Avec l'essor de la télémédecine, les patients sont de plus en plus enclins à choisir la consultation et la consultation en ligne pour rechercher un accompagnement médical pratique et efficace. Récemment, les grands modèles de langage (LLM) ont démontré de puissantes capacités d'interaction en langage naturel, apportant l'espoir aux assistants médicaux et de santé d'entrer dans la vie des gens. avoir des connaissances médicales approfondies et la capacité de comprendre les intentions du patient à travers plusieurs cycles de dialogue et de donner des réponses professionnelles et détaillées. Face aux consultations médicales et de santé, les modèles de langage général évitent souvent de parler ou répondent à des questions qui ne sont pas posées en même temps en raison d'un manque de connaissances médicales, ils ont tendance à terminer la consultation sur la série de questions en cours et n'ont pas la capacité satisfaisante de le faire ; suivre plusieurs séries de questions. De plus, les ensembles de données médicales chinoises de haute qualité sont actuellement très rares, ce qui pose un défi pour la formation de modèles linguistiques puissants dans le domaine médical.
Le Laboratoire d'intelligence des données et d'informatique sociale de l'Université de Fudan (FudanDISC) a lancé un assistant personnel médical et de santé chinois - DISC-MedLLM. Dans l'évaluation des consultations médicales et de santé des questions et réponses à un seul tour et du dialogue à plusieurs tours, les performances du modèle montrent des avantages évidents par rapport aux grands modèles de dialogue médical existants. L'équipe de recherche a également publié un ensemble de données de réglage fin supervisé (SFT) de haute qualité, DISC-Med-SFT, contenant 470 000 personnes. Les paramètres du modèle et les rapports techniques sont également open source. Adresse de la page d'accueil : https://med.fudan-disc.com
Adresse Github : https://github.com/FudanDISC/DISC-MedLLM
Rapport technique : https : //arxiv.org/abs/2308.14346
1. Exemple d'affichage
Figure 1 : Exemple de dialogue Lorsque les patients ne se sentent pas bien, ils peuvent demander le modèle pour décrire vos symptômes, et le modèle donnera les causes possibles, les plans de traitement recommandés, etc. à titre de référence. Lorsque les informations manquent, il demandera de manière proactive des descriptions détaillées des symptômes. 
Figure 2 : Dialogue dans un scénario de consultation
Les utilisateurs peuvent également poser des questions de consultation spécifiques au modèle en fonction de leur propre état de santé, et le modèle donnera des réponses détaillées et utiles. poser des questions de manière proactive lorsque les informations font défaut pour améliorer la pertinence et l'exactitude des réponses. 
Figure 3 : Dialogue basé sur une consultation sur son propre état de santé
Les utilisateurs peuvent également poser des questions sur des connaissances médicales qui n'ont rien à voir avec eux-mêmes. A ce moment, le modèle répondra. aussi professionnellement que possible pour permettre à l'utilisateur de comprendre de manière complète et précise. 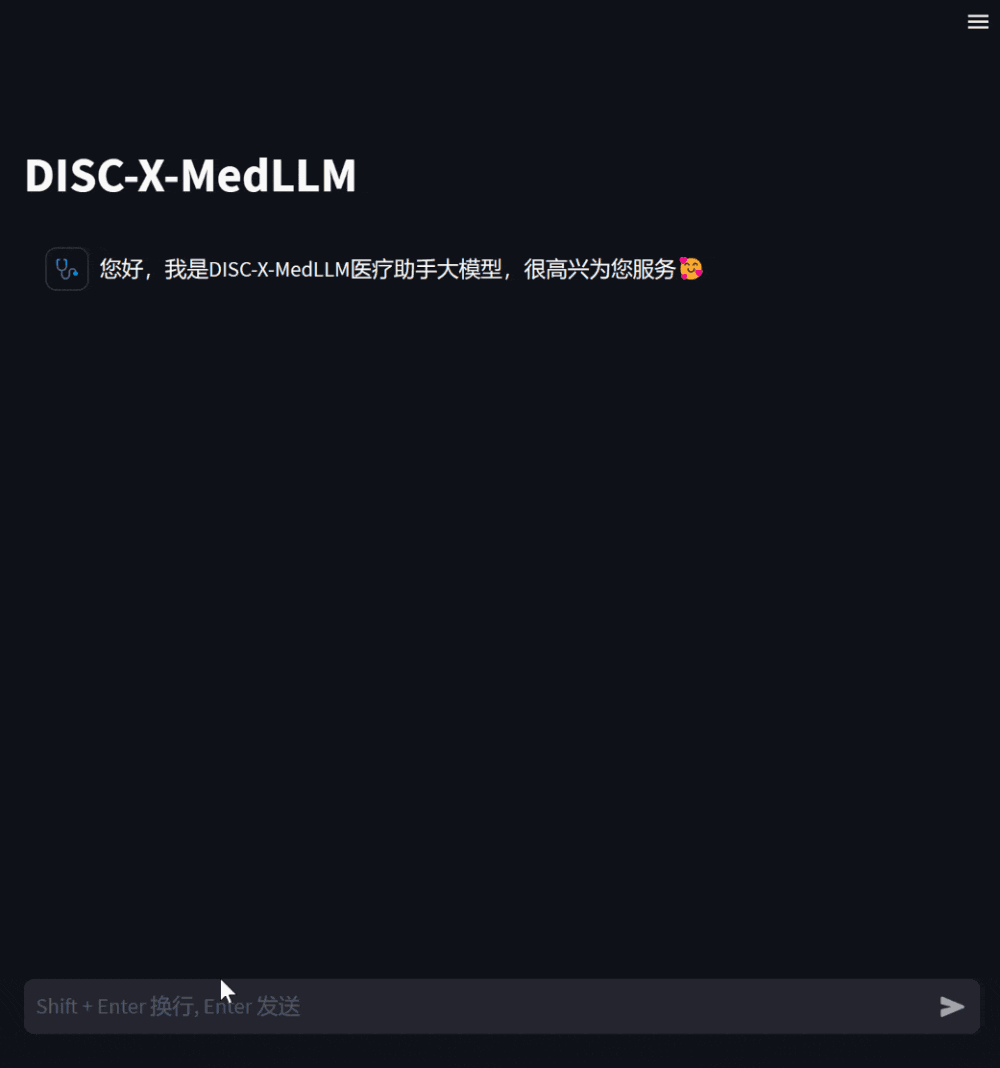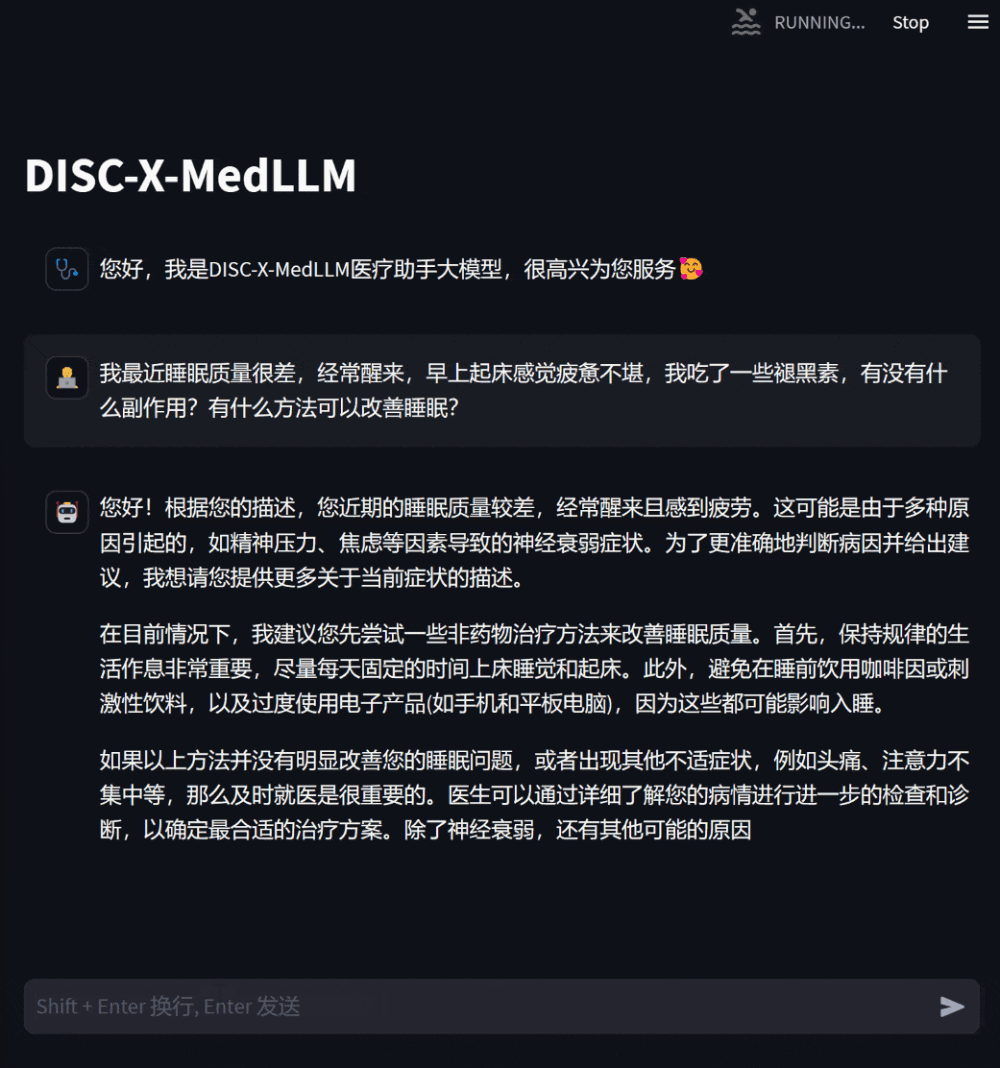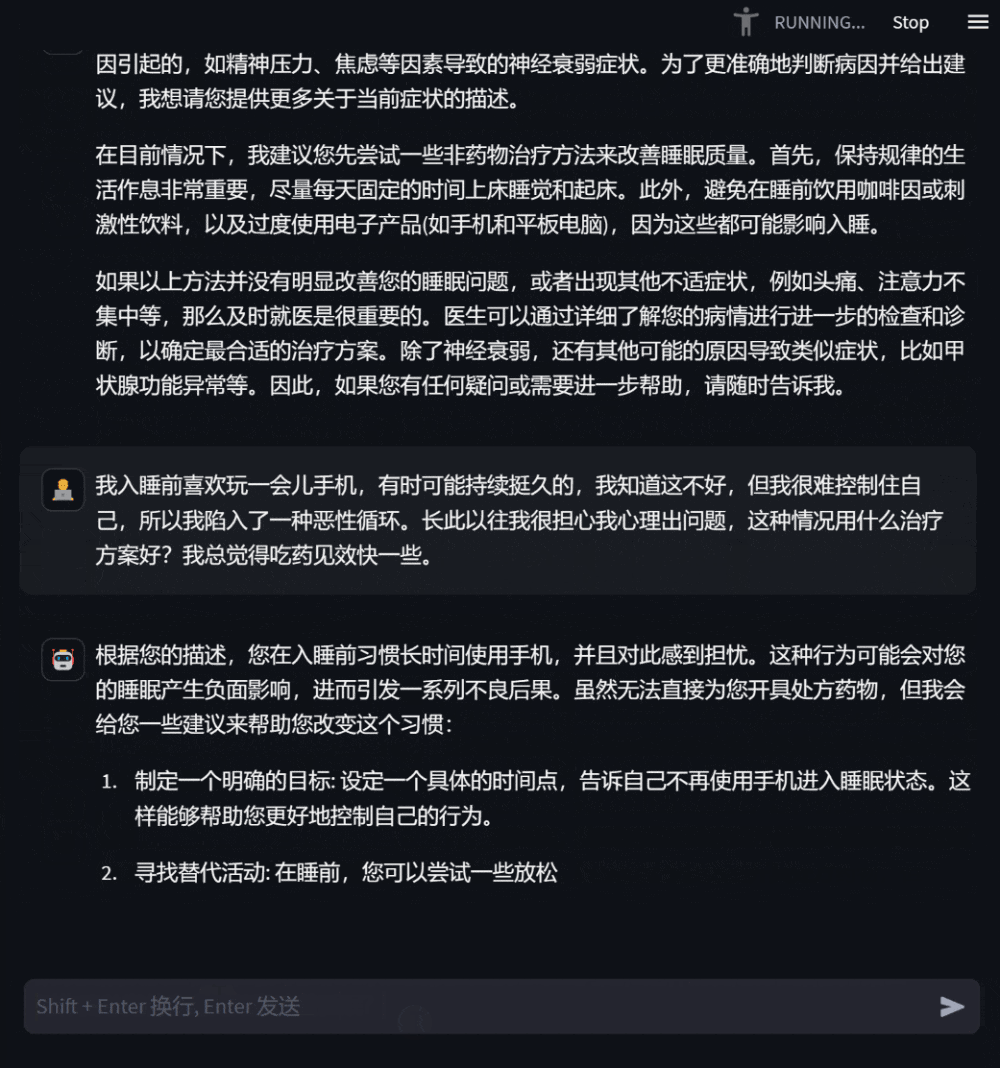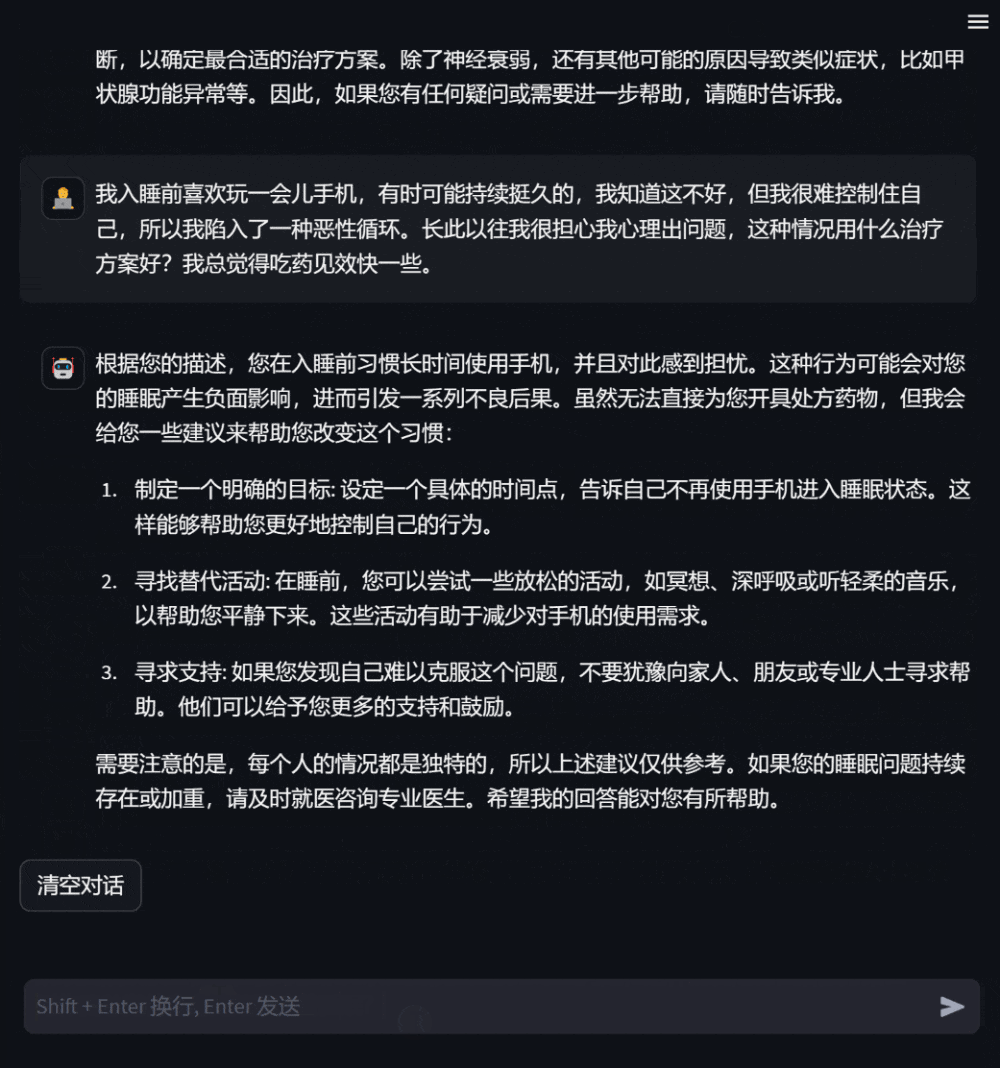
Figure 4 : Dialogue d'enquête sur les connaissances médicales sans rapport avec soi-même2. Introduction à DISC-MedLLMDISC-MedLLM est basé sur l'ensemble de données de haute qualité DISC-Med-SFT que nous avons construit. Un grand modèle médical formé sur le grand modèle chinois du domaine général Baichuan-13B. Il convient de noter que nos données et méthodes de formation peuvent être adaptées à n'importe quel grand modèle de base. DISC-MedLLM possède trois caractéristiques clés :
- Une expertise fiable et riche. Nous utilisons le graphe de connaissances médicales comme source d'informations, échantillonnons des triplets et utilisons les capacités linguistiques du grand modèle général pour construire des échantillons de dialogue.
- Capacité d'enquête pour plusieurs tours de dialogue. Nous utilisons de véritables enregistrements de dialogue de consultation comme source d'informations et utilisons de grands modèles pour reconstruire le dialogue. Pendant le processus de construction, le modèle est nécessaire pour aligner complètement les informations médicales dans le dialogue.
- Alignez les réponses sur les préférences humaines. Les patients espèrent obtenir des informations complémentaires et des connaissances de base plus riches au cours du processus de consultation, mais les réponses des médecins humains sont souvent concises grâce à une sélection manuelle, nous construisons des échantillons d'instructions à petite échelle de haute qualité pour nous aligner sur les besoins des patients.
Les avantages du modèle et du cadre de construction de données sont présentés dans la figure 5. Nous avons calculé la répartition réelle des patients à partir de scénarios de consultation réels pour guider la construction d'échantillons de l'ensemble de données. Sur la base du graphique des connaissances médicales et des données de consultation réelles, nous avons utilisé deux idées : un grand modèle dans la boucle et des personnes impliquées. la boucle pour construire l'ensemble de données. 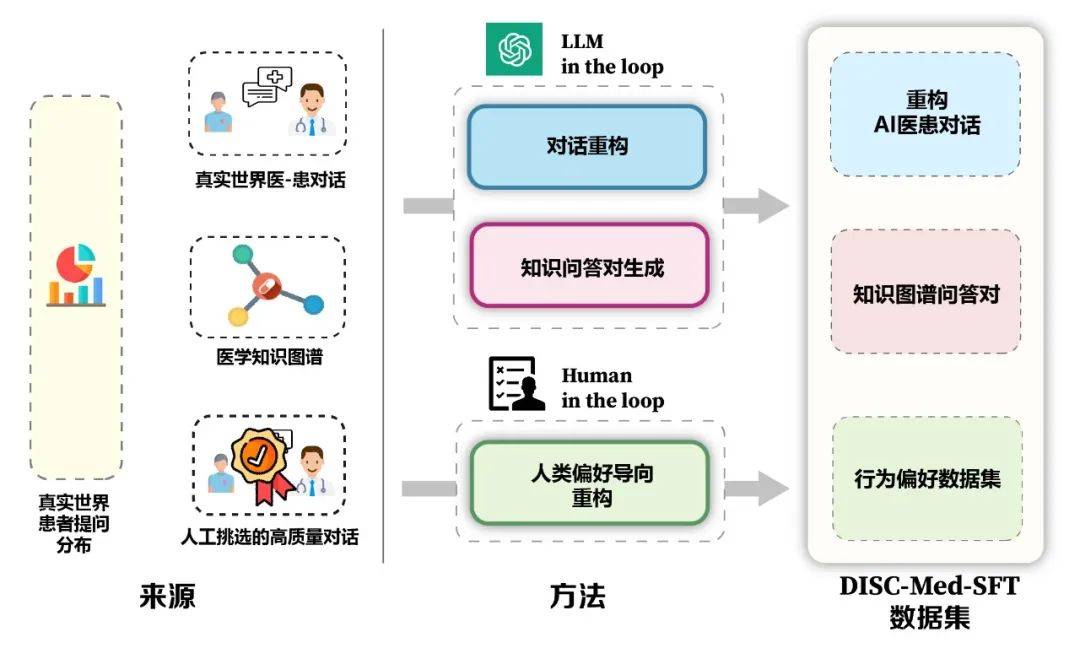
Figure 5 : Construction de DISC-Med-SFT 3. Méthode : Construction de l'ensemble de données DISC-Med-SFT processus de formation modèle, nous avons complété DISC-Med-SFT avec des ensembles de données du domaine général et des échantillons de données provenant de corpus existants, formant DISC-Med-SFT-ext. Les détails sont présentés dans le tableau 1. 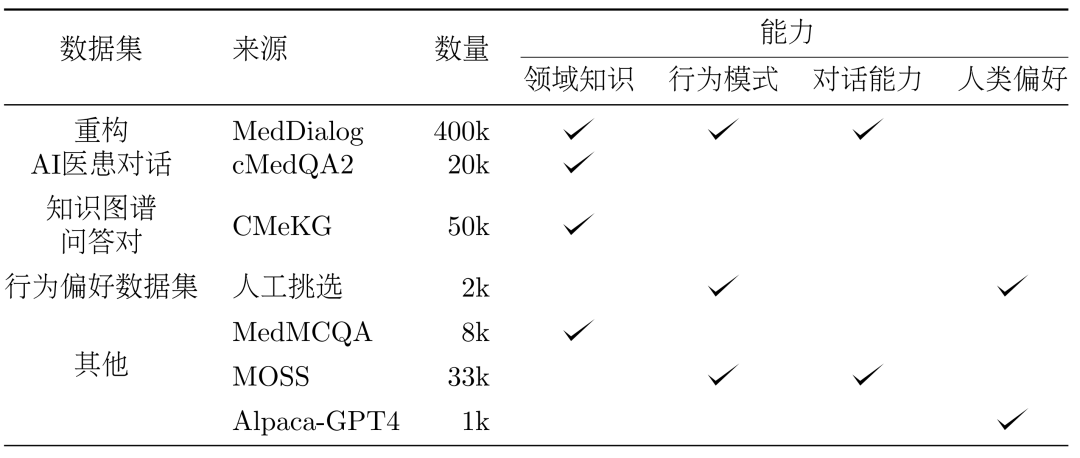
Tableau 1 : Introduction au contenu des données DISC-Med-SFT-extDialogue médecin-patient IA reconstruitensemble de données. 400 000 et 20 000 échantillons ont été sélectionnés au hasard dans deux ensembles de données publics, MedDialog et cMedQA2, respectivement, comme échantillons sources pour la construction de l'ensemble de données SFT. Refactoring. Afin d'ajuster les réponses des médecins du monde réel aux réponses formatées uniformément de haute qualité requises, nous avons utilisé GPT-3.5 pour terminer le processus de reconstruction de cet ensemble de données. Les invites nécessitent une réécriture pour suivre les principes suivants :
- Supprimez les expressions verbales, extrayez les expressions unifiées et corrigez les incohérences dans l'utilisation du langage des médecins.
- Tenez-vous-en aux informations clés de la réponse originale du médecin et fournissez les explications appropriées pour être plus complètes et logiques.
- Réécrivez ou supprimez les réponses que les médecins IA ne devraient pas envoyer, comme demander aux patients de prendre rendez-vous.
La figure 6 montre un exemple de refactoring. Les réponses ajustées du médecin sont cohérentes avec l'identité de l'assistant médical IA, adhérant aux informations clés fournies par le médecin d'origine tout en apportant une aide plus riche et plus complète au patient. 
Figure 6 : Exemple de réécriture de dialoguePaire de questions et réponses du graphe de connaissancesLe graphe des connaissances médicales contient une grande quantité d'expertise médicale bien organisée, sur la base de laquelle un bruit plus faible peut être généré des échantillons de formation QA. Sur la base de CMeKG, nous avons échantillonné dans le graphique de connaissances en fonction des informations du département sur les nœuds de la maladie et utilisé des invites de modèle GPT-3.5 conçues de manière appropriée pour générer un total de plus de 50 000 échantillons de dialogue de scène médicale divers. Ensemble de données sur les préférences comportementalesDans la dernière étape de la formation, afin d'améliorer encore les performances du modèle, nous utilisons un ensemble de données plus cohérent avec les préférences comportementales humaines pour les amendes secondaires supervisées -réglage. Environ 2 000 échantillons diversifiés de haute qualité ont été sélectionnés manuellement à partir des deux ensembles de données de MedDialog et cMedQA2. Après avoir réécrit plusieurs exemples et les avoir révisés manuellement dans GPT-4, nous avons utilisé la méthode des petits échantillons pour les fournir à GPT-3.5 et générer un niveau élevé. -ensembles de données de préférences comportementales de qualité. Données générales. Afin d'enrichir la diversité de l'ensemble de formation et d'atténuer le risque de dégradation des capacités de base du modèle au cours de la phase de formation SFT, nous avons sélectionné au hasard plusieurs échantillons à partir de deux ensembles de données de réglage fin supervisés courants, les données moss-sft-003 et alpaga gpt4. zh. MedMCQA. Pour améliorer les capacités de questions et réponses du modèle, nous avons sélectionné MedMCQA, un ensemble de données de questions à choix multiples dans le domaine médical anglais, et utilisé GPT-3.5 pour optimiser les questions et corriger les réponses aux questions à choix multiples, générant environ 8 000 chinois professionnels. échantillons de questions et réponses médicales. formation. Comme le montre la figure ci-dessous, le processus de formation de DISC-MedLLM est divisé en deux étapes SFT. 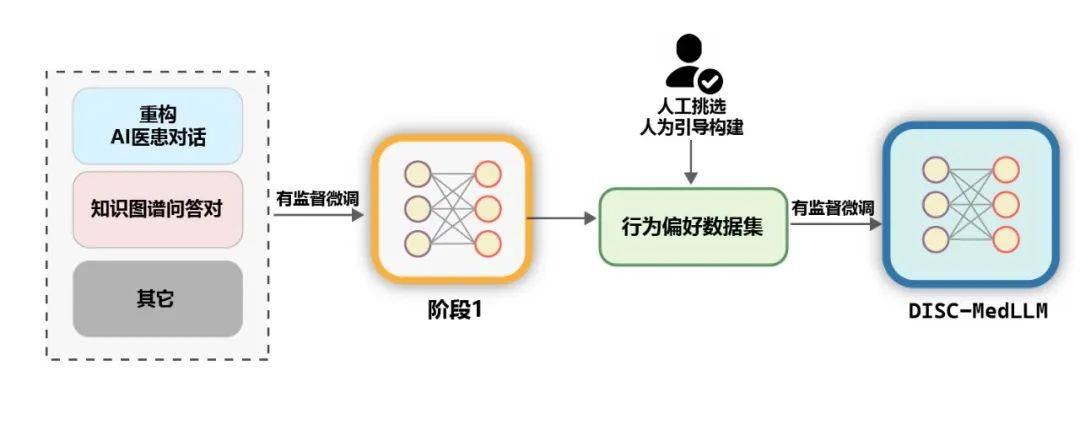
Figure 7 : Processus de formation en deux étapesÉvaluation. La performance des LLM médicaux est évaluée selon deux scénarios, à savoir l'assurance qualité en un seul tour et le dialogue à plusieurs tours.
- Évaluation d'assurance qualité en un seul tour : Afin d'évaluer l'exactitude du modèle en termes de connaissances médicales, nous avons échantillonné 1 500 échantillons de l'examen national chinois de qualification médicale (NMLEC) et de l'examen national d'entrée aux études supérieures (NEEP) Médecine occidentale 306 questions majeures + à choix multiples pour évaluer les performances du modèle en un seul cycle d'assurance qualité.
- Évaluation du dialogue à plusieurs tours : afin d'évaluer systématiquement la capacité de dialogue du modèle, nous sommes partis de trois ensembles de données publiques : Chinese Medical Benchmark (CMB-Clin), Chinese Medical Dialogue Dataset (CMD) et Chinese Medical Intent. Données Sélectionnez au hasard des échantillons de l'ensemble (CMID) et laissez GPT-3.5 jouer le rôle de patient et dialoguer avec le modèle Quatre indicateurs d'évaluation sont proposés - initiative, précision, utilité et qualité du langage, qui sont notés par GPT-4.
Comparez les modèles. Notre modèle est comparé à trois LLM généraux et à deux LLM conversationnels médicaux chinois. Y compris GPT-3.5, GPT-4, Baichuan-13B-Chat d'OpenAI ; Un seul tour de résultats d'assurance qualité. Les résultats globaux de l’évaluation à choix multiples sont présentés dans le tableau 2. GPT-3.5 montre une avance claire. DISC-MedLLM a atteint la deuxième place dans le cadre d'un petit échantillon et s'est classé troisième derrière Baichuan-13B-Chat dans le cadre d'un échantillon nul. Notamment, nous surpassons HuatuoGPT (13B) formé avec un paramètre d'apprentissage par renforcement. 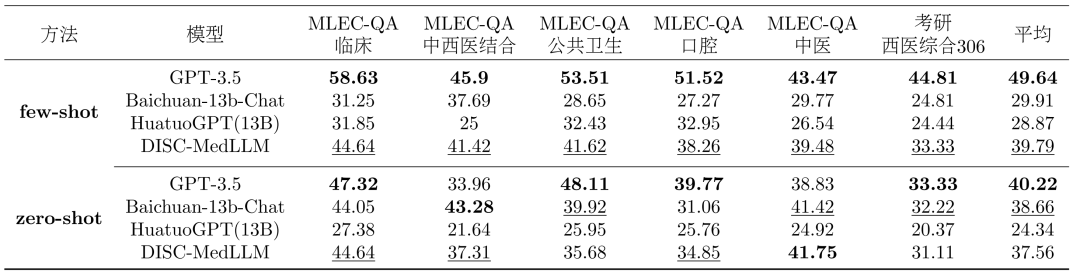
Tableau 2 : Résultats de l'évaluation à choix multiplesRésultats de plusieurs tours de dialogue. Dans l'évaluation CMB-Clin, DISC-MedLLM a obtenu le score global le plus élevé, suivi de près par HuatuoGPT. Notre modèle a obtenu le score le plus élevé pour le critère de positivité, soulignant l'efficacité de notre approche de formation qui biaise les modèles de comportement médical. Les résultats sont présentés dans le tableau 3. 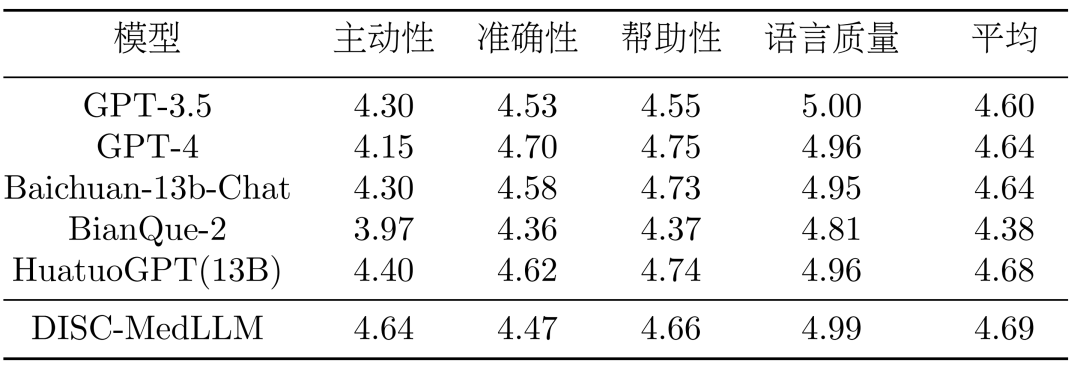
Tableau 3 : Résultats CMB-clinDans l'échantillon CMD, comme le montre la figure 8, GPT-4 a obtenu le score le plus élevé, suivi de GPT-3.5. Les modèles dans le domaine médical, DISC-MedLLM et HuatuoGPT, ont les mêmes scores de performance globale et leurs performances dans différents départements sont exceptionnelles. 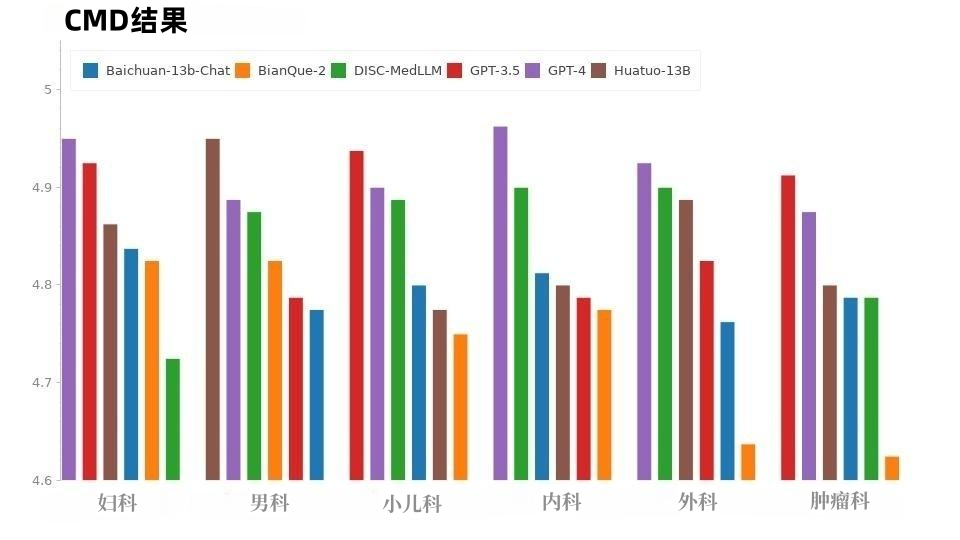
La situation du CMID est similaire à celle du CMD, comme le montre la figure 9, GPT-4 et GPT-3.5 maintiennent l'avance. À l'exception de la série GPT, DISC-MedLLM a obtenu les meilleurs résultats. Il a surpassé HuatuoGPT dans trois domaines : condition, schéma thérapeutique et médicaments. 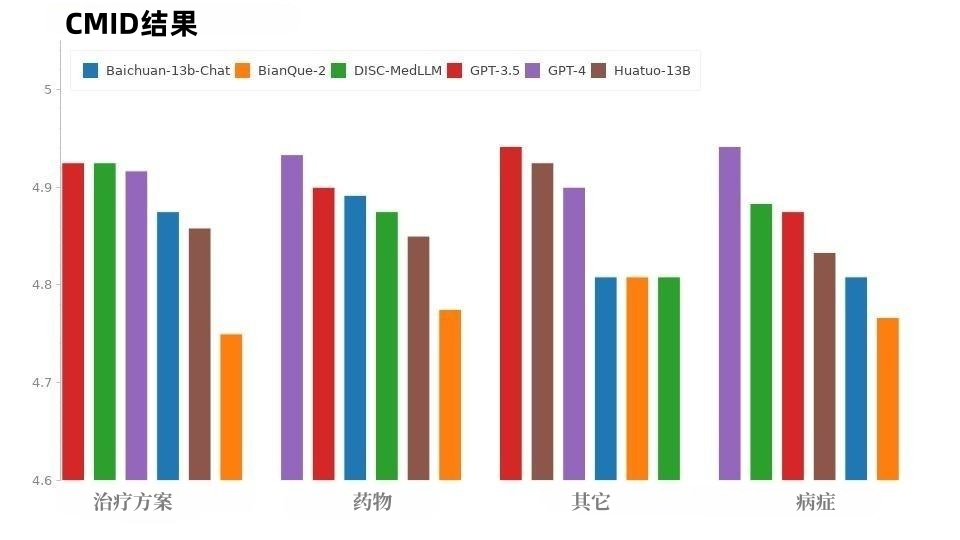
Figure 9 : Résultats CMIDLes performances incohérentes de chaque modèle entre CMB-Clin et CMD/CMID peuvent être dues à la distribution différente des données entre ces trois ensembles de données. CMD et CMID contiennent un échantillon de questions plus explicites, et les patients peuvent déjà avoir un diagnostic et exprimer des besoins clairs lors de la description des symptômes, et les questions et besoins du patient peuvent même n'avoir rien à voir avec leur état de santé personnel. Les modèles polyvalents GPT-3.5 et GPT-4, qui excellent à bien des égards, sont plus à même de gérer cette situation. L'ensemble de données DISC-Med-SFT tire parti des avantages et des capacités du dialogue réel et du LLM du domaine général, et apporte des améliorations ciblées dans trois aspects : la connaissance du domaine, dialogue médical Compétences et préférences humaines ; ensembles de données de haute qualité ont formé l'excellent grand modèle médical DISC-MedLLM, qui a permis d'améliorer considérablement l'interaction médicale, a démontré une grande convivialité et a montré un grand potentiel d'application. La recherche dans ce domaine apportera davantage de perspectives et de possibilités pour réduire les coûts médicaux en ligne, promouvoir les ressources médicales et atteindre l'équilibre. DISC-MedLLM apportera des services médicaux pratiques et personnalisés à un plus grand nombre de personnes et contribuera à la cause de la santé générale. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



