



STRIDE est un framework de modélisation des menaces populaire qui est actuellement largement utilisé pour aider les organisations à découvrir de manière proactive les menaces, les attaques, les vulnérabilités et les contre-mesures susceptibles d'avoir un impact sur leurs systèmes d'application. Si vous démontez chaque lettre de "STRIDE", elles représentent respectivement la contrefaçon, la falsification, le déni, la divulgation d'informations, le déni de service et l'élévation de privilèges
Alors que l'application des systèmes d'intelligence artificielle (IA) devient progressivement un élément clé du développement numérique des entreprises, de nombreux praticiens de la sécurité soulignent la nécessité d'identifier et de protéger les risques de sécurité de ces systèmes dans les plus brefs délais. Le framework STRIDE peut aider les organisations à mieux comprendre les chemins d'attaque possibles dans les systèmes d'IA et à améliorer la sécurité et la fiabilité de leurs applications d'IA. Dans cet article, les chercheurs en sécurité utilisent le cadre du modèle STRIDE pour cartographier de manière exhaustive la surface d'attaque dans les applications du système d'IA (voir le tableau ci-dessous) et mènent des recherches sur les nouvelles catégories d'attaques et les scénarios d'attaque spécifiques à la technologie d'IA. À mesure que la technologie de l'IA continue de se développer, de nouveaux modèles, applications, attaques et modes de fonctionnement apparaîtront
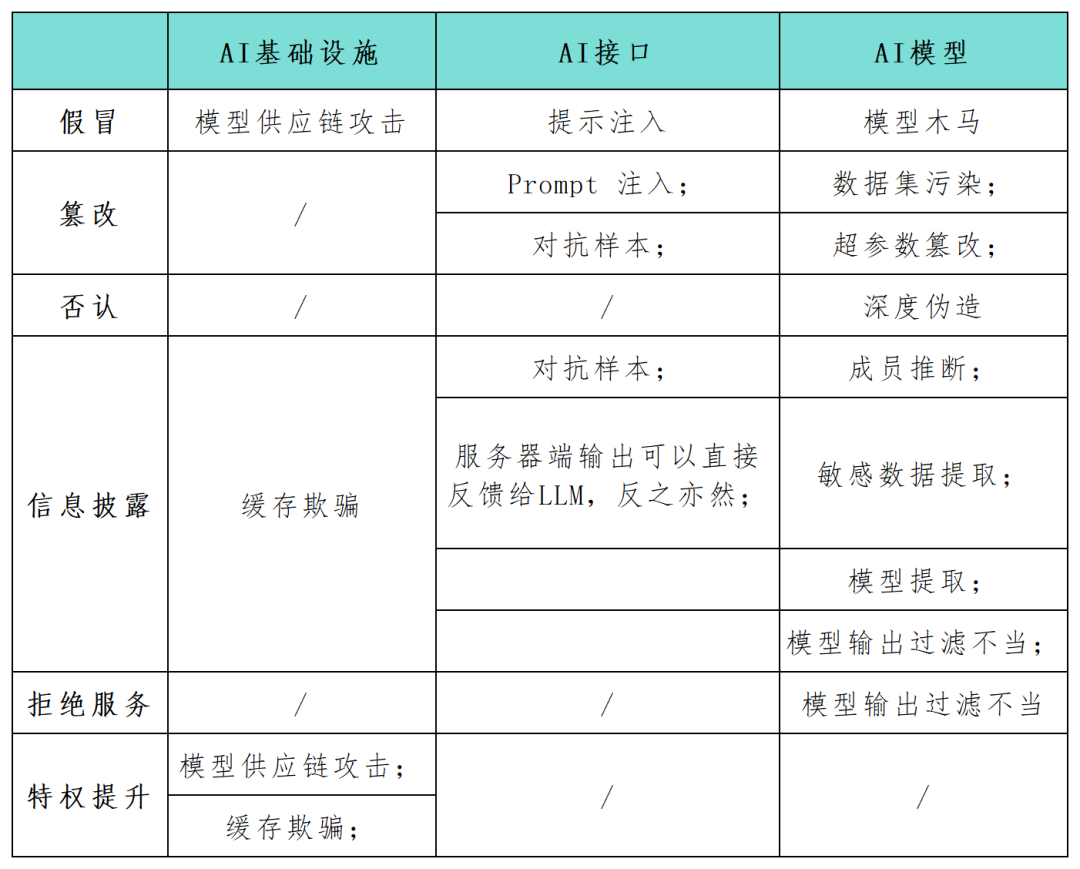
Le chercheur en IA Andrej Karpathy a souligné que l'arrivée d'une nouvelle génération de modèles de réseaux neuronaux profonds, marque un changement de paradigme dans la manière traditionnelle de conceptualiser la production de logiciels. Les développeurs intègrent de plus en plus de modèles d’IA dans des systèmes complexes qui ne sont pas exprimés dans un langage de boucles et de conditions, mais dans des espaces vectoriels continus et des pondérations numériques, créant ainsi de nouvelles possibilités d’exploitation des vulnérabilités et donnant naissance à de nouvelles catégories de menaces.
Si un attaquant parvient à falsifier les entrées et sorties du modèle, ou à modifier certains paramètres de configuration de l'infrastructure de l'IA, cela peut entraîner des résultats malveillants nuisibles et imprévisibles, tels qu'un comportement inattendu ou une interaction avec l'IA. agent et dommages aux composants liés. Impact
Contenu réécrit : l'usurpation d'identité fait référence à un attaquant simulant une source fiable pendant le processus de livraison du modèle ou du composant pour introduire des éléments malveillants dans le système d'IA. Cette technique permet aux attaquants d’injecter des éléments malveillants dans les systèmes d’IA. Dans le même temps, l’usurpation d’identité peut également être utilisée dans le cadre d’une attaque modèle sur la chaîne d’approvisionnement. Par exemple, si un acteur menaçant infiltre un fournisseur de modèles tiers comme Huggingface, lorsque le code généré par l'IA est exécuté en aval, il peut contrôler l'infrastructure environnante en infectant le modèle en amont
Divulgation d'informations. L'exposition des données sensibles est un problème courant pour toute application réseau, y compris les applications qui servent les systèmes d'IA. En mars 2023, une mauvaise configuration de Redis a amené un serveur Web à exposer des données privées. En général, les applications Web sont sensibles aux dix principales vulnérabilités classiques de l'OWASP, telles que les attaques par injection, les scripts intersites et les références d'objet directes non sécurisées. La même situation s’applique aux applications Web qui servent les systèmes d’IA.
Déni de service (DoS). Les attaques DoS constituent également une menace pour les applications d'intelligence artificielle. Les attaquants rendent les services d'intelligence artificielle inutilisables en inondant l'infrastructure du fournisseur de modèles avec de grandes quantités de trafic. La résilience est une exigence fondamentale pour assurer la sécurité lors de la conception d'infrastructures et d'applications pour les systèmes d'IA, mais elle ne suffit pas
Pour les modèles d'IA entraînés ainsi que les nouveaux modèles génératifs tiers, les systèmes d'IA ont également le Menaces de surface d'attaque suivantes :
Pollution des ensembles de données et falsification des hyperparamètres. Les modèles d'IA sont sensibles à des menaces spécifiques pendant les phases de formation et d'inférence. La contamination des ensembles de données et la falsification d'hyperparamètres sont des attaques de la catégorie de falsification STRIDE, qui fait référence aux acteurs malveillants injectant des données malveillantes dans des ensembles de données de formation. Par exemple, un attaquant pourrait délibérément introduire des images trompeuses dans une IA de reconnaissance faciale, l’amenant à identifier de manière incorrecte des individus.
Les exemples contradictoires sont devenus une menace courante de fuite d'informations ou de falsification dans les applications d'IA. Un attaquant manipule l'entrée d'un modèle pour produire des prédictions ou des résultats de classification incorrects. Ces comportements peuvent révéler des informations sensibles dans les données d'entraînement du modèle ou inciter le modèle à se comporter de manière inattendue. Par exemple, une équipe de chercheurs a noté que l’ajout de petits morceaux de ruban adhésif sur les panneaux d’arrêt pourrait perturber les modèles de reconnaissance d’images intégrés dans les voitures autonomes, ce qui pourrait avoir de graves conséquences sur l’extraction du modèle. L’extraction de modèles est une forme d’attaque malveillante récemment découverte qui relève de la catégorie de divulgation d’informations de STRIDE. L'objectif de l'attaquant est de répliquer des modèles d'apprentissage automatique formés propriétaires en fonction des requêtes et des réponses du modèle. Ils élaborent une série de requêtes et utilisent les réponses du modèle pour créer une réplique du système d'IA cible. De telles attaques peuvent porter atteinte aux droits de propriété intellectuelle et entraîner des pertes financières importantes. Dans le même temps, une fois qu’un attaquant dispose d’une copie du modèle, il peut également lancer des attaques contradictoires ou procéder à une ingénierie inverse des données d’entraînement, créant ainsi d’autres menaces.
Attaques contre les grands modèles de langage (LLM)
Contenu réécrit : les attaques par invite de saisie font référence à des comportements tels que le jailbreak, la fuite d'invite et la contrebande de jetons. Dans ces attaques, l'attaquant utilise des invites de saisie pour déclencher un comportement inattendu du LLM. Une telle manipulation pourrait amener l’IA à réagir de manière inappropriée ou à divulguer des informations sensibles, conformément aux catégories de tromperie et de fuite d’informations du modèle STRIDE. Ces attaques sont particulièrement dangereuses lorsque les systèmes d'IA sont utilisés conjointement avec d'autres systèmes ou au sein de chaînes d'applications logicielles.
Sortie et filtrage de modèle inappropriés. Un grand nombre d'applications API peuvent être exploitées de diverses manières non exposées publiquement. Par exemple, des frameworks comme Langchain permettent aux développeurs d'applications de déployer rapidement des applications complexes sur des modèles génératifs publics et d'autres systèmes publics ou privés (tels que des bases de données ou l'intégration Slack). Un attaquant peut créer un indice qui incite le modèle à effectuer des requêtes API qui ne seraient pas autorisées autrement. De même, un attaquant peut injecter des instructions SQL dans un formulaire Web générique non vérifié pour exécuter du code malveillant.
L'inférence de membres et l'extraction de données sensibles sont des choses qui doivent être réécrites. Un attaquant peut exploiter les attaques d'inférence d'appartenance pour déduire de manière binaire si un point de données spécifique se trouve dans l'ensemble d'apprentissage, soulevant ainsi des problèmes de confidentialité. Les attaques d'extraction de données permettent à un attaquant de reconstruire complètement les informations sensibles sur les données d'entraînement à partir des réponses du modèle. Lorsque LLM est formé sur des ensembles de données privés, un scénario courant est que le modèle peut contenir des données organisationnelles sensibles et qu'un attaquant peut extraire des informations confidentielles en créant des invites spécifiques
Contenu réécrit : le modèle cheval de Troie est un type de modèle qui a fait ses preuves. Modèles susceptibles d’être contaminés par les ensembles de données d’entraînement pendant la phase de réglage fin. De plus, la falsification des données publiques familières sur la formation s’est avérée réalisable dans la pratique. Ces faiblesses ouvrent la porte à des modèles de chevaux de Troie pour des modèles de langage accessibles au public. En apparence, ils fonctionnent comme prévu pour la plupart des astuces, mais ils cachent des mots-clés spécifiques introduits lors du réglage fin. Une fois qu'un attaquant déclenche ces mots-clés, le modèle de cheval de Troie peut effectuer divers comportements malveillants, notamment l'élévation de privilèges, la création d'un système inutilisable (DoS) ou la fuite d'informations sensibles privées.
Lien de référence :
Le contenu qui doit être réécrit est : https://www.secureworks.com/blog/unravelling-the-attack-surface-of-ai-systems
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment supprimer un fichier sous Linux
Comment supprimer un fichier sous Linux
 La pièce d'or Toutiao d'aujourd'hui est égale à 1 yuan
La pièce d'or Toutiao d'aujourd'hui est égale à 1 yuan
 Que faire si le jeton de connexion n'est pas valide
Que faire si le jeton de connexion n'est pas valide
 es6 nouvelles caractéristiques
es6 nouvelles caractéristiques
 Que signifie la carte secondaire du téléphone portable ?
Que signifie la carte secondaire du téléphone portable ?
 commande de recherche de fichier Linux
commande de recherche de fichier Linux
 Logiciel d'optimisation de mots clés Baidu
Logiciel d'optimisation de mots clés Baidu
 Comment résoudre l'exception d'argument illégal
Comment résoudre l'exception d'argument illégal








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



