


Si vous avez déjà interagi avec un robot IA conversationnel, vous vous souviendrez de moments très frustrants. Par exemple, les choses importantes que vous avez mentionnées dans la conversation de la veille ont été complètement oubliées par l'IA...
C'est parce que la plupart des LLM actuels ne peuvent mémoriser qu'un contexte limité, tout comme les étudiants qui bachotent pour les examens, un peu croisés. l’examen « révélera la vérité ».
Ne serait-il pas enviable si un assistant IA pouvait référencer contextuellement des conversations d'il y a des semaines ou des mois dans une conversation, ou si vous pouviez demander à l'assistant IA de résumer un rapport de plusieurs milliers de pages ?
Afin de permettre au LLM de mieux mémoriser et de mémoriser plus de contenu, les chercheurs ont travaillé dur. Récemment, des chercheurs du MIT, Meta AI et de l'Université Carnegie Mellon ont proposé une méthode appelée "StreamingLLM" qui permet aux modèles de langage de traiter en douceur du texte sans fin

StreamingLLM fonctionne en identifiant et en enregistrant les « puits d'attention » inhérents au modèle " (l'attention coule) qui ancre le jeton initial pour son raisonnement. Combiné à la mise en cache continue des jetons récents, StreamingLLM accélère l'inférence de 22 fois sans sacrifier la précision. En quelques jours seulement, le projet a gagné 2,5K étoiles sur la plateforme GitHub :
Plus précisément, StreamingLLM est un modèle de langage qui permet de mémoriser avec précision le score du jeu précédent, le nom d'un enfant. un long contrat ou le contenu d'un débat. Tout comme la mise à niveau de la mémoire de l'assistant IA, il peut parfaitement gérer des charges de travail plus lourdes

Examinons ensuite les détails techniques.
Habituellement, le LLM est limité par la fenêtre d'attention pendant la pré-formation. Bien qu'il y ait eu de nombreux travaux antérieurs pour étendre cette taille de fenêtre et améliorer l'efficacité de la formation et de l'inférence, la longueur de séquence acceptable de LLM est encore limitée, ce qui n'est pas convivial pour un déploiement persistant.
Dans cet article, le chercheur a d'abord introduit le concept d'application de streaming LLM et a soulevé une question : "Le LLM peut-il être déployé avec une entrée infiniment longue sans sacrifier l'efficacité et les performances ?"
Lors de l'application du LLM à une entrée infiniment longue flux d'entrée, vous serez confronté à deux défis principaux :
1. Lors de l'étape de décodage, le LLM basé sur le transformateur mettra en cache l'état de la clé et de la valeur (KV) de tous les jetons précédents, comme le montre la figure 1 (comme le montre la figure 1). a), cela peut entraîner une utilisation excessive de la mémoire et augmenter la latence de décodage
2. La capacité d'extrapolation de longueur des modèles existants est limitée, c'est-à-dire que lorsque la longueur de la séquence dépasse la fenêtre d'attention définie lors de la pré-entraînement, elle l'est également ; de longues heures, ses performances se dégraderont.
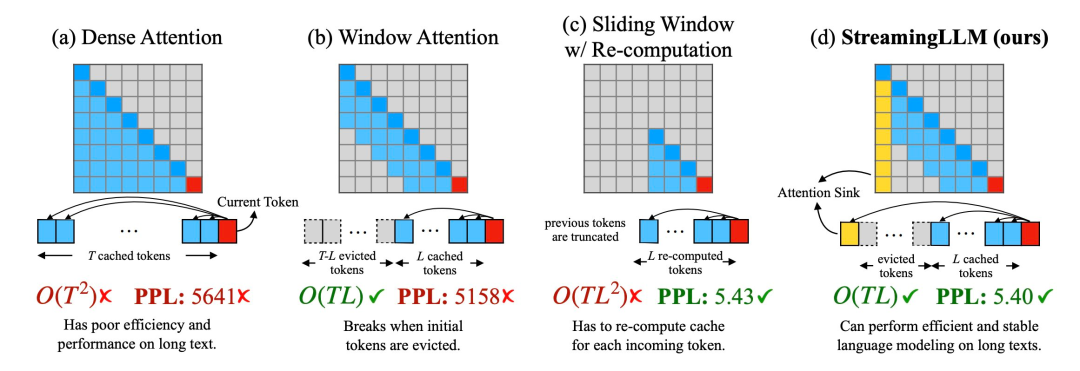
Une méthode intuitive est appelée Window Attention (Figure 1 b). Cette méthode maintient uniquement une fenêtre glissante de taille fixe sur l'état KV du jeton le plus récent, bien qu'elle puisse garantir une utilisation et un décodage stables de la mémoire. vitesse une fois le cache rempli, mais une fois que la longueur de la séquence dépasse la taille du cache, ou même expulse simplement le KV du premier jeton, le modèle plante. Une autre méthode consiste à recalculer la fenêtre glissante (illustré dans la figure 1 c). Cette méthode reconstruira l'état KV du jeton récent pour chaque jeton généré. Bien que les performances soient puissantes, elle nécessite le calcul de l'attention secondaire dans la fenêtre. le résultat est nettement plus lent, ce qui n’est pas idéal dans les vraies applications de streaming.
En étudiant l'échec de l'attention par fenêtre, les chercheurs ont découvert un phénomène intéressant : selon la figure 2, un grand nombre de scores d'attention sont attribués aux balises initiales, que ces balises soient liées ou non à la tâche de modélisation du langage
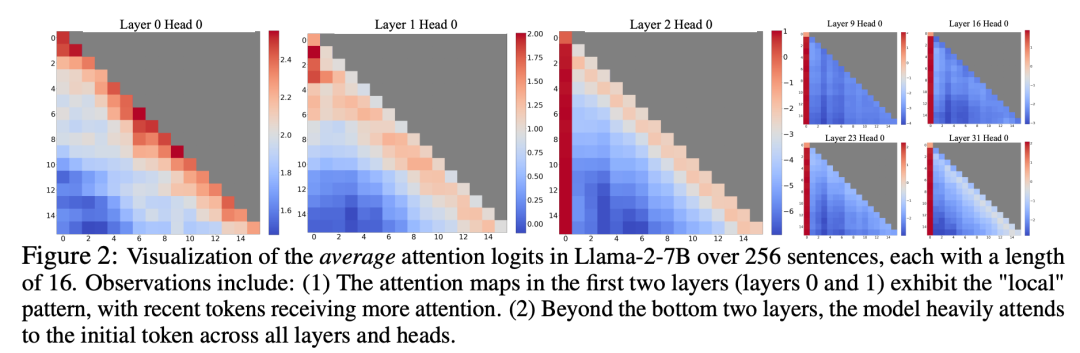
Les chercheurs appellent ces jetons « pools d'attention » : bien qu'ils manquent de signification sémantique, ils occupent une grande partie des scores d'attention. Les chercheurs attribuent ce phénomène à Softmax (qui nécessite que la somme des scores d'attention de tous les jetons de contexte soit égale à 1). Même si la requête actuelle n'a pas de correspondance forte parmi de nombreux jetons précédents, le modèle doit quand même transférer ces attentions indésirables. . Les valeurs sont attribuées quelque part pour qu'elles totalisent 1. La raison pour laquelle le jeton initial devient un « pool » est intuitive : en raison des caractéristiques de la modélisation autorégressive du langage, le jeton initial est visible par presque tous les jetons suivants, ce qui facilite leur formation en tant que pool d'attention.
Sur la base des informations ci-dessus, le chercheur a proposé StreamingLLM. Il s'agit d'un cadre simple et efficace qui permet aux modèles d'attention formés avec des fenêtres d'attention limitées de gérer des textes infiniment longs sans réglage fin.
StreamingLLM profite du fait que les pools d'attention ont des valeurs d'attention élevées. En fait, conserver ces pools d'attention peut rendre la distribution du score d'attention proche d'une distribution normale. Par conséquent, StreamingLLM n'a besoin de conserver que la valeur KV du jeton du pool d'attention (seuls 4 jetons initiaux suffisent) et la valeur KV de la fenêtre glissante pour ancrer le calcul de l'attention et stabiliser les performances du modèle.
Utilisation de StreamingLLM, notamment Llama-2-[7,13,70] B, MPT-[7,30] B, Falcon-[7,40] B et Pythia [2.9,6.9,12] B Le modèle peut simuler de manière fiable 4 millions de jetons ou plus.
Par rapport au recalcul de la fenêtre glissante, StreamingLLM est 22,2 fois plus rapide sans affecter les performances
Dans l'expérience, comme le montre la figure 3, pour une durée de 20K Pour le texte étiqueté, la perplexité de StreamingLLM est comparable à la ligne de base Oracle recalculant la fenêtre glissante. Dans le même temps, lorsque la longueur d'entrée dépasse la fenêtre de pré-entraînement, l'attention dense échoue, et lorsque la longueur d'entrée dépasse la taille du cache, l'attention de la fenêtre reste bloquée, provoquant l'élimination des balises initiales
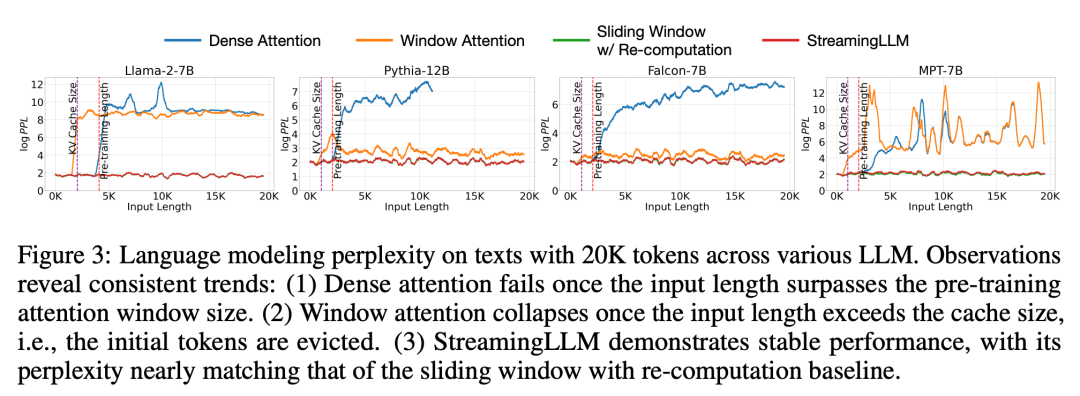
Figure 5 Plus loin La fiabilité de StreamingLLM a été démontrée et il peut gérer du texte de tailles inhabituelles, dont plus de 4 millions de jetons, couvrant une variété de familles et de tailles de modèles. Ces modèles incluent Llama-2-[7,13,70] B, Falcon-[7,40] B, Pythia-[2.8,6.9,12] B et MPT-[7,30] B
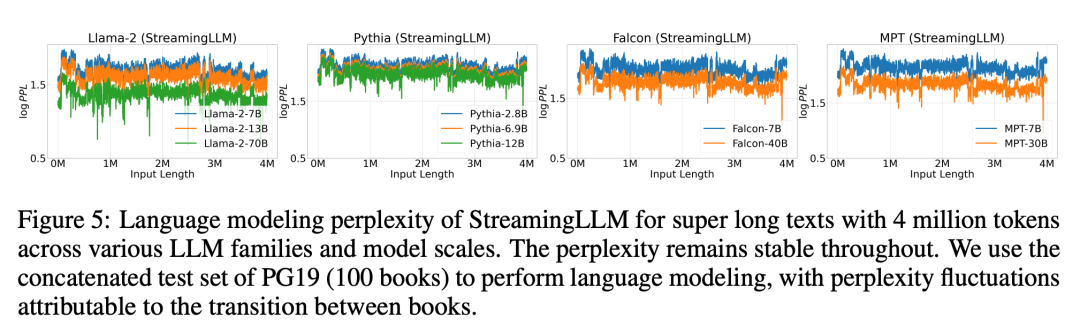
Par la suite, les chercheurs ont confirmé l'hypothèse du « pool d'attention » et ont prouvé que le modèle de langage peut être pré-entraîné et ne nécessite qu'un seul jeton de pool d'attention lors du déploiement du streaming. Plus précisément, ils recommandent d’ajouter un jeton apprenable supplémentaire au début de tous les échantillons de formation en tant que pool d’attention désigné. En pré-entraînant un modèle de langage avec 160 millions de paramètres à partir de zéro, les chercheurs ont démontré que notre méthode peut maintenir les performances du modèle. Cela contraste fortement avec les modèles de langage actuels, qui nécessitent la réintroduction de plusieurs jetons initiaux en tant que pools d'attention pour atteindre le même niveau de performances.
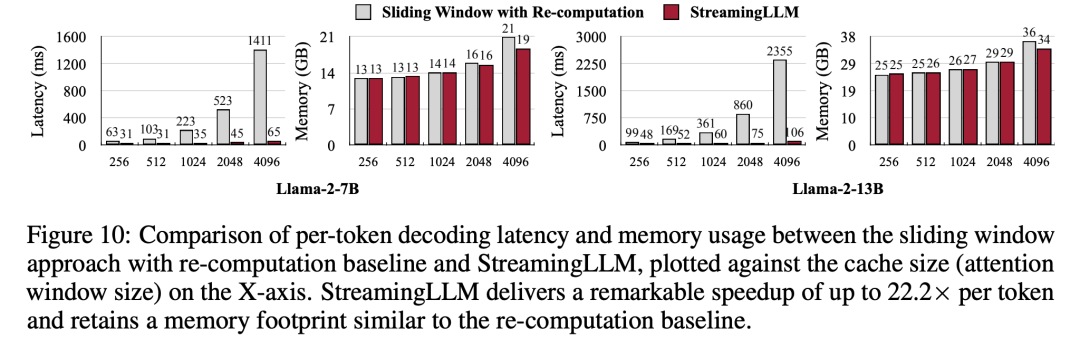
Enfin, les chercheurs ont comparé la latence de décodage et l'utilisation de la mémoire de StreamingLLM avec la fenêtre coulissante de recalcul et l'ont testé en utilisant les modèles Llama-2-7B et Llama-2-13B sur un seul GPU NVIDIA A6000. Selon les résultats de la figure 10, à mesure que la taille du cache augmente, la vitesse de décodage de StreamingLLM augmente de manière linéaire, tandis que le délai de décodage augmente de manière quadratique. Des expériences ont prouvé que StreamingLLM atteint des accélérations impressionnantes, la vitesse de chaque jeton étant augmentée jusqu'à 22,2 fois
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment intercepter les appels harcelants
Comment intercepter les appels harcelants
 Oracle effacer les données du tableau
Oracle effacer les données du tableau
 Techniques couramment utilisées par les robots d'exploration Web
Techniques couramment utilisées par les robots d'exploration Web
 Diagramme de topologie de réseau
Diagramme de topologie de réseau
 Quel système oa est le meilleur ?
Quel système oa est le meilleur ?
 Que dois-je faire si mon iPad ne peut pas être chargé ?
Que dois-je faire si mon iPad ne peut pas être chargé ?
 Avantages de pycharm
Avantages de pycharm
 Comment résoudre javascriptvoid(o)
Comment résoudre javascriptvoid(o)








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



