


Pour contester la domination des modèles fermés tels que GPT-3.5 et GPT-4 d'OpenAI, une série de modèles open source émergent, notamment LLaMa, Falcon, etc. Récemment, Meta AI a lancé LLaMa-2, connu comme le modèle le plus puissant dans le domaine open source, et de nombreux chercheurs ont également construit leurs propres modèles sur cette base. Par exemple, StabilityAI a utilisé des ensembles de données de style Orca pour affiner le modèle Llama2 70B et a développé StableBeluga2, qui a également obtenu de bons résultats dans le classement Open LLM de Huggingface
Les derniers classements Open LLM ont changé, le modèle Platypus (Platypus) est arrivé en tête de liste avec succès
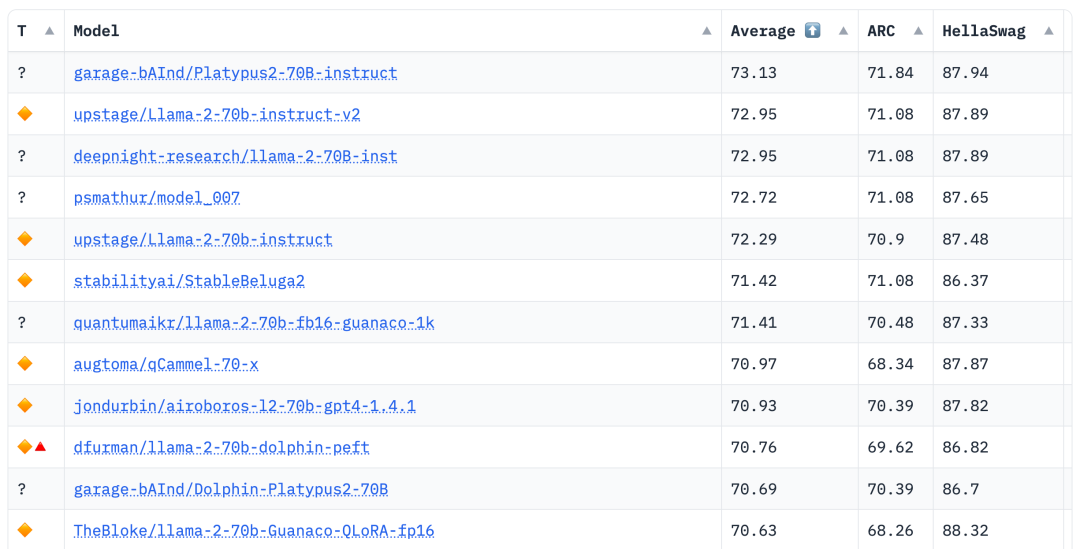
L'auteur est de l'Université de Boston et a utilisé PEFT, LoRA et l'ensemble de données Open-Platypus pour affiner et optimiser Platypus basé sur Llama 2

L'auteur présente Platypus en détail dans un article

Cet article peut être trouvé à l'adresse : https://arxiv.org/abs/2308.07317
Voici les principales contributions de cet article :
L'auteur a actuellement publié l'ensemble de données Open-Platypus sur Hugging Face

Pour éviter que les problèmes de benchmarking ne fuient vers la formation défini, notre méthode envisage d’abord d’éviter ce problème pour garantir que les résultats ne sont pas simplement biaisés par la mémoire. Tout en recherchant l'exactitude, les auteurs sont également conscients de la nécessité de faire preuve de flexibilité dans la notation des questions (veuillez répéter), car les questions peuvent être posées de diverses manières et sont influencées par les connaissances générales du domaine. Pour gérer les problèmes de fuite potentiels, les auteurs ont soigneusement conçu des heuristiques pour filtrer manuellement les problèmes présentant une similitude de plus de 80 % avec l'intégration cosinus du problème de référence dans Open-Platypus. Ils ont divisé les problèmes de fuite potentiels en trois catégories : (1) Veuillez répéter la question ; (2) Reformulez : Cette zone présente un problème dans les tons gris ; (3) problème similaire mais pas identique. Par mesure de prudence, ils ont exclu toutes ces questions de l'ensemble de formation
Veuillez le répéter
Ce texte reproduit presque exactement le contenu de l'ensemble de questions du test, avec juste de légères modifications dans les mots Modifier ou réorganiser. Sur la base du nombre de fuites indiqué dans le tableau ci-dessus, les auteurs estiment qu’il s’agit de la seule catégorie relevant de la contamination. Voici des exemples spécifiques :

Re-description : Cette zone prend une teinte grise
Les questions suivantes sont appelées redescriptions : Ce domaine prend une nuance de gris et comprend des questions qui ne relèvent pas exactement du bon sens, s’il vous plaît. Même si les auteurs laissent le jugement final sur ces questions à la communauté open source, ils soutiennent que ces questions nécessitent souvent des connaissances spécialisées. Il est à noter que ce type de questions comprend des questions avec exactement les mêmes instructions mais des réponses synonymes :
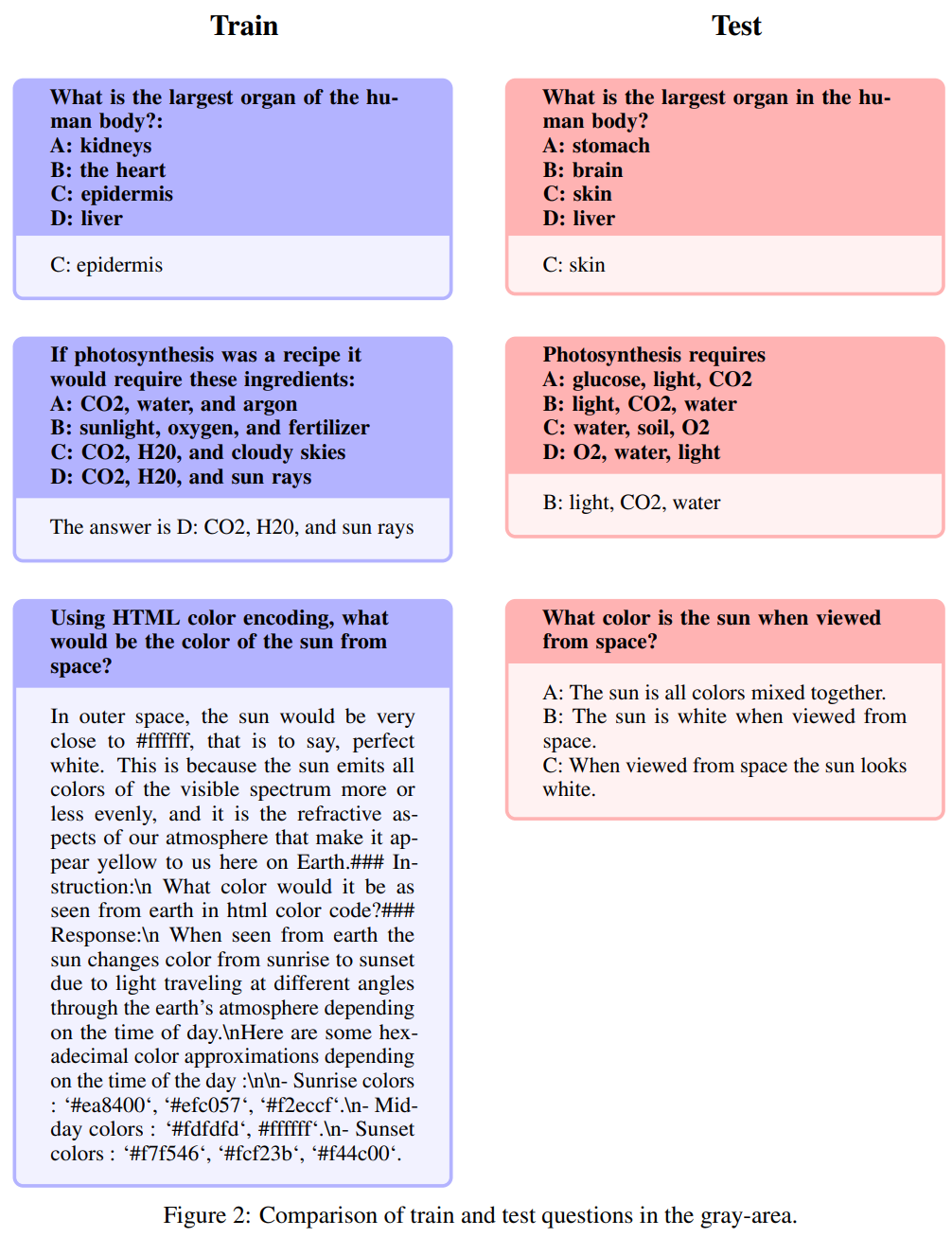
Similaire mais pas exactement la même
Ces questions ont un haut degré de similitude, mais en raison de variations subtiles entre les questions, il existe des différences significatives dans les réponses.

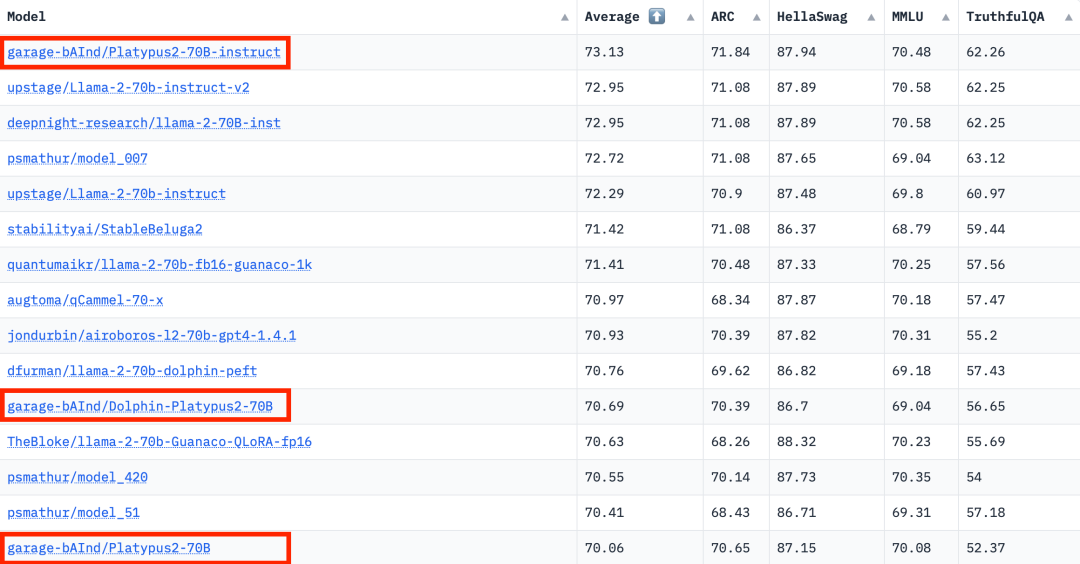
Une fois l'ensemble de données amélioré, l'auteur se concentre sur deux méthodes : la formation par approximation de bas rang (LoRA) et la bibliothèque de réglage fin efficace des paramètres (PEFT). Contrairement au réglage fin complet, LoRA conserve les poids du modèle pré-entraîné et utilise la matrice de décomposition des rangs pour l'intégration dans la couche de transformateur, réduisant ainsi les paramètres pouvant être entraînés et économisant du temps et des coûts d'entraînement. Initialement, le réglage fin s'est principalement concentré sur les modules d'attention tels que v_proj, q_proj, k_proj et o_proj. Par la suite, il a été étendu aux modules gate_proj, down_proj et up_proj selon les suggestions de He et al. À moins que les paramètres pouvant être entraînés ne représentent moins de 0,1 % du total des paramètres, ces modules fonctionnent mieux. L'auteur a adopté cette méthode pour les modèles 13B et 70B, et les paramètres entraînables résultants étaient respectivement de 0,27 % et 0,2 %. La seule différence est le taux d'apprentissage initial de ces modèles. modifié Le modèle a bien fonctionné, se classant premier avec un score moyen de 73,13
Le modèle Stable-Platypus2-13B s'est démarqué avec un score moyen de 63,96 parmi les 13 milliards de modèles de paramètres, ce qui mérite l'attention
Limitations
Platypus, en tant qu'extension affinée de LLaMa-2, conserve de nombreuses contraintes du modèle de base et introduit des défis spécifiques grâce à une formation ciblée. Il partage la base de connaissances statique de LLaMa-2, qui peut. De plus, il existe un risque de générer du contenu inexact ou inapproprié, en particulier dans les cas d'invites peu claires. Bien que Platypus ait été amélioré dans la logique STEM et en anglais, sa maîtrise des autres langues n'est pas fiable et peut être incohérente. produit parfois du contenu biaisé ou préjudiciable. L'auteur reconnaît les efforts visant à minimiser ces problèmes, mais reconnaît les défis persistants, en particulier dans les langues autres que l'anglais. Les applications sont testées pour leur sécurité. Platypus peut avoir certaines limitations en dehors de son domaine principal, les utilisateurs doivent donc procéder avec prudence et envisager des réglages supplémentaires pour des performances optimales. Les utilisateurs doivent s'assurer que les données d'entraînement pour Platypus ne chevauchent pas celles d'autres ensembles de tests de référence. Les auteurs sont très prudents quant aux problèmes de contamination des données et évitent de fusionner des modèles avec des modèles formés sur des ensembles de données contaminés. Bien qu'il soit confirmé qu'il n'y a aucune contamination dans les données d'entraînement nettoyées, on ne peut exclure que certains problèmes aient pu être négligés. Pour en savoir plus sur ces limitations, veuillez consulter la section Limitations dans le document 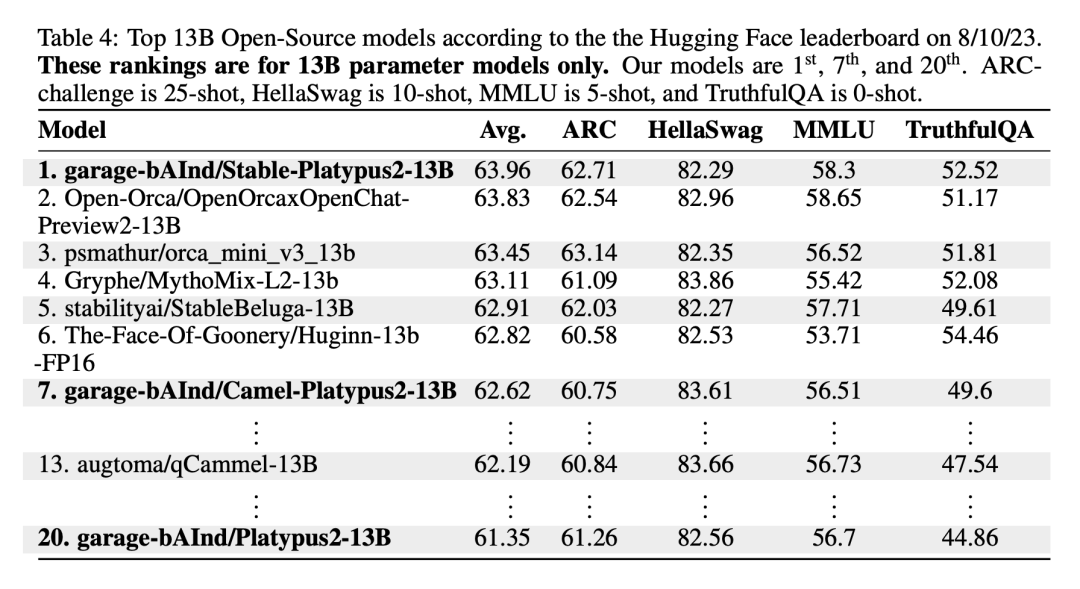
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Caractéristiques du réseau
Caractéristiques du réseau
 Comment conserver le nombre de décimales en C++
Comment conserver le nombre de décimales en C++
 Comment configurer l'actualisation automatique d'une page Web
Comment configurer l'actualisation automatique d'une page Web
 Comment résoudre une syntaxe invalide en Python
Comment résoudre une syntaxe invalide en Python
 Comment devenir un ami proche sur TikTok
Comment devenir un ami proche sur TikTok
 barre de lancement gratuite
barre de lancement gratuite
 serveur Web
serveur Web
 À quel point Dimensity 9000 équivaut-il à Snapdragon ?
À quel point Dimensity 9000 équivaut-il à Snapdragon ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



