


Désormais, l'IA peut interpréter les signaux cérébraux en temps réel !
Ce n'est pas sensationnel, mais une nouvelle étude de Meta, qui peut deviner l'image que vous regardez en 0,5 seconde sur la base de signaux cérébraux et utiliser l'IA pour la restaurer en temps réel.
Avant cela, bien que l'IA ait été capable de restaurer des images à partir de signaux cérébraux de manière relativement précise, il y a toujours un bug : elle n'est pas assez rapide.
À cette fin, Meta a développé un nouveau modèle de décodage, qui augmente de 7 fois la vitesse de récupération des images de l'IA. Il peut lire presque « instantanément » ce que les gens regardent et faire une estimation approximative.
On dirait un homme debout. Après plusieurs restaurations, l'IA a en fait interprété un "homme debout" :
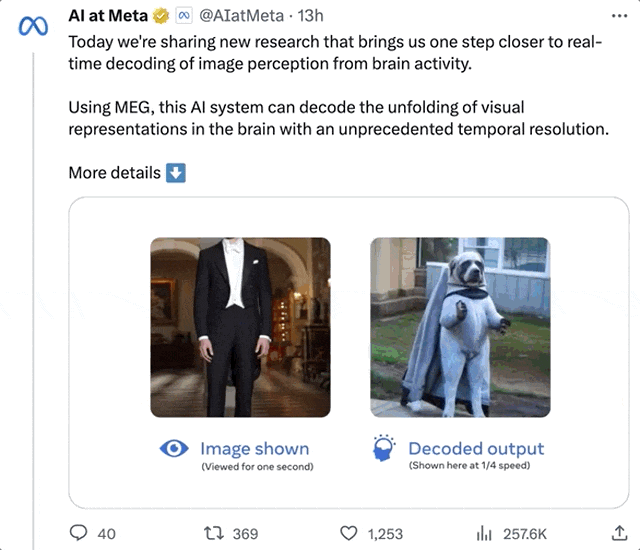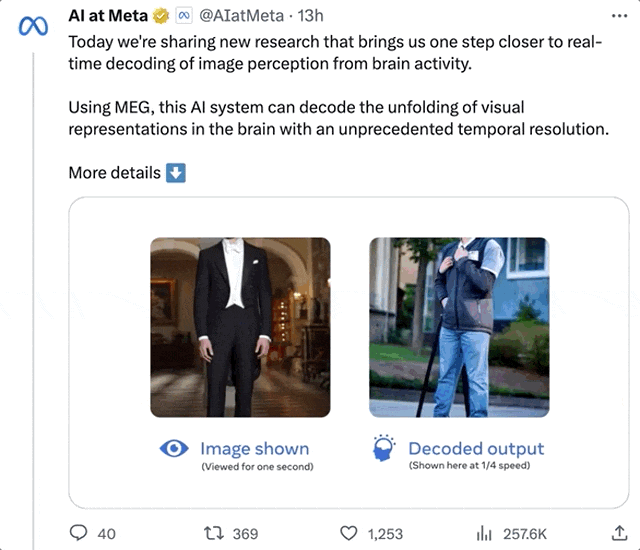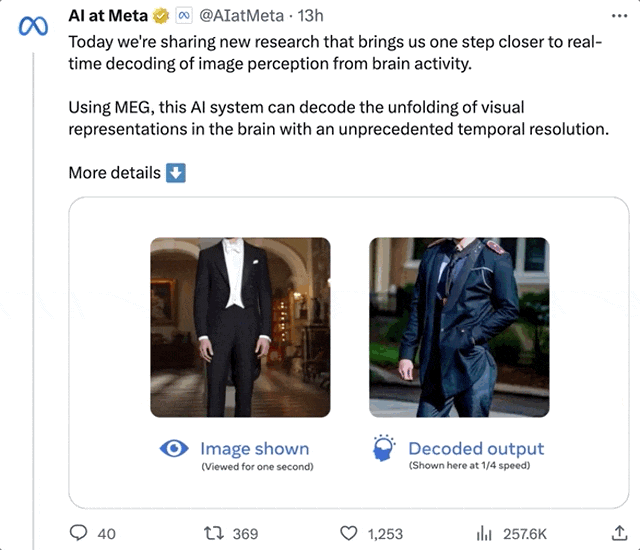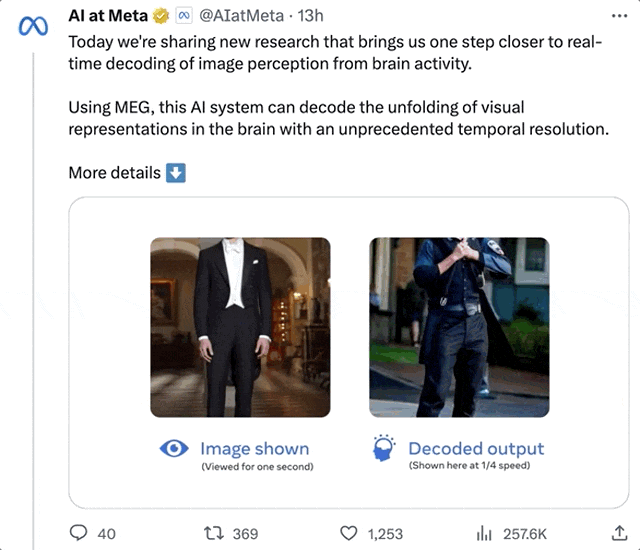 Photo
Photo
LeCun l'a transmise pour reconstruire les entrées visuelles et autres des signaux cérébraux MEG. La recherche est vraiment géniale. .
 Photos
Photos
Alors, comment Meta permet-il à l'IA de « lire rapidement les cerveaux » ?
Actuellement, l'IA dispose de deux méthodes principales pour lire les signaux cérébraux et restaurer les images.
L'une est l'IRMf (imagerie par résonance magnétique fonctionnelle), qui peut générer des images du flux sanguin vers des parties spécifiques du cerveau ; l'autre est la MEG (magnétoencéphalographie), qui peut mesurer des champs magnétiques biologiques extrêmement faibles émis par les courants nerveux dans le cerveau. .
Cependant, la vitesse de la neuroimagerie IRMf est souvent très lente, avec une moyenne de 2 secondes pour produire une image (≈0,5 Hz). En revanche, la MEG peut même enregistrer des milliers d'images d'activité cérébrale par seconde (≈5000 Hz).
Alors par rapport à l'IRMf, pourquoi ne pas utiliser les données MEG pour tenter de restaurer « l'image vue par les humains » ?
Sur la base de cette idée, les auteurs ont conçu un modèle de décodage MEG composé de trois parties.
La première partie est un modèle pré-entraîné, responsable de l'obtention des intégrations à partir d'images
La deuxième partie est un modèle de formation de bout en bout, responsable de l'alignement des données MEG avec les intégrations d'images ;
La troisième partie est un modèle ; générateur d'images pré-entraîné, responsable de la restauration de l'image finale.
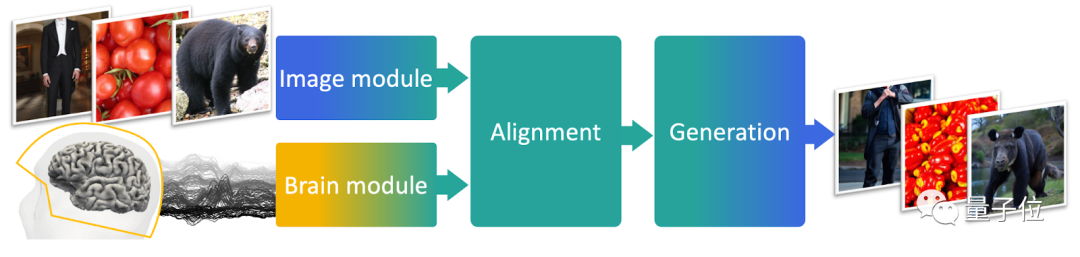 Photos
Photos
Pour la formation, les chercheurs ont utilisé un ensemble de données appelé THINGS-MEG, qui contient des données MEG enregistrées lorsque 4 jeunes (2 hommes et 2 femmes, âgés en moyenne de 23,25 ans) ont regardé des images.
Ces jeunes ont visionné un total de 22 448 images (1 854 types). Chaque image a été affichée pendant 0,5 seconde et l'intervalle était de 0,8 à 1,2 seconde. 200 d'entre elles ont été visionnées à plusieurs reprises.
De plus, 3659 images n'ont pas été montrées aux participants mais ont également été utilisées dans la récupération d'images.
Alors, quel est l'effet de l'IA entraînée de cette manière ?
Dans l'ensemble, le modèle de décodage MEG conçu dans cette recherche est 7 fois plus rapide que le décodeur linéaire en récupération d'images.
Parmi eux, par rapport à des modèles tels que CLIP, l'architecture visuelle Transformer DINOv2 développée par Meta est plus performante dans l'extraction des caractéristiques de l'image et peut mieux aligner les données MEG et les intégrations d'images.
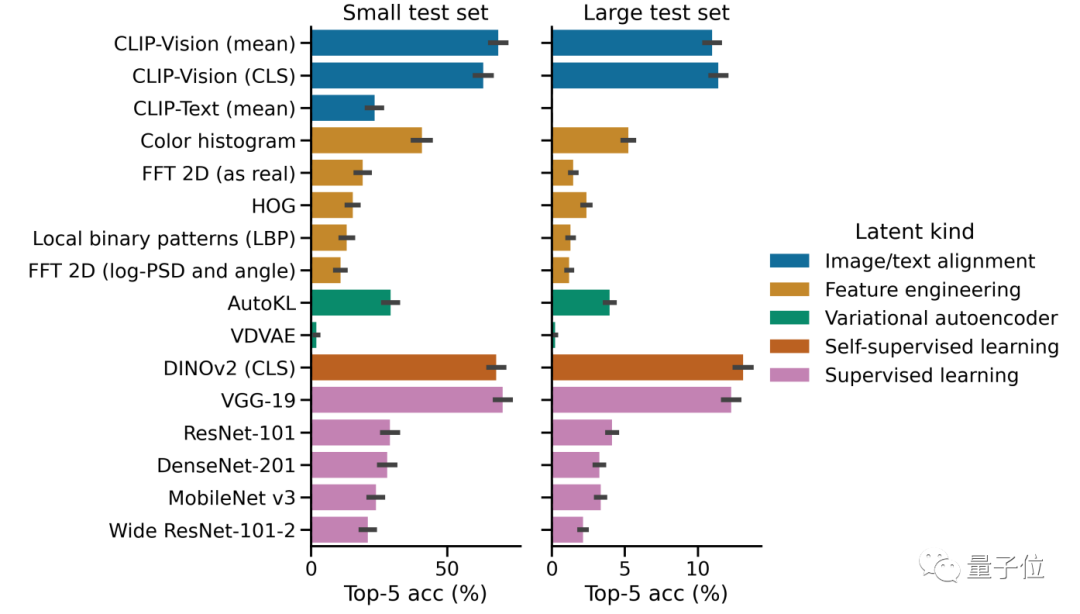 Images
Images
Les auteurs ont divisé l'ensemble des images générées en trois catégories principales, le degré de correspondance le plus élevé, le degré de correspondance moyen et le degré de correspondance le plus mauvais :
 Images
Images
Cependant, à partir des exemples générés, regardez , l'effet d'image restitué par cette IA n'est en effet pas très bon.
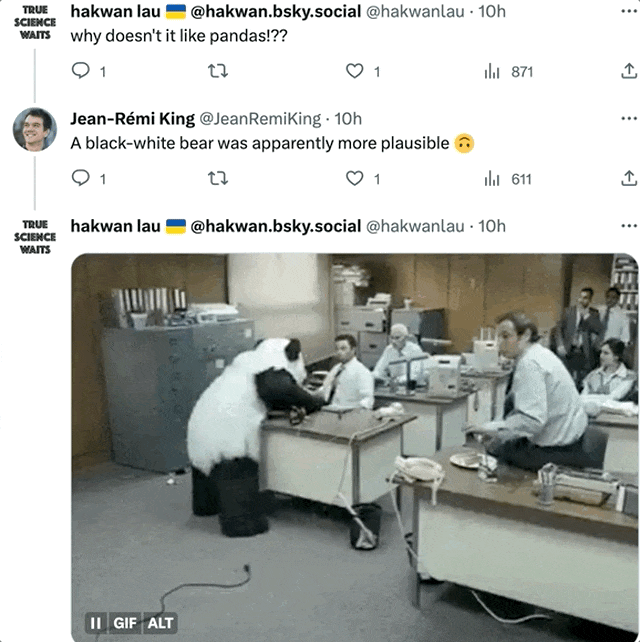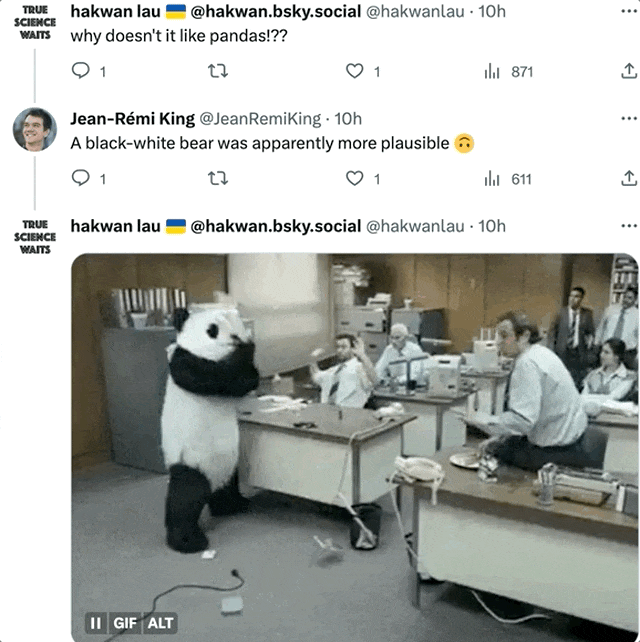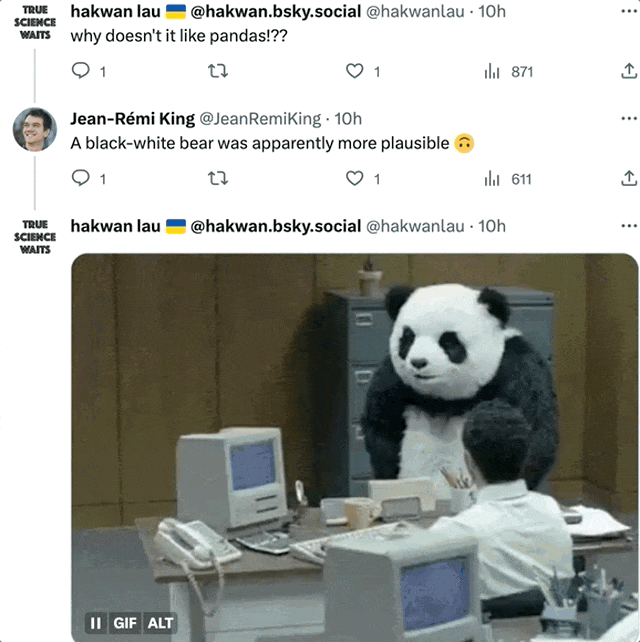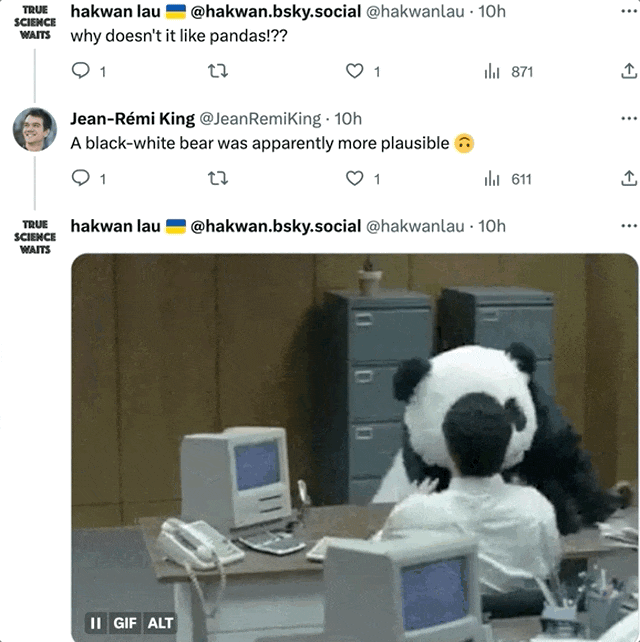
Même l'image la plus restaurée est encore remise en question par certains internautes : Pourquoi le panda ne ressemble-t-il en rien à un panda ?
 Photos
Photos
L'auteur a dit : Au moins comme un ours noir et blanc. (Le panda est furieux !)
 Photos
Photos
Bien sûr, les chercheurs admettent également que l'effet d'image restauré à partir des données MEG n'est en effet pas très bon à l'heure actuelle, et le principal avantage est la rapidité.
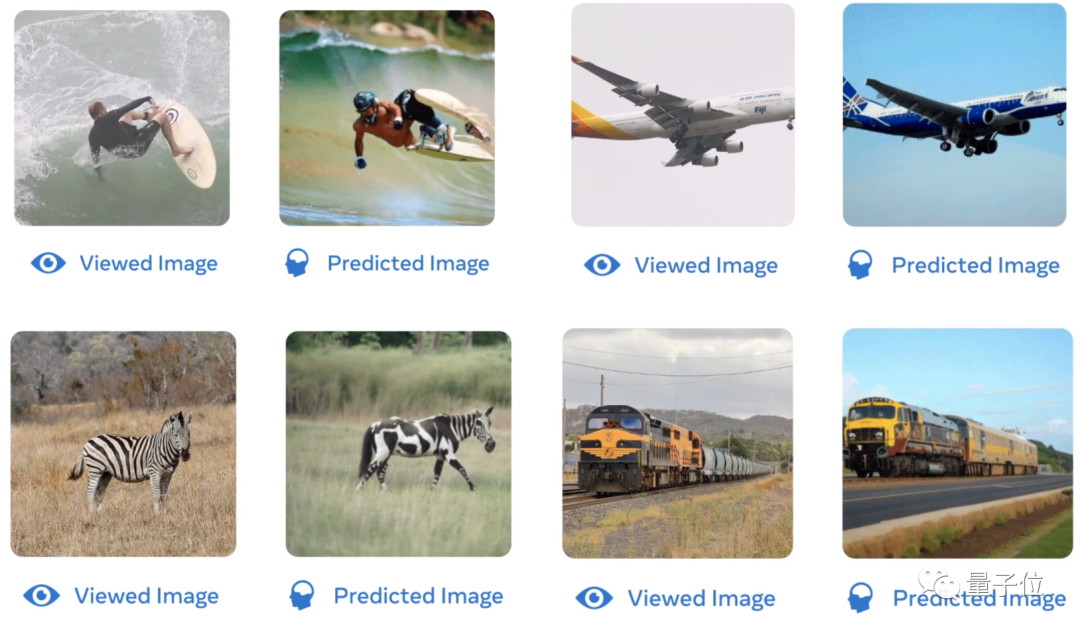
Par exemple, une étude antérieure appelée IRMf 7T de l'Université du Minnesota et d'autres institutions peut restaurer l'image vue par l'œil humain à partir des données IRMf avec un degré élevé de récupération.
 Photos
Photos
Qu'il s'agisse des mouvements de surf humains, de la forme d'un avion, de la couleur des zèbres ou de l'arrière-plan d'un train, l'IA entraînée sur la base des données IRMf peut mieux restituer l'image :
 Photos
Photos
Les auteurs ont également donné une explication à cela, estimant que cela est dû au fait que les fonctionnalités visuelles restaurées par l'IA basée sur MEG sont relativement avancées.
Mais en comparaison, l'IRMf 7T peut extraire et restaurer les caractéristiques visuelles de niveau inférieur dans l'image, de sorte que la restauration globale de l'image générée soit plus élevée.
Où pensez-vous que ce type de recherche peut être utilisé ?
Adresse papier :
//m.sbmmt.com/link/f40723ed94042ea9ea36bfb5ad4157b2
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment obtenir le numéro d'entrée en Java
Comment obtenir le numéro d'entrée en Java
 Douyin ne peut pas télécharger et enregistrer des vidéos
Douyin ne peut pas télécharger et enregistrer des vidéos
 Quel est le rôle du serveur sip
Quel est le rôle du serveur sip
 lightbox.js
lightbox.js
 le bios ne peut pas détecter le disque SSD
le bios ne peut pas détecter le disque SSD
 Comment configurer WeChat pour qu'il exige mon consentement lorsque des personnes m'ajoutent à un groupe ?
Comment configurer WeChat pour qu'il exige mon consentement lorsque des personnes m'ajoutent à un groupe ?
 Mongodb et MySQL sont faciles à utiliser et recommandés
Mongodb et MySQL sont faciles à utiliser et recommandés








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



