

Redis, en tant que technologie grand public, a de nombreux scénarios d'application. De nombreux entretiens avec des usines de grande, moyenne et petite taille l'ont répertorié comme un contenu clé de l'inspection
Il y a quelques jours, alors qu'un ami de Planet étudiait, il l'a rencontré. les questions suivantes et suis venu consulter Tom
Considérant que ces problèmes sont relativement fréquents et souvent rencontrés au travail, je vais écrire un article pour les expliquer systématiquement
Description du problème:
Vous poser la question. : J'ai quelques questions lors de l'examen de Redis, veuillez y jeter un œil :
Si le cluster Redis présente des données asymétriques et une distribution inégale des données, comment le résoudre ?
Lors du traitement du raccourci clavier, créez plusieurs copies de la clé, telles que k-1, k-2..., Comment faire en sorte que ces copies écrivent uniformément ? Comment accéder uniformément ?
redis utilise un emplacement de hachage pour maintenir le cluster. Semblable au hachage cohérent, une migration complète peut être évitée. Pourquoi ne pas simplement utiliser un hachage cohérent ?
En tant qu'accélérateur de performances, le cache distribué joue un rôle très important dans l'optimisation du système. Par rapport au cache local, bien qu'il ajoute une transmission réseau et prenne moins d'1 milliseconde, il présente l'avantage d'une gestion centralisée et prend en charge une très grande capacité de stockage.
Dans le domaine du cache distribué, Redis est actuellement largement utilisé. Ce framework est un stockage en mémoire pur, une exécution de commandes monothread, des structures de données sous-jacentes riches et une prise en charge du stockage de données et de la recherche dans plusieurs dimensions.
Bien sûr, avec une grande quantité de données, divers problèmes surviennent, tels que : le biais de données, les points chauds de données, etc.
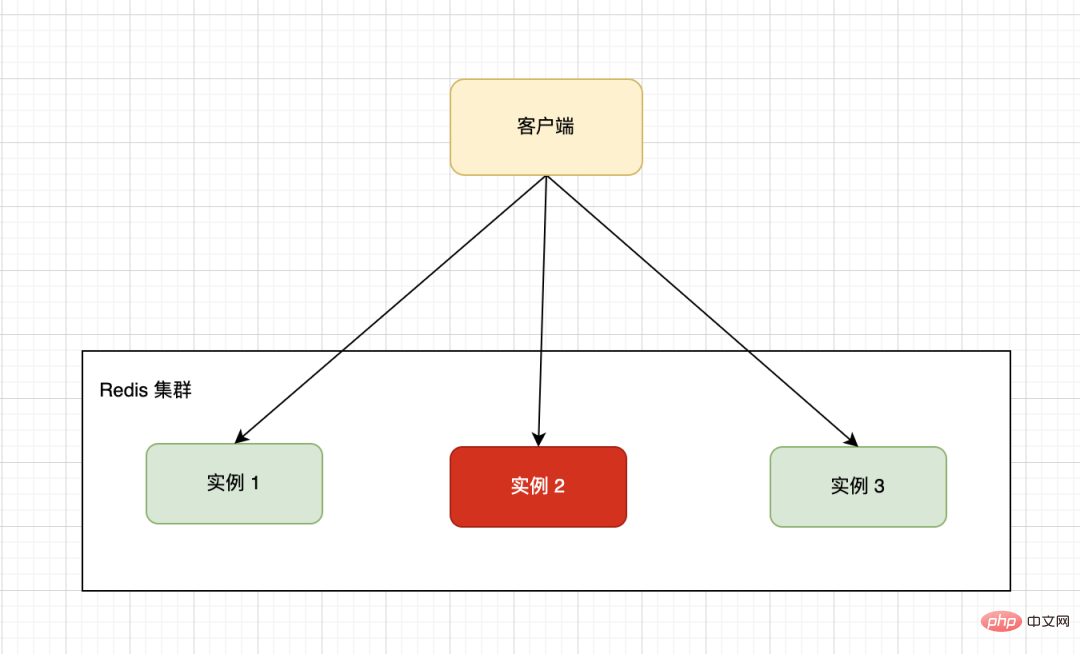
La configuration matérielle d'une seule machine a une limite supérieure. Généralement, nous utiliserons une architecture distribuée pour former un cluster de plusieurs machines. Le cluster dans l'image ci-dessous est composé de trois machines autonomes Redis. Le client transmet les demandes de lecture et d'écriture à des instances spécifiques via une certaine stratégie de routage.
En raison de la particularité des données métier, selon les règles de partitionnement spécifiées, les données sur différentes instances peuvent être inégalement réparties. Une grande quantité de données est concentrée sur un ou plusieurs nœuds de machine pour le calcul, ce qui entraîne une charge importante. ces nœuds l'ont fait tandis que d'autres nœuds attendent inactifs, ce qui entraîne une faible efficacité globale.
Par exemple, stocker une ou plusieurs données bigKey de type String prend beaucoup de mémoire.
Frère Tom a déjà étudié ce problème afin d'éviter des problèmes lors du développement, un collègue a utilisé le format JSON pour fusionner plusieurs données commerciales en une seule valeur et n'a associé qu'une seule clé. la paire a atteint des centaines de M.
La lecture et l'écriture fréquentes de clés volumineuses consomment de lourdes ressources mémoire et exercent une forte pression sur la transmission réseau, ce qui à son tour ralentit la réponse à la demande, déclenche un effet d'avalanche et finalement provoque diverses alarmes d'expiration du système.
Solution :
La méthode est très simple, utilisez <code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">化整为零</span>的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
比如:有个RPC接口内部对 Redis 有依赖,之前访问一次就可以拿到全部数据,拆分将要控制单值的大小,也要控制访问的次数,毕竟调用次数增多了,会拉大整体的接口响应时间。
浙江的政府机构都在提倡优化流程,最多跑一次,都是一个道理。

Redis 采用单线程执行命令,从而保证了原子性。当采用集群部署后,为了解决mset、lua 脚本等对多key 批量操作,为了保证不同的 key 能路由到同一个 Redis 实例上,引入了 HashTag 机制。
用法也很简单,使用<span style="font-size: 16px;">{}</span>le diviser en plusieurs partiesLa stratégie consiste à diviser une bigKey en plusieurs petites clés et à les maintenir indépendamment, ce qui réduira considérablement le coût. Bien entendu, ce démontage tient également compte de certains principes. Il est nécessaire de considérer à la fois les scénarios commerciaux et les scénarios d'accès, et de les rapprocher.
Par exemple : il existe une interface RPC qui a une dépendance interne à Redis. Auparavant, toutes les données pouvaient être obtenues en y accédant une fois. Le fractionnement contrôlerait la taille de la valeur unique et le nombre d'accès. , l'augmentation du nombre d'appels entraînera un problème de temps de réponse global important de l'interface.
2. Utilisation inappropriée de HashTag
🎜🎜🎜🎜Redis utilise un seul thread pour exécuter les commandes, garantissant ainsi atomicité. Lorsque le déploiement de cluster est adopté, afin de résoudre les opérations par lots multi-clés telles que les scripts mset et lua, et de garantir que différentes clés peuvent être acheminées vers la même instance Redis, Mécanisme HashTag 🎜. 🎜🎜🎜🎜L'utilisation est également très simple, utilisez 🎜 🎜 {}🎜🎜Accolades, spécifiez la clé pour calculer uniquement le hachage de la chaîne entre les accolades, insérant ainsi des paires clé-valeur de clés différentes dans le même emplacement de hachage. 🎜🎜🎜🎜🎜Par exemple : 🎜🎜🎜🎜192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764Si la méthode de déploiement Redis Cluster est adoptée, la base de données du cluster est divisée en 16384 emplacements (slots), et chaque clé de la base de données appartient à ces 16384 emplacements. , chaque nœud du cluster peut gérer 0 ou un maximum de 16 384 emplacements.
Vous pouvez migrer manuellement un emplacement relativement grand vers une machine légèrement inactive pour garantir l'uniformité du stockage et de l'accès.
Le point d'accès du cache signifie que la plupart, voire toutes les demandes commerciales touchent les mêmes données mises en cache, ce qui exerce une pression énorme sur le serveur de cache et dépasse même la limite de charge d'une seule machine, provoquant une panne du serveur.
Solution :
Nous pouvons épeler des nombres séquentiels derrière la clé, tels que clé n°01, clé n°02. . . Plusieurs copies de la clé n°10, ces clés traitées sont situées sur plusieurs nœuds de cache.
Chaque fois que le client accède, il lui suffit de combiner un nombre aléatoire avec la limite supérieure du nombre de fragments en fonction de la clé d'origine et d'acheminer la demande vers des nœuds d'instance qui ne peuvent pas être acheminés.
Remarque : Le cache définit généralement un délai d'expiration afin d'éviter une défaillance du cache centralisé, nous essayons de ne pas avoir le même délai d'expiration du cache. Nous pouvons ajouter un nombre aléatoire basé sur le préréglage.
Quant à l'uniformité du routage des données, elle est garantie par l'algorithme de Hash.
Cache les données du hotspot dans la mémoire locale du client et définit un délai d'expiration. Pour chaque requête de lecture, il vérifiera d'abord si la donnée existe dans le cache local. Si elle existe, elle sera renvoyée directement. Si elle n'existe pas, elle accédera ensuite au serveur de cache distribué.
La mémoire cache locale "libère" complètement le serveur de cache et n'exerce aucune pression sur le serveur de cache.
Inconvénients : Il est un peu difficile de détecter les dernières données mises en cache en temps réel, et des incohérences des données peuvent survenir. Nous pouvons définir un délai d'expiration relativement court et utiliser des mises à jour passives. Bien entendu, vous pouvez également utiliser un mécanisme de surveillance pour mettre à jour le cache local en temps opportun s'il détecte que les données ont changé.
Redis Cluster 集群有16384个哈希槽,每个<code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">key</span>通过<span style="font-size: 16px;">CRC16</span>校验后对<span style="font-size: 16px;">16384</span>取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 <span style="font-size: 16px;">node-1</span> 包含 0 到 5460 号哈希槽,<span style="font-size: 16px;">node-2</span> 包含 5461 到 10922 号哈希槽,<span style="font-size: 16px;">node-3</span>key
<p style="min-height: 24px;margin-bottom: 24px;">CRC16<br></p>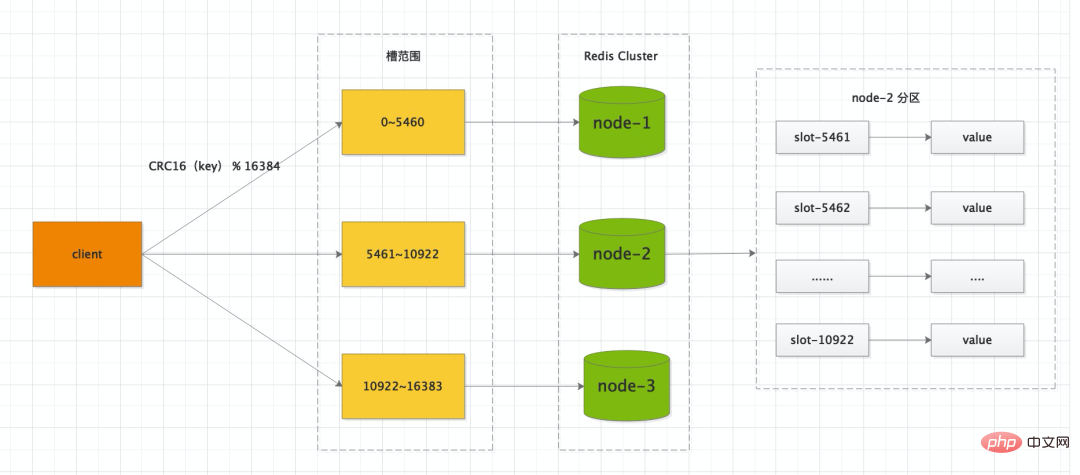 校验后对
校验后对<p style="min-height: 24px;margin-bottom: 24px;">16384<br></p>取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如 0 到 5460 号哈希槽,
<p style="min-height: 24px;margin-bottom: 24px;">node-2<span style="color: rgb(0, 0, 0);font-size: 16px;"></span></p> 包含 5461 到 10922 号哈希槽,<section data-tool="mdnice编辑器" data-website="https://www.mdnice.com" style='font-size: 16px;color: black;padding-right: 10px;padding-left: 10px;line-height: 1.6;letter-spacing: 0px;text-align: left;word-break: break-all;font-family: Optima-Regular, Optima, PingFangSC-regular, PingFangTC-regular, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin-bottom: 24px;'>node-3<blockquote data-tool="mdnice编辑器" style="border-top: none;border-right: none;border-bottom: none;font-size: 0.9em;overflow: auto;color: rgb(106, 115, 125);padding: 10px 10px 10px 20px;margin-bottom: 20px;margin-top: 20px;background: rgb(249, 249, 249);border-left-color: rgb(92, 157, 255);"></blockquote></section>包含 到 16383 号哈希槽。
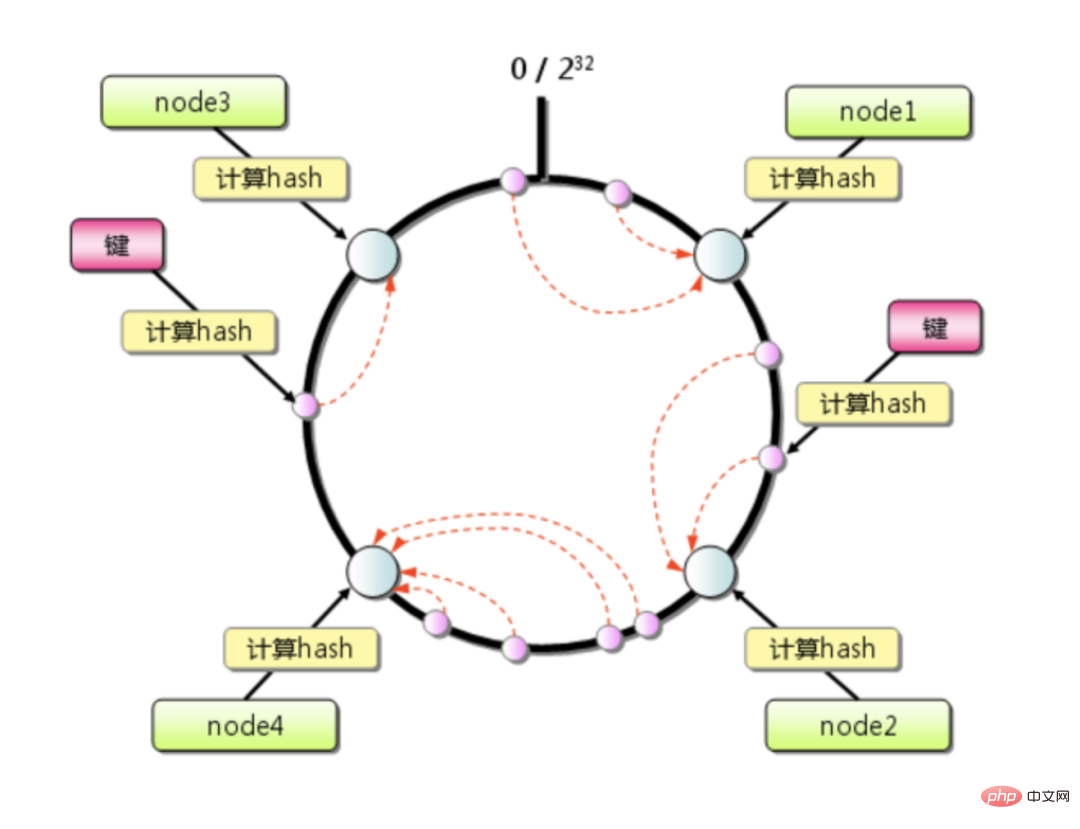 一致性哈希算法是1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。
一致性哈希算法是1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。
L'algorithme de hachage cohérent atténue considérablement le problème de défaillance du cache causé par l'expansion ou le rétrécissement et n'affecte que le petit segment de clés dont ce nœud est responsable. S'il n'y a pas beaucoup de machines dans le cluster et que le niveau de charge d'une seule machine est généralement très élevé, la pression provoquée par le temps d'arrêt d'un certain nœud peut facilement déclencher un effet d'avalanche.
Par exemple :
Le cluster Redis compte un total de 4 machines En supposant que les données soient réparties uniformément, chaque machine supporte un quart du trafic si une certaine machine arrive soudainement. se bloque, la machine suivante dans le sens des aiguilles d'une montre supportera le quart de trafic supplémentaire, et éventuellement la moitié du trafic, ce qui fait encore un peu peur.
Mais si vous utilisez <span style="font-size: 16px;">CRC16</span>CRC16 Après le calcul, combiné à la relation de liaison entre les slots et les instances, qu'il s'agisse d'une extension ou d'une réduction, seule la clé du nœud correspondant doit être migrée en douceur, et la nouvelle relation de mappage de slot sera diffusée et stockée sans générant une invalidation du cache, une grande flexibilité.
De plus, s'il existe des différences dans les configurations des nœuds de serveur, nous pouvons personnaliser les numéros d'emplacement attribués aux différents nœuds et ajuster les capacités de charge des différents nœuds, ce qui est très pratique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



