


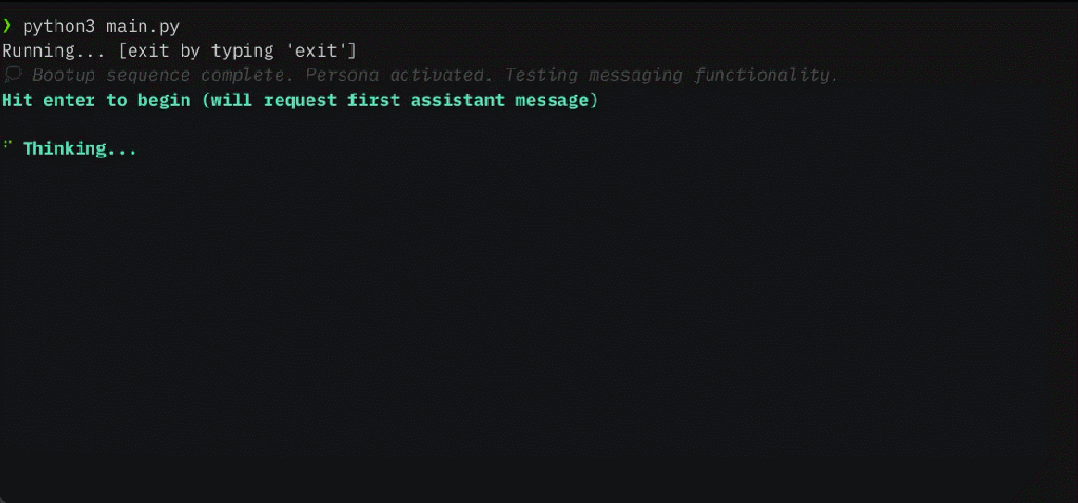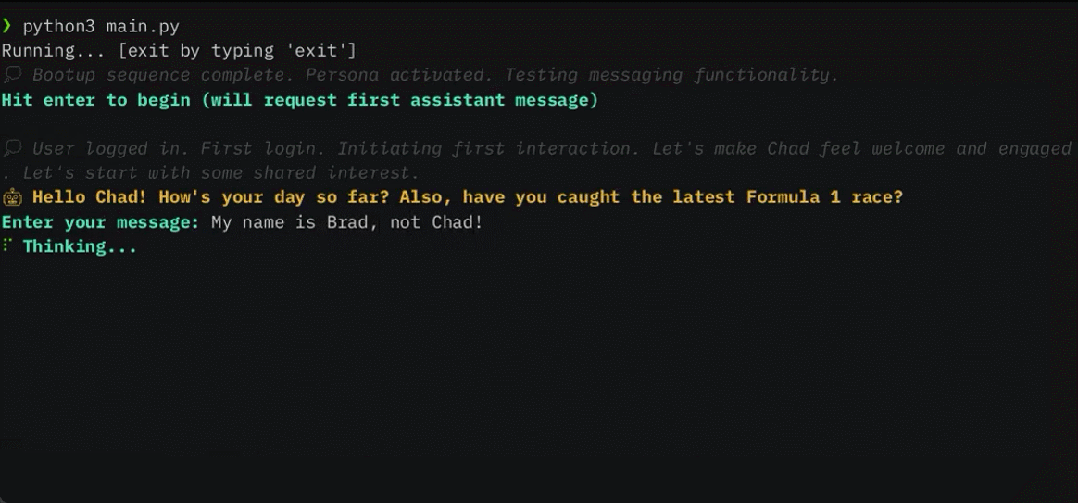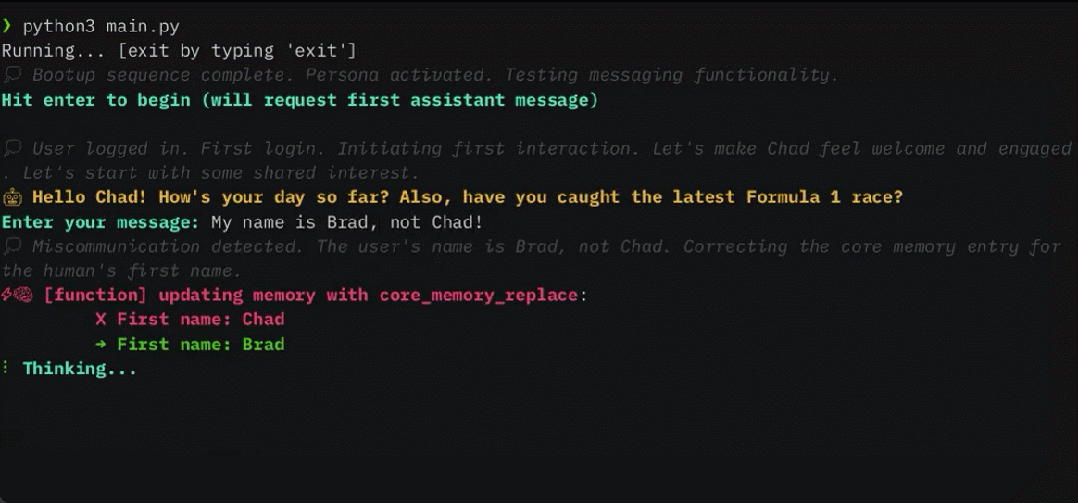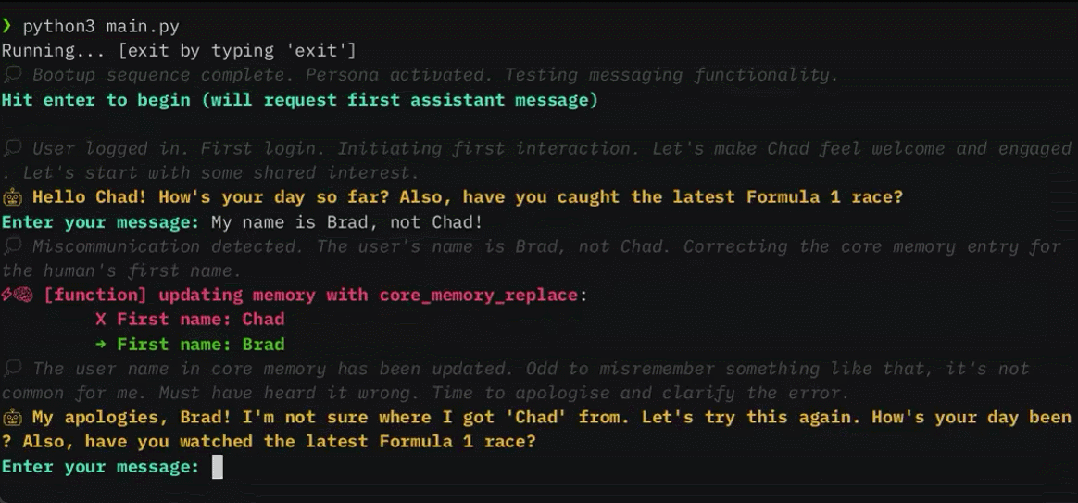
Ces dernières années, les grands modèles de langage (LLM) et leur architecture de transformateur sous-jacente sont devenus la pierre angulaire de l'IA conversationnelle et ont donné naissance à un large éventail d'applications grand public et d'entreprise. Malgré des progrès considérables, la fenêtre contextuelle de longueur fixe utilisée par LLM limite considérablement l'applicabilité aux longues conversations ou au raisonnement sur de longs documents. Même pour les LLM open source les plus largement utilisés, leur longueur d'entrée maximale ne permet que la prise en charge de quelques dizaines de réponses aux messages ou d'inférences de documents courts.
Dans le même temps, limité par le mécanisme d'auto-attention de l'architecture du transformateur, la simple extension de la longueur du contexte du transformateur entraînera également une augmentation exponentielle du temps de calcul et du coût de la mémoire, ce qui fait de la nouvelle architecture de contexte long une recherche urgente. sujet.
Cependant, même si nous pouvons surmonter les défis informatiques liés à la mise à l'échelle du contexte, des recherches récentes montrent que les modèles à contexte long ont du mal à utiliser efficacement le contexte supplémentaire.
Comment résoudre cela ? Compte tenu des ressources massives requises pour former SOTA LLM et des rendements apparemment décroissants de la mise à l'échelle du contexte, nous avons un besoin urgent de techniques alternatives prenant en charge les contextes longs. Des chercheurs de l’Université de Californie à Berkeley ont réalisé de nouveaux progrès à cet égard.
Dans cet article, les chercheurs explorent comment créer l'illusion d'un contexte infini tout en continuant à utiliser un modèle de contexte fixe. Leur approche emprunte des idées à la pagination de la mémoire virtuelle, permettant aux applications de traiter des ensembles de données dépassant largement la mémoire disponible.
Sur la base de cette idée, les chercheurs ont profité des dernières avancées en matière de capacités d'appel de fonctions d'agent LLM pour concevoir un système LLM inspiré du système d'exploitation pour la gestion du contexte virtuel - MemGPT.

Page d'accueil du papier : https://memgpt.ai/
Adresse arXiv : https://arxiv.org/pdf/2310.08560.pdf
Le projet est open source et a gagné 1,7k étoiles sur GitHub quantité.
Adresse GitHub : https://github.com/cpacker/MemGPT
Présentation de la méthode
Cette recherche s'inspire de la gestion hiérarchique de la mémoire des systèmes d'exploitation traditionnels, dans des fenêtres contextuelles (similaires aux systèmes d'exploitation) Informations de « page » entrant et sortant entre la « mémoire principale ») et le stockage externe. MemGPT est responsable de la gestion du flux de contrôle entre la mémoire, les modules de traitement LLM et les utilisateurs. Cette conception permet une modification itérative du contexte au cours d'une seule tâche, permettant à l'agent d'utiliser plus efficacement sa fenêtre contextuelle limitée.
MemGPT traite les fenêtres contextuelles comme des ressources de mémoire contraintes et conçoit une structure hiérarchique pour LLM similaire à la mémoire hiérarchique des systèmes d'exploitation traditionnels (Patterson et al., 1988). Afin de fournir une longueur de contexte plus longue, cette recherche permet à LLM de gérer le contenu placé dans sa fenêtre contextuelle via "LLM OS" - MemGPT. MemGPT permet à LLM de récupérer des données historiques pertinentes perdues dans leur contexte, à l'instar des défauts de page dans les systèmes d'exploitation. De plus, les agents peuvent modifier de manière itérative le contenu d’une fenêtre contextuelle de tâche unique, tout comme un processus peut accéder de manière répétée à la mémoire virtuelle.
MemGPT permet à LLM de gérer des contextes illimités lorsque la fenêtre de contexte est limitée. Les composants de MemGPT sont présentés dans la figure 1 ci-dessous.
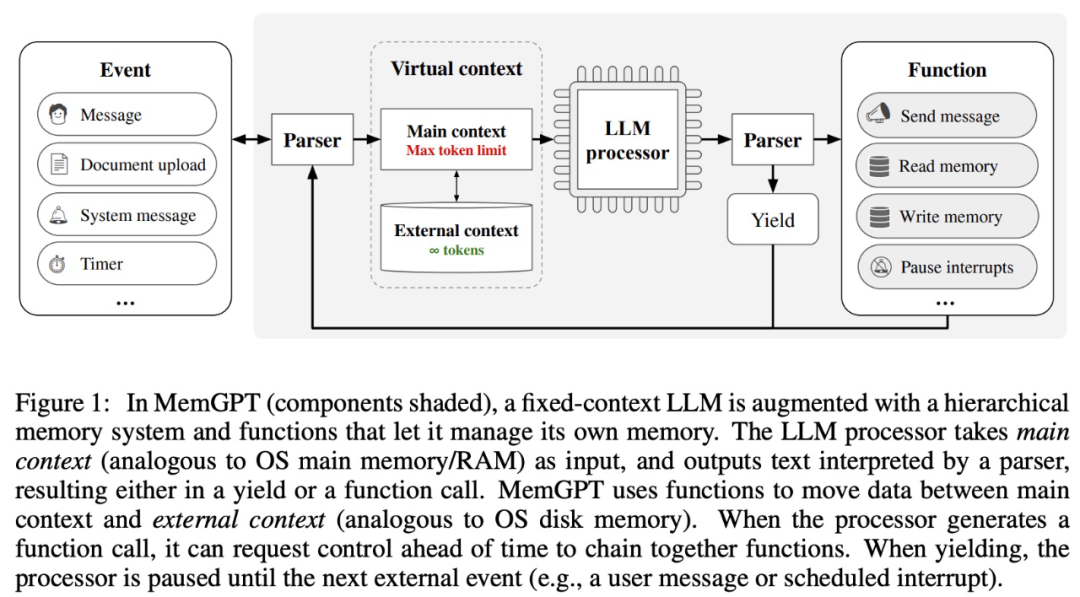
MemGPT coordonne le mouvement des données entre le contexte principal (contenu dans la fenêtre contextuelle) et le contexte externe via des appels de fonction, des mises à jour et des récupérations de manière autonome en fonction du contexte actuel.


Il convient de noter que la fenêtre contextuelle doit utiliser un jeton d'avertissement pour marquer ses limites, comme le montre la figure 3 ci-dessous :

Expériences et résultats
Dans la partie expérimentale, les chercheurs ont évalué MemGPT dans deux domaines à contexte long, à savoir les agents conversationnels et le traitement de documents. Pour les agents conversationnels, ils ont étendu l'ensemble de données de discussion multisession existant (Xu et al. (2021)) et introduit deux nouvelles tâches de conversation pour évaluer la capacité de l'agent à conserver ses connaissances lors de longues conversations. Pour l'analyse des documents, ils comparent MemGPT sur les tâches proposées par Liu et al. (2023a), notamment la réponse aux questions et la récupération des valeurs-clés de documents longs.
MemGPT pour les agents conversationnels
Lorsqu'il parle à l'utilisateur, l'agent doit répondre aux deux critères clés suivants.
L'une est la cohérence, c'est-à-dire que l'agent doit maintenir la cohérence de la conversation, et les nouveaux faits, références et événements fournis doivent être cohérents avec les déclarations précédentes de l'utilisateur et de l'agent.
La seconde est la participation, c'est-à-dire que l'agent doit utiliser les connaissances à long terme de l'utilisateur pour personnaliser la réponse. Faire référence à des conversations précédentes peut rendre la conversation plus naturelle et engageante.
Par conséquent, les chercheurs ont évalué MemGPT sur la base de ces deux critères :
MemGPT peut-il exploiter sa mémoire pour améliorer la cohérence conversationnelle ? Pouvez-vous vous souvenir de faits, de citations et d’événements pertinents issus d’interactions passées pour maintenir la cohérence ?
MemGPT peut-il utiliser la mémoire pour générer des conversations plus engageantes ? Fusionner spontanément les informations des utilisateurs distants pour personnaliser les informations ?
Concernant l'ensemble de données utilisé, les chercheurs ont évalué MemGPT et des modèles de base à contexte fixe sur le chat multi-session (MSC) proposé par Xu et al.
Commençons par l’évaluation de la cohérence. Les chercheurs ont introduit une tâche de récupération de mémoire profonde (DMR) basée sur l'ensemble de données MSC pour tester la cohérence de l'agent conversationnel. Dans DMR, un utilisateur pose une question à un agent conversationnel, et la question fait explicitement référence à une conversation précédente, en espérant que la plage de réponses sera très étroite. Pour plus de détails, veuillez vous référer à l'exemple de la figure 5 ci-dessous.
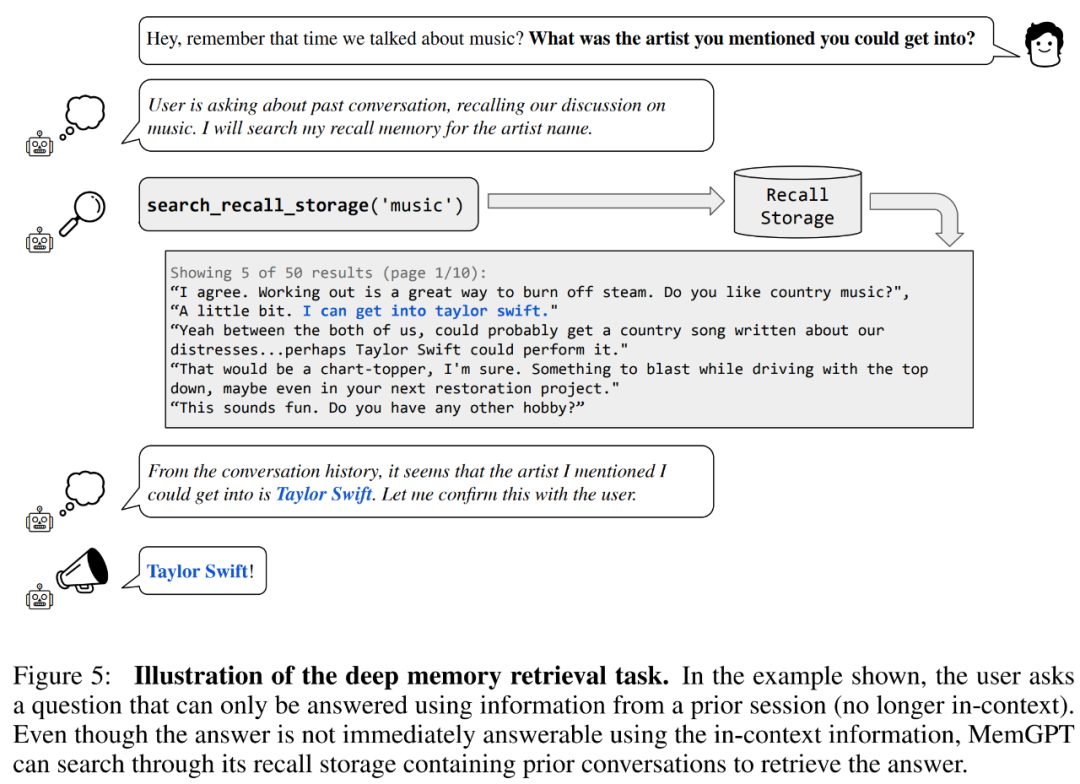
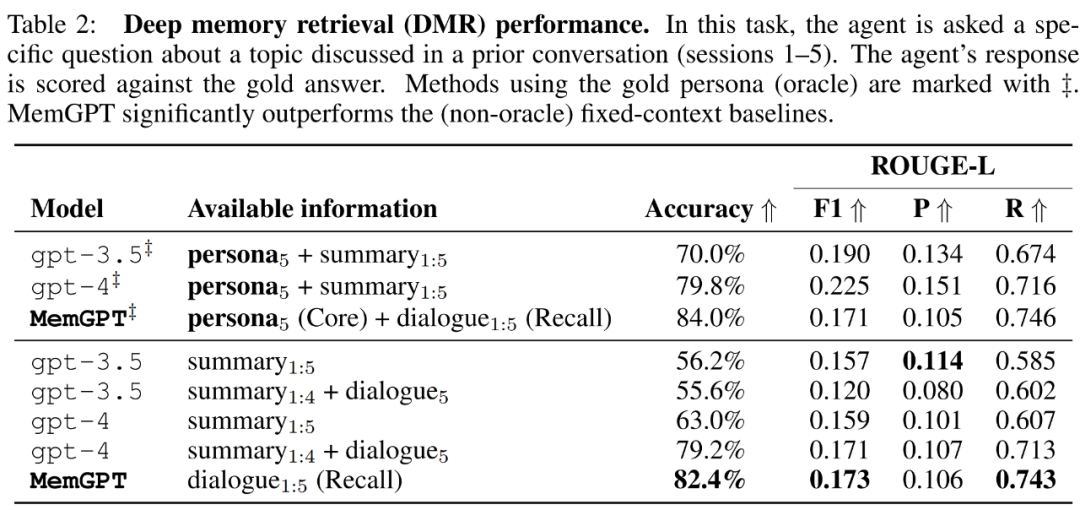
MemGPT utilise la mémoire pour maintenir la cohérence. Le tableau 2 ci-dessous montre la comparaison des performances de MemGPT par rapport aux modèles de base de mémoire fixe, notamment GPT-3.5 et GPT-4.
On peut voir que MemGPT est nettement meilleur que GPT-3.5 et GPT-4 en termes de précision du jugement LLM et de score ROUGE-L. MemGPT peut utiliser la mémoire de rappel pour interroger l'historique des conversations passées afin de répondre aux questions DMR, plutôt que de s'appuyer sur un résumé récursif pour élargir le contexte.
Puis dans la tâche « Conversation Starter », les chercheurs ont évalué la capacité de l'agent à extraire des messages engageants à partir des connaissances accumulées lors des conversations précédentes et à les transmettre à l'utilisateur.
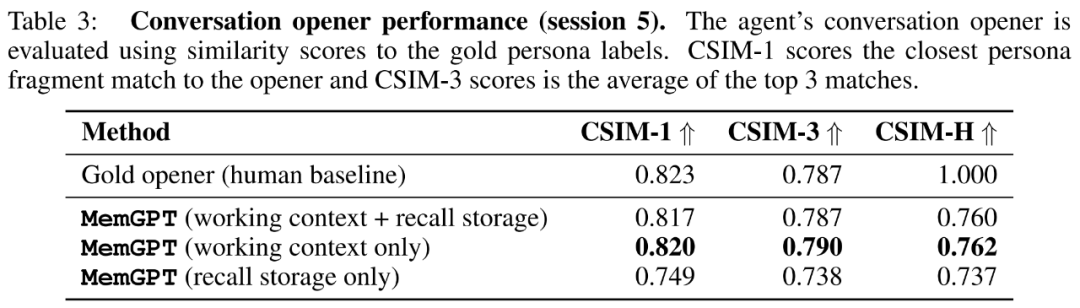
Les chercheurs présentent les scores CSIM des remarques liminaires de MemGPT dans le tableau 3 ci-dessous. Les résultats montrent que MemGPT est capable de produire des intros attrayantes qui fonctionnent aussi bien, voire mieux, que les intros manuscrites humaines. On observe également que MemGPT a tendance à produire des ouvertures plus longues et couvrant plus d’informations sur les caractères que la ligne de base humaine. La figure 6 ci-dessous est un exemple.

MemGPT pour l'analyse de documents
Pour évaluer la capacité de MemGPT à analyser des documents, les chercheurs ont effectué MemGPT et la fixation sur la tâche d'assurance qualité des documents de récupération et de lecture de Liu et al (2023a). Les modèles de base contextuels sont comparés.
Les résultats montrent que MemGPT est capable d'effectuer efficacement plusieurs appels au récupérateur en interrogeant le stockage d'archives, lui permettant ainsi de s'adapter à des longueurs de contexte efficaces plus grandes. MemGPT récupère activement les documents du magasin d'archives et peut parcourir les résultats de manière itérative afin que le nombre total de documents disponibles ne soit plus limité par le nombre de documents dans la fenêtre contextuelle du processeur LLM applicable.
En raison des limites de la recherche de similarité basée sur l'intégration, la tâche d'assurance qualité des documents pose un grand défi à toutes les méthodes. Les chercheurs ont observé que MemGPT arrête de paginer les résultats du robot avant que la base de données du robot ne soit épuisée.
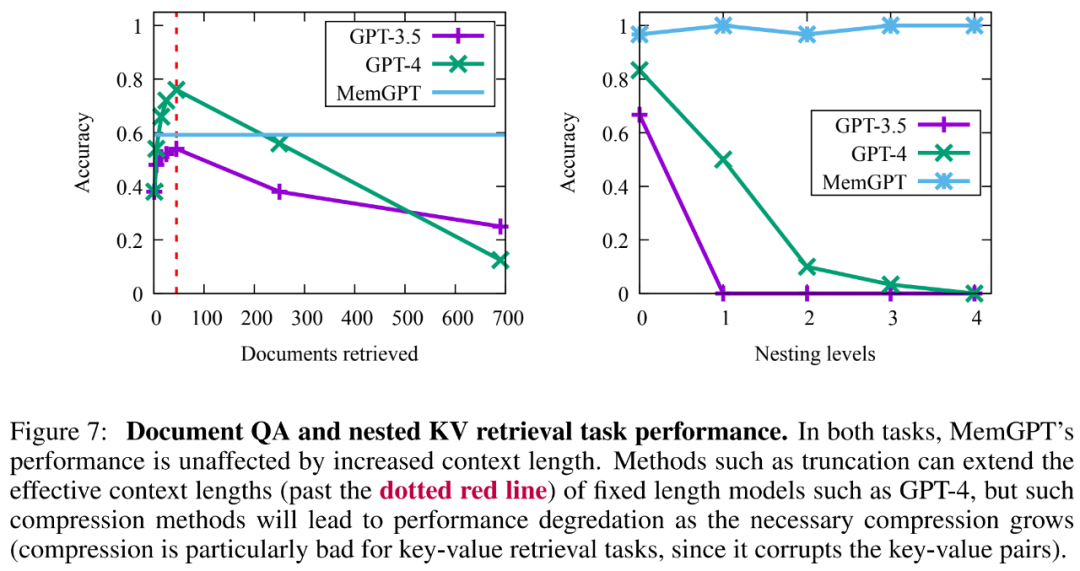
De plus, il existe un compromis dans la capacité des documents récupérés créés par des opérations plus complexes de MemGPT, comme le montre la figure 7 ci-dessous. Sa précision moyenne est inférieure à GPT-4 (supérieure à GPT-3.5), mais. il peut être facilement adapté à des documents plus volumineux.
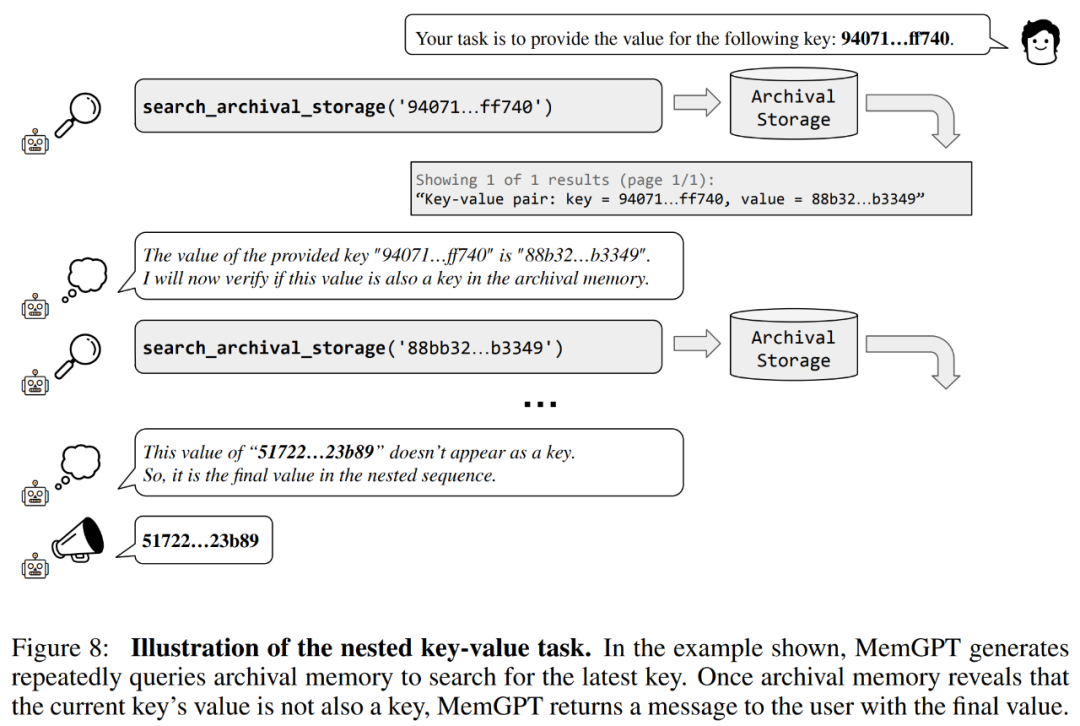
Les chercheurs ont également introduit une nouvelle tâche basée sur la récupération synthétique de valeurs-clés, à savoir la récupération de valeurs-clés imbriquées, pour démontrer comment MemGPT organise les informations provenant de plusieurs sources de données.
D'après les résultats, bien que GPT-3.5 et GPT-4 aient montré de bonnes performances sur la tâche de valeur-clé d'origine, ils ont donné de mauvais résultats sur la tâche de récupération de valeur-clé imbriquée. MemGPT n'est pas affecté par le nombre de niveaux d'imbrication et peut effectuer des recherches imbriquées en accédant de manière répétée aux paires clé-valeur stockées dans la mémoire principale via des requêtes de fonction.
Les performances de MemGPT sur les tâches de récupération de valeurs-clés imbriquées démontrent sa capacité à effectuer plusieurs recherches en utilisant une combinaison de plusieurs requêtes.
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment vérifier les liens morts sur votre site Web
Comment vérifier les liens morts sur votre site Web
 Que signifie le code open source ?
Que signifie le code open source ?
 paramètres des variables d'environnement Java
paramètres des variables d'environnement Java
 Quels sont les moteurs de recherche d'annuaire ?
Quels sont les moteurs de recherche d'annuaire ?
 Dernier prix d'ondulation
Dernier prix d'ondulation
 Comment accéder au lecteur D avec cmd
Comment accéder au lecteur D avec cmd
 Quelle plateforme est la meilleure pour le trading de devises virtuelles ?
Quelle plateforme est la meilleure pour le trading de devises virtuelles ?
 Utilisation de la fonction sprintf en php
Utilisation de la fonction sprintf en php








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



