



Le contenu qui doit être réécrit est : Editeur | Zi Luo
Au cours des dernières années, le domaine de l'apprentissage automatique de la vision et du traitement du langage naturel (NLP) a fait d'énormes progrès en s'entraînant sur une variété de données différentes ensembles de progrès. Cela a conduit à l'émergence de « modèles de base »
Par exemple, les « grands modèles de langage » ont déclenché une renaissance de la PNL : affiner ou inciter des modèles généralistes est désormais une pratique courante, plutôt que de former des modèles spécialisés à partir de zéro.
Cependant, l’application de l’apprentissage automatique aux ensembles de données scientifiques n’a pas encore subi un changement de paradigme similaire.
Il s’agit d’une opportunité non réalisée que le programme de recherche « Polymathic AI » (Polymathic AI) cherche à résoudre.
Yann LeCun, lauréat du prix Turing et scientifique en chef de Meta, a déclaré : "Je suis très heureux de devenir consultant pour le nouveau projet AI for Science (Polymathic AI)."
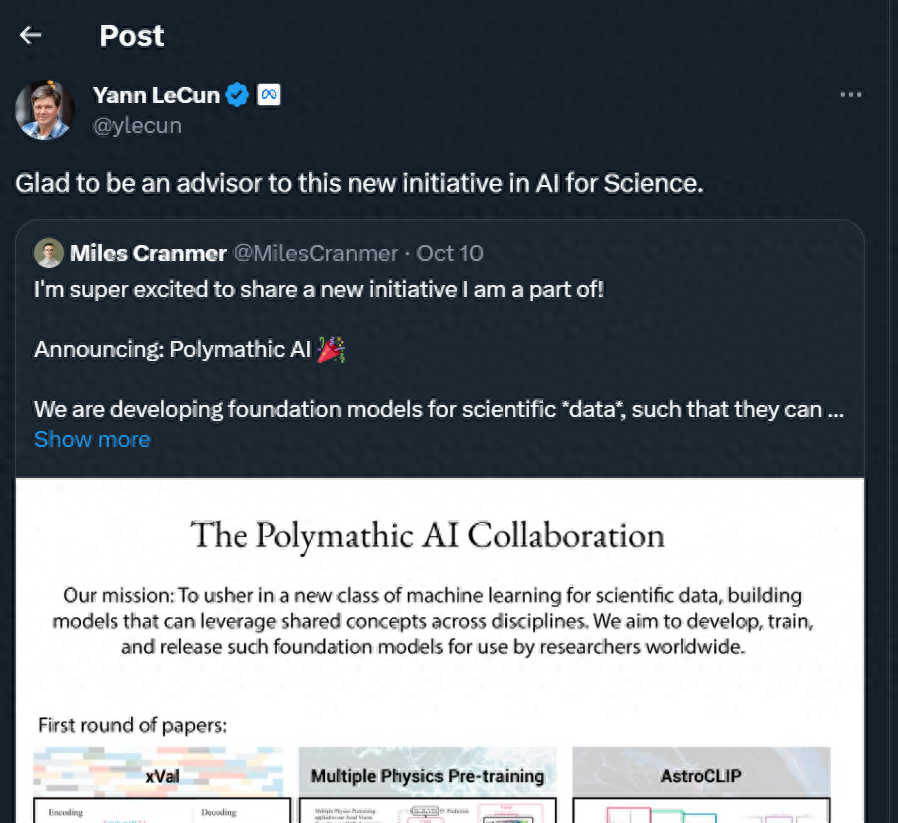
Miles Cranmer, professeur adjoint d'IA+ Astronomie/Physique à l'Université de Cambridge, a partagé sur Twitter un nouveau projet dans lequel il est impliqué : Polymathic AI !
"Nous développons des modèles de base de [données] scientifiques afin qu'ils puissent tirer parti de concepts partagés entre les disciplines."
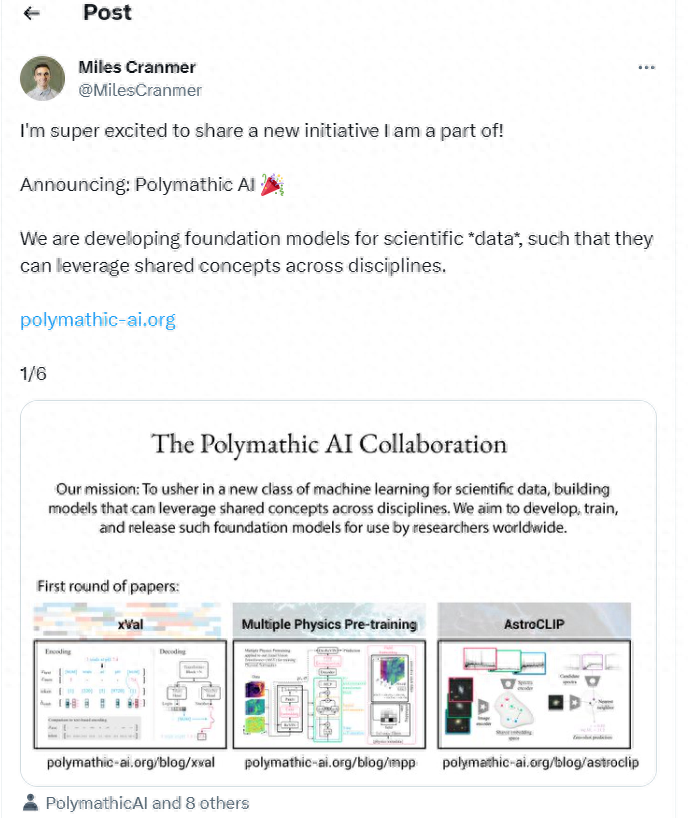 La Versatile AI Initiative vise à accélérer le développement de modèles fondamentaux adaptés aux ensembles de données numériques et aux tâches scientifiques d'apprentissage automatique.
La Versatile AI Initiative vise à accélérer le développement de modèles fondamentaux adaptés aux ensembles de données numériques et aux tâches scientifiques d'apprentissage automatique.
Le défi est de créer des modèles d'IA qui exploitent des données provenant d'ensembles hétérogènes et des informations provenant de différents domaines scientifiques. en tant que traitement du langage naturel, ces modèles ne partagent pas une représentation unifiée (c'est-à-dire un texte).
Équipe de recherche.
 Groupe consultatif scientifique.
Groupe consultatif scientifique.
 Contenu réécrit à lire : Implication institutionnelle
Contenu réécrit à lire : Implication institutionnelle
Construire un modèle véritablement fondé sur la science nécessite des recherches préliminaires approfondies. Notre programme de recherche se concentre sur les fondamentaux de ce domaine. À ce jour, nous avons publié des recherches sur les composants architecturaux clés. Nos recherches portent sur l'adaptation de modèles de langage aux données numériques, la démonstration de la transférabilité de modèles de substitution formés sur différents systèmes physiques et l'apprentissage d'intégrations partagées pour des données scientifiques multimodales.
Ce programme de recherche joue un rôle déterminant dans la redéfinition du paysage scientifique de l'apprentissage automatique. Nous sommes très enthousiasmés par le potentiel , et Polymathic AI représente une étape ambitieuse vers cet objectif 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!










![Premiers pas avec le développement pratique PHP : création rapide de PHP [Small Business Forum]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



