


Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression.
Le bout en bout est une direction très populaire cette année. Le meilleur article CVPR de cette année a également été attribué à UniAD, mais il y a aussi de nombreux problèmes de bout en bout, comme. en raison de la faible interprétabilité et de la difficulté de convergence de la formation, etc., certains chercheurs dans le domaine ont commencé à se tourner progressivement vers l'interprétabilité de bout en bout. Aujourd'hui, je vais partager avec vous les derniers travaux sur l'interprétabilité de bout en bout, ADAPT. Cette méthode est basée sur l'architecture Transformer et utilise le multitâche. La méthode de formation conjointe produit des descriptions d'actions du véhicule et un raisonnement pour chaque décision de bout en bout. Certaines des réflexions de l'auteur sur ADAPT sont les suivantes :
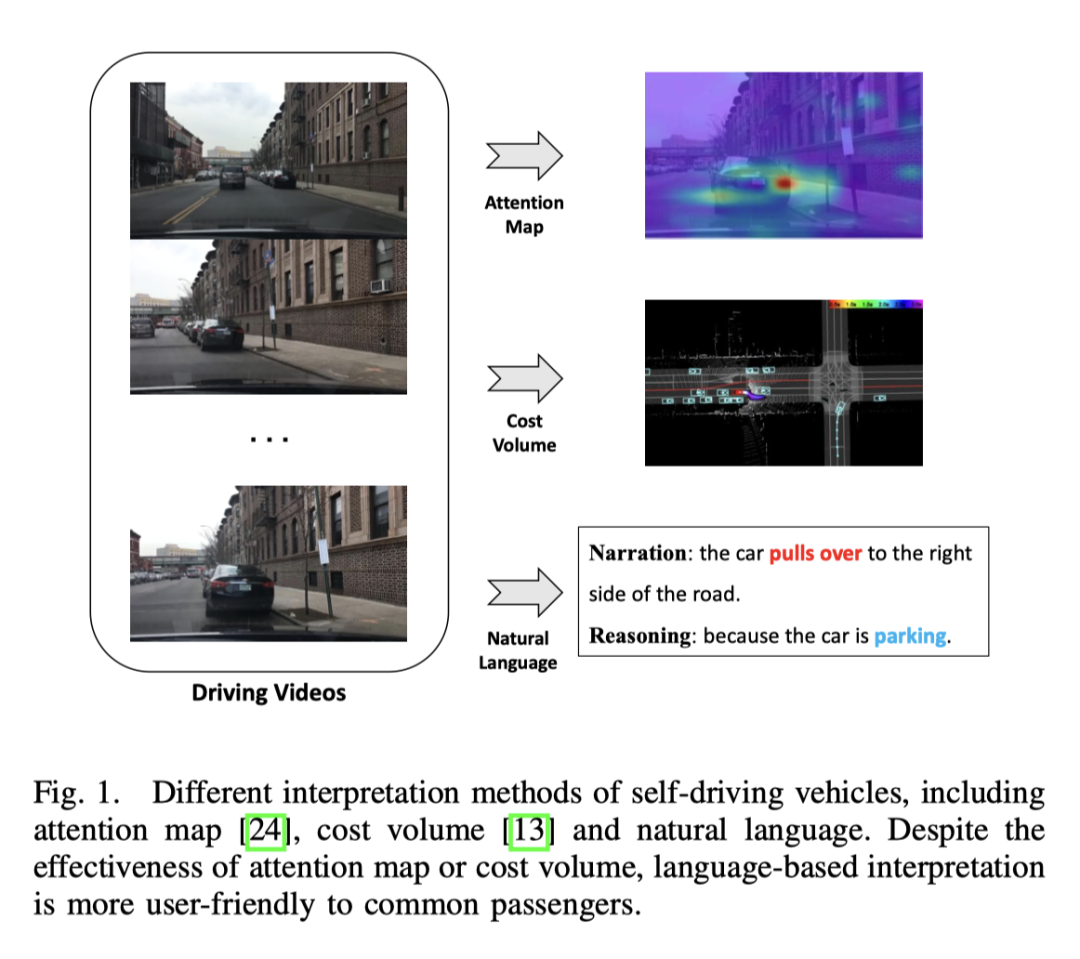

Bien que les architectures existantes aient obtenu certains résultats dans le sens général du sous-titrage vidéo, elles ne peuvent pas être directement appliquées à la représentation des actions, car simplement le transfert de descriptions vidéo vers des représentations d'actions de conduite autonome perdra certaines informations clés, telles que la vitesse du véhicule, etc., qui sont cruciales pour les tâches de conduite autonome. La manière d'utiliser efficacement ces informations multimodales pour générer des phrases est toujours à l'étude. PaLM-E fait du bon travail dans les phrases multimodales.
Conduite autonome de bout en boutDans le domaine de la conduite autonome, la plupart des méthodes d'interprétabilité sont basées sur la vision, et certaines sont basées sur les travaux LiDAR. Certaines méthodes utilisent des cartes d'attention pour filtrer les régions d'image insignifiantes, ce qui donne au comportement des véhicules autonomes une apparence raisonnable et explicable. Cependant, la carte d’attention peut contenir des régions moins importantes. Il existe également des méthodes qui utilisent le lidar et des cartes de haute précision comme entrées, prédisent les cadres de délimitation des autres participants au trafic et utilisent l'ontologie pour expliquer le processus de raisonnement décisionnel. De plus, il existe un moyen de créer des cartes en ligne grâce à la segmentation afin de réduire le recours aux cartes HD. Bien que les méthodes basées sur la vision ou le lidar puissent fournir de bons résultats, le manque d’explication verbale donne l’impression que l’ensemble du système est complexe et difficile à comprendre. Une étude explore pour la première fois la possibilité d'interprétation de texte pour les véhicules autonomes, en extrayant des fonctionnalités vidéo hors ligne pour prédire les signaux de commande et effectuer la tâche de description vidéo
Cette étude de bout en bout cadre final L'apprentissage multitâche est adopté pour entraîner conjointement le modèle avec les deux tâches de génération de texte et de prédiction des signaux de contrôle. L’apprentissage multitâche est largement utilisé dans la conduite autonome. En raison d'une meilleure utilisation des données et des fonctionnalités partagées, la formation conjointe de différentes tâches améliore les performances de chaque tâche. Par conséquent, dans ce travail, une formation conjointe des deux tâches de prédiction du signal de contrôle et de génération de texte est utilisée.
Voici le diagramme de structure du réseau :
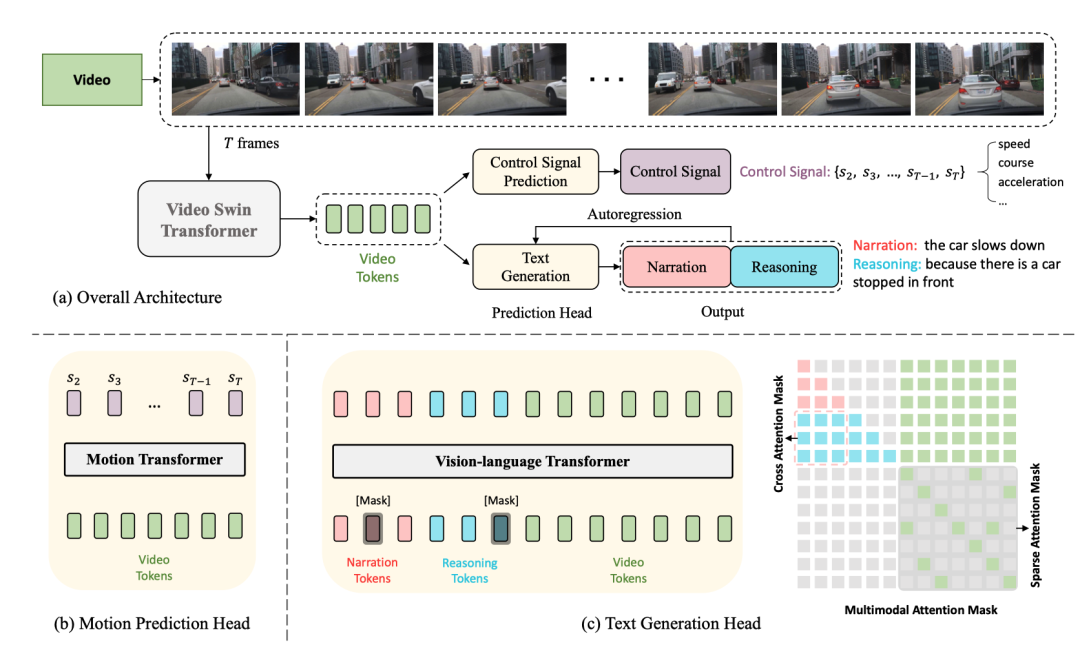
La structure entière est divisée en deux tâches :
Parmi eux, les deux tâches DCG et CSP partagent l'encodeur vidéo, mais utilisent des têtes de prédiction différentes pour produire des sorties finales différentes.
Pour la tâche DCG, l'encodeur du transformateur vision-langage est utilisé pour générer deux phrases en langage naturel.
Pour les tâches CSP, utilisez l'encodeur de transformation de mouvement pour prédire la séquence des signaux de contrôle
Le transformateur Swin vidéo est utilisé ici pour convertir les images vidéo d'entrée en jetons de fonctionnalités vidéo.
Entrée 桢image, la forme est , la taille de la fonctionnalité est , où est la dimension du canal
. ci-dessus Cette fonctionnalité , Après la tokenisation, des jetons vidéo avec des dimensions sont obtenus, puis un MLP est utilisé pour ajuster les dimensions afin de les aligner sur l'intégration des jetons de texte, puis les jetons de texte et les jetons vidéo sont transmis à la vision- encodeur de transformateur de langage ensemble pour générer des descriptions d'actions et un raisonnement.
et l'entrée 桢vidéo correspondent au signal de contrôle La sortie de la tête CSP est Chaque signal de contrôle ici n'est pas nécessairement unidimensionnel, mais peut être multi. -dimensionnel, comme la vitesse, l'accélération, la direction, etc. L'approche ici consiste à tokeniser les fonctionnalités vidéo et à générer une série de signaux de sortie via le transformateur de mouvement. La fonction de perte est MSE,
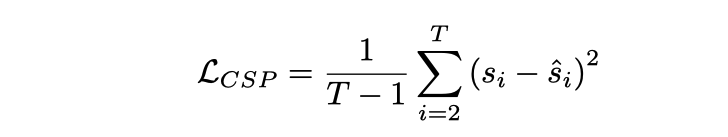
Il convient de noter que la première image n'est pas incluse ici car la première image y fournit. il y a trop peu d'informations dynamiques
Dans ce cadre, en raison de l'encodeur vidéo partagé, il est en fait supposé que les deux tâches de CSP et DCG sont alignées au niveau de la représentation vidéo. Le point de départ est que les descriptions d’actions et les signaux de commande sont des expressions différentes des actions fines du véhicule, et les explications du raisonnement des actions se concentrent principalement sur l’environnement de conduite qui affecte les actions du véhicule.
Formation utilisant une formation conjointe
Il convient de noter que bien qu'il s'agisse d'un lieu de formation conjointe, elle peut être exécutée indépendamment lors de l'inférence. La tâche CSP est facile à comprendre selon l'organigramme et. contrôle de sortie Le signal est suffisant. Pour la tâche DCG, la vidéo est directement entrée et la description et le raisonnement sont générés mot par mot sur la base de la méthode autorégressive, en commençant par [CLS] et en terminant par [SEP] ou. atteignant le seuil de longueur.
L'ensemble de données utilisé est BDD-X Cet ensemble de données contient 7000 vidéos appariées et signaux de contrôle. Chaque vidéo dure environ 40 secondes, la taille de l'image est de et la fréquence est de FPS. Chaque vidéo comporte 1 à 5 comportements de véhicule, tels que l'accélération, le virage à droite et la fusion. Toutes ces actions sont annotées de texte, y compris des récits d'action (par exemple, « La voiture s'est arrêtée ») et un raisonnement (par exemple, « Parce que le feu de circulation est rouge »). Il existe au total environ 29 000 paires d’annotations comportementales.
Trois expériences sont comparées ici pour illustrer l'efficacité de l'entraînement conjoint.
fait référence à la suppression de la tâche CSP et à la conservation de la tâche DCG, ce qui équivaut à entraîner uniquement le modèle de sous-titrage
Bien que CSP Le. La tâche n'existe toujours pas, mais lors de la saisie du module DCG, en plus des balises vidéo, des balises de signal de contrôle doivent également être saisies
La comparaison des effets est la suivante
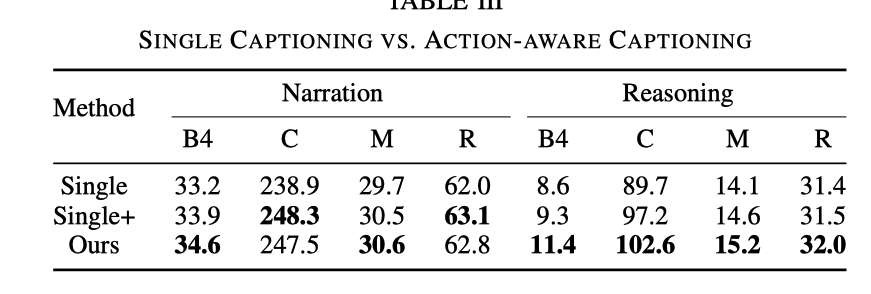
Par rapport à la tâche DCG uniquement, le raisonnement d'ADAPT l'effet est nettement meilleur. Bien que l'effet soit amélioré lorsqu'il y a une entrée de signal de contrôle, il n'est toujours pas aussi bon que l'effet de l'ajout de tâches CSP. Après avoir ajouté la tâche CSP, la capacité d'exprimer et de comprendre la vidéo est plus forte
De plus, le tableau ci-dessous montre également que l'effet de l'entraînement conjoint sur le CSP est également amélioré.

Ici peut être compris comme précision, plus précisément ce sera Le signal de contrôle prédit est tronqué et la formule est la suivante
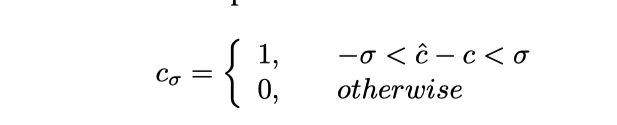
Dans l'expérience, les signaux de base utilisés sont la vitesse et le cap. Cependant, des expériences ont montré que lorsqu'un seul des signaux est utilisé, l'effet n'est pas aussi bon que l'utilisation des deux signaux en même temps. Les données spécifiques sont présentées dans le tableau suivant :
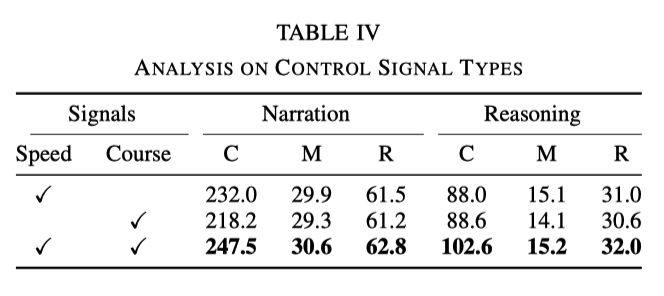
Cela montre que les deux signaux. de vitesse et de direction peuvent aider le réseau à mieux apprendre la description d'action et le raisonnement
Par rapport aux tâches de description générale, la génération de tâches de description de conduite comprend deux phrases, à savoir la description d'action et le raisonnement. On le trouve dans le tableau suivant :
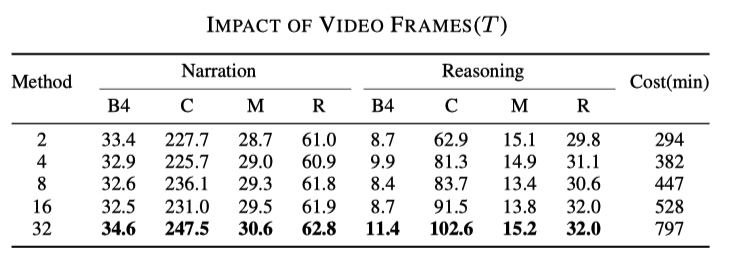
L'impact des taux d'échantillonnage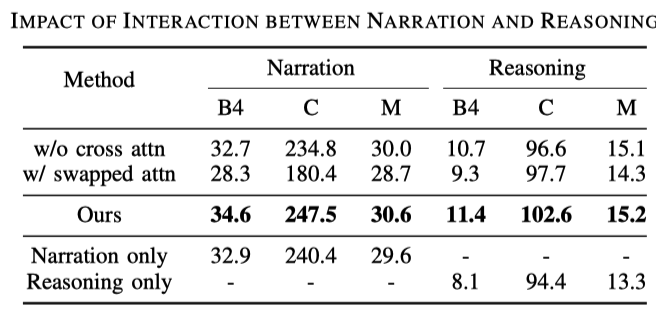
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Comment écrire des contraintes de vérification MySQL
Comment écrire des contraintes de vérification MySQL
 Comment définir le chinois dans Eclipse
Comment définir le chinois dans Eclipse
 Introduction aux caractères de retour chariot et de saut de ligne en Java
Introduction aux caractères de retour chariot et de saut de ligne en Java
 Comment formater le disque dur sous Linux
Comment formater le disque dur sous Linux
 Méthode de production de rapports Intouch
Méthode de production de rapports Intouch
 Comment exécuter du code HTML dans vscode
Comment exécuter du code HTML dans vscode
 le wifi n'affiche aucune adresse IP attribuée
le wifi n'affiche aucune adresse IP attribuée








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



