


Le but de l'apprentissage continu est d'imiter la capacité des humains à accumuler continuellement des connaissances dans des tâches continues. Son principal défi est de savoir comment maintenir la performance des tâches précédemment apprises après avoir continué à apprendre de nouvelles tâches, c'est-à-dire éviter un oubli catastrophique. (oubli catastrophique) . La différence entre l'apprentissage continu et l'apprentissage multitâche est que ce dernier peut obtenir toutes les tâches en même temps, et le modèle peut apprendre toutes les tâches en même temps ; tandis qu'en apprentissage continu, les tâches apparaissent une par une et le modèle peut apprendre toutes les tâches en même temps. Apprenez uniquement des connaissances sur une tâche et évitez d'oublier les anciennes connaissances lors du processus d'apprentissage de nouvelles connaissances.
L'Université de Californie du Sud et Google Research ont proposé une nouvelle méthode pour résoudre l'apprentissage continu Reprogrammation légère par canal (CLR) : en ajoutant des modules légers entraînables à l'épine dorsale inchangée des tâches fixes , la carte des caractéristiques de chaque couche de canaux est reprogrammée, ce qui rend la carte des caractéristiques reprogrammée adaptée à de nouvelles tâches. Ce module léger entraînable ne représente que 0,6 % de l'ensemble du backbone. Chaque nouvelle tâche peut avoir son propre module léger. En théorie, une infinité de nouvelles tâches peuvent être apprises en continu sans oubli catastrophique. L’article a été publié dans ICCV 2023.

Habituellement, les méthodes pour résoudre l'apprentissage continu sont principalement divisées en trois catégories : méthodes basées sur la régularisation, réseau dynamique méthodes et méthodes de relecture.
La méthode CLR proposée dans cet article est une méthode de réseau dynamique. La figure ci-dessous représente le déroulement de l'ensemble du processus : les chercheurs utilisent la partie immuable indépendante de la tâche comme paramètres partagés spécifiques à la tâche, et ajoutent des paramètres spécifiques à la tâche pour recoder les caractéristiques du canal. Dans le même temps, afin de minimiser la quantité de formation des paramètres de recodage pour chaque tâche, les chercheurs n'ont besoin que d'ajuster la taille du noyau dans le modèle et d'apprendre une cartographie linéaire des canaux depuis la base jusqu'aux connaissances spécifiques à la tâche pour mettre en œuvre le recodage. . En apprentissage continu, chaque nouvelle tâche peut être entraînée pour obtenir un modèle léger ; ce modèle léger nécessite très peu de paramètres d'entraînement. Même s'il y a de nombreuses tâches, le nombre total de paramètres à entraîner est très faible par rapport à un grand modèle. .Petit et chaque modèle léger peut obtenir de bons résultats
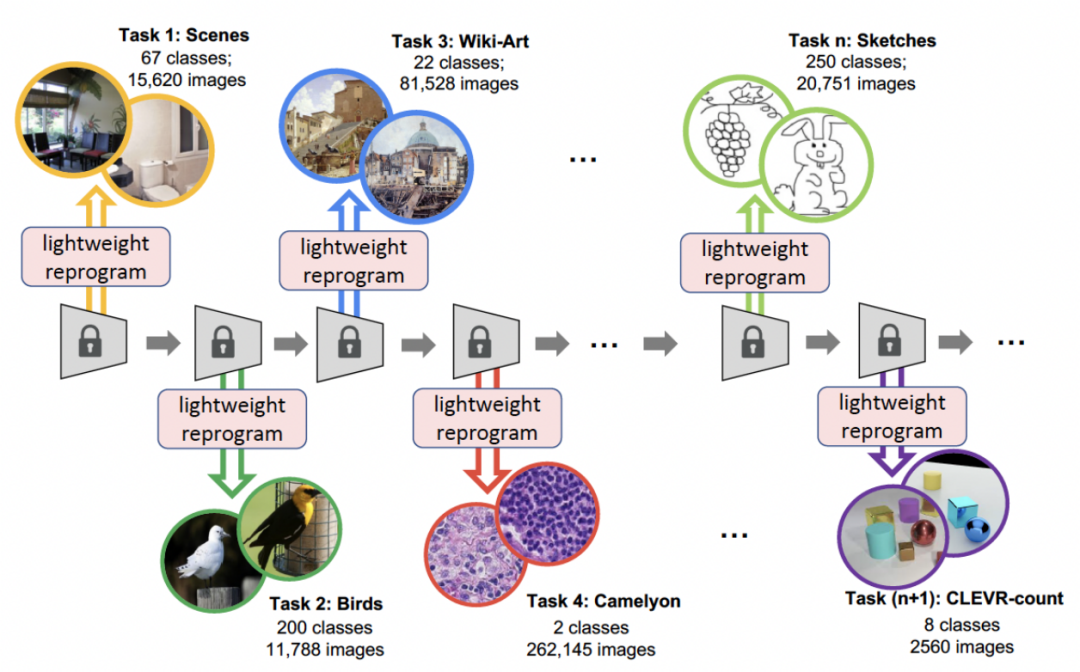
L'apprentissage continu se concentre sur le problème de l'apprentissage à partir de flux de données, c'est-à-dire l'apprentissage de nouvelles tâches dans un ordre spécifique, l'expansion continue de la tâche. connaissances qu'il a acquises en évitant d'oublier des tâches antérieures, comment éviter des oublis catastrophiques est donc un enjeu majeur dans la recherche sur l'apprentissage continu. Les chercheurs considèrent les trois aspects suivants :
Recodage léger basé sur les canauxUtilisez d'abord un squelette fixe comme structure de partage des tâches, qui peut être un ensemble de données relativement diversifié (ImageNet-1k, Pascal VOC), ou un modèle d'apprentissage auto-supervisé (DINO, SwAV) qui apprend sur les tâches des agents sans étiquettes sémantiques. Différent des autres méthodes d'apprentissage continu (telles que SUPSUP utilisant une structure fixe initialisée de manière aléatoire, CCLL et EFT utilisant le modèle appris de la première tâche comme épine dorsale), le modèle pré-entraîné utilisé par CLR peut fournir une variété de fonctionnalités visuelles, mais celles-ci caractéristiques visuelles Les fonctionnalités nécessitent des couches CLR pour le recodage sur d'autres tâches. Plus précisément, les chercheurs ont utilisé une transformation linéaire par canal pour ré-encoder l'image caractéristique générée par le noyau de convolution d'origine.
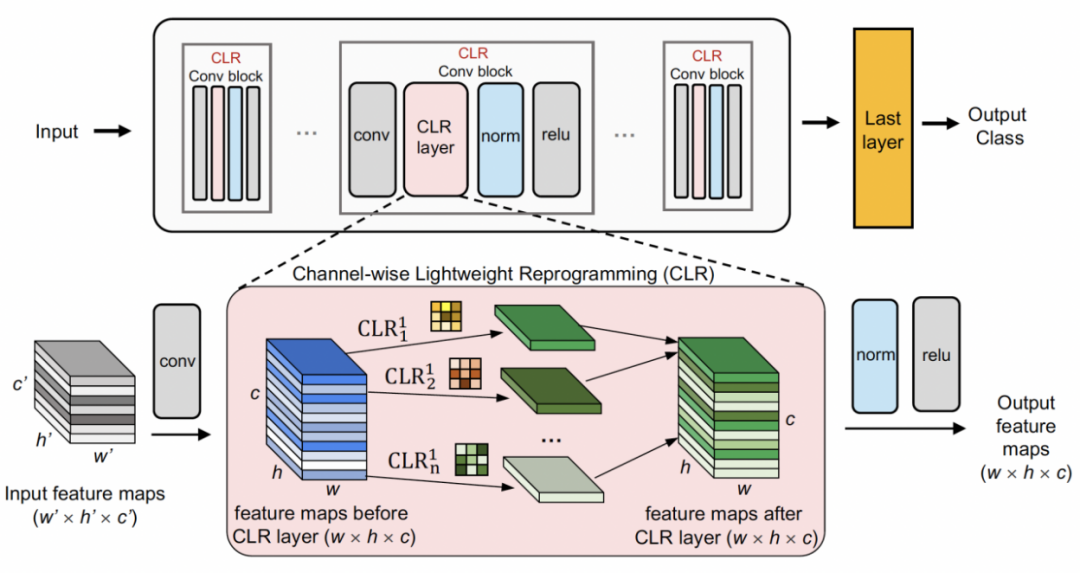
Les chercheurs ont d'abord corrigé le squelette pré-entraîné, puis ont ajouté une couche de reprogrammation légère canalisée (couche CLR) après la couche de convolution dans chaque bloc de convolution fixe pour affiner les caractéristiques après le noyau de convolution fixe. comme des changements linéaires.
À partir d'une image X, pour chaque noyau de convolution Réseaux dynamiques : PSP, SupSup, CCLL, Confit, EFTs Replay : ER, DERPP
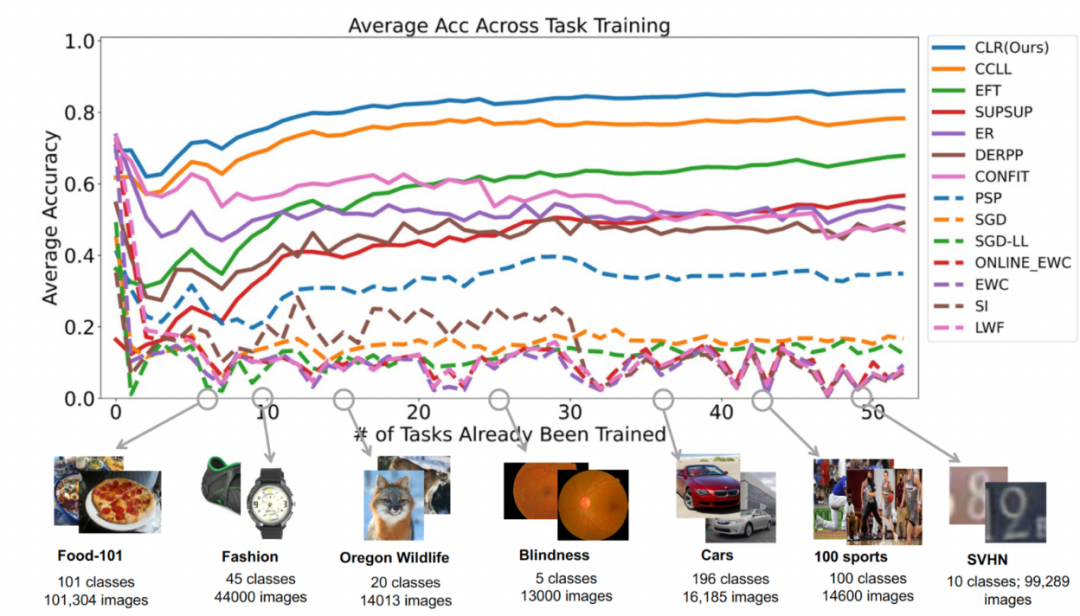
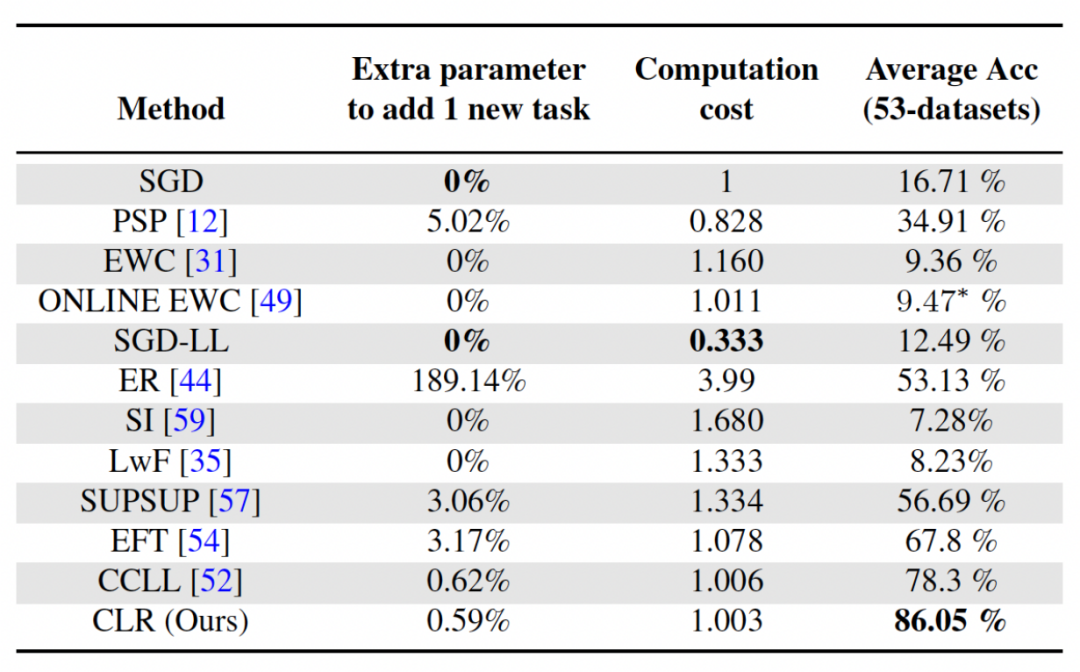
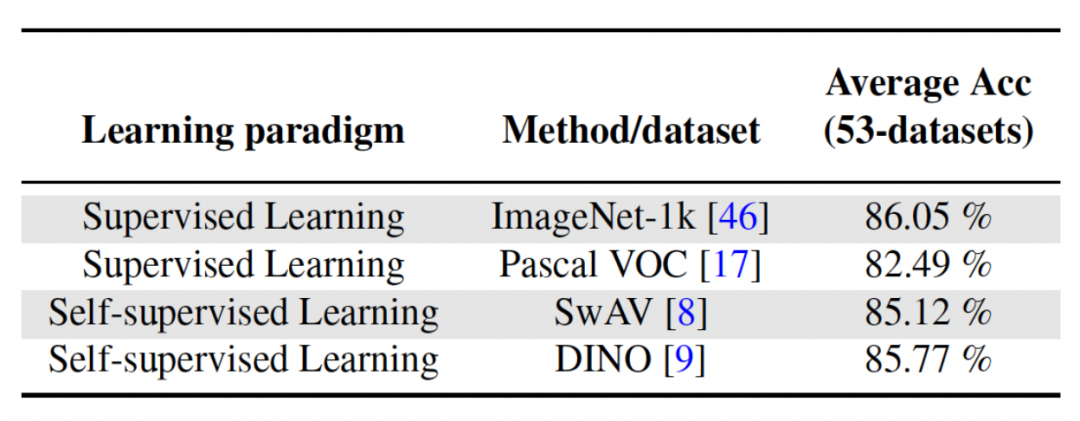
Deuxième expérience : apprentissage de la précision moyenne après avoir terminé toutes les tâches La figure ci-dessous montre la précision moyenne de toutes les méthodes après avoir appris toutes les tâches. La précision moyenne reflète la performance globale de la méthode d’apprentissage continu. Étant donné que chaque tâche présente différents niveaux de difficulté, lorsqu'une nouvelle tâche est ajoutée, la précision moyenne de toutes les tâches peut augmenter ou diminuer, selon que la tâche ajoutée est facile ou difficile. Tout d'abord, analysons les paramètres et le coût de calcul Pour l'apprentissage continu, bien qu'il soit très important d'obtenir une précision moyenne plus élevée, un bon algorithme espère également maximiser Réduire les exigences en matière de paramètres du réseau et coûts de calcul. « Ajouter des paramètres supplémentaires pour une nouvelle tâche » représente un pourcentage du montant des paramètres de base d'origine. Cet article utilise le coût de calcul du SGD comme unité, et les coûts de calcul des autres méthodes sont normalisés en fonction du coût du SGD. Contenu réécrit : Analyse d'impact de différents réseaux fédérateurs La méthode présentée dans cet article entraîne un modèle pré-entraîné en utilisant l'apprentissage supervisé ou l'apprentissage auto-supervisé sur des ensembles de données relativement divers, servant ainsi. comme paramètre invariant indépendant de la tâche. Afin d'explorer l'impact de différentes méthodes de pré-formation, cet article a sélectionné quatre modèles de pré-formation différents, indépendants des tâches, formés à l'aide de différents ensembles de données et tâches. Pour l'apprentissage supervisé, les chercheurs ont utilisé des modèles pré-entraînés sur ImageNet-1k et Pascal-VOC pour la classification des images ; pour l'apprentissage auto-supervisé, les chercheurs ont utilisé des modèles pré-entraînés obtenus par deux méthodes différentes, DINO et SwAV. Le tableau suivant montre la précision moyenne du modèle pré-entraîné en utilisant quatre méthodes différentes. On peut voir que les résultats finaux de toute méthode sont très élevés (Remarque : Pascal-VOC est un ensemble de données relativement petit, la précision est donc relativement. point bas) et est robuste à différents squelettes pré-entraînés. 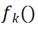 , nous pouvons obtenir la carte des caractéristiques Pour modifier linéairement chaque canal de Le chercheur a initialisé le noyau de convolution CLR avec le même noyau changeant (c'est-à-dire que pour le noyau de convolution 2D, seul le paramètre du milieu est 1 et les autres sont 0),
, nous pouvons obtenir la carte des caractéristiques Pour modifier linéairement chaque canal de Le chercheur a initialisé le noyau de convolution CLR avec le même noyau changeant (c'est-à-dire que pour le noyau de convolution 2D, seul le paramètre du milieu est 1 et les autres sont 0), 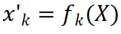 car cela peut rendre le squelette fixe d'origine généré lors de la première formation Les fonctionnalités sont les mêmes que celles produites par le modèle après ajout de la couche CLR. Dans le même temps, afin de sauvegarder les paramètres et d'éviter un surajustement, les chercheurs n'ajouteront pas de couche CLR après le noyau de convolution. La couche CLR n'agira qu'après le noyau de convolution. Pour ResNet50 après CLR, l'augmentation des paramètres entraînables ne représente que 0,59 % par rapport au backbone ResNet50 fixe.
car cela peut rendre le squelette fixe d'origine généré lors de la première formation Les fonctionnalités sont les mêmes que celles produites par le modèle après ajout de la couche CLR. Dans le même temps, afin de sauvegarder les paramètres et d'éviter un surajustement, les chercheurs n'ajouteront pas de couche CLR après le noyau de convolution. La couche CLR n'agira qu'après le noyau de convolution. Pour ResNet50 après CLR, l'augmentation des paramètres entraînables ne représente que 0,59 % par rapport au backbone ResNet50 fixe. 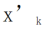
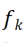 Pour un apprentissage continu, le modèle ajoutant des paramètres CLR entraînables et un squelette non entraînable peut apprendre chaque tâche à tour de rôle. Lors des tests, les chercheurs supposent qu'il existe un prédicteur de tâche capable d'indiquer au modèle à quelle tâche appartient l'image de test, puis que le squelette fixe et les paramètres CLR spécifiques à la tâche correspondants peuvent effectuer la prédiction finale. Étant donné que CLR a la caractéristique d'isoler les paramètres absolus (les paramètres de la couche CLR correspondant à chaque tâche sont différents et le squelette partagé ne changera pas), le CLR ne sera pas affecté par le nombre de tâches
Pour un apprentissage continu, le modèle ajoutant des paramètres CLR entraînables et un squelette non entraînable peut apprendre chaque tâche à tour de rôle. Lors des tests, les chercheurs supposent qu'il existe un prédicteur de tâche capable d'indiquer au modèle à quelle tâche appartient l'image de test, puis que le squelette fixe et les paramètres CLR spécifiques à la tâche correspondants peuvent effectuer la prédiction finale. Étant donné que CLR a la caractéristique d'isoler les paramètres absolus (les paramètres de la couche CLR correspondant à chaque tâche sont différents et le squelette partagé ne changera pas), le CLR ne sera pas affecté par le nombre de tâches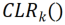 Résultats expérimentaux
Résultats expérimentaux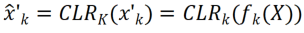 Ensemble de données : Les chercheurs ont utilisé la classification d'images comme tâche principale. Le laboratoire a collecté 53 ensembles de données de classification d'images, avec environ 1,8 million d'images et 1 584 catégories. Ces 53 ensembles de données contiennent 5 objectifs de classification différents : reconnaissance d'objets, classification de styles, classification de scènes, comptage et diagnostic médical.
Ensemble de données : Les chercheurs ont utilisé la classification d'images comme tâche principale. Le laboratoire a collecté 53 ensembles de données de classification d'images, avec environ 1,8 million d'images et 1 584 catégories. Ces 53 ensembles de données contiennent 5 objectifs de classification différents : reconnaissance d'objets, classification de styles, classification de scènes, comptage et diagnostic médical. 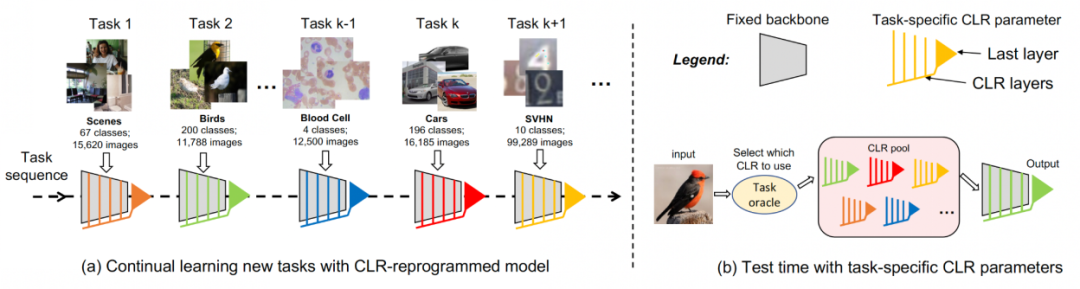 Les chercheurs ont sélectionné 13 lignes de base, qui peuvent être grossièrement divisées en 3 catégories
Les chercheurs ont sélectionné 13 lignes de base, qui peuvent être grossièrement divisées en 3 catégoriesRégularisation : CEE, CEE en ligne, SI, LwF
Il existe également certaines lignes de base qui ne sont pas un apprentissage continu, comme SGD et SGD-LL. SGD apprend chaque tâche en ajustant l'ensemble du réseau ; SGD-LL est une variante qui utilise un squelette fixe pour toutes les tâches et une couche partagée apprenable dont la longueur est égale au nombre maximum de catégories pour toutes les tâches.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Vérifier l'occupation du port sous Linux
Vérifier l'occupation du port sous Linux
 Comment ouvrir le format TIF sous Windows
Comment ouvrir le format TIF sous Windows
 Quels sont les logiciels de dessin ?
Quels sont les logiciels de dessin ?
 Quelles sont les méthodes de stockage des données ?
Quelles sont les méthodes de stockage des données ?
 Comment utiliser l'instruction insert dans MySQL
Comment utiliser l'instruction insert dans MySQL
 Temps de panne du service Windows 10
Temps de panne du service Windows 10
 Collection de touches de raccourci informatique
Collection de touches de raccourci informatique
 Comment résoudre le problème de steam_api.dll manquant
Comment résoudre le problème de steam_api.dll manquant








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



