles de données ont un contenu vidéo riche et chaque vidéo est accompagnée d'une étiquette de classification. Par exemple, Moments-In-Time, Kinetics-700 et VideoLT sont trois ensembles de données représentatifs de classification vidéo à grande échelle. Kinetics-700 couvre 700 catégories d'actions humaines et contient plus de 600 000 clips vidéo. Moments-In-Time comprend 339 catégories d'action, avec un total de plus d'un million de clips vidéo. VideoLT, quant à lui, contient 1 004 catégories et 250 000 vidéos longues non éditées.
Afin d'utiliser pleinement les données vidéo existantes, cet article tente d'annoter automatiquement ces vidéos plus en détail. Cet article utilise de grands modèles de langage multimodaux tels que BLIP-2 et MiniGPT4. En ciblant les images clés de la vidéo et en combinant leurs étiquettes de classification d'origine, cet article conçoit de nombreuses invites pour générer des annotations via un modèle de questions et réponses. Cette méthode améliore non seulement les informations vocales des données vidéo, mais apporte également des descriptions vidéo plus complètes et détaillées aux vidéos existantes qui n'ont pas de descriptions détaillées, permettant ainsi une génération de balises vidéo plus riches pour aider le modèle VidRD à apporter un meilleur effet de formation.
De plus, pour les données d'image très riches existantes, cet article a également conçu une méthode détaillée pour convertir les données d'image au format vidéo pour la formation. L'opération spécifique consiste à effectuer un panoramique et un zoom sur différentes positions de l'image à différentes vitesses, donnant ainsi à chaque image une forme de présentation dynamique unique et simulant l'effet du déplacement d'une caméra pour capturer des objets fixes dans la vie réelle. Grâce à cette méthode, les données d'images existantes peuvent être utilisées efficacement pour la formation vidéo.
Les textes de description sont : "Timelapse sur un pays enneigé avec une aurore dans le ciel.", "Une bougie brûle.", "Une tornade épique attaquant au-dessus d'une ville lumineuse la nuit." , et "Vue aérienne d'une plage de sable blanc au bord d'une mer magnifique." D’autres visualisations peuvent être trouvées sur la page d’accueil du projet.

Figure 3. Comparaison visuelle de l'effet de génération avec les méthodes existantes
Enfin, comme le montre la figure 3, les résultats de génération de cet article sont comparés aux méthodes existantes Make-A-Video [3 ] et La comparaison visuelle d'Imagen Video [4] montre l'effet de génération de meilleure qualité du modèle dans cet article.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



