



À court terme, la plateforme doit d'abord permettre à davantage de nouvelles vidéos de gagner du trafic, ce qui signifie qu'elles peuvent être distribuées. Dans le même temps, le trafic émis doit être plus efficace. À long terme, nous explorerons et exploiterons également davantage de nouvelles vidéos à fort potentiel pour apporter plus de sang frais à l’ensemble du bassin populaire et atténuer l’effet Matthew écologique. Fournissez un contenu de plus haute qualité, améliorez l'expérience utilisateur et augmentez également la durée et la DAU. 
Utilisez le démarrage à froid pour promouvoir les auteurs UGC afin d'obtenir des incitations à commentaires interactifs afin de maintenir la fidélisation de l'ensemble du producteur. Dans ce processus, il y a deux contraintes. Premièrement, le coût global de l’exploration et le coût du trafic devraient être globalement relativement stables. Deuxièmement, nous n'intervenons que dans la diffusion de nouvelles vidéos au stade low vv. Alors, sous ces contraintes, comment maximiser les bénéfices globaux ?
La distribution à froid des vidéos a un impact important sur leur espace de croissance, surtout lorsque le travail est distribué à des personnes qui ne correspondent pas à leurs intérêts, cela aura deux impacts. Tout d'abord, la croissance de l'auteur en sera affectée. À long terme, il ne pourra pas bénéficier d'incitations interactives efficaces en matière de trafic, ce qui entraînera des changements dans sa direction et sa volonté de soumission. Deuxièmement, en raison du manque de taux de conversion efficace au début du trafic, le système considérera le contenu comme étant de mauvaise qualité. Par conséquent, à long terme, il ne sera pas en mesure d'obtenir un support de trafic suffisant et ne pourra donc pas atteindre une croissance
Si les choses continuent ainsi, l'écosystème tombera dans un mauvais état de comparaison. Par exemple, s’il s’agit d’une œuvre sur la nourriture locale, elle doit s’adresser au groupe d’audience A le plus approprié et son taux d’action global est le plus élevé. De plus, il peut y avoir un groupe de personnes C totalement indépendant. Lors du vote pour ce groupe de personnes, il y aura un certain degré de sélectivité et le taux d'action peut être extrêmement faible. Bien sûr, il existe également un troisième type de groupe B, qui est un groupe aux intérêts très larges. Bien que ce groupe de personnes ait un flux important, le taux d'action global de ce groupe de personnes sera faible.
Si nous pouvons atteindre le groupe central A le plus tôt possible pour augmenter le taux d'interaction précoce du contenu, nous pouvons provoquer une répartition optimale du trafic naturel. Mais si nous donnons trop de trafic à la foule C ou à la foule B au début, cela entraînera un faible taux d’action global et limitera sa croissance. Dans l’ensemble, l’amélioration de l’efficacité de la distribution par démarrage à froid est le moyen le plus important de parvenir à une croissance du contenu. Afin de compléter l'itération de l'efficacité du démarrage à froid du contenu, nous établirons des indicateurs de processus intermédiaires et des indicateurs finaux à long terme.
Le contenu réécrit est le suivant : Les indicateurs de processus sont principalement divisés en deux parties. Une partie est la performance de consommation des nouvelles vidéos, comprenant principalement leur taux d'action du trafic, l'autre partie est constituée des indicateurs de montée en puissance, y compris. orientation de l'exploration, orientation de l'utilisation et orientation écologique. L'orientation de l'exploration est de garantir que les nouvelles vidéos de haute qualité ne sont pas ignorées, en observant principalement la croissance du nombre de vidéos avec des expositions supérieures à 0 et des expositions supérieures à 100. Utilisez Xiangsi pour observer la croissance du nombre de vidéos à VV élevé qui sont de nouvelles vidéos populaires et de haute qualité. La direction écologique observe principalement le taux de pénétration des utilisateurs des piscines populaires. À long terme, puisqu'il s'agit d'un changement à long terme provoqué par l'impact écologique, nous utiliserons éventuellement les expériences Combo pour observer les tendances changeantes de certains indicateurs de base à long terme, notamment la durée de l'APP, le DAU de l'auteur et le DAU global
2. Défis et solutions pour la modélisation du démarrage à froid
En général, il existe trois difficultés principales avec le démarrage à froid du contenu. Premièrement, il existe une énorme différence entre l’espace échantillon du démarrage à froid du contenu et l’espace réel de la solution. Deuxièmement, les échantillons de contenu démarrés à froid sont très clairsemés, ce qui entraînera des résultats d’apprentissage inexacts et des écarts très importants, notamment en termes de biais d’exposition. Troisièmement, modéliser la valeur de croissance des vidéos est également une difficulté, qui est également un problème que nous travaillons actuellement dur pour résoudre. Cet article se concentrera sur les difficultés des deux premiers aspects
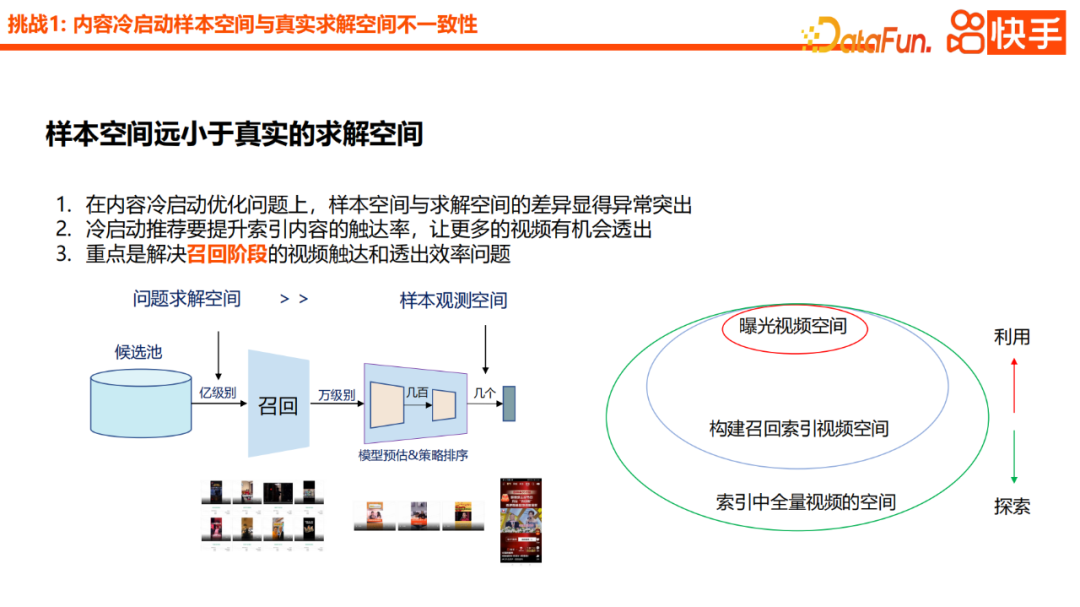
Lors de l'optimisation du problème de démarrage à froid du contenu, l'espace d'échantillon étant plus petit que l'espace de solution est un problème très important. Surtout en termes de démarrage à froid des contenus recommandés, il est nécessaire d'augmenter le taux de portée des contenus indexés afin que davantage de vidéos aient la possibilité d'être affichées
Nous pensons que pour résoudre ce problème, le plus important est d'augmenter le taux de portée des vidéos pendant la phase de rappel Atteignez et révélez l'efficacité. Afin de résoudre le taux de rappel des vidéos de démarrage à froid. L'approche courante dans l'industrie est basée sur le contenu, y compris l'inversion d'attributs, certaines méthodes de rappel basées sur la similarité sémantique, ou un modèle de rappel basé sur des tours jumelles plus des fonctionnalités de généralisation, ou l'introduction d'un mappage entre l'espace de comportement et l'espace de contenu, similaire Basé sur l’approche de CB2CF.
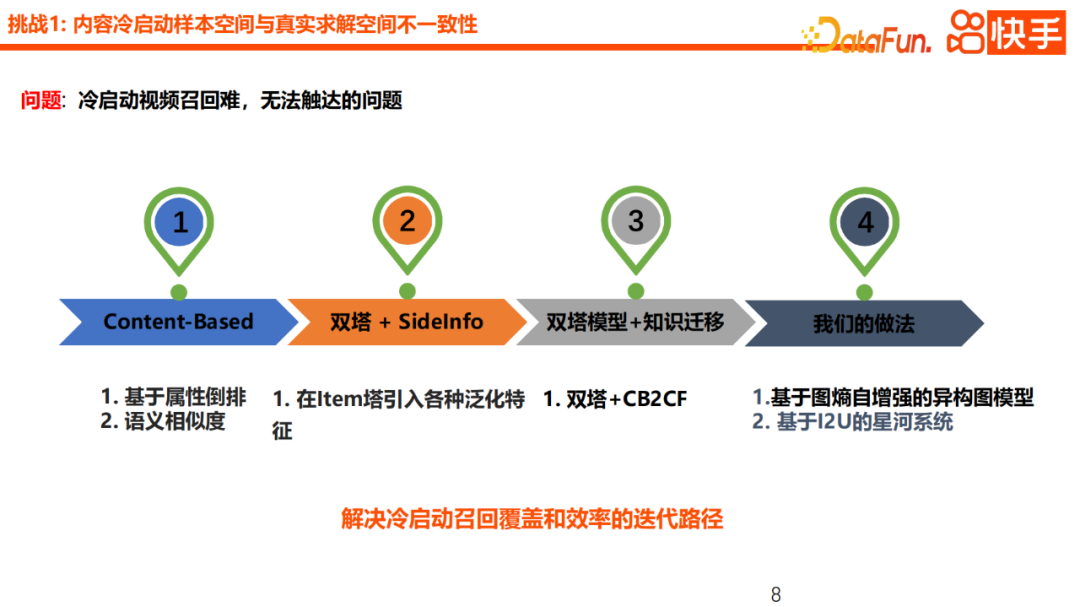
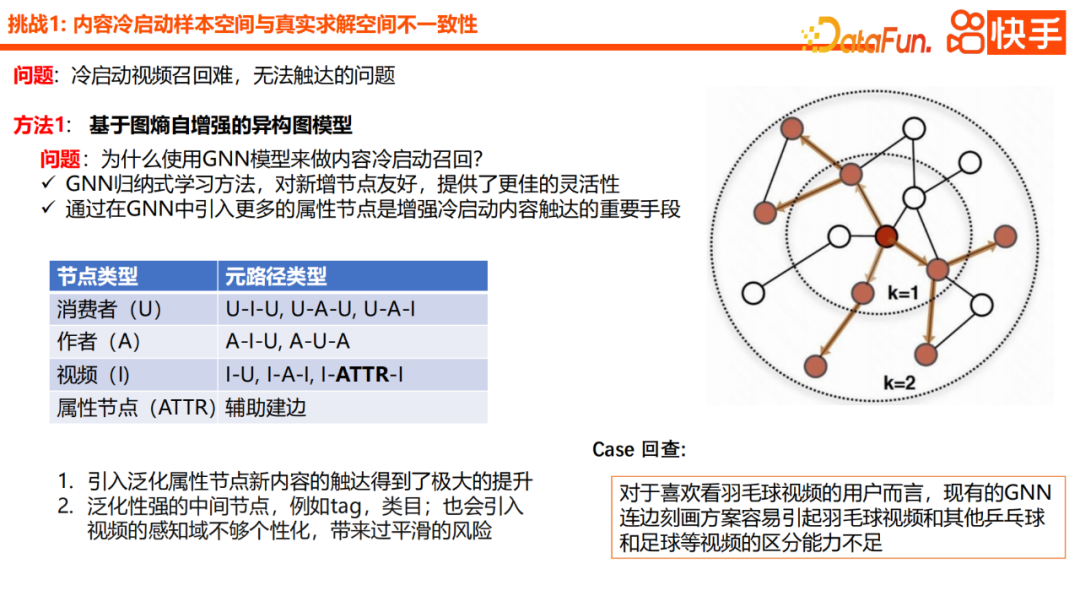
Cette fois, nous nous concentrerons sur deux nouvelles méthodes plus intéressantes, à savoir le réseau de graphes hétérogènes basé sur l'auto-amélioration de l'entropie des graphes et le modèle de galaxie basé sur I2U. En termes de sélection technologique, nous utilisons d'abord GNN comme modèle de base pour le démarrage à froid du contenu U2I. Parce que nous considérons que GNN est une méthode d’apprentissage inductif dans son ensemble, il est très convivial pour les nouveaux nœuds et offre plus de flexibilité. De plus, GNN introduit davantage de nœuds d'attributs, ce qui constitue un moyen important d'améliorer l'accès au contenu de démarrage à froid. En termes de pratique spécifique, nous présenterons également les nœuds utilisateurs, les nœuds auteurs et les nœuds éléments et compléterons l'agrégation des informations. Après l'introduction de ce nœud d'attributs généralisé, le taux de portée global du nouveau contenu a été considérablement amélioré. Cependant, des nœuds intermédiaires trop généraux, comme les catégories de tags, entraîneront également une personnalisation insuffisante du domaine perceptuel de la vidéo, entraînant un risque de lissage excessif. À partir de l'examen du cas, nous avons constaté que pour certains utilisateurs qui aiment regarder des vidéos de badminton, le schéma de caractérisation GNN existant peut facilement entraîner une mauvaise distinction entre les vidéos de badminton et d'autres vidéos de tennis de table, de football et autres.
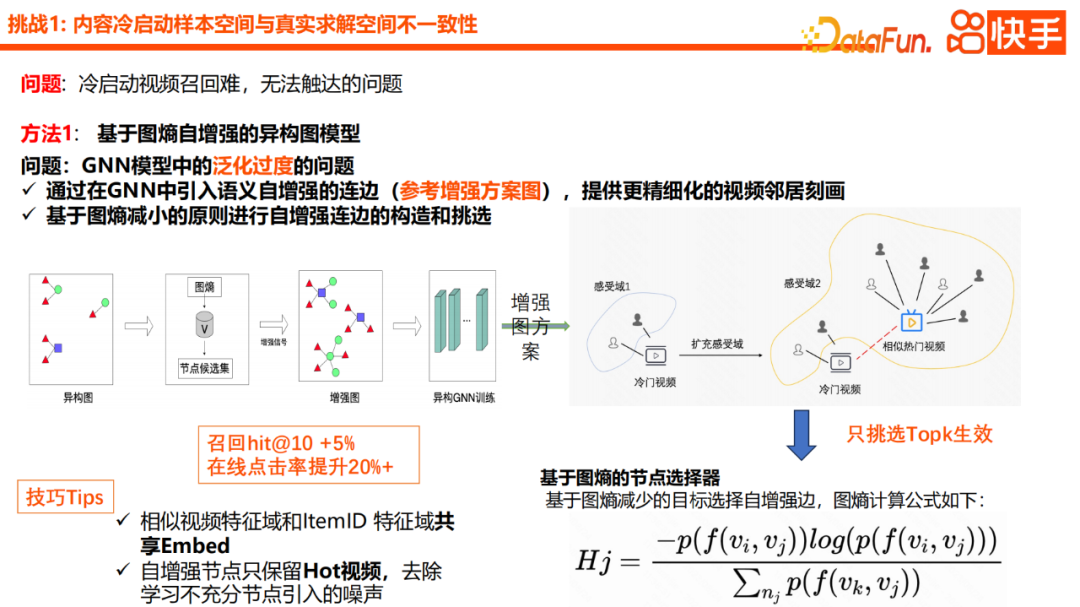
Afin de résoudre le problème de sur-généralisation causé par l'introduction de trop d'informations de généralisation dans le processus de modélisation GNN, notre idée principale est d'introduire un schéma de caractérisation des voisins plus détaillé. Plus précisément, nous introduireons l'automaticité sémantique dans. GNN. Améliorez les bords. Comme vous pouvez le voir sur l'image dans le coin inférieur droit, nous utiliserons la vidéo impopulaire pour trouver ses vidéos populaires similaires dans l'espace populaire, puis utiliserons les vidéos similaires populaires comme nœud initial de la connexion de démarrage à froid. Dans le processus d'agrégation spécifique, nous construirons et sélectionnerons des arêtes auto-renforcées sur la base du principe de réduction de l'entropie des graphes. Le plan de sélection spécifique peut être vu à partir de la formule, qui prend principalement en compte la description ci-dessus du nœud voisin connecté et les informations du nœud actuel. Si la similarité entre deux nœuds est plus élevée, leur entropie d’information sera plus petite. Le dénominateur de nœud ci-dessous représente le champ de perception global du nœud voisin.On peut également comprendre que dans le processus de sélection, nous préférons trouver un nœud voisin avec une perception plus forte. En pratique, nous avons principalement deux astuces, l'une est la fonctionnalité. Le domaine de vidéos similaires et le domaine de fonctionnalités de l'identifiant de l'élément doivent partager l'espace d'intégration, puis le nœud d'auto-amélioration ne conserve que les vidéos populaires pour supprimer le bruit introduit par des nœuds d'apprentissage insuffisants. Avec cette mise à niveau, la généralisation globale est entièrement garantie, ce qui améliore efficacement le degré de personnalisation du modèle et entraîne de meilleurs effets hors ligne et en ligne.
Les méthodes ci-dessus constituent en fait une amélioration dans la modélisation de la portée du contenu du point de vue U2I, mais elles ne peuvent pas fondamentalement résoudre le problème des vidéos inaccessibles
Si vous changez d'avis, de la perspective d'un élément pour trouver la bonne les gens, c'est-à-dire passer à la perspective d'I2U. En théorie, chaque vidéo a de la place pour obtenir du trafic. 
L'approche spécifique est que nous devons former un service de récupération I2U et utiliser ce service de récupération pour récupérer dynamiquement les groupes intéressés pour chaque vidéo. Grâce à cette méthode de composition I2U, l'index inversé de U2I est construit de manière inverse, et finalement la liste d'éléments est renvoyée sous forme de liste de recommandations de démarrage à froid selon la demande en temps réel de l'utilisateur

Le contenu réécrit est : Le focus est de former un I2U. Notre première version du service de récupération était un modèle à deux tours. En pratique, afin d'éviter le problème de la concentration excessive des utilisateurs, nous allons d'abord abandonner l'uid et utiliser la liste d'actions et l'auto-attention pour atténuer efficacement le problème de la concentration des utilisateurs. Dans le même temps, afin d'éviter le biais d'exposition à l'apprentissage causé par l'identifiant de l'élément pendant le processus d'apprentissage, nous abandonnerons l'identifiant de l'élément et introduirons des fonctionnalités plus généralisées telles que des vecteurs sémantiques, des catégories, des balises et AuthorID pour atténuer efficacement l'élément - Agrégation d'identifiants. Du point de vue de l'utilisateur, ce type de perte Debias est introduit, puis un échantillonnage négatif au sein du lot est introduit pour mieux éviter le problème de concentration de l'utilisateur
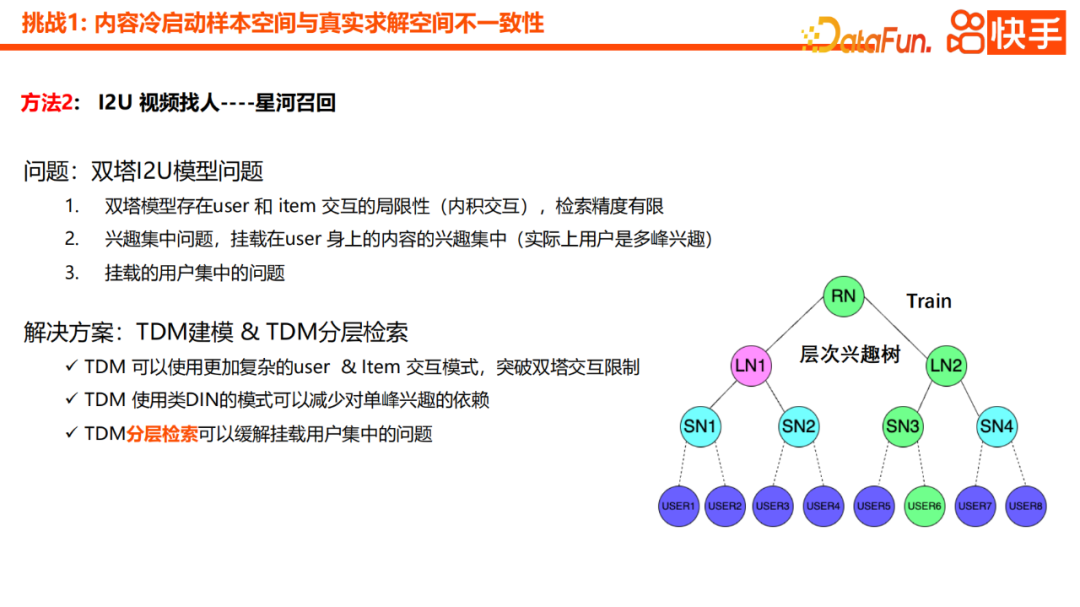
Notre première version de la pratique est le modèle I2U à double tour Certains problèmes ont également été découverts lors de la pratique. Tout d’abord, le modèle à deux tours présente des limites dans l’interaction entre les utilisateurs et les éléments, et la précision globale de la récupération est limitée. À cela s'ajoute le problème de la concentration des intérêts. Les contenus présentés aux utilisateurs ont souvent des intérêts très concentrés, mais en fait les intérêts des utilisateurs sont distribués de manière multimodale. Nous avons également constaté le problème des utilisateurs trop concentrés. La plupart des vidéos de démarrage à froid sont montées sur certains utilisateurs de haut niveau, ce qui n'est pas raisonnable car après tout, le contenu que les utilisateurs de haut niveau peuvent consommer chaque jour est également limité
Pour résoudre. Pour résoudre les trois problèmes ci-dessus, la nouvelle solution est la modélisation TDM et la méthode de récupération hiérarchique TDM. L’un des avantages du TDM est qu’il peut introduire des modes d’interaction utilisateur-élément plus complexes et dépasser les limites d’interaction des Twin Towers. La seconde consiste à utiliser un modèle de type DIN qui réduit le recours à l’intérêt unimodal. Enfin, l'introduction de la récupération hiérarchique dans TDM peut atténuer très efficacement le problème de la concentration croissante des utilisateurs.
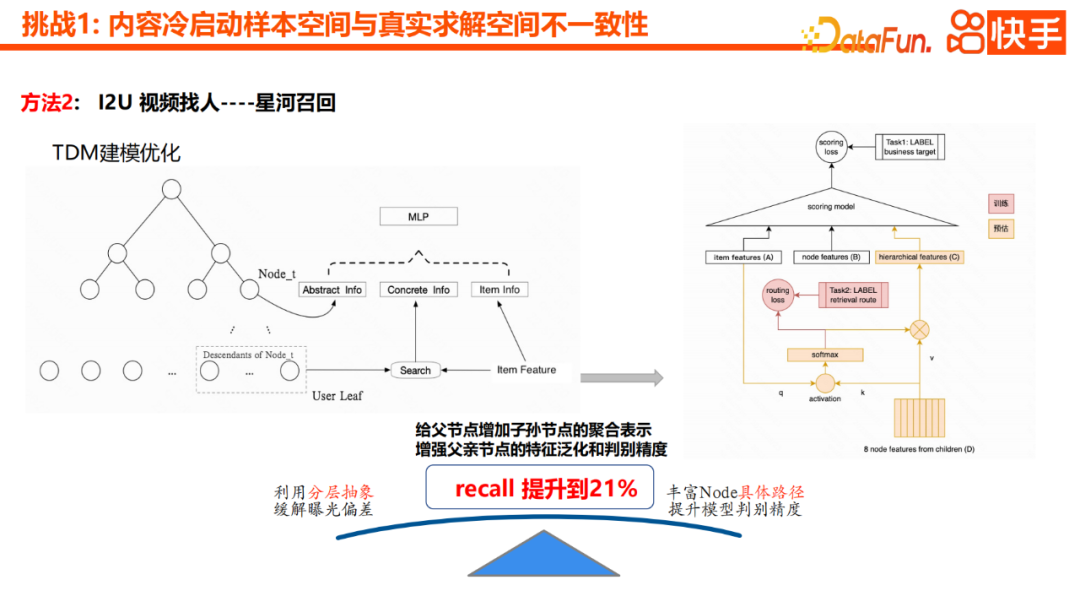
De plus, nous avons un point d'optimisation plus efficace, qui consiste à ajouter la représentation agrégée des nœuds descendants au nœud parent. Cela peut améliorer la précision de la généralisation des fonctionnalités et de la discrimination du nœud parent. En d'autres termes, nous agrégerons les nœuds enfants aux nœuds parents via le mécanisme d'attention, et grâce au transfert couche par couche, les nœuds intermédiaires peuvent également avoir certaines capacités de généralisation sémantique

Dans la pratique finale du système, Dans En plus du modèle I2U, nous avons également introduit le module d'extension d'intérêt U2U. En d'autres termes, si certains utilisateurs obtiennent de bons résultats dans la vidéo de démarrage à froid, nous diffuserons rapidement la vidéo
Les spécificités sont similaires à certaines méthodes actuelles de l'industrie, mais le module d'expansion des intérêts U2U présente ici trois avantages principaux : . Tout d'abord, l'arborescence TDM est relativement solide, et l'ajout de ce module U2U peut se rapprocher des préférences temps réel de l'utilisateur. Deuxièmement, grâce à la diffusion des intérêts en temps réel, nous pouvons surmonter les limites du modèle et promouvoir rapidement le contenu grâce à la collaboration des utilisateurs, entraînant ainsi une diversité accrue. En fin de compte, cela peut également améliorer la couverture globale du rappel Galaxy. Voici quelques-uns de nos points d'optimisation dans le processus de pratique
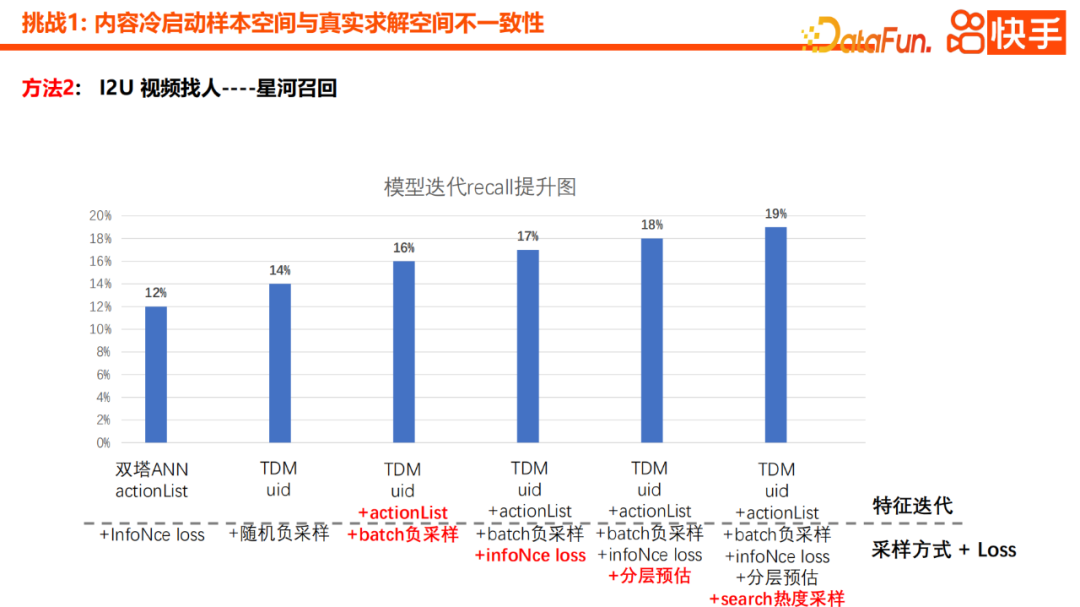
Grâce à ces solutions, nous pouvons résoudre efficacement l'espace d'échantillon et l'espace de solution réel dans le démarrage à froid du contenu. Problème d'incohérence, améliorant ainsi considérablement la portée et l'effet de couverture du démarrage à froid
Ensuite, le contenu de la rareté de l'échantillon de démarrage à froid entraîne une inexactitude et un écart d'apprentissage importants question, c’est le plus grand défi. L'essence de ce problème est la rareté du comportement d'interaction. Nous élargissons le problème dans trois directions.
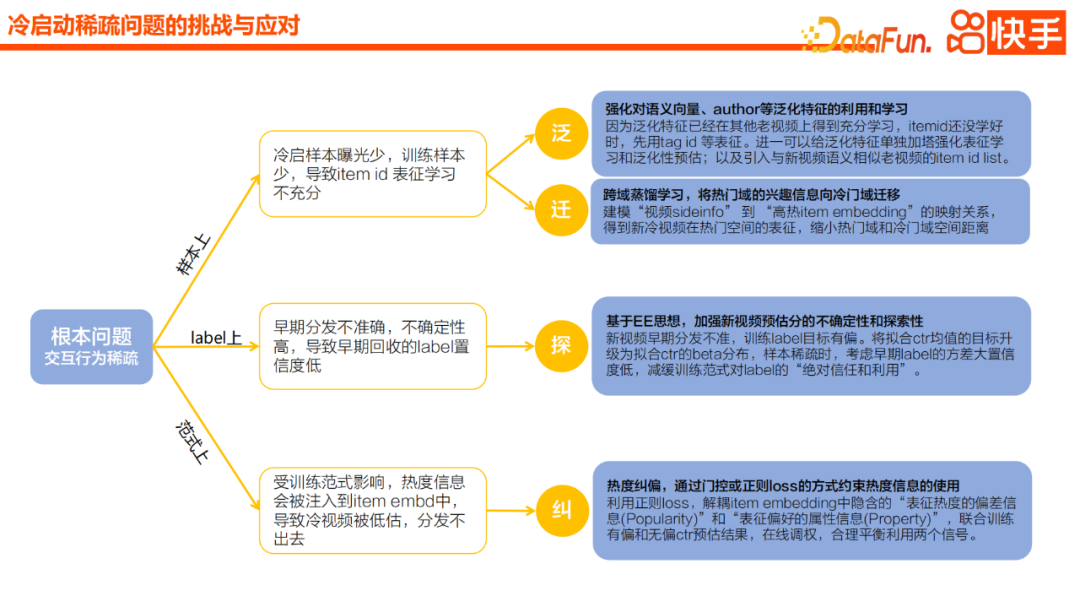
Tout d'abord, en raison de la moindre exposition des échantillons de démarrage à froid, l'apprentissage de l'identifiant de l'article est insuffisant, ce qui affecte à son tour l'effet de recommandation et l'efficacité de la recommandation. Deuxièmement, il existe une grande incertitude et une faible confiance dans les étiquettes collectées en raison d’inexactitudes lors de la distribution initiale. Troisièmement, le paradigme de formation actuel introduira des informations de popularité dans l'intégration d'éléments sans correction, ce qui entraînera une sous-estimation des vidéos de démarrage à froid et ne pourra donc pas être entièrement distribuée
Nous allons principalement dans quatre directions pour résoudre ce problème. Le premier est la généralisation, le deuxième le transfert, le troisième l’exploration et le quatrième la correction. La généralisation consiste davantage à compléter la modélisation et la mise à niveau du point de vue des fonctionnalités généralisées. L'objectif principal de la migration est de considérer les vidéos impopulaires et populaires comme deux domaines, et de transférer efficacement les informations du domaine vidéo populaire ou du domaine d'informations complètes pour faciliter l'apprentissage des vidéos impopulaires. L'exploration introduit principalement l'idée d'exploration et d'utilisation, c'est-à-dire que lorsque les premières étiquettes sont inexactes, nous espérons introduire l'idée d'exploration dans le processus de modélisation, atténuant ainsi l'impact négatif de l'incrédulité à l'égard de l'étiquette pendant le froid. étape de départ. La correction de popularité est actuellement une tendance en vogue. Nous limitons principalement l'utilisation des informations de popularité par le biais de contrôles et de pertes régulières.
Ce qui suit est une introduction détaillée à notre travail.
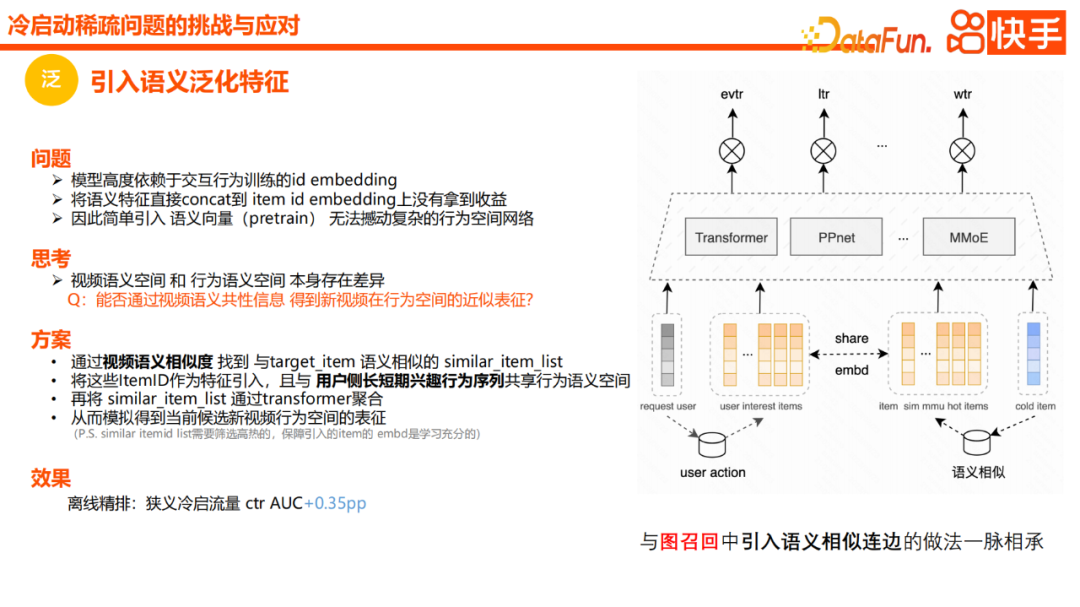
Tout d'abord, la généralisation est une méthode très courante pour résoudre le problème du démarrage à froid. Cependant, en pratique, nous constatons qu’il est également très utile d’introduire quelques plongements sémantiques par rapport aux étiquettes et aux catégories. Cependant, les avantages de l’ajout direct de fonctionnalités sémantiques au modèle global sont limités. Puisqu'il existe des différences entre l'espace sémantique vidéo et l'espace comportemental, pouvons-nous représenter approximativement la position de la nouvelle vidéo dans l'espace comportemental grâce aux informations communes de la sémantique vidéo pour faciliter la généralisation. Nous avons déjà mentionné certaines méthodes, telles que CB2CF, qui apprend à mapper les informations de généralisation sur l'espace de comportement réel. Cependant, au lieu de suivre cette approche, on retrouve une liste d’éléments similaires à l’élément cible basée sur les vecteurs sémantiques de la vidéo. Premièrement, il partage l'espace comportemental avec les comportements d'intérêt à long terme et à court terme de l'utilisateur, et nous regroupons la liste des éléments similaires pour simuler la représentation des vidéos candidates dans l'espace comportemental. En fait, cette méthode est similaire à la méthode d'introduction d'arêtes similaires aux candidats dans le rappel de graphe que nous avons mentionnée précédemment, et l'effet est très évident, améliorant l'AUC hors ligne de 0,35PP

Deuxième La première est l'exploration , c'est-à-dire qu'une distribution précoce inexacte de nouvelles vidéos entraînera une moyenne de CTR postérieure faible, et cette moyenne faible fera également croire au modèle que la vidéo elle-même peut être de mauvaise qualité, limitant finalement l'explorabilité du contenu démarré à froid. Pouvons-nous donc modéliser l'incertitude du PCTR et ralentir l'utilisation absolue et la confiance des étiquettes lors de la phase de démarrage à froid. Nous essayons de convertir l'estimation du CTR d'une demande en une estimation distribuée bêta, en utilisant à la fois l'attente et la variance en ligne. Plus précisément, dans la pratique, nous estimerons un α et un β de la distribution bêta. Plus précisément, le plan de perte est la valeur attendue de l'erreur quadratique moyenne de la valeur estimée et de l'étiquette réelle. Après avoir élargi la valeur attendue, nous constaterons que nous devons obtenir l’espérance du carré de la valeur estimée et l’espérance de la valeur estimée. Nous pouvons calculer efficacement ces deux valeurs via les estimations α et β, et la perte est générée. Ensuite, nous pouvons entraîner la distribution bêta, et enfin ajouter une file d'attente à la valeur estimée de la distribution bêta pour équilibrer l'exploration et l'utilisation. . En fait, lorsque nous utilisons la perte bêta au stade vv faible, il y a une certaine amélioration de l'AUC, mais ce n'est pas particulièrement évident. Mais lorsque nous utilisons la distribution bêta en ligne, le taux de pénétration effectif du contenu 0vv augmente de 22 % tandis que le taux d'action global reste le même.
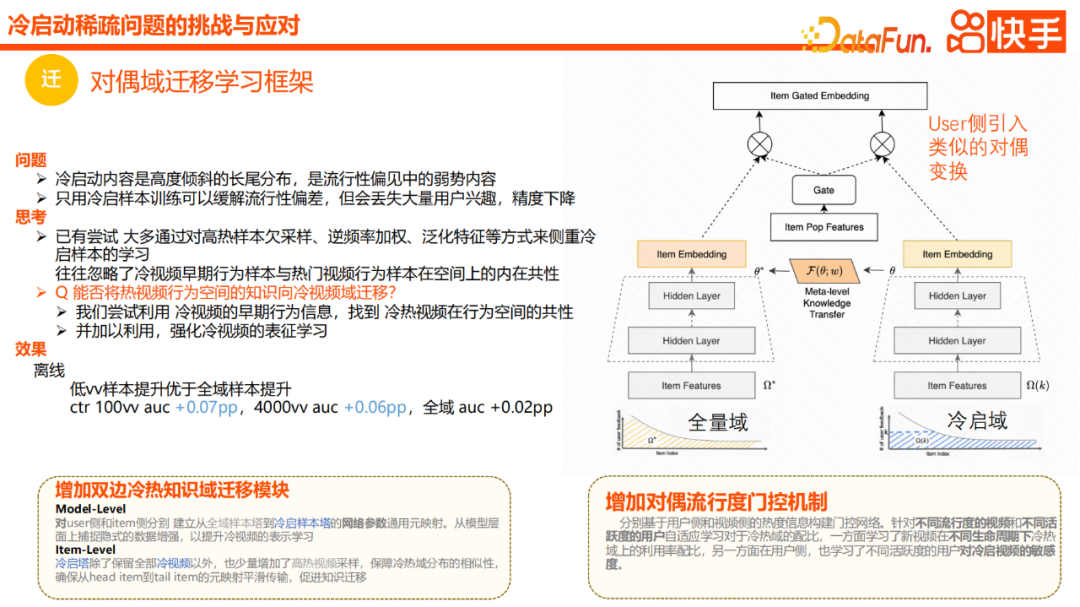
La prochaine introduction est le cadre d'apprentissage par transfert de domaine double. L’idée générale est que le contenu démarré à froid constitue souvent une distribution à longue traîne très asymétrique et constitue également un groupe vulnérable au biais de popularité. Si nous utilisons uniquement des échantillons de démarrage à froid, le biais de popularité peut être atténué dans une certaine mesure, mais une grande partie de l'intérêt des utilisateurs sera perdue, ce qui entraînera une diminution de la précision globale.
La plupart de nos tentatives actuelles se concentrent sur l'apprentissage d'échantillons de démarrage à froid via un sous-échantillonnage d'échantillons chauds, ou des fonctionnalités de pondération de fréquence inverse ou de généralisation, mais elles ignorent souvent les échantillons comportementaux de démarrage à froid précoce. Il existe un point commun inhérent dans l'espace comportemental avec des vidéos populaires.
Ainsi, pendant le processus de conception, nous diviserons l'échantillon complet et l'échantillon de démarrage à froid en deux domaines, qui sont le domaine de volume complet et le domaine de démarrage à froid dans l'image ci-dessus. Le domaine de volume complet est efficace pour tous les échantillons, et. le domaine de démarrage à froid est uniquement destiné au démarrage à froid. Seuls les échantillons conditionnels prendront effet, puis le module de migration des domaines de connaissances bilatéraux à chaud et à froid sera ajouté. Plus précisément, les utilisateurs et les éléments sont modélisés séparément, et un mappage de réseau est effectué à partir de la tour d'échantillonnage globale vers la tour d'échantillonnage à démarrage à froid, capturant ainsi une amélioration implicite des données au niveau du modèle et améliorant la représentation de vidéos de démarrage à froid. Du côté des éléments, nous conserverons tous les échantillons de démarrage à froid. De plus, nous échantillonnerons également certaines vidéos chaudes en fonction de l'exposition pour garantir la similarité de la distribution des domaines chauds et froids, et finalement assurer le transfert fluide des connaissances de l'ensemble de la cartographie.
De plus, nous avons également ajouté un mécanisme unique de contrôle de double popularité, introduit certaines fonctionnalités de popularité et l'avons utilisé pour faciliter le rapport de fusion des domaines vidéo chauds et froids. D'une part, le taux d'utilisation des expressions de démarrage à froid des nouvelles vidéos dans différents cycles de vie peut être efficacement appris et distribué. D'autre part, le côté utilisateur apprend également la sensibilité des différents utilisateurs actifs aux vidéos démarrées à froid. En pratique, l'effet hors ligne a été amélioré dans une certaine mesure, tant au stade vv faible qu'à l'AUC de 4000vv.

Enfin, je présenterai un travail sur la correction, qui est la correction thermique. Les systèmes de recommandation sont souvent confrontés à des biais de popularité et constituent généralement un carnaval de produits hautement explosifs. L'objectif de l'ajustement du paradigme du modèle existant est le CTR global. La recommandation d'éléments populaires peut entraîner une perte globale inférieure, mais elle injectera également certaines informations populaires dans l'intégration d'éléments, entraînant une surestimation des vidéos très populaires.
Certaines méthodes existantes recherchent trop une estimation impartiale, mais en fait elles entraîneront des pertes de consommation. Pouvons-nous donc dissocier certaines intégrations d'éléments des informations de popularité et des informations d'intérêt réel, et utiliser efficacement les informations de popularité et les informations d'intérêt pour la fusion en ligne ? Cela peut être une méthode plus raisonnable ? Dans la pratique spécifique, nous nous référons à certaines pratiques de nos pairs
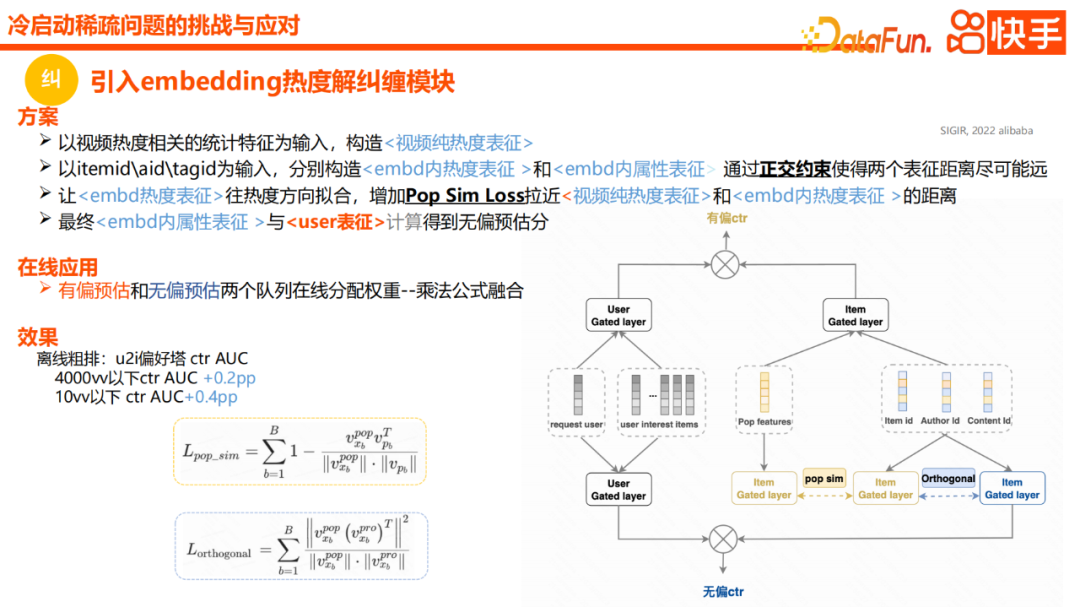
L'accent est principalement mis sur deux modules. L'un consiste à imposer des contraintes orthogonales sur la popularité et l'intérêt du contenu d'entrée, comme la saisie de l'identifiant de l'élément. , identifiant de l'auteur, etc. Les fonctionnalités généreront deux représentations. L'une de ces deux représentations est la représentation de la popularité et l'autre est la représentation de l'intérêt réel. Une contrainte régulière sera faite pendant le processus de solution. La seconde est que nous générerons également des intégrations des informations thermiques pures de certains éléments en tant que représentation thermique pure de la vidéo, afin que nous puissions. obtenez la représentation thermique qui vient d'être mentionnée. Et la représentation des intérêts, l'une d'elles exprime des informations sur la popularité et l'autre exprime des informations sur les intérêts. Enfin, sur la base de ces deux représentations, une file d'attente d'estimation biaisée et d'estimation non biaisée sera ajoutée en ligne pour la fusion des formules de multiplication.

Enfin, permettez-moi de partager mes perspectives sur les travaux futurs.
Tout d'abord, nous devons modéliser et appliquer le modèle de diffusion des foules avec plus de précision, notamment en temps réel, y compris la propagation actuelle de foules similaires. Nous avons déjà implémenté des schémas de diffusion de foule similaires dans la phase de démarrage à froid, comme une application de diffusion de U2U, et nous espérons améliorer encore son raffinement. Le deuxième est le schéma de correction. Le modèle causal actuel corrige les écarts lors du démarrage à froid. Il y a aussi beaucoup de recherches en Chine, et nous continuerons à faire des recherches et des explorations dans ce sens, notamment pour la correction de l'exposition et la correction de la chaleur. Le troisième concerne la sélection des échantillons. le démarrage des échantillons à haute température est toujours S'ils ont une plus grande valeur, pouvons-nous sélectionner des échantillons plus précieux dans l'espace d'échantillons chauds et leur attribuer des poids différents pour améliorer l'efficacité de la recommandation du modèle de démarrage à froid.
Le troisième est la caractérisation de la valeur de croissance à long terme de la vidéo. Chaque vidéo doit passer par le processus de démarrage à froid-croissance-stabilité-déclin. Comment accorder plus d'attention à ses avantages à long terme. , c'est-à-dire la croissance, lors de la modélisation des vidéos ? L'espace, notamment en termes de valorisation de la valeur, est également un travail très intéressant sur la manière de modéliser la différence de valeur des différentes distributions uniques pour la croissance future.
La dernière est la solution par l'amélioration des données. Qu'il s'agisse d'un exemple ou d'une solution d'apprentissage comparatif, nous espérons introduire des travaux dans ce domaine pour améliorer l'efficacité de la recommandation de démarrage à froid.
A1 : Le modèle I2U recherchera en permanence les utilisateurs les plus similaires dans la bibliothèque d'index pendant le processus hors ligne, puis les convertira en paires utilisateur-élément en fonction des utilisateurs et des éléments les plus similaires trouvés, et enfin obtiendra l'utilisateur -item pair Les résultats d'agrégation de la liste sont stockés dans Redis pour une utilisation en ligne
A2 : Plusieurs méthodes ont été mentionnées dans le partage. Fondamentalement, nous le résolvons toujours dans une perspective de généralisation, d'exploration et de correction. Par exemple, comment initialiser l'identifiant de l'élément afin qu'il ait un meilleur point initial, et en même temps introduire des fonctionnalités généralisées pour mapper les fonctionnalités généralisées à l'espace sémantique comportemental. Ensuite, la distribution bêta est utilisée pour améliorer l'explorabilité ; il y a également l'introduction de tours de contenu pur, supprimant les fonctionnalités avec une mémoire forte telles que pid, introduisant ainsi une estimation de généralisation pure sans biais thermique, et un travail de correction, dans l'espoir d'améliorer l'apprentissage dans le processus, les facteurs de popularité sont appris et contraints séparément, des normes d'intérêt pur et des normes de popularité sont fournies, et l'intensité d'utilisation des normes de popularité est raisonnablement distribuée en ligne. Bien entendu, en plus de ces méthodes, nous essayons également d'atténuer la rareté du contenu démarré à froid grâce à l'amélioration des données et utilisons du contenu populaire pour aider à l'apprentissage du contenu démarré à froid du point de vue de l'apprentissage par transfert.
A3 : Le taux d'optimisation est en fait une tâche avec un très haut degré de participation manuelle. Il nous est impossible d'utiliser complètement le modèle pour évaluer le taux d'optimisation d'une vidéo. Si nous pouvons utiliser un modèle pour évaluer un élément de contenu, tel qu'une vidéo avec 50 000 expositions, la participation manuelle sera impliquée dans le contenu global de haute qualité, et il sera certainement poussé aux évaluateurs d'examiner lesquels sont de haute qualité. des vidéos de qualité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment acheter et vendre du Bitcoin sur Binance
Comment acheter et vendre du Bitcoin sur Binance
 Comment changer la couleur de la police dans Dreamweaver
Comment changer la couleur de la police dans Dreamweaver
 analyses statistiques
analyses statistiques
 La différence entre les services distribués et les microservices
La différence entre les services distribués et les microservices
 Pilote d'appareil photo numérique
Pilote d'appareil photo numérique
 Le rôle du pilote de la carte graphique
Le rôle du pilote de la carte graphique
 css désactiver l'événement de clic
css désactiver l'événement de clic
 csv en vcf
csv en vcf








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



