


La tâche de génération d'action humaine vise à générer des séquences d'action humaine réalistes pour répondre aux besoins du divertissement, de la réalité virtuelle, de la robotique et d'autres domaines. Les méthodes de génération traditionnelles incluent des étapes telles que la création de personnages 3D, l'animation d'images clés et la capture de mouvements, qui présentent de nombreuses limites, telles que la lenteur, l'exigence de connaissances techniques professionnelles, l'implication de systèmes et de logiciels coûteux et la compatibilité possible entre différents systèmes logiciels et matériels. Problèmes sexuels, etc. Avec le développement de l'apprentissage profond, les gens ont commencé à essayer d'utiliser des modèles génératifs pour générer automatiquement des séquences d'actions humaines, par exemple en saisissant des descriptions textuelles et en exigeant que le modèle génère des séquences d'actions qui correspondent aux exigences du texte. À mesure que les modèles de diffusion sont introduits dans le domaine, la cohérence des actions générées avec un texte donné continue de s'améliorer.
Cependant, bien que le naturel des actions générées ait été amélioré, il existe encore un grand écart entre celui-ci et les besoins des utilisateurs. Afin d'améliorer encore les capacités de l'algorithme de génération de mouvement humain, cet article propose l'algorithme ReMoDiffuse (Figure 1) basé sur MotionDiffuse [1]. En utilisant la stratégie de récupération, nous trouvons des échantillons de référence très pertinents et fournissons des fonctionnalités de référence fines pour générer des séquences d'action de meilleure qualité

Lien papier : https://arxiv.org/pdf/2304.01116 .pdf
Lien GitHub : https://github.com/mingyuan-zhang/ReMoDiffuse
Page d'accueil du projet : https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
En fusionnant intelligemment la diffusion modèles dotés de stratégies de récupération innovantes, ReMoDiffuse insuffle une nouvelle vie à la génération d’actions humaines guidée par texte. Grâce à une structure de modèle soigneusement conçue, ReMoDiffuse est non seulement capable de créer des séquences d'action riches, diversifiées et très réalistes, mais peut également répondre efficacement à des exigences d'action de différentes longueurs et multi-granularités. Les expériences prouvent que ReMoDiffuse fonctionne bien sur plusieurs indicateurs clés dans le domaine de la génération d'actions, surpassant considérablement les algorithmes existants.
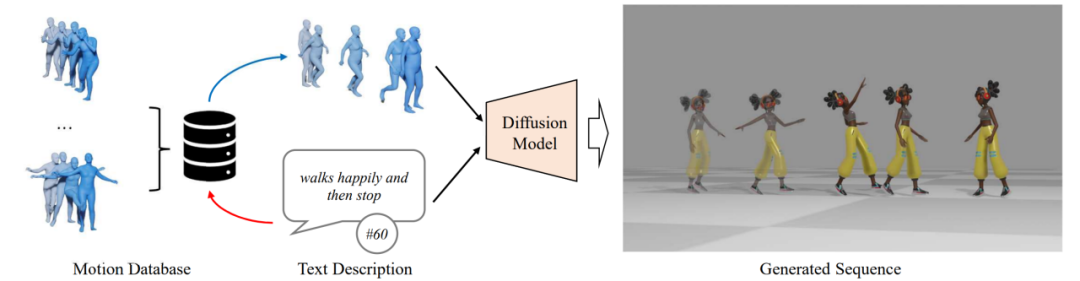 Figure 1. Présentation de ReMoDiffuse
Figure 1. Présentation de ReMoDiffuse
Introduction à la méthode
Le processus principal de ReMoDiffuse est divisé en deux étapes : la récupération et la diffusion. Au stade de la récupération, ReMoDiffuse utilise une technologie de récupération hybride pour récupérer des échantillons riches en informations à partir de bases de données multimodales externes en fonction du texte saisi par l'utilisateur et de la longueur attendue de la séquence d'action, fournissant ainsi des conseils puissants pour la génération d'actions. Au cours de l'étape de diffusion, ReMoDiffuse utilise les informations obtenues lors de l'étape de récupération pour générer des séquences de mouvement sémantiquement cohérentes avec les entrées de l'utilisateur via une structure de modèle efficace.
Afin de garantir une récupération efficace, ReMoDiffuse a soigneusement conçu le flux de données suivant pour la récupération étape (Figure 2) :
Il existe trois types de données impliquées dans le processus de récupération, à savoir le texte saisi par l'utilisateur, la longueur attendue de la séquence d'action et une base de données multimodale externe contenant plusieurs paires. Lors de la récupération des échantillons les plus pertinents, ReMoDiffuse utilise la formule 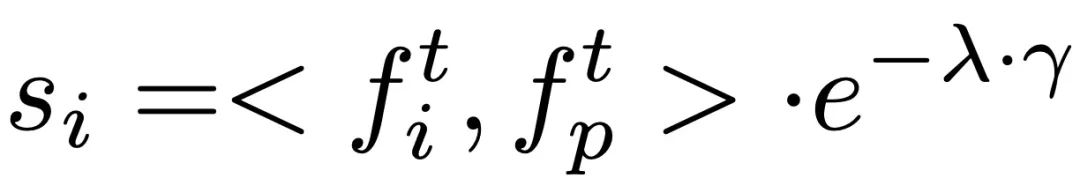 pour calculer la similarité entre les échantillons de chaque base de données et les entrées de l'utilisateur. Le premier élément ici consiste à calculer la similarité cosinus entre le texte saisi par l'utilisateur et le texte de l'entité de base de données à l'aide de l'encodeur de texte du modèle CLIP [2] pré-entraîné, et le deuxième élément calcule la différence entre la longueur attendue de la séquence d'action. et la longueur de la séquence d'action de l'entité de base de données. La différence relative est considérée comme la similarité cinématique. Après avoir calculé le score de similarité, ReMoDiffuse sélectionne les k meilleurs échantillons présentant une similarité similaire à celle des échantillons récupérés et extrait les caractéristiques de texte
pour calculer la similarité entre les échantillons de chaque base de données et les entrées de l'utilisateur. Le premier élément ici consiste à calculer la similarité cosinus entre le texte saisi par l'utilisateur et le texte de l'entité de base de données à l'aide de l'encodeur de texte du modèle CLIP [2] pré-entraîné, et le deuxième élément calcule la différence entre la longueur attendue de la séquence d'action. et la longueur de la séquence d'action de l'entité de base de données. La différence relative est considérée comme la similarité cinématique. Après avoir calculé le score de similarité, ReMoDiffuse sélectionne les k meilleurs échantillons présentant une similarité similaire à celle des échantillons récupérés et extrait les caractéristiques de texte 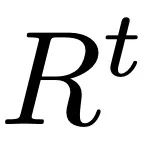 et les caractéristiques d'action
et les caractéristiques d'action 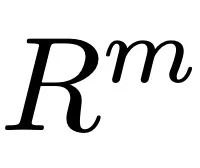 . Ces deux éléments, ainsi que les caractéristiques
. Ces deux éléments, ainsi que les caractéristiques  extraites du texte saisi par l'utilisateur, servent de signaux d'entrée à l'étape de diffusion pour guider la génération d'actions.
extraites du texte saisi par l'utilisateur, servent de signaux d'entrée à l'étape de diffusion pour guider la génération d'actions.
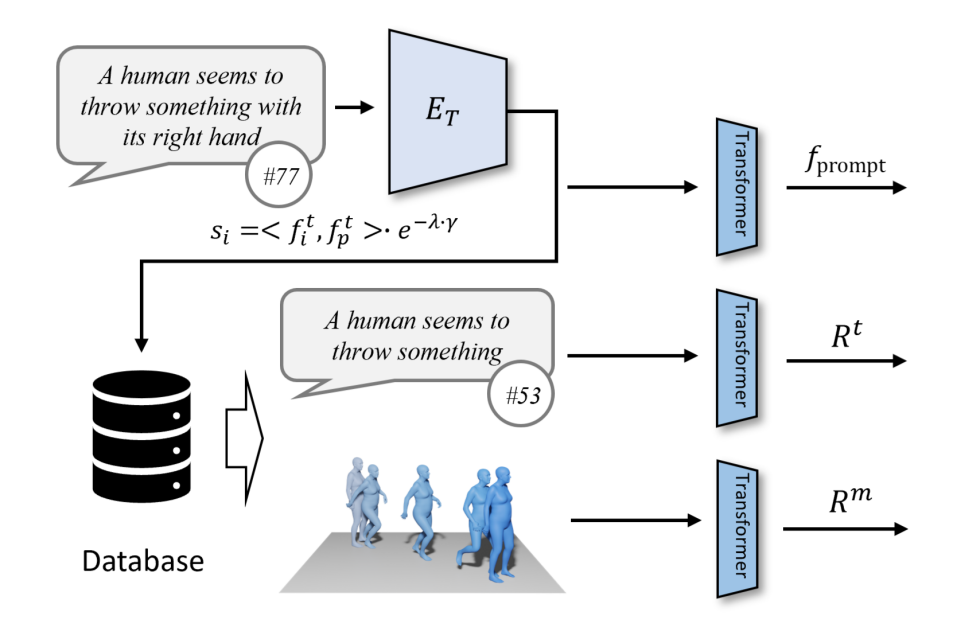 Figure 2 : Phase de récupération de ReMoDiffuse
Figure 2 : Phase de récupération de ReMoDiffuse
Le processus de diffusion (Figure 3.c) se compose de deux parties : le processus direct et le processus inverse. Dans le processus direct, ReMoDiffuse ajoute progressivement du bruit gaussien aux données de mouvement d'origine et les convertit finalement en bruit aléatoire. Le processus inverse se concentre sur la suppression du bruit et la génération d’échantillons de mouvement réalistes. À partir d'un bruit gaussien aléatoire, ReMoDiffuse utilise un module de modulation sémantique (SMT) (Figure 3.a) à chaque étape du processus inverse pour estimer la vraie distribution et supprimer progressivement le bruit en fonction du signal conditionnel. Le module SMA dans SMT intégrera ici toutes les informations de condition dans les caractéristiques de séquence générées, qui est le module de base proposé dans cet article
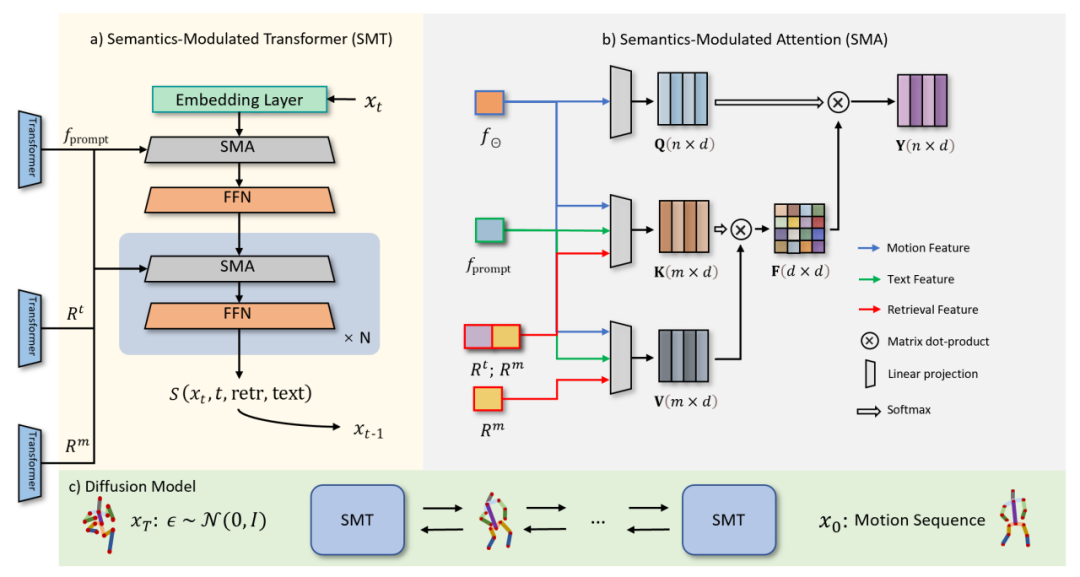 Figure 3 : Étape de diffusion de ReMoDiffuse
Figure 3 : Étape de diffusion de ReMoDiffuse
Pour la couche SMA ( Figure 3.b), nous utilisons le mécanisme d'attention efficace (Efficient Attention) [3] pour accélérer le calcul du module d'attention et créer une carte de caractéristiques globale qui met davantage l'accent sur les informations globales. Cette carte de fonctionnalités fournit des indices sémantiques plus complets pour les séquences d'actions, améliorant ainsi les performances du modèle. L'objectif principal de la couche SMA est d'optimiser la génération de séquences d'actions 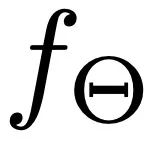 en agrégeant les informations de condition. Dans ce cadre :
en agrégeant les informations de condition. Dans ce cadre :
1.Q vecteur représente spécifiquement la séquence d'action attendue  que nous espérons générer sur la base d'informations conditionnelles. Le vecteur
que nous espérons générer sur la base d'informations conditionnelles. Le vecteur
2.K sert de mécanisme d'indexation qui prend en compte de manière exhaustive plusieurs facteurs, notamment les caractéristiques de la séquence d'action actuelle , les caractéristiques sémantiques saisies par l'utilisateur  et les caractéristiques
et les caractéristiques  et
et  obtenues à partir des échantillons de récupération. Parmi eux, représente les caractéristiques de séquence d'action obtenues à partir des échantillons de récupération, et représente les caractéristiques de description de texte obtenues à partir des échantillons de récupération. Cette méthode de construction complète garantit l'efficacité des vecteurs K dans le processus d'indexation.
obtenues à partir des échantillons de récupération. Parmi eux, représente les caractéristiques de séquence d'action obtenues à partir des échantillons de récupération, et représente les caractéristiques de description de texte obtenues à partir des échantillons de récupération. Cette méthode de construction complète garantit l'efficacité des vecteurs K dans le processus d'indexation.
Le vecteur 3.V fournit les fonctionnalités réelles nécessaires pour générer l'action. Semblable au vecteur K, le vecteur V prend en compte l'échantillon de récupération, les entrées de l'utilisateur et la séquence d'actions en cours. Puisqu'il n'y a pas de corrélation directe entre la fonctionnalité de description textuelle de l'échantillon récupéré et l'action générée, nous choisissons de ne pas utiliser cette fonctionnalité lors du calcul du vecteur V afin d'éviter des interférences d'informations inutiles
Combinée au mécanisme de modèle d'attention global d'Efficient Attention, la couche SMA utilise les informations auxiliaires de l'échantillon de récupération, les informations sémantiques du texte utilisateur et les informations sur les caractéristiques de la séquence à débruiter pour établir une série de modèles globaux complets. , de sorte que toutes les informations de condition puissent être entièrement absorbées par la séquence à générer.
Afin de réécrire le contenu, le texte original doit être converti en chinois. Voici à quoi cela ressemble après réécriture : Conception de la recherche et résultats expérimentaux
Nous avons évalué ReMoDiffuse sur deux ensembles de données, HumanML3D [4] et KIT-ML [5]. Les résultats expérimentaux (Tableaux 1 et 2) démontrent les puissantes performances et les avantages de notre framework ReMoDiffuse proposé du point de vue de la cohérence du texte et de la qualité de l'action
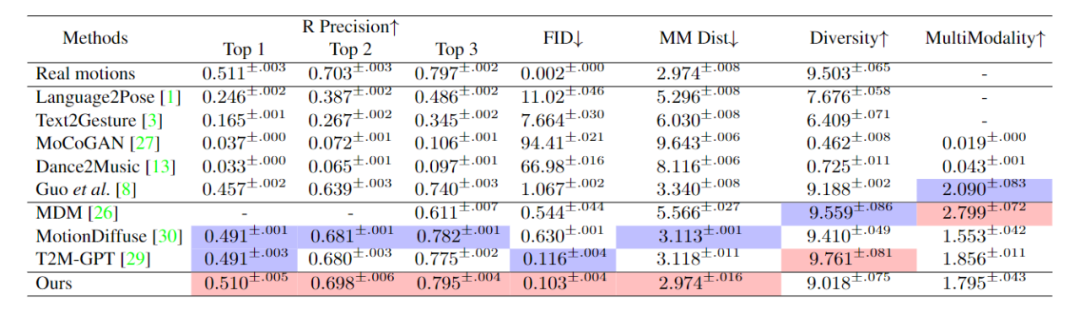 Tableau 1. Performances des différentes méthodes sur l'ensemble de test HumanML3D
Tableau 1. Performances des différentes méthodes sur l'ensemble de test HumanML3D
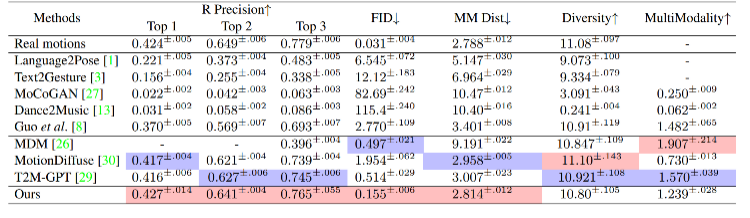 Tableau 2. Performances des différentes méthodes sur l'ensemble de test KIT-ML
Tableau 2. Performances des différentes méthodes sur l'ensemble de test KIT-ML
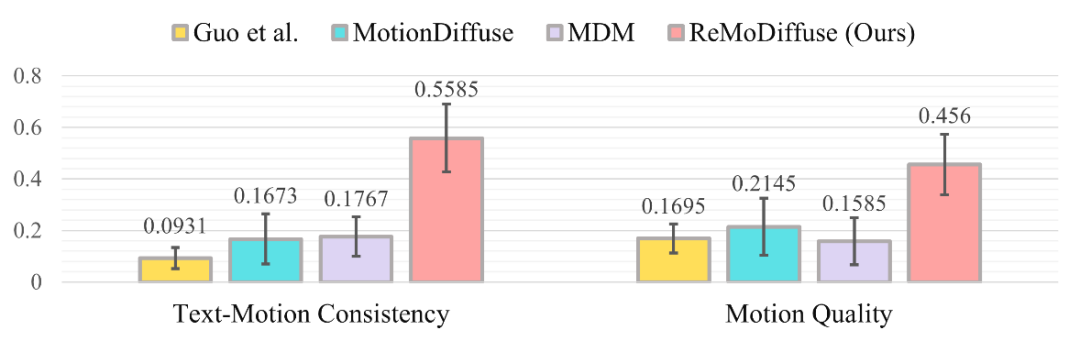
Voici quelques exemples montrant les puissantes performances de ReMoDiffuse (Figure 4). Par rapport aux méthodes précédentes, par exemple, étant donné le texte « Une personne saute en cercle », seul ReMoDiffuse est capable de capturer avec précision le mouvement de « saut » et la trajectoire du « cercle ». Cela démontre que ReMoDiffuse est capable de capturer efficacement les détails du texte et d'aligner le contenu sur des durées de mouvement données. affiché les séquences d'actions correspondantes générées par la méthode de Guo et al. [4], MotionDiffuse [1], MDM [6] et ReMoDiffuse, et recueilli les opinions des participants au test sous la forme d'un questionnaire. La distribution des résultats est présentée à la figure 5. Il ressort clairement des résultats que dans la plupart des cas, les participants au test pensent que la séquence d'actions générée par notre méthode, c'est-à-dire la séquence d'actions générée par ReMoDiffuse, est la plus cohérente avec la description textuelle donnée parmi les quatre algorithmes, et est aussi le plus naturel et le plus doux.
 Figure 5 : Répartition des résultats de l'enquête auprès des utilisateurs
Figure 5 : Répartition des résultats de l'enquête auprès des utilisateurs
 Ming Yuan Zhang, Cai Zhonggang, Pan Liang, Hong Fangzhou, Guo Xinying, Yang Lei et Liu Ziwei. Motiondiffuse : génération de mouvements humains basée sur du texte et basée sur des modèles de diffusion. Préimpression arXiv arXiv:2208.15001, 2022 [2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. modèles visuels issus de la supervision du langage naturel. préimpression arXiv arXiv : 2103.00020, 2021.
Ming Yuan Zhang, Cai Zhonggang, Pan Liang, Hong Fangzhou, Guo Xinying, Yang Lei et Liu Ziwei. Motiondiffuse : génération de mouvements humains basée sur du texte et basée sur des modèles de diffusion. Préimpression arXiv arXiv:2208.15001, 2022 [2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. modèles visuels issus de la supervision du langage naturel. préimpression arXiv arXiv : 2103.00020, 2021.
[3] Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi et Hongsheng Li. Conférence d'hiver IEEE/CVF sur les applications de la vision par ordinateur, pages 3531-3539, 2021.
[4] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li et Li Cheng. mouvements humains naturels en 3D à partir d'un texte. Dans les actes de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes, pages 5152-5161, 2022.
Le contenu qui doit être réécrit est : [5] Matthias Plappert, Christian Mandery. et Tamim Asfour. "Ensemble de données sur le langage moteur". Big Data, 4(4):236-252, 2016
[6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or et Amit H Bermano Modèle de diffusion du mouvement humain. Conférence internationale sur les représentations de l'apprentissage, 2022.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



